Author: Denis Avetisyan
A new approach leverages deep reinforcement learning to intelligently adapt search strategies, boosting performance on complex vehicle routing problems.
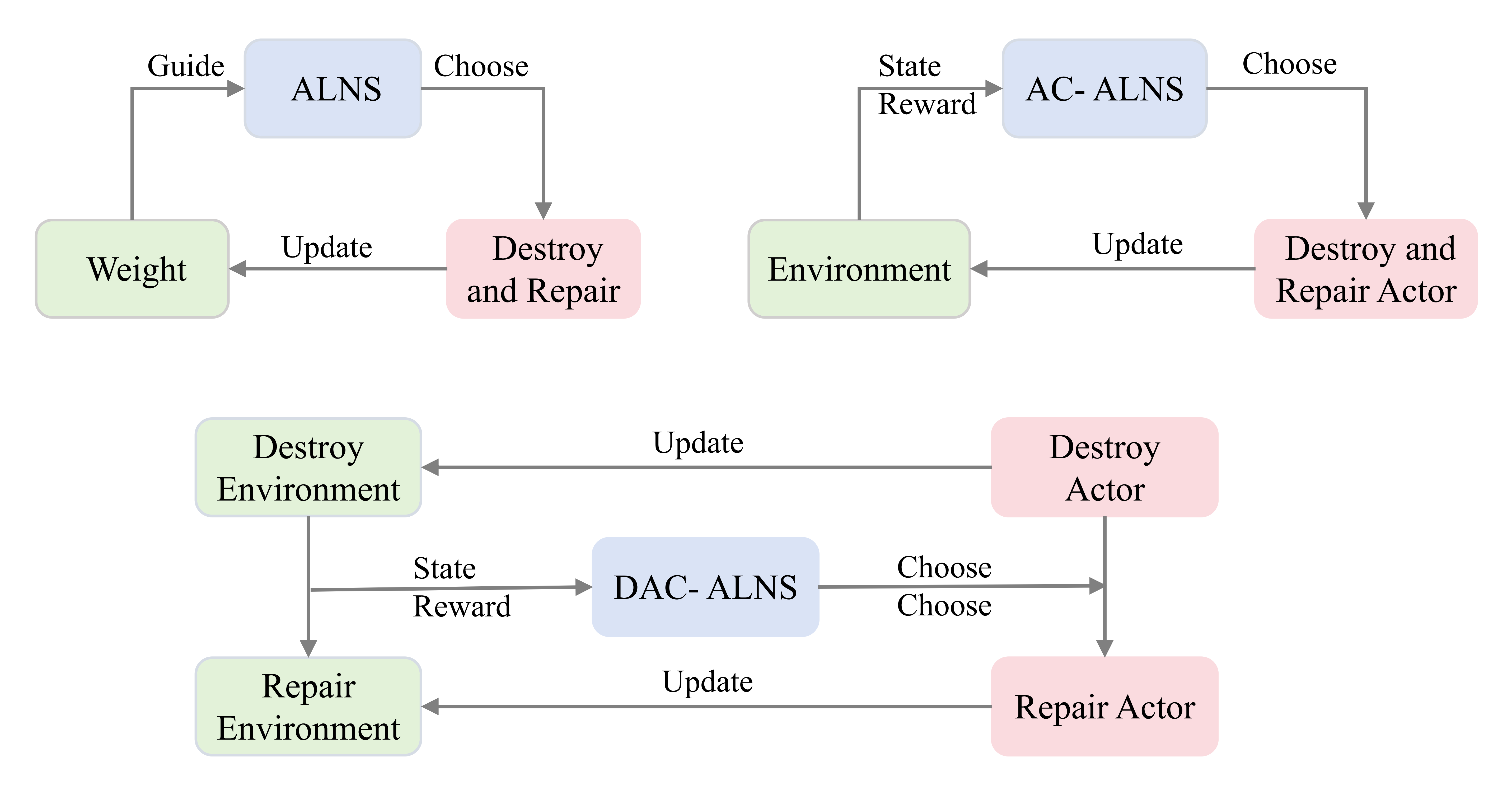
This paper introduces a dual actor-critic model, combined with graph neural networks, to enhance operator selection within the Adaptive Large Neighborhood Search algorithm.
