Author: Denis Avetisyan
Uber engineers detail how AI-powered fault injection is proactively identifying and resolving vulnerabilities in their massive mobile infrastructure.

This paper presents a scalable system integrating AI-driven mobile testing with systematic fault injection for proactive resilience validation and automated root cause analysis.
While large-scale mobile applications are increasingly vulnerable to backend failures, traditional chaos engineering struggles with the combinatorial complexity of validating mobile resilience. This paper, ‘Scaling Mobile Chaos Testing with AI-Driven Test Execution’, presents an automated system integrating an LLM-based mobile testing platform with service-level fault injection to proactively identify architectural weaknesses. Operational experience at Uber, encompassing over 180,000 tests, demonstrates a scalable approach capable of uncovering resilience risks-including critical issues undetectable by backend testing alone-and reducing debugging time by an order of magnitude. Can continuous mobile resilience validation become a standard practice for maintaining quality at production scale, and what new challenges will arise as mobile architectures evolve?
Navigating the Complexity: The Evolving Landscape of Software Testing
Contemporary software applications are no longer characterized by linear workflows; instead, they present intricate webs of interconnected features and dynamic states. This increasing complexity fuels a combinatorial explosion of potential test cases, meaning the number of tests required to achieve thorough coverage grows exponentially with each added feature or configuration. A seemingly simple application can quickly demand millions of unique tests, far exceeding the capacity of even dedicated testing teams. Consequently, comprehensive testing becomes a significant challenge, forcing developers to prioritize and often accept a level of risk due to the sheer impossibility of validating every possible interaction and edge case. This situation highlights the need for innovative testing strategies that can efficiently address the growing complexity of modern software.
Contemporary automated testing frameworks often falter when confronted with the dynamic nature of modern applications. Rapid UI changes – driven by iterative development and A/B testing – necessitate constant script maintenance, a process that quickly becomes unsustainable. Simultaneously, applications increasingly rely on complex interactions with numerous backend services, each presenting a potential failure point. Testing these integrations requires orchestrating multiple dependencies and validating data flows across systems, a task that exceeds the capacity of many traditional tools. The resulting bottleneck means that automated tests quickly become brittle and incomplete, leaving substantial gaps in coverage and increasing the risk of undetected issues reaching production.
