Author: Denis Avetisyan
A new approach to training complex AI models overcomes the challenges of vanishing and exploding gradients by propagating updates through textual representations.
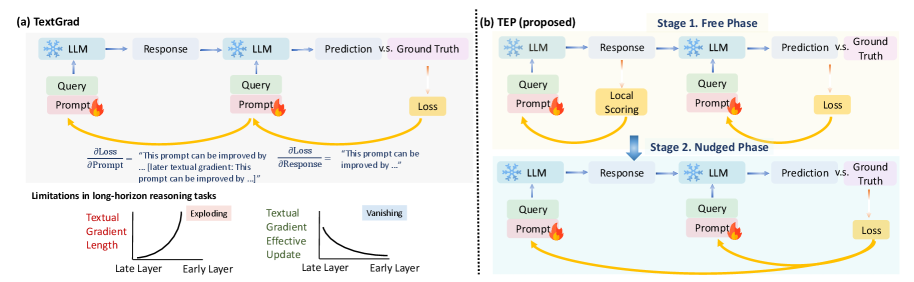
Textual Equilibrium Propagation offers a scalable local learning framework for deep compound AI systems, addressing limitations of traditional backpropagation.
While large language models increasingly power complex, multi-step AI systems, scaling these ‘compound’ architectures is hindered by the breakdown of traditional global feedback mechanisms. This paper, ‘Textual Equilibrium Propagation for Deep Compound AI Systems’, introduces a novel local learning framework to address these depth-scaling challenges, specifically avoiding the exploding and vanishing gradients that plague long-horizon workflows. By drawing inspiration from Equilibrium Propagation, the proposed Textual Equilibrium Propagation (TEP) optimizes prompts iteratively and propagates task-level objectives via forward signaling, rather than relying on backward textual chains. Could this localized approach unlock truly scalable and robust deep AI systems, moving beyond the limitations of global backpropagation?
The Fragility of Deep Reasoning: A Systemic Challenge
Despite remarkable advances, contemporary compound AI systems-those built from interconnected neural networks-frequently falter when tasked with multi-step reasoning. While excelling at pattern recognition and immediate inference, these systems struggle to maintain a consistent and logically sound chain of thought over extended problem-solving sequences. This isn’t a matter of computational power, but rather a limitation in their ability to track dependencies and avoid accumulating errors across numerous processing layers. Essentially, the signal representing the core logic of a problem can degrade as it propagates through the network, leading to inconsistent conclusions or a failure to reach a solution-a phenomenon akin to a game of telephone where the original message becomes distorted with each repetition. This challenge highlights a critical need for architectural innovations that prioritize the preservation of reasoning coherence in increasingly complex AI models.
The architecture of deep artificial intelligence systems, while enabling remarkable feats of pattern recognition, presents a significant challenge in effectively distributing instructive signals during the learning process. As data flows through numerous layers in these networks, the gradient – the signal used to adjust the system’s parameters – can weaken or vanish entirely, a phenomenon known as vanishing gradients. This makes it difficult for earlier layers to learn from later-stage errors, hindering the optimization of the entire network. Consequently, even though a system might perform well on initial tasks, subtle improvements become increasingly difficult to achieve, and the system may struggle to generalize to novel situations. Researchers are actively exploring methods, such as residual connections and attention mechanisms, to facilitate more robust feedback propagation and overcome these limitations in deep learning architectures.
The capacity of current artificial intelligence systems to tackle increasingly complex problems is often limited by a critical flaw in their learning process: the accumulation of errors and biases as reasoning extends over multiple steps. Without effective mechanisms to provide consistent and informative feedback during training, these systems experience performance plateaus where further scaling yields diminishing returns. Subtle inaccuracies introduced early in a multi-step process are not corrected, instead propagating and amplifying with each subsequent calculation. This creates a compounding effect, leading to skewed results and a reduced ability to generalize to novel situations. Consequently, even powerful AI architectures struggle with tasks demanding sustained, coherent reasoning, highlighting the need for innovative training strategies that prioritize robust feedback and error correction throughout the entire problem-solving process.
