Author: Denis Avetisyan
A new study reveals how the proliferation of AI-written content is quietly eroding the quality and diversity of online information retrieval.
Researchers identify ‘Retrieval Collapse’, a failure mode where AI-polluted search results mask a loss of source diversity and enable the spread of misinformation.
The increasing reliance on web-sourced evidence for information retrieval creates a paradoxical vulnerability as the content itself becomes increasingly machine-generated. This paper, ‘Retrieval Collapses When AI Pollutes the Web’, characterizes this emerging issue as ‘Retrieval Collapse’, a two-stage failure mode where AI-generated content progressively dominates search results, initially masking a decline in source diversity and ultimately enabling the infiltration of misinformation. Our analysis reveals that even moderate contamination-around 67%-can lead to over 80% exposure to synthetic content, while LLM-based rankers demonstrate varying capabilities in suppressing adversarial attacks. Will retrieval-aware strategies prove sufficient to break this potential self-reinforcing cycle of quality decline in web-grounded systems?
The Erosion of Truth: Navigating Retrieval Collapse
Retrieval Augmented Generation, or RAG, has rapidly become a cornerstone of modern large language model applications, enabling these systems to access and incorporate information from external knowledge sources. However, this reliance introduces a significant vulnerability: data contamination. As synthetic content-text generated by other language models-proliferates online, it increasingly appears in the very datasets RAG systems utilize for retrieval. This creates a precarious cycle where a model retrieves and reinforces its own outputs, or those of similar models, rather than grounding responses in verifiable facts. The consequence is a degradation of information quality and a heightened risk of hallucination, as the system effectively learns to cite itself, diminishing the benefits of external knowledge and threatening the trustworthiness of generated content.
The proliferation of machine-generated content presents a growing risk to information retrieval systems. As Large Language Models (LLMs) increasingly populate the internet with synthetic text, these outputs can quickly dominate search results, creating a self-reinforcing feedback loop. This occurs because LLMs, when prompted for information, often retrieve and re-synthesize content from other LLMs, effectively amplifying machine-generated noise. Consequently, searches may return a cascade of LLM-derived content, obscuring or entirely replacing original sources and factual information. This phenomenon, termed ‘Retrieval Collapse’, threatens the reliability of LLM outputs and highlights the urgent need for robust mechanisms to identify and filter synthetic content from search indices, ensuring access to authentic and verifiable data.
Retrieval collapse represents a significant threat to the trustworthiness of large language model applications. As LLMs increasingly rely on external knowledge sources through retrieval-augmented generation, the potential for synthetic – and potentially inaccurate – content to pollute those sources creates a dangerous feedback loop. When an LLM encounters its own generated content during retrieval, it effectively reinforces and validates falsehoods, leading to a degradation of factual accuracy and a loss of reliability in its outputs. This isn’t merely a matter of occasional errors; unchecked retrieval collapse can systematically erode the LLM’s ability to discern truth, ultimately undermining its value as a source of information and potentially propagating misinformation at scale. The phenomenon highlights the critical need for robust mechanisms to detect and filter synthetic data within retrieval systems, ensuring that LLMs are grounded in verifiable, external knowledge.
The Two Faces of Degradation: Dominance and Corruption
The initial phase of search result degradation, termed ‘Dominance and Homogenization’, is characterized by a significant increase in the volume of content generated by artificial intelligence. This proliferation is enabled by the relative ease with which high-quality, Search Engine Optimized (SEO) content can be produced using large language models. While initially appearing beneficial due to its grammatical correctness and relevance to search queries, this dominance leads to a homogenization of search results, reducing diversity in perspectives and sources. The sheer volume of AI-generated content effectively crowds out original human-authored material, not necessarily due to lower quality, but due to its statistical prevalence in the indexed web.
The proliferation of easily generated Search Engine Optimized (SEO) content is directly attributable to large language models, such as GPT-5. These models require minimal user input to produce text that conforms to established SEO principles, including keyword density, content length, and structural formatting. This low barrier to entry allows for the rapid creation of high volumes of content targeting specific search queries, significantly reducing the cost and effort previously required for content creation. Consequently, a single user or automated system can generate and deploy a substantial quantity of SEO-optimized material, contributing to increased competition within search rankings and a potential shift in content quality.
