Author: Denis Avetisyan
New research reveals a fundamental constraint on how neural networks store information, explaining why they falter when faced with complex, overlapping memories.
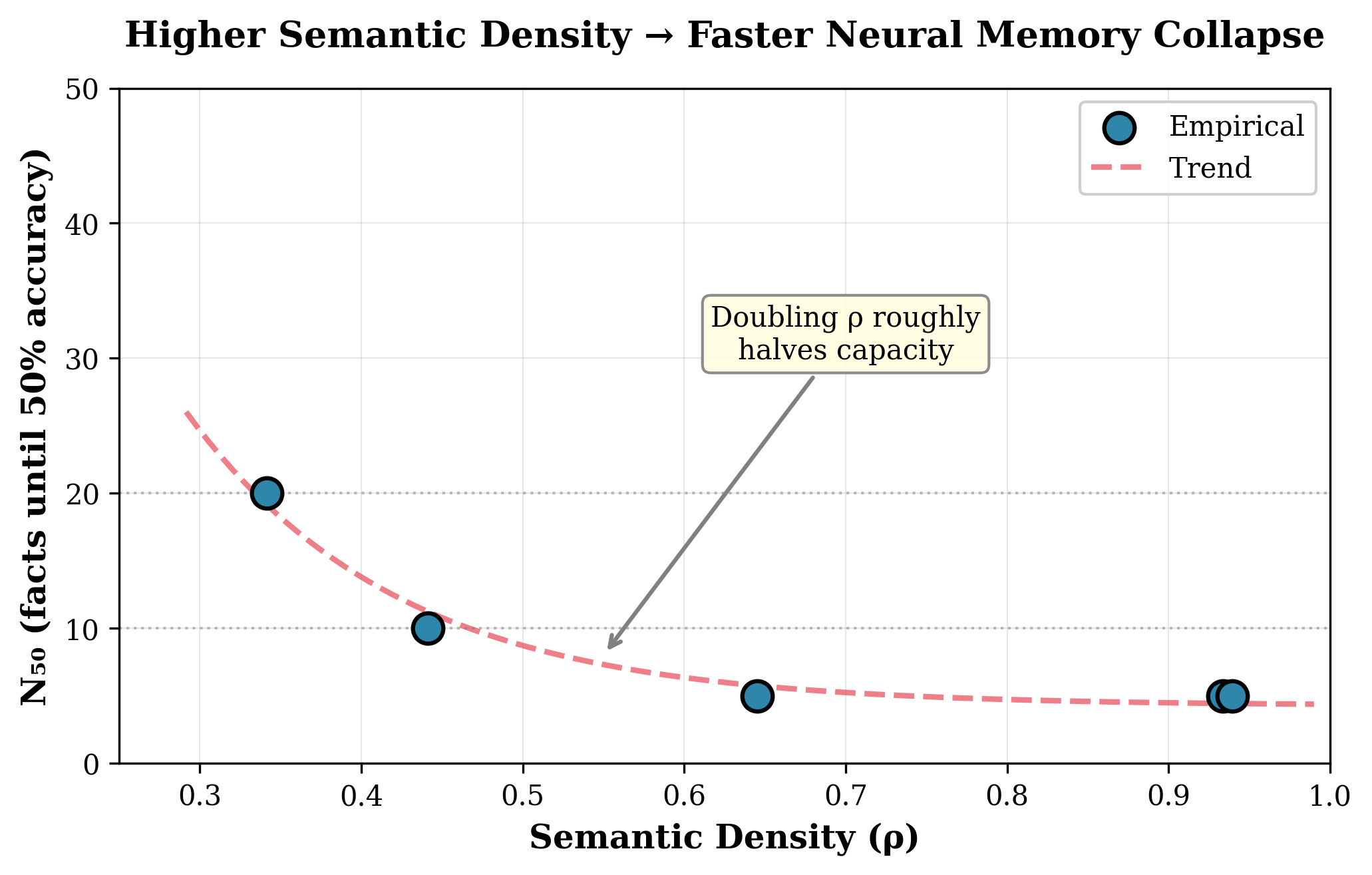
A geometric incompatibility between continuous vector storage and the need for discrete addressing limits the capacity and reliability of neural memory systems.