Addressing the limitations of current artificial intelligence demands a shift beyond simply increasing computational power and dataset size. Researchers are actively exploring novel training paradigms, including techniques like reinforcement learning with hierarchical structures and curriculum learning, which strategically introduces increasingly complex problems. Furthermore, the development of more sophisticated feedback mechanisms – such as those inspired by biological reward systems and attention mechanisms – allows AI systems to not only identify errors but also understand why those errors occurred, facilitating targeted refinement. These approaches, combined with innovations in architectural design like sparse transformers and neuro-symbolic integration, represent a crucial move towards creating AI capable of sustained, reliable, and genuinely deep reasoning – a capacity extending far beyond the limitations of mere scale.

TextGrad: Backpropagation Through Language
TextGrad facilitates feedback propagation in Compound AI Systems by directly modifying textual outputs based on evaluation. Unlike gradient descent, which is unsuitable for discrete text, TextGrad utilizes Large Language Model (LLM) Critics to assess generated text and produce textual edits representing feedback signals. These edits are then applied to the original text, creating a revised output and establishing a closed-loop refinement process. This approach allows for iterative improvement of text-based outputs within the compound system by translating evaluation into actionable textual changes, effectively “backpropagating” feedback through language itself.
Traditional gradient descent, a cornerstone of machine learning optimization, is fundamentally designed for continuous spaces where infinitesimal changes yield predictable results. However, natural language operates within a discrete space; altering a single token constitutes a non-differentiable step, preventing the direct application of gradient-based methods. TextGrad circumvents this limitation by reframing optimization as a search for textual modifications-rewrites, additions, or deletions-guided by LLM Critics. This approach avoids the need to calculate gradients on discrete tokens, instead leveraging the LLM’s capacity to evaluate and suggest improvements in a more human-analogous manner, enabling iterative refinement of text-based outputs without relying on continuous differentiability.
TextGrad utilizes Large Language Model (LLM) Critics to assess the quality of generated text and produce iterative feedback signals. These LLM Critics are prompted to evaluate outputs based on predefined criteria, and then generate textual modifications intended to improve performance. This feedback isn’t a scalar gradient, but rather a natural language suggestion for revision, which is then fed back into the system for further processing. This process establishes a closed-loop refinement cycle where the LLM Critic continuously evaluates and guides the text generation, allowing for iterative improvement without relying on traditional gradient-based optimization methods in discrete text spaces.
The Structured Rubric in TextGrad facilitates granular feedback by distinguishing between qualities inherent to well-formed text and criteria specific to the task at hand. Task-independent metrics assess attributes like grammatical correctness, clarity, and coherence, providing a baseline evaluation applicable across diverse applications. Task-dependent performance criteria, conversely, are defined by the specific objectives of a given task-for example, factual accuracy in question answering or stylistic adherence in creative writing. This separation allows the LLM Critic to provide targeted feedback, addressing both fundamental textual quality and the successful completion of task-specific goals, enabling more effective refinement of generated text.
Phased Refinement: A Strategy for Robust Learning
The Free Phase of prompt refinement utilizes Large Language Model (LLM) Critics to iteratively modify initial prompts without constraints, allowing for rapid exploration of the prompt space. This unconstrained refinement continues until a Local Equilibrium is achieved, defined as the point where further free modifications yield diminishing returns in performance metrics. The objective is to maximize initial improvements by enabling the LLM Critic to freely navigate potential prompt variations, effectively escaping suboptimal local minima before more structured refinement strategies are employed. This phase prioritizes breadth of exploration over immediate convergence, establishing a strong foundation for subsequent, more focused refinement stages.
Following the Free Phase, the Nudged Phase implements a constrained refinement strategy. This phase limits the degree of prompt modification, preventing drastic alterations that could destabilize the learning process. These bounded adjustments are specifically directed by the defined task objectives, ensuring that refinements consistently work towards improving performance on the target function. By restricting the scope of change while maintaining a goal-oriented approach, the Nudged Phase facilitates stable convergence towards an optimal prompt, avoiding oscillations or divergence that might occur with unconstrained optimization.