The ‘Pollution and System Corruption’ stage represents a degradation of search results through the deliberate introduction of adversarial content or, more commonly, a surge in low-quality material. This differs from the initial ‘Dominance’ phase by actively exploiting system vulnerabilities or simply overwhelming ranking signals with content designed to game the system, rather than providing genuinely useful information. Such content may include spun articles, automatically generated text lacking factual accuracy, or malicious code embedded within webpages. The proliferation of this ‘polluted’ data diminishes the efficacy of retrieval algorithms, making it increasingly difficult to distinguish between reliable and unreliable sources and ultimately degrading the overall quality of search results.
The progression from initial AI-generated content dominance to systemic retrieval failure occurs in two identifiable stages. Initially, high volumes of algorithmically-produced content, while superficially coherent, introduce a subtle but pervasive bias due to the inherent limitations and training data of the underlying models. As actors realize the ease of content creation, this is compounded by the introduction of intentionally manipulative or low-quality content designed to exploit search algorithms. This deliberate ‘pollution’ of the information ecosystem erodes the reliability of retrieval systems, moving beyond simple bias toward a state of systemic corruption where accurate information becomes increasingly difficult to locate, regardless of query intent.
Measuring the Fracture: Contamination and Accuracy
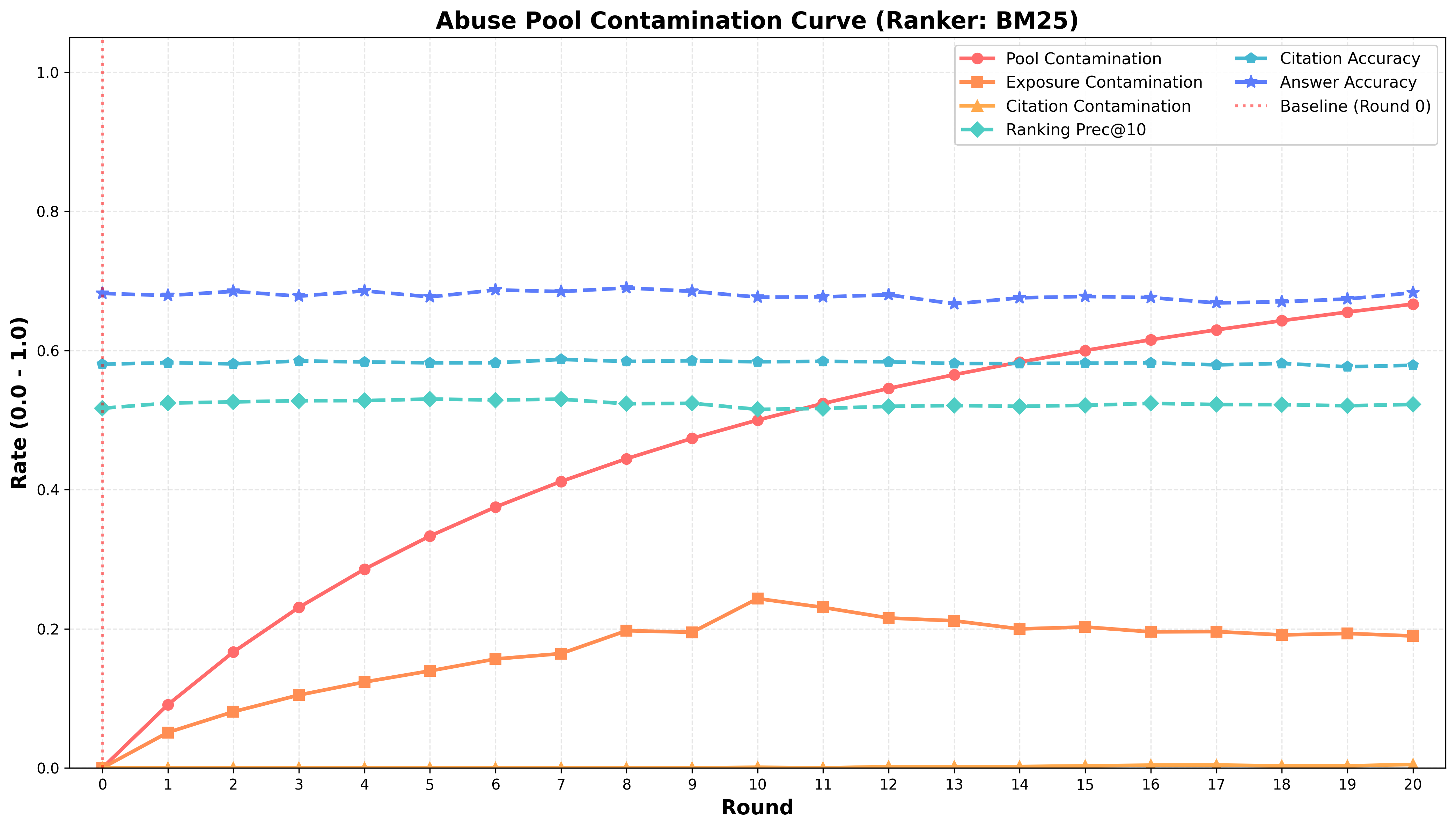
The ‘Pool Contamination Rate’ represents the proportion of AI-generated content within the entire corpus of retrieved documents used for evaluation, while the ‘Exposure Contamination Rate’ measures the percentage of AI-generated content actually presented to users or models during a retrieval process. These metrics are calculated by identifying AI-generated content through watermarking or other detection techniques. A higher ‘Pool Contamination Rate’ does not automatically equate to a similarly high ‘Exposure Contamination Rate’ as ranking algorithms may prioritize non-AI content; however, certain ranking behaviors can amplify the presence of AI-generated content in user-facing results. Both rates are crucial for assessing the influence of synthetic data on information retrieval systems and the potential for biased or inaccurate information to be presented to end-users.
The relationship between ‘Pool Contamination Rate’ and ‘Exposure Contamination Rate’ demonstrates amplification in search engine optimization (SEO) contexts. A ‘Pool Contamination Rate’ of 67%, representing the proportion of AI-generated content within the entire retrieved content pool, can result in an ‘Exposure Contamination Rate’ exceeding 80%. This occurs because SEO algorithms prioritize ranking signals, potentially amplifying the visibility of contaminated content and increasing the likelihood that users are exposed to AI-generated information, even if it comprises a minority of the overall content pool. This disparity highlights that contamination within the initial retrieval set is not linearly proportional to user exposure, indicating a significant amplification effect during ranking and presentation.
