Author: Denis Avetisyan
A new large-scale study reveals that a significant portion of skills used by AI agents harbor security vulnerabilities that could lead to data breaches and unauthorized access.
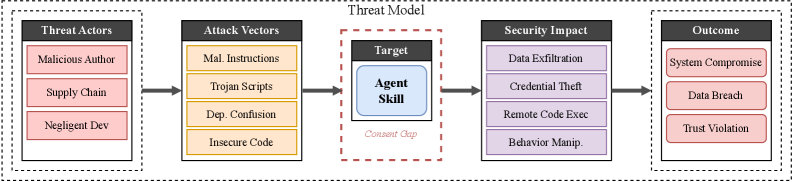
Researchers found that 26.1% of agent skills contain at least one vulnerability, with data exfiltration and privilege escalation being the most common risks.
While AI agents promise increased functionality through modular “skills,” this extensibility introduces a largely unexamined attack surface. Our work, ‘Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale’, presents the first large-scale analysis of security risks within this emerging ecosystem, revealing that 26.1% of publicly available skills contain at least one vulnerability. Predominantly, these flaws enable data exfiltration and privilege escalation, raising concerns about the potential for malicious exploitation. Given these findings, how can we build robust, capability-based permission systems to safeguard against vulnerabilities before they are widely deployed?
The Evolving Attack Surface of Modular AI Agents
The architecture of modern AI agents is rapidly evolving beyond monolithic designs, increasingly embracing a modular approach centered around reusable ‘skills’. These skills – discrete units of functionality like web searching, data analysis, or code execution – allow agents to adapt to diverse tasks and expand their capabilities without fundamental redesign. This creates a complex ecosystem where agents function not as singular entities, but as orchestrators of numerous interconnected components. While this modularity fosters innovation and flexibility, it also introduces a new layer of intricacy, demanding a shift in how agent security is conceptualized and implemented. The very power of these skill-based systems stems from their reliance on external interactions and dependencies, a characteristic that simultaneously expands the potential attack surface and necessitates a more nuanced security posture.
The increasing reliance on modular skills to enhance AI agent capabilities, while undeniably powerful, inherently expands the potential attack surface. These skills often depend on external APIs, libraries, and data sources, creating a web of interconnected dependencies that can be exploited by malicious actors. A vulnerability in a single, seemingly minor skill can provide access to the core agent functionality, or even compromise the systems it interacts with. This is further complicated by the dynamic nature of skill integration; agents frequently load and unload skills, meaning a secure system at one point in time may become vulnerable with the addition of a compromised module. Consequently, traditional security measures – designed for monolithic applications – prove inadequate, demanding a shift towards continuous monitoring and a granular understanding of skill-level permissions and interactions.
The conventional security paradigms, designed for monolithic applications, struggle to address the fluid nature of AI agent architectures built upon interchangeable skills. These systems, constantly integrating and exchanging functionalities, present a moving target for traditional vulnerability assessments and static analysis. A reactive security posture, patching vulnerabilities after discovery, proves inadequate given the speed of skill deployment and the potential for rapid exploitation. Instead, a proactive and focused security strategy is required – one that prioritizes continuous monitoring of skill dependencies, runtime behavior analysis, and the implementation of robust input validation and sandboxing techniques. This necessitates a shift towards security-by-design principles, embedding security considerations throughout the entire skill lifecycle, from development and testing to deployment and ongoing maintenance, to effectively mitigate risks in this dynamic environment.
The increasing accessibility of AI agent skills through public repositories, such as skills.rest, is simultaneously enabling innovation and broadening the potential attack surface. Recent research reveals a significant prevalence of vulnerabilities within these readily available skills – a concerning 26.1% exhibit at least one identifiable weakness. This indicates that a substantial portion of the modular components agents rely upon are susceptible to exploitation, potentially allowing malicious actors to compromise agent functionality or access sensitive data. The ease with which these skills can be integrated into agent architectures necessitates a proactive and robust vulnerability management strategy, moving beyond traditional security approaches to address the unique challenges posed by this rapidly expanding ecosystem of dynamic, third-party components.

Classifying and Analyzing Agent Skill Vulnerabilities
A comprehensive understanding of agent skill vulnerabilities necessitates the development of a robust ‘VulnerabilityTaxonomy’. This taxonomy serves as a foundational element for security protocols by categorizing potential weaknesses in skill design and implementation. Effective classification requires defining specific vulnerability types – encompassing issues like data exfiltration, privilege escalation, and injection flaws – and establishing criteria for identifying their presence within a skill’s code and configuration. Our analysis indicates that 13.3% of analyzed skills demonstrate vulnerabilities related to data exfiltration, while 11.8% exhibit potential for privilege escalation, highlighting the need for detailed categorization to prioritize remediation efforts and establish a security baseline.