Task-dependent performance robustness is achieved through systematic integration of unit tests and boundary handling procedures. Unit tests verify the functionality of individual components within the LLM system, ensuring correct operation across a defined range of inputs. Boundary handling specifically addresses edge cases and atypical inputs, preventing failures or unexpected behavior when prompts or data fall outside of expected parameters. This dual approach allows for validation of both core functionality and resilience to variations in input, leading to a more reliable and predictable system performance across diverse tasks and datasets.
Effective implementation of iterative refinement processes requires comprehensive context integration between each module. Specifically, outputs from prior refinement stages – including prompt modifications, performance metrics, and identified failure cases – must be accurately communicated as inputs to subsequent stages. This ensures that each module operates with a complete understanding of the current state of the prompt and the evolving task objectives. Failure to properly integrate this contextual information can lead to redundant modifications, instability in the refinement process, and ultimately, suboptimal performance on the target task. Data formats for context transfer are typically serialized JSON objects containing relevant metadata and results, enabling consistent interpretation across modules.

Preserving Signal Integrity: Addressing Gradient Instability
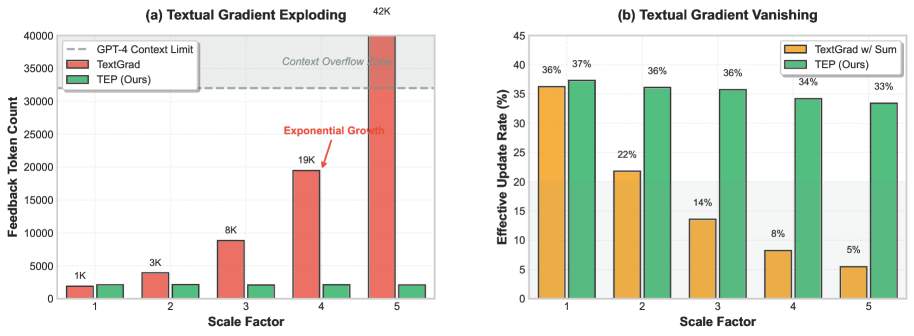
Global Textual Backpropagation, a method for training deep compound AI systems, offers substantial reasoning capabilities but isn’t without its challenges. The process of propagating error signals backwards through numerous textual layers can lead to two primary forms of instability: exploding and vanishing gradients. Exploding gradients occur when error signals amplify with each layer, causing drastic weight updates and disrupting learning; conversely, vanishing gradients see these signals diminish to near zero, effectively halting learning in earlier layers. This phenomenon arises because textual operations, unlike those in traditional neural networks, don’t inherently constrain signal magnitude, leading to exponential growth or decay during backpropagation. Consequently, maintaining stable training requires careful architectural considerations and specialized techniques to regulate the flow of information through the system’s deep layers, preventing either runaway amplification or complete signal loss.
The necessity of managing context windows in large language models often leads to summarization techniques, but this practice introduces a critical vulnerability to the Vanishing Textual Gradient problem. As information is condensed to fit within these limits, crucial details – particularly those needed for accurate reasoning across multiple steps – can be lost or diluted. This loss isn’t simply a reduction in data; it actively weakens the signal propagating backward through the network during training. The model struggles to properly attribute credit or blame to earlier steps in the reasoning process when the supporting evidence has been abstracted away, effectively diminishing the gradient and hindering the learning of long-range dependencies. Consequently, while summarization offers a temporary solution for context constraints, it can ultimately undermine the model’s ability to perform complex, multi-step reasoning tasks reliably.
The system addresses the challenges of gradient instability in deep learning through a refined methodology centered on prompt engineering and controlled feedback propagation. Rather than relying on unrestricted gradient flow, the approach carefully crafts prompts to encourage more stable learning signals and constrains how feedback is propagated through the network. This involves structuring prompts to highlight crucial information and prevent the dilution of key specifics during summarization-a common cause of vanishing gradients. By limiting the scope of feedback and focusing on pertinent details, the system minimizes the risk of both exploding and vanishing gradients, enabling robust learning even in deeply layered architectures and complex reasoning tasks. The result is a system capable of sustaining reliable performance and achieving notable gains in multi-step question answering and object counting, while remaining highly efficient in terms of token usage.