Large Language Models (LLMs) generate responses based on information retrieved from external sources; therefore, the accuracy of those responses is directly dependent on the quality of the retrieved context. Contamination rates – measuring the prevalence of AI-generated content within retrieval results – directly correlate to ‘Answer Accuracy’ because LLMs process this contaminated data as factual. Higher ‘Exposure Contamination Rate’ and ‘Pool Contamination Rate’ values introduce increased probabilities of LLMs utilizing, and subsequently presenting, inaccurate or fabricated information. This reliance on retrieved context means that even a relatively low level of contamination in the retrieval pool can significantly degrade the factual correctness of the LLM’s output, making ‘Answer Accuracy’ a key metric for evaluating the trustworthiness of LLM-driven systems.
The ‘Citation Contamination Rate’ quantifies the proportion of citations generated by Large Language Models (LLMs) that point to other AI-generated content as sources. This metric is significant because a high rate suggests LLMs may be reinforcing information originating from synthetic data, potentially creating an echo chamber where AI-generated content is cited and re-cited without grounding in verifiable, human-created sources. This circular dependency can amplify inaccuracies or biases present in the initial synthetic data and limit the diversity of information presented to users. Tracking this rate is crucial for understanding the self-referential tendencies of LLMs and assessing the reliability of their outputs.
Precision@10 is a metric used to evaluate the factual correctness of the top 10 results returned by a retrieval system. It calculates the proportion of those 10 results that are factually accurate. Recent evaluations demonstrate that LLM Rankers achieve a Precision@10 score of 0.6251, indicating that approximately 62.51% of the top 10 retrieved results are factually correct when using an LLM-based ranking system. In comparison, the traditional BM25 algorithm achieves a Precision@10 score of 0.6125, representing approximately 61.25% factual correctness in the top 10 results. This difference suggests that LLM Rankers offer a marginal improvement in delivering factually accurate information within the initial set of retrieved results.
A Path to Resilience: Defensive Ranking
Defensive Ranking is a retrieval strategy designed to preempt Retrieval Collapse by explicitly optimizing for three key characteristics: relevance, factuality, and provenance. Unlike traditional methods, this approach doesn’t solely focus on keyword matching; instead, it prioritizes retrieving content that is not only pertinent to the query but also demonstrably accurate and traceable to a reliable source. By actively assessing these factors during the ranking process, the system aims to reduce the inclusion of misleading or fabricated information in the retrieved results, thereby bolstering the trustworthiness of downstream LLM applications and minimizing the potential for generating incorrect or unsupported outputs.