The increasing complexity of modern software creates a substantial testing gap, directly threatening user experience and system reliability through the potential for undetected regressions. These hidden flaws can manifest as frustrating bugs or even critical failures, eroding user trust and impacting business operations. Bridging this gap is not merely a matter of best practice, but a necessity, considering the sheer scale of effort required for comparable manual testing – an estimated 39,000 hours to achieve the same level of coverage. This highlights the unsustainable nature of relying solely on human testers to validate increasingly intricate systems and underscores the urgent need for innovative automated solutions that can efficiently and effectively address the growing complexity of modern applications.
Adaptive Testing: Leveraging Intelligence for Dynamic Systems
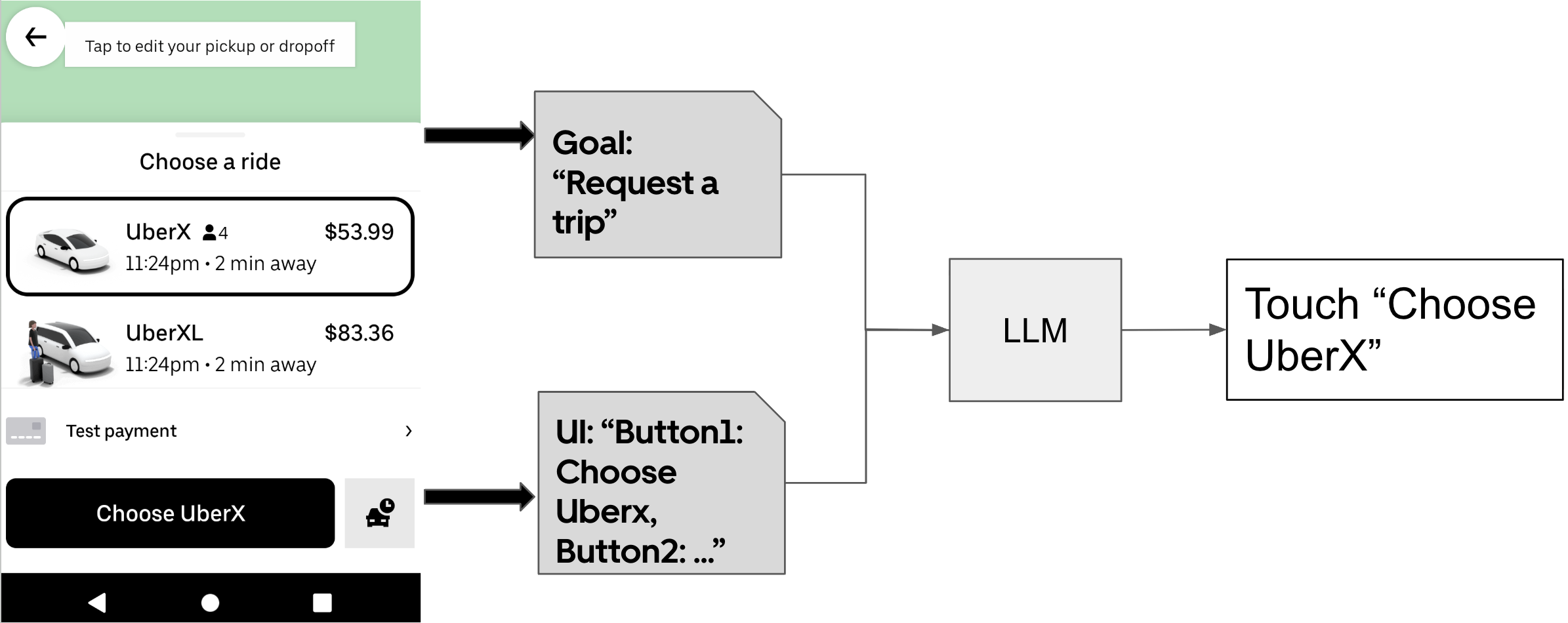
The integration of Machine Learning, specifically Large Language Models (LLMs), represents a shift towards adaptive mobile testing methodologies. Traditional automated testing relies on pre-defined scripts that are susceptible to breakage with even minor UI changes. LLM-based systems overcome this limitation by interpreting application interfaces through natural language processing. This allows the testing framework to understand the function of UI elements, rather than their precise location or attributes, and dynamically adjust test execution accordingly. Consequently, LLMs enable testing to adapt to application variations without requiring constant manual script updates, increasing test reliability and reducing maintenance overhead at scale.
DragonCrawl employs Large Language Models (LLMs) to interpret the elements of a mobile application’s user interface by processing screen content as natural language. This enables the system to identify UI components and their functionalities without relying on traditional methods like coordinate-based image recognition or explicit element identifiers. Consequently, DragonCrawl can dynamically adapt test execution paths when UI changes occur, such as button re-labeling, layout shifts, or the introduction of new elements, without requiring manual updates to test scripts. The LLM’s understanding of the screen’s semantic meaning allows it to correctly interact with the application despite these visual variations, ensuring continued test coverage and reducing maintenance overhead.
Traditional automated testing relies on brittle scripts susceptible to failure with even minor UI changes, necessitating frequent manual updates. DragonCrawl addresses this limitation by utilizing Large Language Models to interpret application interfaces, enabling dynamic test adaptation to UI variations without script modification. This intelligent handling of change significantly reduces maintenance overhead and associated costs. Demonstrated at production scale, the system has successfully completed over 180,000 tests, validating the feasibility and robustness of LLM-driven adaptive testing for mobile applications.
