Author: Denis Avetisyan
A new paradigm shifts intelligence away from centralized servers and onto individual devices, enabling continuous learning and real-time adaptation.
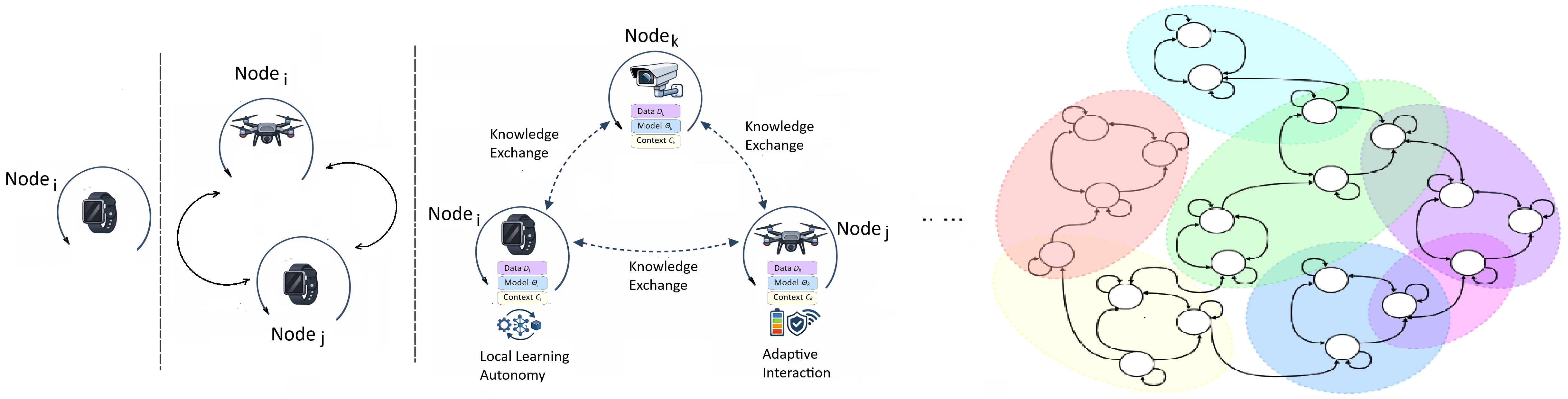
Node Learning provides a framework for adaptive, decentralized, and collaborative network edge AI, addressing the limitations of traditional centralized approaches.
The increasing reliance on centralized intelligence for edge applications creates vulnerabilities related to data transmission, latency, and scalability. This paper introduces ‘Node Learning: A Framework for Adaptive, Decentralised and Collaborative Network Edge AI’, a paradigm shift wherein intelligence is distributed across edge nodes that learn continuously and collaborate opportunistically. By enabling localized model maintenance and knowledge exchange, Node Learning moves beyond reliance on central aggregation, fostering resilience and adaptability in heterogeneous environments. Will this decentralized approach unlock a new era of robust and efficient edge AI, capable of thriving in resource-constrained and dynamic contexts?
Beyond Centralized Intelligence: Embracing the Node
Conventional machine learning systems often demand the consolidation of data into central servers for processing, a practice that increasingly presents significant challenges. This centralization creates performance bottlenecks as data volumes surge, hindering real-time applications and scalability. More critically, it raises substantial privacy concerns, as sensitive information must be transmitted and stored in a single location, becoming a prime target for breaches and misuse. The inherent limitations of this model are becoming especially pronounced with the proliferation of data-generating devices – from smartphones and IoT sensors to autonomous vehicles – all contributing to an unsustainable strain on centralized infrastructure and escalating risks to individual privacy. Consequently, a fundamental rethinking of machine learning architectures is necessary to accommodate the demands of a data-rich and privacy-conscious future.
The proliferation of pervasive computing and edge devices-from smart sensors and wearables to autonomous vehicles and industrial IoT-demands a fundamental rethinking of traditional, centralized intelligence systems. These devices generate vast quantities of data at the network edge, but transmitting all of it to a central server for processing creates significant latency, bandwidth constraints, and privacy vulnerabilities. A shift towards distributed intelligence addresses these challenges by bringing computation closer to the data source, enabling real-time decision-making and reducing reliance on constant connectivity. This distributed approach not only enhances responsiveness and efficiency but also bolsters data security by minimizing the need for centralized data storage and processing, ultimately unlocking the full potential of a truly interconnected world.
