Author: Denis Avetisyan
A new study details how machine learning algorithms can automatically classify white dwarf stars from large spectroscopic surveys, accelerating the discovery of rare and unusual systems.

This work demonstrates the effective use of machine learning, including UMAP dimensionality reduction, for classifying white dwarf spectral types and identifying binary stars within large spectroscopic datasets.
The increasing volume of spectroscopic data from multi-object surveys presents a significant challenge for efficient white dwarf characterization. Addressing this, our study, ‘Classifying white dwarfs from multi-object spectroscopy surveys with machine learning’, details a novel application of neural networks to automatically classify white dwarf spectral types using data from the Dark Energy Spectroscopic Instrument and Pan-STARRS photometry. This approach achieves near-perfect accuracy for common types and successfully identifies rare objects, including those with inhomogeneous surface compositions and potential binary systems. Could these machine learning techniques unlock a more comprehensive understanding of the white dwarf population and accelerate the discovery of previously hidden stellar systems?
The Faint Echoes of Stellar Lives
Though appearing as faint, featureless points of light, the spectra of white dwarfs are remarkably informative archives of stellar life cycles and chemical composition. These compact stellar remnants, the final fate of many stars, possess atmospheres where elements are sorted by mass, with heavier elements sinking beneath lighter ones. This process creates distinct spectral features – absorption lines – that reveal not only the star’s surface temperature and gravity, but also the abundance of elements like hydrogen, helium, carbon, and oxygen. Subtle variations in these spectral signatures can pinpoint a white dwarf’s age, its evolutionary path, and even provide clues about planets or asteroids that may have been disrupted and incorporated into its atmosphere, making each spectrum a unique fingerprint of a star’s past.
The increasing volume of observed white dwarfs presents a significant hurdle for astronomers relying on established spectral classification techniques. Historically, categorizing these stellar remnants depended on identifying key spectral lines indicative of atmospheric composition and temperature; however, the sheer number of newly discovered white dwarfs, coupled with the subtlety of certain spectral features, strains the efficiency of these traditional methods. Existing classification schemes, designed for a smaller sample size, struggle to accommodate the diversity now apparent in white dwarf populations, leading to ambiguities and inaccuracies in determining fundamental stellar parameters. This necessitates the development of more robust and automated classification tools capable of handling large datasets and discerning nuanced spectral variations, ultimately allowing for a more comprehensive understanding of stellar evolution and the demographics of these fascinating objects.
The categorization of white dwarfs is increasingly complicated by the presence of faint spectral signatures revealing atmospheric intricacies and external influences. These subtle features, often masked by the dominant hydrogen or helium lines, indicate the presence of heavier elements accreted from companion stars in binary systems, or unusual metallic compositions within the white dwarf’s atmosphere itself. Discerning these delicate details requires advanced spectral modeling and analysis, as even minor variations can dramatically alter a white dwarf’s classification and reveal crucial information about its evolutionary history and potential interactions with nearby stars. The challenge lies not in identifying broad spectral types, but in accurately interpreting these nuanced signals to unlock the full complexity of white dwarf populations.
The Machine as Stellar Cartographer
Machine learning classification is implemented to automate the categorization of white dwarf spectra, addressing limitations inherent in traditional, manual spectroscopic analysis. This approach utilizes algorithms to objectively identify and quantify spectral features, thereby minimizing subjective interpretation and potential bias associated with human classification. The pipeline processes spectroscopic data to assign white dwarfs to specific spectral types based on the presence and strength of identified elements and features. This automated system increases throughput and consistency in white dwarf categorization, enabling the analysis of larger datasets than previously feasible with manual methods.
The automated classification pipeline leverages machine learning algorithms trained on extensive spectroscopic datasets, notably the Dark Energy Spectroscopic Instrument (DESI) Data Release 1 (DR1). These algorithms are designed to identify and quantify key spectral features – absorption lines, emission lines, and overall spectral shape – which are indicative of specific white dwarf characteristics. Training on the DESI DR1 dataset, comprising spectra of over a million objects, allows the algorithms to learn the relationships between these spectral features and known white dwarf properties. The large dataset size is critical for robust training, minimizing the impact of noise and ensuring the algorithms generalize effectively to new, unseen spectra. Feature extraction is performed automatically, and the algorithms are optimized to distinguish between subtle variations in spectral features that would be difficult to discern through manual inspection.
The performance of machine learning algorithms used for white dwarf spectral classification is directly dependent on the quality of the input data; therefore, rigorous spectroscopic data reduction techniques are essential. These techniques include bias subtraction, flat-field correction, wavelength calibration, and cosmic ray removal, all of which minimize systematic errors and noise. Accurate data reduction ensures that identified spectral features genuinely reflect the physical properties of the white dwarf, rather than instrumental artifacts. Specifically, precise flux calibration is critical for accurate feature identification and subsequent classification. Without these preparatory steps, even the most sophisticated machine learning algorithms will produce unreliable results and introduce substantial biases into the classification process.