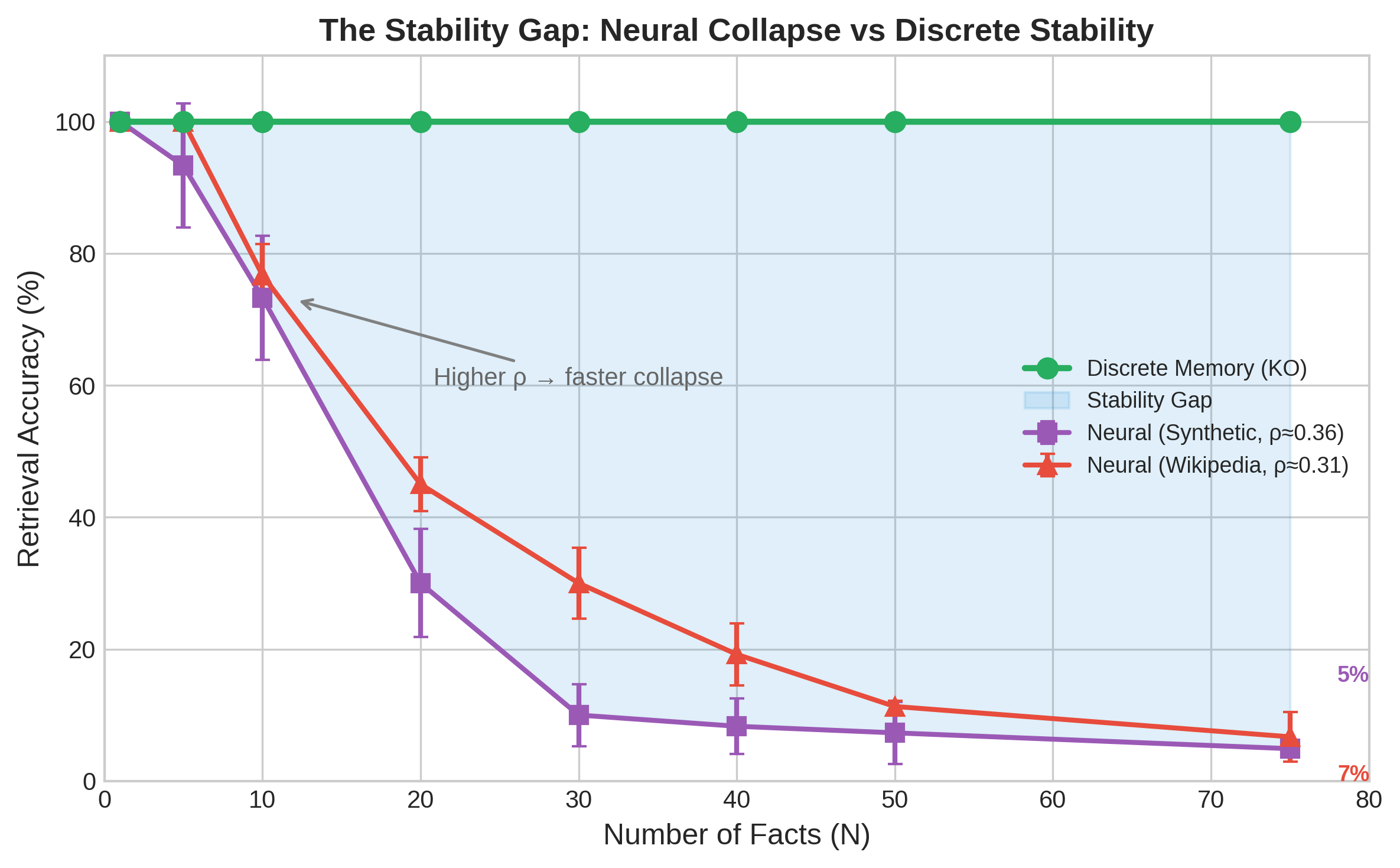
While the brain adeptly stores specific memories without corrupting general knowledge, current artificial neural networks struggle with this fundamental distinction. In ‘Mind the Gap: Why Neural Memory Fails Under Semantic Density’, we identify a ‘Stability Gap’ wherein continuous parameter-based memory rapidly degrades with even modest numbers of semantically related facts-collapsing to near-random accuracy with as few as \mathcal{N}=5 facts at high semantic density. This failure, formalized as the Orthogonality Constraint, arises from inherent interference when storage and retrieval share the same substrate, even with perfect attention and unlimited context. Does achieving reliable AI memory necessitate a complementary learning architecture-separating discrete fact storage from the generalization capabilities of neural weights- mirroring the brain’s own bicameral design?