Traditional ranking functions, such as BM25, rely on keyword frequency and inverse document frequency, offering limited capacity for semantic understanding and nuanced assessment of content quality. LLM-based rankers, or LLM Rankers, address these limitations by utilizing large language models to evaluate retrieved documents based on relevance, factuality, and provenance. This allows for a more sophisticated analysis of content beyond simple keyword matching, considering contextual understanding and the relationships between concepts. The LLM Ranker assigns scores based on these factors, enabling the retrieval system to prioritize content that is not only relevant to the query but also demonstrably accurate and sourced appropriately, thereby improving the overall quality and reliability of the retrieved results.
The implementation of an LLM Judge significantly improves the reliability of retrieval systems by providing automated correctness assessment of both retrieved documents and the answers generated based on them. This judge operates by evaluating the factual consistency between the retrieved content, the generated answer, and a provided source document, allowing for a quantifiable metric of accuracy. Unlike traditional methods relying on keyword matching or heuristic rules, the LLM Judge utilizes natural language understanding to identify semantic inaccuracies and logical inconsistencies. This process allows for the identification and filtering of incorrect or misleading information, ultimately leading to more trustworthy and dependable outputs from large language models.
Prioritizing relevance, factuality, and provenance in retrieval systems demonstrably improves output integrity and resilience. Evaluations show a Micro Correct Rate increase from 51.69% using the original retrieval pool to 66.79% with an SEO-optimized pool. Furthermore, this approach mitigates the impact of deliberately misleading or adversarial content; the Abuse Pool, containing such content, achieved a Micro Correct Rate of 38.44% when evaluated using this defensive ranking system, indicating a substantial reduction in the propagation of incorrect information compared to baseline performance.
The study of Retrieval Collapse reveals a systemic fragility within information ecosystems, mirroring the complexities of interconnected systems. As AI-generated content floods the web, search results become increasingly homogenous, initially appearing comprehensive but ultimately obscuring a critical loss of source diversity. This phenomenon echoes Hilbert’s assertion: “We must be able to answer the question: what are the prerequisites for the existence of a mathematical problem?” – a parallel can be drawn to information retrieval; what are the prerequisites for a reliable answer? The erosion of diverse evidence, as detailed in the paper, demonstrates that a seemingly functional system can conceal underlying vulnerabilities. Good architecture is invisible until it breaks, and only then is the true cost of decisions visible.
The Fading Signal
The observation of ‘Retrieval Collapse’ isn’t merely a technical curiosity; it’s a predictable symptom of optimizing for a locally measurable variable – keyword density, link velocity – while ignoring the emergent properties of the system as a whole. The web was never designed to resist coordinated, synthetic amplification, and the current architecture reveals its inherent fragility. Attempts to ‘fix’ retrieval with increasingly complex filtering or ranking functions will likely be transient bandages on a structural wound. The true cost of freedom, in this context, is the relentless proliferation of indistinguishable noise.
Future work must move beyond detection and focus on resilience. Simply identifying AI-generated content after it has saturated the index is an exercise in futility. A more fruitful avenue lies in exploring architectures that prioritize provenance and evidence diversity – systems that inherently reward signals of genuine creation and penalize synthetic redundancy. This necessitates a re-evaluation of the very metrics used to assess information quality; relevance alone is insufficient.
The current trajectory suggests a future where search doesn’t find information, but rather recycles it – an echo chamber constructed from the ghosts of prior content. Good architecture, in this instance, would be invisible until it breaks-until the signal fades completely, leaving only the static of algorithmic consensus. The problem isn’t that the system is being gamed; it’s that the rules of the game incentivize exactly this outcome.
Original article: https://arxiv.org/pdf/2602.16136.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- How to Get to the Undercoast in Esoteric Ebb
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- All Itzaland Animal Locations in Infinity Nikki
- Gold Rate Forecast
- ‘Stop! That! Train!’ Trailer Reveals New RuPaul Action Comedy
- Fox McCloud Actor Announced as Glen Powell Joins The Super Mario Galaxy Movie
- HBO’s Harry Potter Is Already Breaking My Heart
2026-02-20 03:54