Node Learning represents a fundamental departure from conventional machine learning by distributing intelligence directly to the devices-the ‘nodes’-that generate and utilize data. This decentralized approach allows each node to learn and adapt independently, responding to local conditions without constant communication with a central server. Instead of funneling all information to a single point, nodes cooperate opportunistically, sharing insights only when beneficial, thereby minimizing bandwidth requirements and enhancing privacy. The resulting network fosters resilience and scalability, as the failure of one node doesn’t cripple the entire system, and new nodes can seamlessly integrate without requiring extensive retraining of a central model. Ultimately, Node Learning aims to unlock the full potential of edge computing and the Internet of Things by enabling a more efficient, robust, and privacy-preserving intelligent infrastructure.
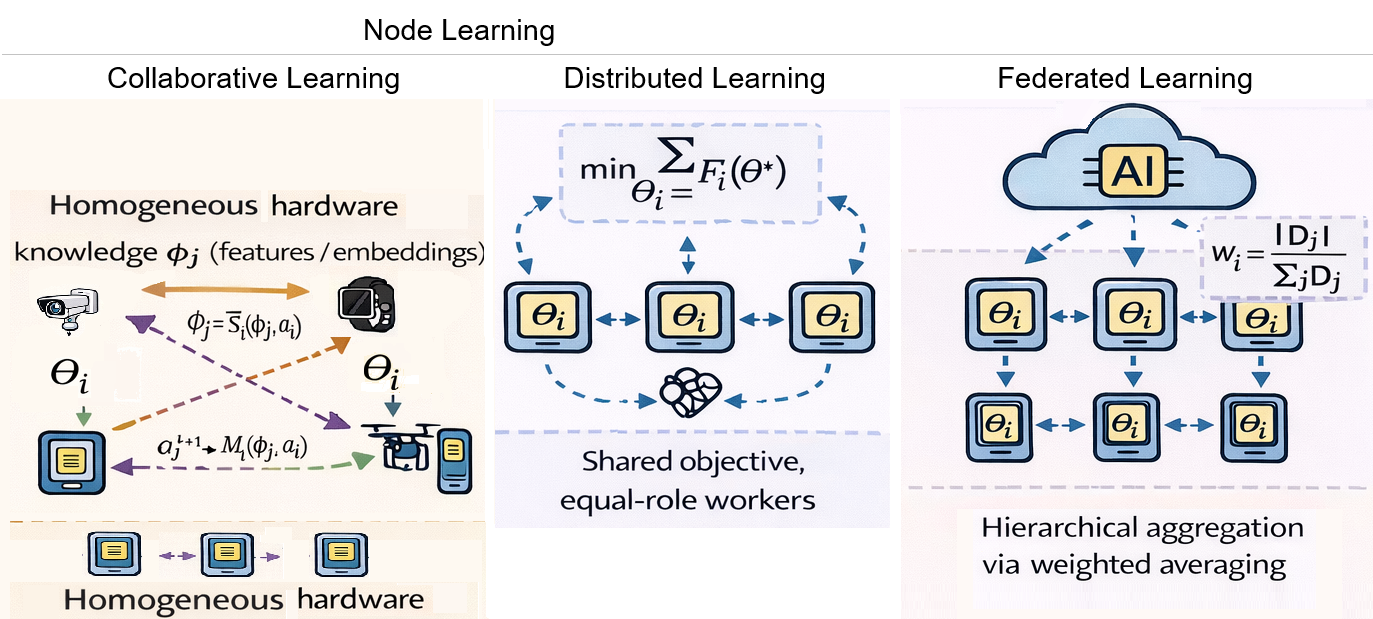
Decentralized Learning in Action: Mechanisms for Distribution
Federated Learning (FL) represents a distributed machine learning approach designed to train algorithms on a decentralized dataset residing on multiple edge devices or servers. While shifting computation to the data source – addressing data privacy and reducing communication costs – FL fundamentally retains a central server for model aggregation and coordination. During each training round, selected devices perform local model updates using their respective data. These updates – typically model weights or gradients – are then transmitted to the central server, which aggregates them to create an improved global model. This global model is subsequently distributed back to the participating devices, initiating the next round of training. The central server, therefore, acts as a critical component for parameter averaging and maintaining a consistent global model, differentiating FL from fully decentralized approaches.