Proactive Resilience: Engineering Systems to Withstand Failure
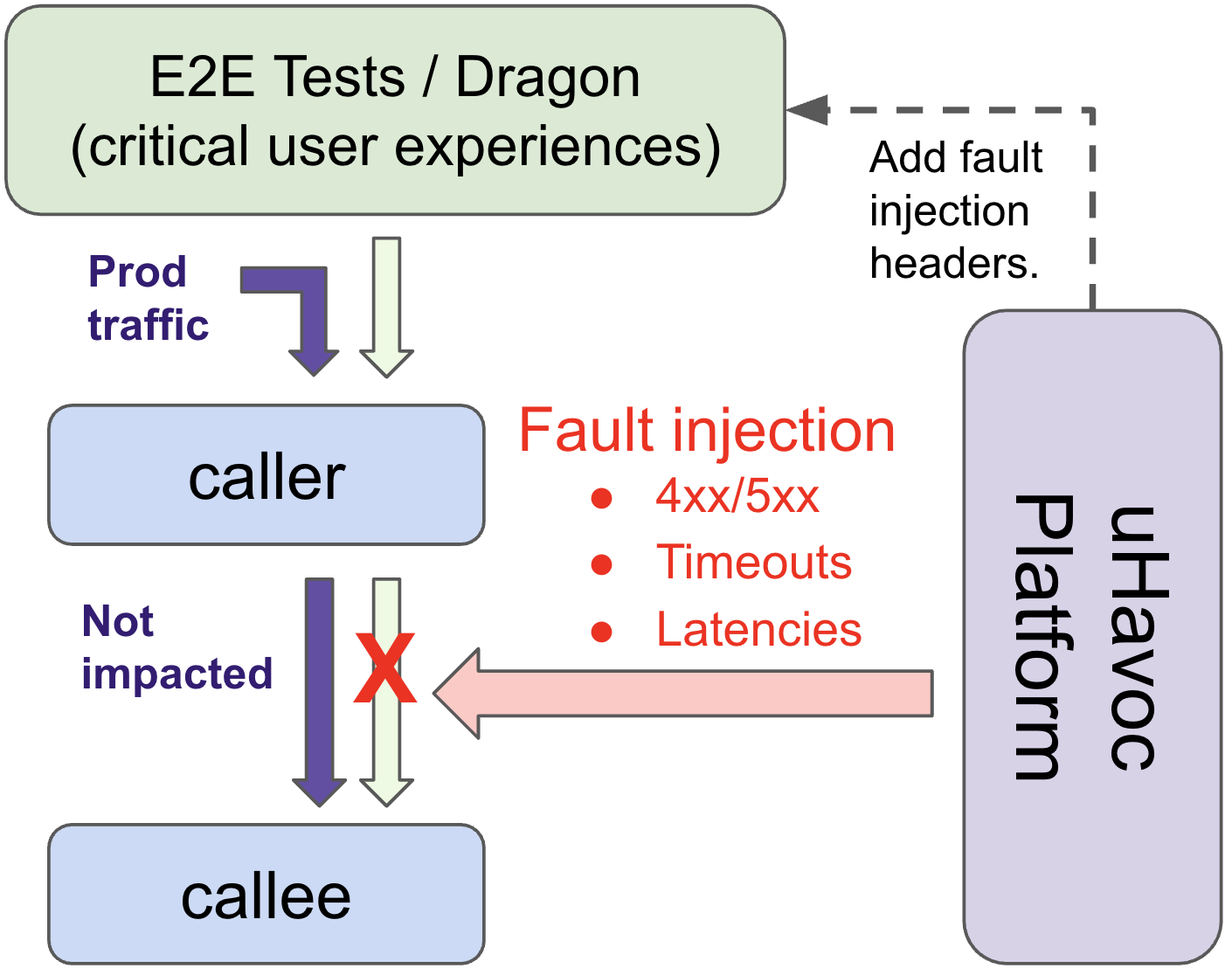
uHavoc operates as a service-level fault injection platform designed to introduce controlled failures into backend systems. This is achieved through the systematic and automated generation of faults, allowing engineering teams to observe system behavior under adverse conditions without impacting end-users. The platform focuses on injecting failures at the service level, simulating issues such as latency increases, error responses, or complete service unavailability. Importantly, uHavoc prioritizes production safety by employing techniques like blast radius control, automated rollback, and real-time monitoring to prevent cascading failures and ensure minimal disruption during testing. This controlled environment enables teams to validate resilience capabilities and identify potential vulnerabilities before they manifest in a production incident.
uHavoc’s service-level fault injection platform enables validation of system resilience by intentionally introducing disruptions to running services. This process assesses the system’s capacity to maintain defined performance levels under adverse conditions and confirms the effectiveness of automated recovery mechanisms. Teams can simulate a range of failure scenarios – including service outages, network latency, and resource exhaustion – to observe system behavior and identify potential single points of failure. Validation focuses on verifying that the system not only detects failures but also initiates and completes pre-defined recovery actions within acceptable timeframes, ensuring continued service availability and data integrity.