The Fragility of Memory in Artificial Minds
Contemporary artificial intelligence, notably large language models, fundamentally stores information within the adjustable parameters – the ‘weights’ – of interconnected neural networks. This approach, while enabling impressive feats of pattern recognition and text generation, presents inherent vulnerabilities regarding knowledge retention. Unlike traditional computer memory which stores data in discrete locations, neural networks distribute information across countless connections, making them susceptible to interference – where new learning overwrites existing memories – and capacity limits. As the volume of stored knowledge increases, the network’s ability to reliably retrieve specific facts diminishes, effectively creating a bottleneck in long-term memory. This isn’t a matter of simply adding more storage, but a fundamental constraint of how these systems learn and recall, highlighting a critical challenge in achieving truly robust and scalable artificial intelligence.
Neural networks struggle to retain information as the relationships between learned concepts become increasingly intricate. This phenomenon, linked to the orthogonality constraint, dictates that similar concepts require distinct neural representations; however, as semantic density rises-meaning concepts are closely related-these representations inevitably overlap, leading to interference. Research demonstrates this fragility: while discrete, unrelated facts can be stored with 100% accuracy, the recall rate of a neural network plummets to approximately 1.3% when attempting to reliably retrieve just 75 interconnected facts. This sharp decline suggests that current neural memory systems are fundamentally limited in their capacity to manage complex, semantically rich knowledge, highlighting a critical gap between the way artificial and biological memories function.
Despite advancements in neural network architecture, attempts to enhance dynamic knowledge updates ironically diminish the reliability of stored information. Techniques such as Fast-Weight Associative Memory and Context Window Attention, designed to allow for flexible learning and adaptation, actually worsen the inherent limitations of neural memory. Research demonstrates a substantial ‘stability gap’ – a staggering 98.7 percentage point drop in accuracy – when these methods are used to recall even a modest 75 facts. This signifies that while these systems can rapidly incorporate new data, they do so at the expense of previously stored knowledge, highlighting a critical trade-off between plasticity and stability in current artificial neural networks and underscoring the need for novel approaches to knowledge representation and retention.