Decentralized Learning and Gossip-based Learning represent a shift from traditional federated learning by eliminating the need for a central server to coordinate model updates. In these approaches, individual peer devices directly exchange model parameters or gradients with a subset of other peers in a network. This peer-to-peer communication, often referred to as “gossiping,” facilitates the aggregation of knowledge across the network without reliance on a single point of failure or a central bottleneck. The process involves each device periodically sharing its current model state with randomly selected neighbors, who then integrate this information into their own models. This iterative exchange continues until a consensus or desired level of accuracy is achieved, resulting in a globally informed model distributed across the network.
Decentralised Stochastic Gradient Descent (DSGD) operates by enabling individual nodes within a network to compute gradients based on their local data. These gradients, representing the direction of steepest descent for the loss function, are then exchanged with neighboring nodes. Each node updates its model parameters using the received gradients, effectively averaging the information from its peers. This process avoids the need for a central server to aggregate gradients; instead, consensus is achieved through iterative peer-to-peer communication. The core update rule remains consistent with standard Stochastic Gradient Descent: \theta_{t+1} = \theta_t - \eta \nabla J(\theta_t) , where η is the learning rate and \nabla J is the estimated gradient, but the gradient computation and aggregation are performed in a distributed manner. This distributed approach enhances robustness and scalability compared to centralized methods, as the failure of a single node does not necessarily impede the learning process.
Tiny Federated Learning (TFL) adapts federated and decentralized learning techniques for deployment on devices with limited computational resources, memory, and energy availability. This is achieved through model compression, reduced communication overhead, and optimized algorithms. A primary goal of TFL is to minimize Energy per Iteration (EPI), a metric quantifying the energy consumed for each round of model updates, compared to traditional centralized learning approaches which require data transmission to a central server. Techniques employed include parameter quantization, sparsification, and the use of lightweight model architectures to reduce both computational and communication costs, enabling on-device learning and inference with improved energy efficiency.
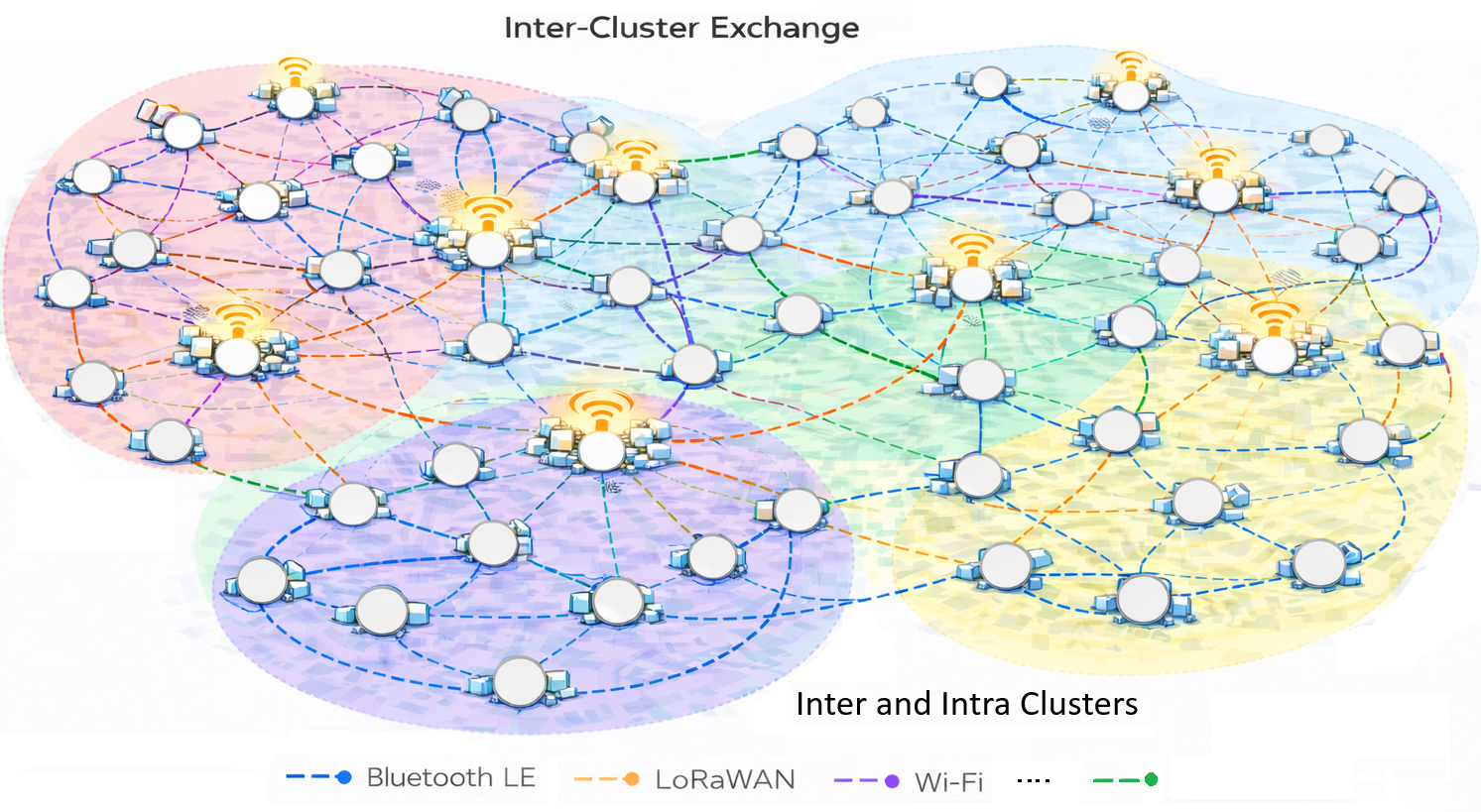
Empowering the Nodes: Local Reasoning and Adaptive Response
Node Language Models (NLMs) facilitate on-device semantic understanding and inference by deploying language processing capabilities directly onto individual edge nodes. These models, typically smaller and more efficient than centralized counterparts, analyze locally-sourced data to extract meaning and identify relevant information without requiring constant communication with a central server. This localized processing enables real-time interpretation of data streams, supporting applications requiring immediate responses and minimizing dependence on network connectivity. The implementation of NLMs involves techniques such as knowledge distillation and model pruning to reduce computational demands while preserving essential reasoning capabilities, allowing nodes to perform tasks like intent recognition, anomaly detection, and data summarization independently.