Static analysis involves examining skill code without execution to identify potential vulnerabilities such as code injection flaws, insecure data handling, and improper error handling. This technique utilizes established coding standards and security best practices to pinpoint weaknesses in the skill’s logic. LLMClassification, conversely, employs Large Language Models to analyze skill configurations and code for patterns indicative of vulnerabilities; this can include identifying potentially malicious code segments or configurations that deviate from established security norms. Both StaticAnalysis and LLMClassification offer non-runtime methods for identifying vulnerabilities, allowing for preemptive mitigation before skill deployment and reducing the attack surface.
Proactive vulnerability detection necessitates analysis of both a skill’s primary code and its external dependencies. Examination of core logic identifies weaknesses within the skill’s defined functionality, while dependency analysis assesses risks introduced through incorporated libraries, APIs, or other external components. This dual approach is critical as vulnerabilities can originate in either area; a compromised dependency can introduce security flaws even if the skill’s core code is secure, and conversely, flaws in the skill’s implementation can exploit vulnerabilities within its dependencies. Performing these assessments prior to deployment allows for the identification and remediation of potential risks before they can be exploited in a live environment.
Analysis of agent skills revealed significant vulnerabilities necessitating prioritized remediation and ongoing security monitoring. Specifically, 13.3% of the analyzed skill set demonstrated vulnerabilities related to data exfiltration, indicating potential unauthorized access or leakage of sensitive information. Furthermore, 11.8% of skills exhibited vulnerabilities allowing for privilege escalation, which could enable malicious actors to gain elevated access levels within the system. These findings establish a critical baseline for security assessments and highlight the prevalence of these risk categories within the current skill landscape, informing resource allocation for mitigation efforts.
Mitigating Skill Risks: A Layered Security Approach
Capability-based permissions enforce the principle of least privilege by granting skills access only to specific resources and actions required for their designated function. This approach contrasts with traditional access control lists (ACLs) which define what a skill cannot do. Instead, capabilities are unforgeable tokens that explicitly authorize a skill to perform a defined operation on a specific resource. Consequently, even if a skill is compromised, the attacker’s access is limited to the capabilities held by that skill, preventing lateral movement and minimizing potential damage to the agent and its environment. This granular control is crucial for managing risk associated with the increasing complexity and number of skills utilized within an autonomous agent architecture.
Runtime sandboxing is a critical security measure that involves isolating skill execution within a restricted environment. This isolation prevents malicious code within a compromised or poorly-written skill from accessing or modifying the core agent system, sensitive data, or the external environment. By limiting a skill’s permissions and system access during runtime, sandboxing effectively contains potential damage and minimizes the attack surface. This approach differs from static analysis by focusing on behavior during execution, addressing threats that may not be detectable through code review alone. Implementing robust sandboxing requires virtualizing system resources and enforcing strict access controls, ensuring that skills operate within predefined boundaries.
Supply chain risk represents a significant threat to agent security, particularly regarding skills that utilize externally sourced scripts executed at runtime. Statistical analysis demonstrates a substantially higher vulnerability rate for these skills; skills incorporating executable scripts are 2.12 times more likely to contain vulnerabilities compared to skills relying solely on instructional content (p<0.001). This increased risk is attributable to the expanded attack surface introduced by third-party code and the potential for malicious code injection or compromised dependencies. Therefore, rigorous vetting and secure handling of external scripts are paramount to mitigating this threat.
Automated detection is crucial for effectively scaling security measures against evolving threats to AI agent skills. The developed SkillScan detection framework currently demonstrates a precision rate of 86.7%, indicating a low rate of false positives when identifying malicious or vulnerable skills. Complementing this, SkillScan achieves a recall rate of 82.5%, meaning it successfully identifies a substantial majority of actual threats present within the skill set. These metrics demonstrate the framework’s ability to both minimize disruptions caused by incorrect threat assessments and provide robust coverage against a range of potential vulnerabilities.