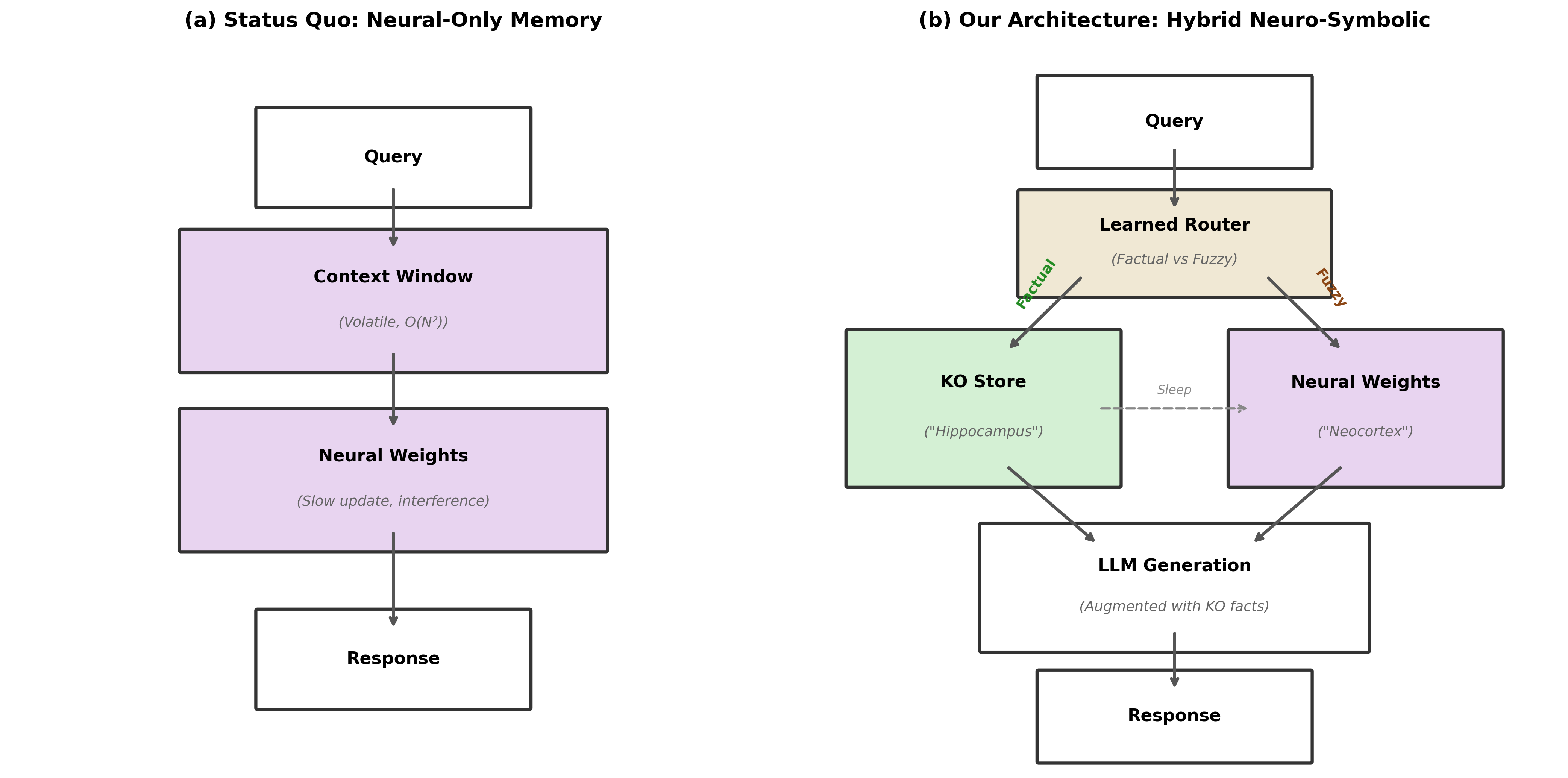
Discrete Memory: A Foundation for Reliable Knowledge
Unlike neural networks which represent knowledge through weighted connections prone to interference – where learning new information can overwrite or distort existing memories – discrete memory systems utilize distinct data structures to store individual facts. This separation fundamentally addresses the issue of interference by isolating each piece of information. Each fact is encoded and stored as a discrete unit, preventing updates to one fact from inadvertently altering others. This approach is analogous to storing data in separate files rather than a single, interconnected database, ensuring that retrieval of one fact does not depend on the state of any other, and allowing for more predictable and reliable access to stored information.
Orthogonality in discrete memory systems enables high-density knowledge storage by minimizing data collisions and interference. This is achieved through the use of independent data structures – each fact is stored in a location that does not overlap with any other, ensuring that retrieval of one fact does not impact access to others. Consequently, recall accuracy remains constant, and perfect retrieval is maintained regardless of the total number of stored facts, a significant advantage over associative or neural networks which often experience performance degradation with increasing data volume. This principle allows for a linear scaling of storage capacity without compromising data integrity or access speed.
Effective implementation of discrete memory systems necessitates more than a structural shift from neural networks; robust design principles are crucial for sustained performance. Data integrity must be actively maintained through error detection and correction mechanisms, preventing corruption or loss of stored facts. Accessibility relies on efficient indexing and retrieval algorithms, ensuring rapid location of specific data points within the discrete knowledge base. Furthermore, a well-defined schema for knowledge representation is required to standardize data formats and facilitate interoperability, while ongoing maintenance and updates are essential to address evolving information and system requirements. Without these considerations, the potential benefits of discrete memory – denser storage and accurate recall – cannot be fully realized.