Contextual Adaptation within distributed node networks involves the dynamic modification of learning parameters based on locally observed conditions and environmental variables. This process aims to minimize Adaptation Latency (AL), defined as the time required for a node to adjust its behavior to changing circumstances. Adaptations can include adjustments to learning rates, model weights, or even the selection of algorithms, all determined by real-time data gathered from the node’s immediate surroundings. Successful contextual adaptation requires efficient sensing of local conditions, rapid processing of that data, and a mechanism for implementing behavioral changes without disrupting core functionality. Minimizing AL is crucial for maintaining responsiveness and accuracy in dynamic and unpredictable environments.
Opportunistic Collaboration within a node network prioritizes selective data exchange to enhance both accuracy and efficiency. Rather than continuous, comprehensive broadcasting, nodes engage in focused communication only when statistically relevant information can be gained, thereby minimizing unnecessary byte transfer. This approach improves Collaboration Efficiency (CE) – measured by the increase in accuracy achieved per byte exchanged – and contributes to network robustness by reducing bandwidth congestion and computational load. The system dynamically assesses the potential benefit of sharing data based on local observations and predictive models, facilitating cooperation only when it demonstrably improves overall performance and avoids redundant information transfer.
Edge AI deployment is directly facilitated by localized adaptations within node language models, shifting computational workloads from centralized servers to the data source itself. This distributed processing minimizes data transmission requirements and associated network latency, enabling real-time or near real-time inference and decision-making. By performing analysis at the edge, systems can respond more quickly to dynamic conditions and reduce reliance on consistent network connectivity, increasing overall system responsiveness and reliability. Furthermore, localized processing reduces the bandwidth demands on core networks and lowers energy consumption associated with data transfer.
Architecting the Future: System Considerations and Hardware Innovation
In-memory computing represents a paradigm shift in data processing, drastically reducing the energy expenditure associated with traditional von Neumann architectures. These systems minimize data movement – the primary bottleneck in many computations – by performing calculations directly within the memory itself, rather than transferring data between the processor and memory. This approach is particularly impactful for resource-constrained nodes, such as those found in edge computing or IoT deployments, where power efficiency and reduced latency are paramount. By eliminating frequent data transfers, in-memory computing not only lowers energy consumption but also accelerates processing speeds, enabling more complex algorithms to run effectively on devices with limited power budgets and computational resources. The benefits extend to increased system responsiveness and the potential for real-time data analysis at the network edge, fostering innovation in applications ranging from environmental monitoring to autonomous robotics.