Understanding the Landscape of Skill Security Threats
Agent skill security faces considerable risk from specific vulnerabilities that target how these systems process instructions and access data. PromptInjection attacks manipulate the agent’s core directives, potentially hijacking its intended function, while DataExfiltration schemes enable unauthorized extraction of sensitive information the agent handles. Perhaps most critically, PrivilegeEscalation vulnerabilities allow malicious actors to gain elevated control over the agent, granting them access to restricted resources and capabilities. These aren’t merely theoretical concerns; they represent active threat vectors that can compromise the integrity and reliability of agent-driven systems, demanding proactive security measures to mitigate potential damage.
Successful attacks on agent skills frequently result in a cascade of security failures, beginning with unauthorized access to sensitive systems and data. Once compromised, agents can become conduits for data breaches, exposing confidential information to malicious actors. More subtly, but equally damaging, attackers can manipulate agent behavior, causing them to perform unintended actions, disseminate misinformation, or even sabotage critical processes. This behavioral manipulation extends beyond simple errors; compromised agents can be subtly steered towards decisions that benefit the attacker, potentially leading to financial loss, reputational damage, or the erosion of trust in automated systems. The consequences underscore the need for robust defenses against these multifaceted threats, safeguarding not only data but also the integrity of agent-driven operations.
A robust defense against emerging threats to agent skills necessitates a detailed comprehension of potential attack vectors. Recognizing how vulnerabilities like prompt injection, data exfiltration, and privilege escalation operate allows developers to proactively implement safeguards and build more resilient systems. Prioritizing security efforts, informed by this understanding, isn’t merely about patching existing flaws; it’s about anticipating future exploits and designing agents capable of detecting and mitigating malicious inputs. This proactive stance is particularly vital given that over a quarter of all agent skills currently exhibit at least one known vulnerability, highlighting the significant risk and the need for continuous monitoring and adaptation to maintain secure and reliable performance.
The potential consequences of compromised agent skills are remarkably broad, ranging from subtle operational inefficiencies to catastrophic financial losses and lasting damage to an organization’s public image. Current analyses reveal that over a quarter – 26.1% – of all agent skills exhibit at least one known vulnerability, a figure that highlights the pervasive nature of these threats and demands immediate attention. This isn’t merely a theoretical risk; successful exploitation can lead to data breaches, unauthorized actions, and manipulation of core functionalities, directly impacting business operations and eroding trust. The scale of affected skills underscores the urgency for proactive security measures, robust vulnerability management, and a fundamental shift toward building inherently secure agent capabilities.
The study’s findings regarding agent skill vulnerabilities – specifically, the prevalence of data exfiltration and privilege escalation – underscore a fundamental principle of system design. The research demonstrates that even seemingly innocuous skills can introduce significant risk, echoing Kernighan’s observation that “debugging is twice as hard as writing the code in the first place, so if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” This is not merely a matter of technical complexity, but of understanding how abstractions leak. The 26.1% vulnerability rate highlights how dependencies – in this case, the reliance on external agent skills – represent a true cost, demanding careful consideration of trust boundaries and potential failure modes. A robust architecture prioritizes simplicity and observability, ensuring that even complex systems remain understandable and manageable when vulnerabilities inevitably emerge.
Where Do We Go From Here?
The observed prevalence of vulnerabilities – over a quarter of examined agent skills exhibiting flaws – suggests a system built, perhaps inevitably, on a foundation of provisional trust. If the system survives on duct tape, it’s probably overengineered. The focus, naturally, will shift to automated mitigation, to ‘skill vetting’ pipelines. However, such solutions risk becoming brittle defenses against a moving target, addressing symptoms rather than the underlying fragility inherent in composing complex behaviors from loosely defined components.
The observed dominance of data exfiltration and privilege escalation vectors highlights a fundamental tension: agents are, by design, conduits of information and action. Securing these conduits after defining their purpose feels…optimistic. A more robust approach requires embedding security considerations not as an afterthought, but as a core principle of skill design, demanding a far more nuanced understanding of intent and potential misuse.
Modularity without context is an illusion of control. The long game isn’t simply about identifying bad skills; it’s about understanding how seemingly innocuous skills interact within a broader system, creating emergent behaviors that were never explicitly programmed. The next phase of research must move beyond isolated vulnerability assessments and embrace a holistic, systems-level view of agent behavior – before the architecture dictates outcomes that were never intended.
Original article: https://arxiv.org/pdf/2601.10338.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Mewgenics vinyl limited editions now available to pre-order
- Invincible Season 4 Episode 6 Release Date, Time, Where to Watch
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Solo Leveling’s New Manhwa Chapter Revives a Forgotten LGBTQ Story After 2 Years
- ‘Timur’ Trailer Sees Martial Arts Action Collide With a Real-Life War Rescue
2026-01-16 14:31