The automated white dwarf classification pipeline incorporates photometric data from the Pan-STARRS survey to improve classification accuracy and reliability. This supplementary data, consisting of multi-color brightness measurements, provides additional constraints on stellar parameters and helps to resolve ambiguities present in spectroscopic data alone. Specifically, the integration of Pan-STARRS photometry enables the pipeline to achieve classification accuracies approaching 100% for the prevalent DA and DB white dwarf types, representing a significant improvement over methods relying solely on spectral analysis.
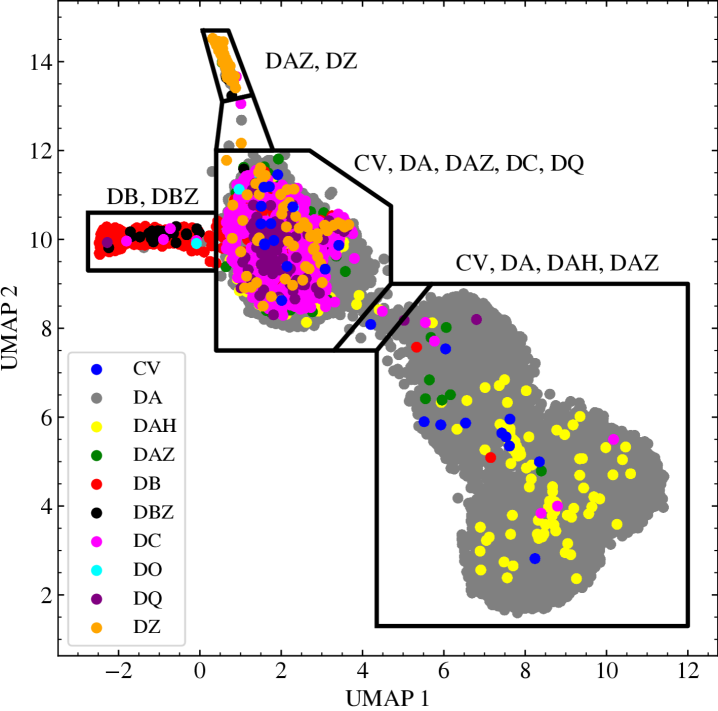
Unveiling the Hidden Lives Within
Machine learning models were implemented to detect the presence of metal lines within white dwarf stellar spectra, enabling the characterization of atmospheric compositions beyond the typical hydrogen and helium dominance. These models analyze spectral data to identify absorption features corresponding to elements heavier than hydrogen and helium, such as iron, calcium, and magnesium. The detection of these metal lines provides insights into the processes affecting white dwarf atmospheres, including accretion from companion stars, radiative levitation, and gravitational settling. Quantitative analysis of the line strengths allows for the determination of atmospheric metal abundances, revealing information about the progenitor star’s composition and the subsequent evolutionary history of the white dwarf.
Magnetic white dwarfs are identified through the presence of Zeeman splitting in their spectra, a phenomenon resulting from the interaction of magnetic fields with atomic energy levels. Analysis of spectral line shapes allows for the quantification of magnetic field strength and geometry. Our models reliably classify these objects and, crucially, can detect instances of inhomogeneous surface compositions. This is achieved by identifying spectral variations that indicate differing chemical abundances across the stellar surface, often manifested as asymmetries or shifts in the Zeeman-split lines. These variations suggest localized concentrations of elements, deviating from a uniform distribution and providing insights into magnetic field topology and atmospheric processes.
A neural network architecture was implemented to automatically identify and categorize binary white dwarf systems from spectral data. This system was trained on a dataset comprising 224 binary star candidates, allowing for the differentiation of single white dwarfs from those engaged in binary interactions. Accurate classification of these systems is critical for modeling stellar interactions, including mass transfer and potential Type Ia supernova progenitors, as the network effectively distinguishes spectral signatures indicative of companion stars or accretion processes. The resulting classifications provide a statistically robust catalog for follow-up observations and detailed astrophysical analysis.
Dimensionality reduction using Uniform Manifold Approximation and Projection (UMAP) was employed to visualize the high-dimensional spectral data and identify relationships between different white dwarf classifications. This technique allowed for the identification of underlying structure not readily apparent through traditional analysis methods. Specifically, application of UMAP to the spectral data led to the discovery of three previously uncharacterized white dwarfs exhibiting evidence of inhomogeneous surface compositions, indicated by spectral features inconsistent with homogeneous models. These newly identified objects were confirmed through follow-up spectral analysis, demonstrating the effectiveness of UMAP as a tool for exploratory data analysis in stellar spectroscopy.
A New Dawn for Stellar Archaeology
The advent of automated white dwarf classification represents a significant leap forward for astronomical research, allowing for the analysis of datasets previously too large for manual examination. This framework efficiently categorizes white dwarfs based on their spectral characteristics, dramatically accelerating the rate at which these stellar remnants are discovered and studied. Consequently, astronomers can now move beyond individual object analysis to conduct robust statistical studies of white dwarf populations, revealing previously hidden patterns and correlations. This capability is particularly valuable for unraveling the complex processes of stellar evolution and galactic history, as large samples provide the statistical power needed to discern subtle trends and test theoretical models with unprecedented precision. The efficiency gains promise a new era of white dwarf astronomy, shifting the focus from identifying individual objects to understanding the broader context of stellar populations and their role in the universe.