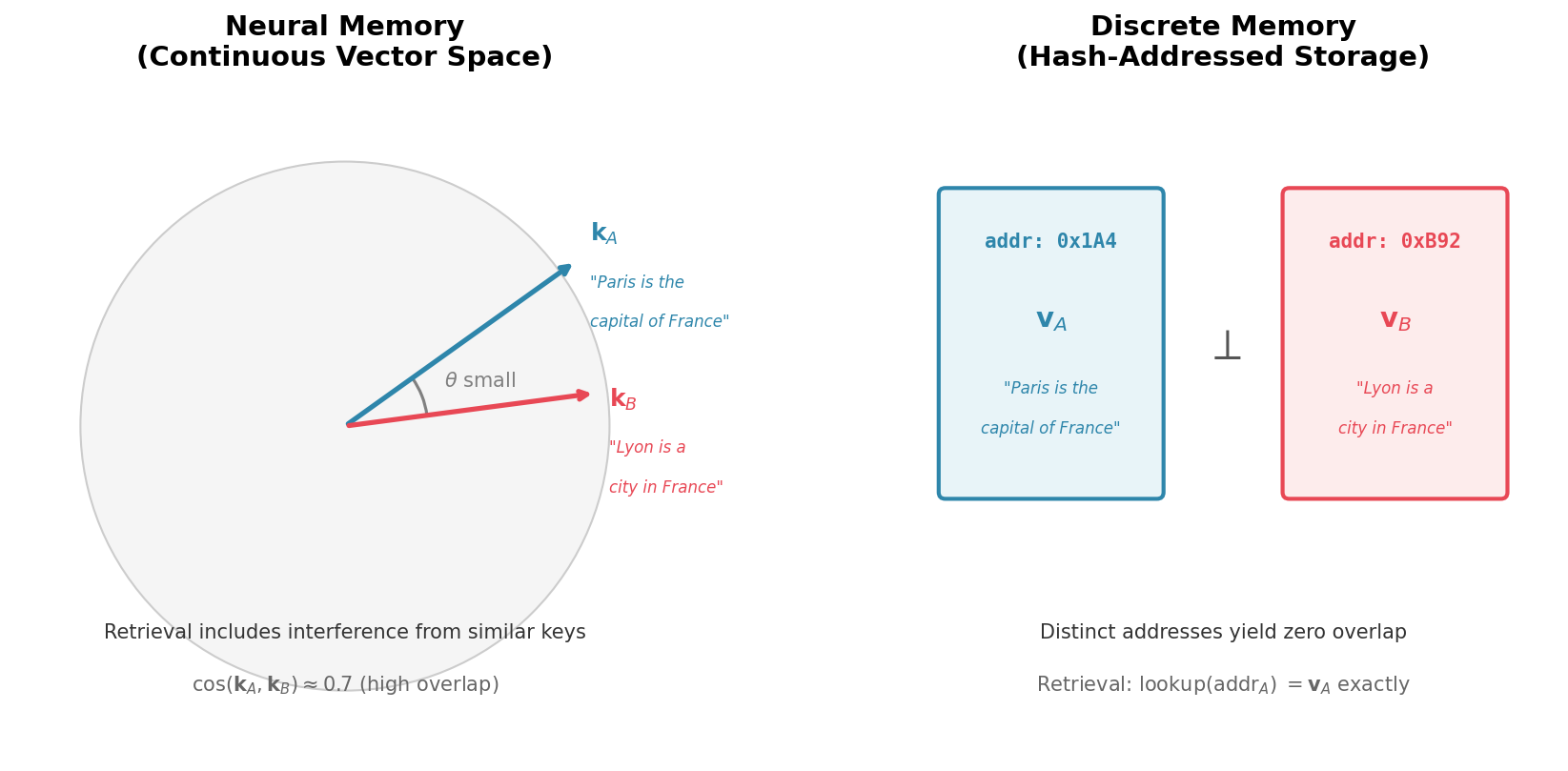
Knowledge Objects: Structuring Facts for Enduring Reliability
Knowledge Objects establish a structured memory system founded on discrete addressing, controlled vocabularies, and version chains to guarantee data integrity. Discrete addresses enable precise data location and retrieval, while controlled vocabularies standardize terminology, minimizing ambiguity and facilitating consistent interpretation. Critically, version chains track the history of each fact, recording modifications and enabling access to prior states. This allows the system to differentiate between current and outdated information, resolving potential conflicts and ensuring that retrieved facts are the most accurate and relevant available. The implementation of version chains is fundamental to maintaining a reliable and auditable record of knowledge within the system.
The Learned Router functions as a query dispatcher, dynamically selecting between accessing the discrete Knowledge Object memory and utilizing a generative model. This decision is based on an assessment of the query’s requirements; for factual recall, the router prioritizes the structured, addressable Knowledge Objects to ensure accuracy. However, when faced with queries demanding inference, nuanced responses, or information not explicitly stored, the router activates the generative model to leverage its capacity for synthesis and flexibility. This hybrid approach optimizes performance by retrieving precise facts directly from memory when possible, and employing generative capabilities only when necessary, resulting in both improved reliability and broadened response potential.
Version chains within the Knowledge Object system address the problem of version ambiguity by maintaining a complete history of factual updates. Each fact is not simply overwritten, but rather, each modification creates a new version linked to its predecessors. This allows the system to resolve conflicting information by identifying the most recent, validated iteration of a fact. The system can also access prior versions for auditing or to understand the evolution of information. This chronological tracking ensures that outdated facts do not persist and compromise the reliability of the knowledge base, establishing a dependable source of truth grounded in verifiable historical data.