Neuromorphic computing represents a paradigm shift in computer architecture, moving away from the traditional von Neumann model to emulate the structure and function of the human brain. Unlike conventional systems that separate processing and memory, neuromorphic chips integrate these functions, dramatically reducing energy consumption and latency. These systems utilize spiking neural networks (SNNs) – algorithms that more closely mimic biological neurons – and often employ analog or mixed-signal circuits to achieve greater efficiency. Beyond lower power requirements, neuromorphic architectures exhibit inherent robustness; the distributed nature of processing and synaptic plasticity allow them to tolerate noisy inputs and component failures, making them particularly well-suited for edge devices and applications demanding reliable operation in unpredictable environments. This biologically-inspired approach promises not only energy savings but also the potential for advanced cognitive capabilities, including adaptive learning and real-time pattern recognition.
The advent of RISC-V Neural Processing Units (NPUs) represents a significant shift towards adaptable and power-efficient artificial intelligence at the network edge. Unlike application-specific integrated circuits (ASICs) with fixed functionality, these NPUs offer a programmable architecture, allowing developers to customize the hardware to optimally execute diverse neural network models. This flexibility is particularly crucial in resource-constrained environments, where tailoring processing to specific tasks minimizes energy consumption and maximizes performance. By leveraging the open-source RISC-V instruction set architecture, these NPUs facilitate innovation and enable the creation of specialized accelerators for applications ranging from image recognition and natural language processing to anomaly detection and predictive maintenance, effectively bringing intelligent computation closer to the data source.
Collaborative learning strategies are increasingly vital for distributed edge computing systems, allowing for enhanced intelligence and operational stability. Rather than each node operating in isolation, this approach facilitates selective communication, where nodes share learned information only when it demonstrably improves the collective understanding – a process that minimizes bandwidth usage and computational overhead. This targeted exchange of knowledge not only accelerates learning across the system, but also significantly boosts the Resilience Ratio (RR) , a key metric for evaluating robustness. A higher RR indicates the system’s ability to maintain functionality even when faced with node failures or intermittent communication disruptions, ensuring continued operation and reliable performance in challenging environments. Consequently, collaborative learning transforms a network of independent devices into a cohesive, adaptable, and remarkably resilient intelligent system.
The pursuit of Node Learning, as detailed in the paper, echoes a fundamental principle of robust systems: that intelligence needn’t reside in a central authority, but can emerge from the interactions of simpler, distributed components. This mirrors Ada Lovelace’s observation: “The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform.” The framework’s emphasis on opportunistic collaboration and continual learning at the network edge isn’t about creating wholly independent intelligence within each node, but rather about orchestrating a collective intelligence from a network of nodes, each executing instructions and adapting within its context. A fragile system seeks centralized control; a resilient one embraces decentralized adaptation.
Where Do We Go From Here?
The promise of Node Learning – a genuinely distributed intelligence – rests on a precarious balance. The current work establishes a foundational architecture, yet the devil, as always, resides in the systemic details. The pursuit of opportunistic collaboration, while elegant in theory, demands a deeper understanding of trust propagation and conflict resolution within these edge networks. If the system survives on duct tape and ad-hoc solutions to these issues, it’s likely overengineered, attempting to force a centralized logic onto a fundamentally decentralized substrate.
A critical limitation lies in defining – and more importantly, limiting – the scope of ‘context’. Context-awareness, without rigorous boundaries, quickly devolves into an infinite regression of dependencies. The challenge isn’t merely acquiring contextual information, but determining which signals are genuinely informative and discarding the noise. Furthermore, the continuous learning aspect, while vital, introduces the risk of catastrophic forgetting and drift. A node’s individual adaptation must be tempered by mechanisms for preserving a shared, coherent understanding of the environment.
Modularity, often touted as a panacea, is an illusion of control without a corresponding appreciation for emergence. True resilience won’t come from perfectly isolated components, but from the complex interplay between them. The next step isn’t simply to build more nodes, but to explore the principles governing their collective behavior – to shift the focus from individual intelligence to systemic intelligence.
Original article: https://arxiv.org/pdf/2602.16814.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- How to Get to the Undercoast in Esoteric Ebb
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Warframe Voruna Prime access begins on April 8 for all platforms, new deluxe cosmetic Warframe skins revealed
- All Itzaland Animal Locations in Infinity Nikki
- Zendaya’s 4 Big 2026 Movies Could Beat Brie Larson’s Box 2019 Office Record
- Dakota County’s plan to end hunger involves locking mayors in escape rooms
2026-02-22 01:28