Accurate identification of binary white dwarfs and chemically peculiar examples is fundamentally reshaping stellar evolution theory. These stellar remnants, particularly when interacting in close binary systems or exhibiting unusual atmospheric compositions, represent critical testing grounds for models describing the late stages of stellar life. Binary white dwarfs provide precise constraints on the processes governing common envelope evolution, mass transfer, and ultimately, the pathways to Type Ia supernovae. Meanwhile, chemically peculiar white dwarfs-those with abundances of elements like iron, calcium, or carbon deviating significantly from the norm-reveal details about internal mixing, radiative levitation, and the accretion of planetary debris. By carefully characterizing these objects, astronomers can refine existing models and address longstanding questions about the final fates of stars and the enrichment of the interstellar medium with heavy elements.
The spatial distribution of various white dwarf types acts as a fossil record of galactic evolution. Detailed mapping of these stellar remnants reveals clues about the assembly history of the Milky Way, including past merger events and the formation of the galactic disk and halo. Different white dwarf populations-those formed early in the galaxy’s history versus more recent generations-trace distinct kinematic and chemical signatures, allowing astronomers to reconstruct the processes that have shaped stellar populations over billions of years. Analyzing the concentration and movements of specific white dwarf classes, such as those rich in heavy elements or exhibiting peculiar atmospheric compositions, provides critical constraints on models of star formation, stellar migration, and the overall chemical evolution of the galaxy, ultimately illuminating the complex interplay of forces that have sculpted the Milky Way into its present form.
Ongoing development centers on enhancing the automated classification framework by integrating data from diverse sources, such as astrometric measurements and photometric time series. This multi-faceted approach promises to not only bolster classification accuracy – already demonstrated at 85-95% for rarer spectral types – but also to reveal previously undetectable spectral subtleties. Refinements to the machine learning algorithms will focus on feature engineering and model architectures capable of discerning nuanced patterns within the white dwarf spectra, potentially uncovering new sub-classes or providing more precise determinations of stellar parameters. Such improvements will be instrumental in maximizing the scientific return from large-scale surveys and pushing the boundaries of white dwarf astronomy.
The automated classification of white dwarf spectra, as demonstrated in this study, echoes a sentiment articulated by Isaac Newton: “If I have seen further it is by standing on the shoulders of giants.” This work builds upon decades of spectroscopic analysis and stellar modeling, leveraging machine learning to efficiently categorize vast datasets. The application of algorithms like UMAP to reduce dimensionality and identify patterns within spectral data allows for a more nuanced understanding of white dwarf populations and the detection of peculiar objects, such as binary systems, that might otherwise remain obscured. Any attempt to predict stellar evolution, however, requires rigorous numerical methods and careful consideration of the stability of solutions to Einstein’s equations, given the complex physics at play.
What Lies Beyond the Classification?
The successful deployment of machine learning algorithms to categorize white dwarf spectra, as demonstrated, represents not a culmination, but an amplification of existing uncertainties. Automated classification, while efficient, offers a polished veneer over the inherent ambiguities within spectroscopic data. The precision with which a spectral type is assigned should not be mistaken for an understanding of the underlying stellar physics; it merely refines the boundaries of ignorance. Gravitational collapse forms event horizons with well-defined curvature metrics, but the information contained within those horizons – the true nature of stellar endpoints – remains elusive, even when illuminated by advanced analytical tools.
Future work will undoubtedly focus on expanding the training datasets and improving algorithmic sophistication. However, the most pressing challenge lies not in achieving ever-finer distinctions within existing classifications, but in identifying and incorporating genuinely novel phenomena. The algorithms, by their very nature, are predisposed to recognize patterns mirroring the training data; truly exceptional objects, those lying outside the established parameter space, risk being mislabeled or overlooked. Singularity is not a physical object in the conventional sense; it marks the limit of classical theory applicability.
Ultimately, the utility of these methods rests on the acknowledgement that classification is a provisional act. The categories themselves are constructs, useful for organizing observations but potentially obscuring deeper truths. The pursuit of knowledge, in this context, resembles an attempt to map the surface of a black hole – a task destined to reveal more about the limitations of the cartographer than the nature of the abyss.
Original article: https://arxiv.org/pdf/2602.04964.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Gold Rate Forecast
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- 15 Lost Disney Movies That Will Never Be Released
- How to Solve the Glenbright Manor Puzzle in Crimson Desert
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- 8 Actors Who Could Play Blackbeard In One Piece Live-Action Season 3
- Wartales Curse of Rigel DLC Guide – Best Tips, POIs & More
- These are the 25 best PlayStation 5 games
- What are the Minecraft Far Lands & how to get there
2026-02-07 11:16