Knowledge Objects mitigate the challenges of schema drift by maintaining consistent fact retrieval through a structured, addressable memory system. This approach is grounded in the principles of Complementary Learning Systems, which posits that different brain systems-here, a discrete memory and a generative model-collaborate for optimal performance. Empirical results demonstrate that selective retrieval utilizing Knowledge Objects achieves efficiencies 30 to 300 times greater than context-based memory approaches, indicating a substantial reduction in computational cost and improved responsiveness for factual queries.
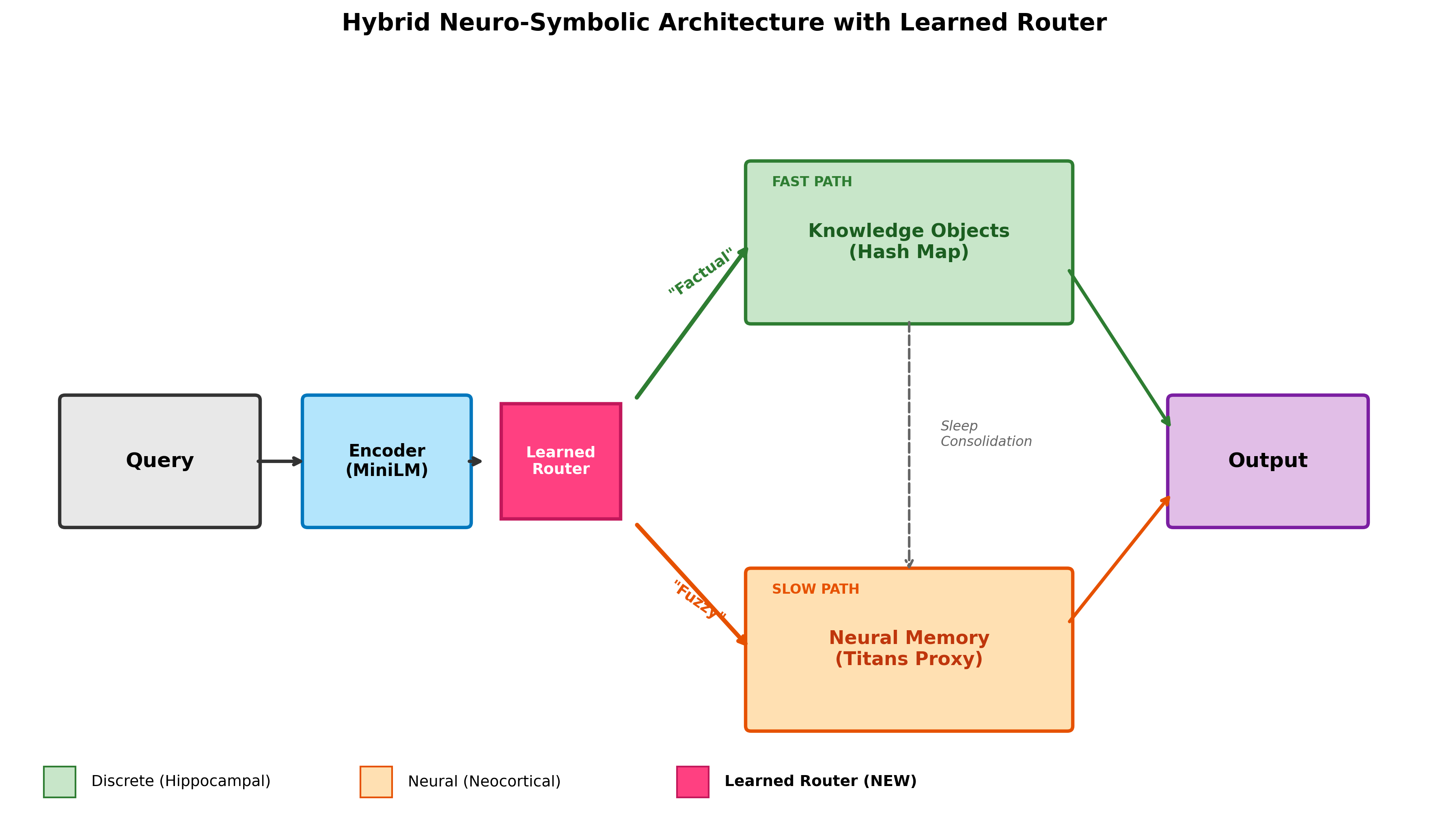
Towards Robust and Reliable Artificial Intelligence
Artificial intelligence systems often struggle with reliability and complex problem-solving due to their reliance on continuous parameter adjustments rather than explicit, symbolic reasoning. Recent advancements explore integrating discrete memory modules – akin to a digital notepad – with structured knowledge representation, such as knowledge graphs. This hybrid approach allows AI to store and retrieve factual information independently of its learned parameters, providing a stable foundation for reasoning. By decoupling knowledge from the model’s weights, these systems demonstrate increased robustness to noisy or incomplete data, and a greater capacity for adapting to new information without catastrophic forgetting. The architecture essentially provides a mechanism for ‘thinking’ with facts, enabling more explainable, consistent, and ultimately, more reliable artificial intelligence capable of tackling intricate challenges.