uHavoc’s methodology builds upon traditional fault injection techniques by prioritizing the discovery and remediation of systemic vulnerabilities rather than isolated failure scenarios. This proactive approach involves deliberately introducing controlled disruptions to backend services in a production environment to observe system behavior and identify weaknesses before they impact users. Through the implementation of this process, the system successfully identified 23 previously undetected resilience risks, demonstrating an ability to uncover latent failures not revealed by conventional testing methods.
Unveiling Root Causes: Automated Analysis for Rapid Resolution
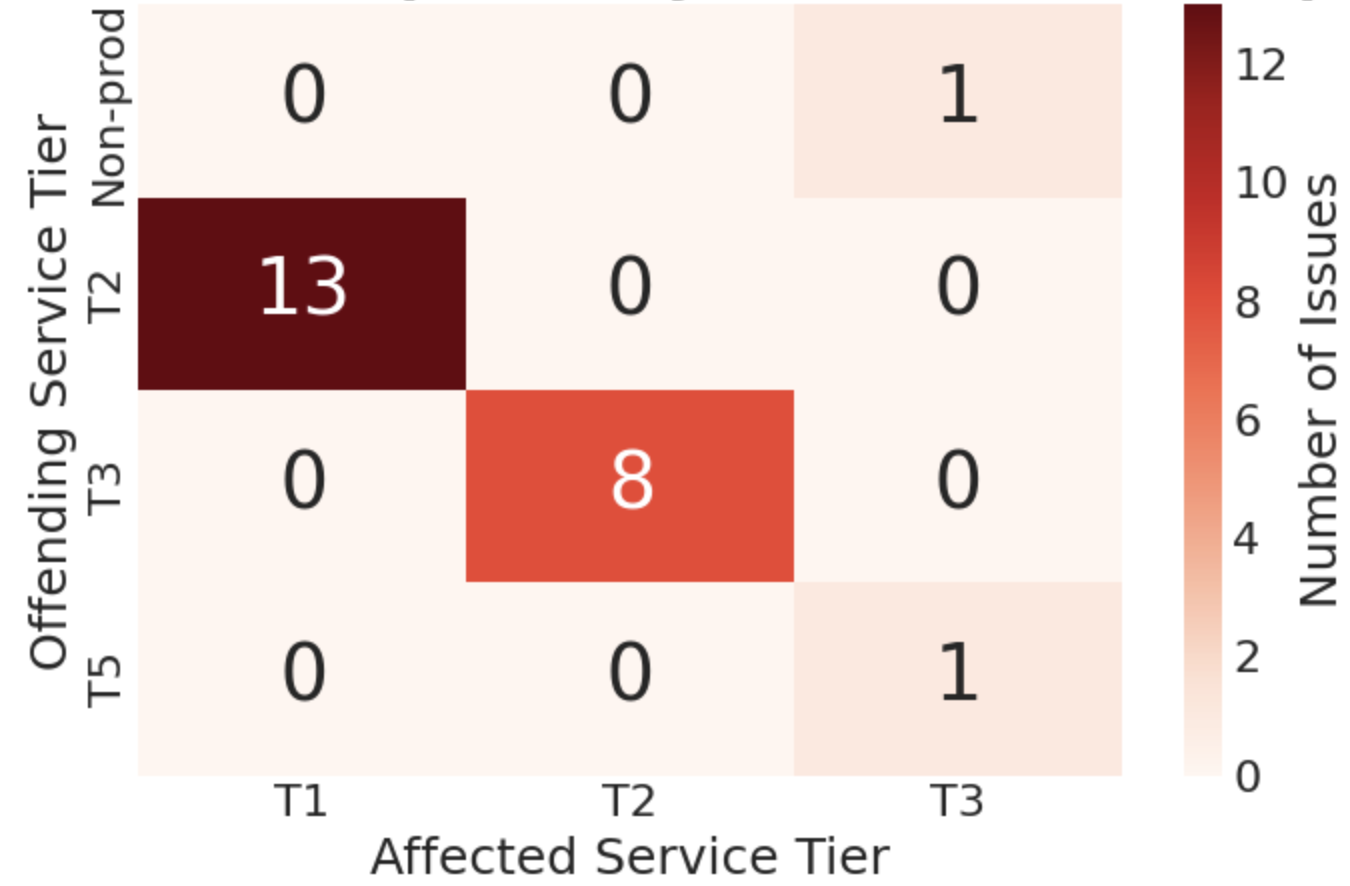
Automated Root Cause Analysis leverages the synergy between Distributed Tracing and service tier classification to dramatically accelerate failure identification. By meticulously tracking requests as they propagate through interconnected services – a process facilitated by tools like Jaeger – the system constructs a detailed map of inter-service dependencies. This tracing data is then intelligently categorized based on service tiers – grouping components by their criticality and function – allowing the system to quickly isolate the source of an issue. Instead of manually sifting through logs and metrics, this automated approach pinpoints the failing component with exceptional speed and accuracy, enabling proactive intervention and minimizing disruption.