The capacity for complex, multi-step reasoning within Compound AI Systems is fundamentally limited by gradient instability – the tendency for signals to either vanish or explode during the learning process. Addressing this instability unlocks a pathway to genuinely deep understanding and reliable performance, as demonstrated by a 3.4% improvement observed across challenging multi-step Question Answering tasks. This gain isn’t merely incremental; it represents a significant leap toward systems capable of processing nuanced information and drawing accurate conclusions from extensive datasets. By maintaining strong signal propagation throughout the network, these systems can effectively leverage the full depth of their architecture, leading to more robust and insightful responses – a critical step in realizing the potential of artificial intelligence to tackle complex real-world problems.
Evaluations reveal that the proposed Textual Entailment Propagation (TEP) method achieves substantial performance improvements on complex question answering tasks. Specifically, TEP surpasses Chain-of-Thought (CoT) baseline models by a margin of 5.3% on the HotpotQA dataset, which demands multi-hop reasoning over supporting facts, and by 5.7% on PubMedQA, a biomedical question answering benchmark requiring expert knowledge. These gains demonstrate TEP’s capacity to not only process information but to synthesize it effectively, leading to more accurate and reliable answers in challenging domains and highlighting its potential for advanced reasoning applications.
Tests evaluating the system’s robustness involved progressively more complex object counting scenarios, designated by a complexity factor ‘d’ representing the number of objects and their spatial relationships; notably, the proposed technique, TEP, sustained a 79% accuracy rate even at d=5. This performance stands in stark contrast to TextGrad, which required significantly more computational resources to achieve comparable results – a 13-fold increase in token usage for TextGrad versus a minimal increase observed with TEP. This efficiency suggests that TEP not only preserves reasoning ability with greater complexity, but also scales more effectively, offering a practical advantage for deploying deep AI systems in resource-constrained environments.

The pursuit of scalable deep learning, as explored within this research, echoes a fundamental tenet of system design: interconnectedness. This paper’s introduction of Textual Equilibrium Propagation (TEP) to mitigate the depth-scaling issues inherent in traditional backpropagation exemplifies this principle. As Edsger W. Dijkstra aptly stated, “It’s not enough to have good intentions; you must also have good methods.” TEP provides a ‘good method’ by addressing the exploding and vanishing gradient problems, effectively optimizing prompt learning in compound AI systems. The framework recognizes that alterations within one component invariably ripple through the entire system, demanding a holistic approach to learning and stability-a testament to the interconnected nature of complex AI architectures.
What’s Next?
The introduction of Textual Equilibrium Propagation represents a necessary, though likely insufficient, step toward tractable learning in increasingly complex, compound AI systems. The avoidance of depth-scaling issues through local updates is a pragmatic solution, but it sidesteps the fundamental question of holistic system optimization. While gradients may no longer explode or vanish, the resulting equilibrium may simply be a locally optimal, and therefore limited, representation of the true solution space. The elegance of backpropagation always lay in its global view – a view now fractured into localized exchanges.
Future work must address the integration of these localized learnings. Can information be efficiently propagated between equilibrium points, creating a broader, more coherent understanding? Or will such systems remain collections of isolated intelligences, achieving competence through compartmentalization rather than genuine integration? The challenge isn’t merely to train deeper networks, but to design architectures that deserve such depth – structures where complexity yields capability, and not just brittle, opaque behavior.
The pursuit of scalable learning is, at its heart, a search for elegant design. The system will reveal its failings only under stress – and the cost of poor architecture is invariably borne when the invariants break. Good architecture is invisible until it breaks, and only then is the true cost of decisions visible.
Original article: https://arxiv.org/pdf/2601.21064.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- How to Get to the Undercoast in Esoteric Ebb
- Mewgenics vinyl limited editions now available to pre-order
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
- Warframe Voruna Prime access begins on April 8 for all platforms, new deluxe cosmetic Warframe skins revealed
- All Itzaland Animal Locations in Infinity Nikki
- Zendaya’s 4 Big 2026 Movies Could Beat Brie Larson’s Box 2019 Office Record
2026-02-02 00:04