Current artificial intelligence systems often struggle with real-world complexity due to their reliance on statistical patterns rather than a deep understanding of underlying concepts. A novel architecture integrating discrete memory with structured knowledge offers a potential solution by enabling AI to not just recognize information, but to understand and reason with it. This approach allows systems to dynamically update their understanding as new information arises, mitigating the brittleness seen in systems reliant on static datasets. By grounding AI in a consistent, knowledge-based framework, it can better handle ambiguity, adapt to changing circumstances, and maintain a coherent worldview – effectively moving beyond pattern recognition towards genuine comprehension and robust performance in unpredictable environments.
The promise of knowledge-infused artificial intelligence hinges on resolving critical issues of data consistency and evolving information. Current systems struggle when the underlying structure of knowledge – its ‘schema’ – changes over time, or when multiple, conflicting versions of facts exist. Studies demonstrate the significant performance impact of these challenges; complex, context-based queries require substantially more processing time – up to 23 times longer, reaching 4.6 seconds compared to the 0.2 seconds needed for selective retrieval from a knowledge base of 5000 facts. Effectively addressing schema drift and version ambiguity isn’t merely a technical refinement, but a foundational requirement for building AI systems capable of reliable reasoning and adapting to a dynamic world.
The pursuit of robust artificial intelligence, as detailed in this exploration of neural memory, echoes a principle of elegant design: clarity through separation. The study reveals that dense semantic storage within continuous vector spaces introduces interference, hindering reliable recall-a form of visual noise in the system. This resonates with Henry David Thoreau’s observation that, “Simplify, simplify.” Just as a cluttered interface obscures understanding, so too does a conflation of factual storage and generalization within a neural network. The orthogonal constraint, highlighted in the research, suggests a need for distinct, well-defined spaces-a principle akin to the careful arrangement of elements for maximum clarity and effect.
The Road Ahead
The insistence on collapsing storage and generalization into a single continuous vector space has, it seems, reached an impasse. This work gently, but firmly, suggests that such approaches are fundamentally limited by geometric realities-the more knowledge accrued, the more inevitably it interferes with itself. The elegant solution-discrete addressing coupled with neural weighting-feels almost… inevitable in retrospect. One wonders why the field so long favored a path that asked a continuous system to mimic the discrete nature of symbolic representation.
Remaining challenges, however, are not trivial. Scaling discrete addressing to truly vast knowledge bases demands innovations in indexing and retrieval-a dance between efficiency and expressive power. Further, the interplay between discrete and continuous systems requires careful tuning; an improperly balanced architecture could easily forfeit the benefits of both approaches. The goal isn’t simply to store more, but to structure knowledge in a way that allows for graceful degradation and insightful generalization.
Ultimately, the future likely resides in architectures that embrace separation of concerns-systems where facts are clearly delineated, and the subtle art of generalization is left to the neural weights. Every interface sings if tuned with care, and the same holds true for memory systems. A clumsy attempt to do everything at once, by contrast, simply shouts.
Original article: https://arxiv.org/pdf/2601.15313.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- All Itzaland Animal Locations in Infinity Nikki
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- Gold Rate Forecast
- How to Get to the Undercoast in Esoteric Ebb
- A Dark Scream Theory Rewrites the Only Movie to Break the 2-Killer Rule
- Fire Force Season 3 Part 2 Episode 24 Release Date, Time, Where to Watch
- Australia’s New Crypto Law: Can They Really Catch the Bad Guys? 😂
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
2026-01-25 20:18