Modern distributed systems often involve numerous interconnected services, making it challenging to diagnose failures when they occur. Tools like Jaeger address this complexity by providing a platform for distributed tracing, which allows development teams to follow a request as it propagates through various services. This process generates a visual representation – a trace – that maps the journey of the request, highlighting the time spent in each service. By examining these traces, engineers can pinpoint the exact component responsible for latency or errors, effectively isolating the root cause of an issue. This granular level of visibility moves beyond simple error messages, revealing the precise sequence of events that led to the failure and accelerating the debugging process.
The implementation of automated root cause analysis demonstrably accelerates issue resolution and bolsters system dependability. Traditionally, diagnosing complex failures across distributed systems consumed considerable time – often hours – for engineering teams. However, this capability compresses that timeframe to mere minutes, a substantial improvement in operational efficiency. Recent testing revealed a 99.27% success rate in identifying the source of errors, specifically uncovering twelve critical issues that previously blocked trip requests and food orders from completing. This proactive identification not only minimizes service disruptions but also enhances the overall user experience by ensuring a more stable and reliable platform.
The presented system exemplifies a holistic approach to mobile application resilience, mirroring the interconnectedness of a living organism. Every new dependency introduced during development, as acknowledged within the research, carries a hidden cost to the overall system’s freedom and stability. This echoes Ada Lovelace’s observation: “The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform.” The AI-driven fault injection, therefore, isn’t about creating chaos, but meticulously probing the boundaries of what the system can do, revealing vulnerabilities inherent in its structure and ultimately reinforcing architectural principles. The study highlights that understanding these structural limitations is paramount to building truly robust and scalable mobile applications.
Beyond the Static Map
The presented system, while demonstrating a clear improvement in proactive resilience validation, ultimately addresses only the symptoms of a deeper challenge. Like adding new traffic lights to a poorly planned city, it optimizes flow within existing constraints. The true evolution of mobile chaos engineering will not come from more sophisticated fault injection, but from a fundamental shift towards architectures designed for failure. The infrastructure must adapt, not merely withstand.
Current approaches largely treat resilience as a testing phase – a final inspection before deployment. Future work should focus on embedding resilience directly into the development lifecycle. This necessitates a move beyond simply identifying root causes; the system should anticipate likely failure modes through predictive modeling, informed by the continuous observation of application behavior in production.
The integration of large language models offers a promising avenue, but the true power lies not in automated debugging, but in the ability to model complex system interactions. The challenge is not to automate the work of a seasoned engineer, but to provide the tools to understand the emergent behavior of these complex systems – to see the city not as a collection of buildings, but as a living, breathing organism.
Original article: https://arxiv.org/pdf/2602.06223.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- Gold Rate Forecast
- How to Solve the Glenbright Manor Puzzle in Crimson Desert
- 15 Lost Disney Movies That Will Never Be Released
- 8 Actors Who Could Play Blackbeard In One Piece Live-Action Season 3
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- What are the Minecraft Far Lands & how to get there
- These are the 25 best PlayStation 5 games
- Wartales Curse of Rigel DLC Guide – Best Tips, POIs & More
2026-02-10 00:01