While Adaptive Large Neighborhood Search (ALNS) effectively tackles combinatorial optimization, its traditional adaptive mechanisms often overlook the synergistic relationship between solution destruction and repair operators. This study introduces a novel approach, detailed in ‘New Adaptive Mechanism for Large Neighborhood Search using Dual Actor-Critic’, which leverages a Dual Actor-Critic model and Graph Neural Networks to intelligently guide operator selection. By modeling these processes as Markov Decision Processes and extracting key features from problem instances, the proposed method demonstrably improves solution efficiency and transferability. Could this integration of deep reinforcement learning and graph-based feature extraction unlock new levels of performance for heuristic algorithms across a broader range of complex optimization challenges?
The Inevitable Rigidity of Heuristics
Numerous real-world optimization challenges, prominently including vehicle routing and scheduling, traditionally depend on heuristic algorithms to find acceptable, though not necessarily perfect, solutions. These heuristics, while computationally efficient, often falter when confronted with intricate constraints – such as time windows, vehicle capacities, or road restrictions – or dynamic environments where conditions change rapidly. For instance, a delivery route optimized in the morning may become inefficient or impossible by afternoon due to unforeseen traffic congestion or new order requests. The inherent rigidity of many heuristics prevents them from effectively adapting to such complexities, leading to suboptimal performance and increased operational costs; thus, a need arises for more flexible and robust search strategies capable of navigating these challenging landscapes.
Adaptive Large Neighborhood Search, or ALNS, represents a significant advancement in tackling complex optimization challenges. This metaheuristic framework distinguishes itself by moving beyond fixed search strategies and instead dynamically adapting its approach during the solution process. Rather than relying on a single, pre-defined method, ALNS maintains a pool of different ‘destroy’ and ‘repair’ operators – algorithms designed to disrupt and then rebuild potential solutions. The algorithm intelligently selects which operators to apply, based on their recent performance, effectively focusing the search on promising areas of the solution space. This adaptability allows ALNS to navigate intricate problem landscapes – those with numerous constraints or constantly changing conditions – with greater efficiency and robustness than traditional heuristics, ultimately leading to higher quality solutions in a reasonable timeframe.
Adaptive Large Neighborhood Search distinguishes itself through a unique methodology of iterative refinement, systematically dismantling portions of a proposed solution before reconstructing them with alternative strategies. This ‘destroy and repair’ process isn’t random; rather, it employs a suite of operators designed to disrupt existing patterns and explore new areas of the solution space. Crucially, ALNS doesn’t treat all operators equally; it adaptively weights their selection based on their recent performance, favoring those that have previously led to improvements. This dynamic adjustment allows the search to concentrate on promising avenues while simultaneously maintaining diversity, preventing premature convergence and fostering robust solutions even in the face of complex, real-world optimization challenges. The continual assessment and refinement of these operators is central to ALNS’s ability to navigate intricate problem landscapes effectively.
The Illusion of Control Through Destruction
Traditional Adaptive Large Neighborhood Search (ALNS) implementations utilize a fixed set of destruction operators defined prior to execution. This presents a limitation as the effectiveness of these operators is highly problem-instance specific; an operator performing well on one instance may be suboptimal for another. The pre-definition prevents the algorithm from dynamically adjusting its search strategy to best suit the characteristics of the current problem, potentially leading to slower convergence or suboptimal solutions. Consequently, research has focused on methods to select and weight destroy operators during the search process, or to dynamically generate new operators, to overcome this rigidity and improve performance across diverse problem landscapes.
Destroy operators, a core component of Adaptive Large Neighborhood Search (ALNS), function by deliberately removing one or more elements from the currently evaluated solution. This process isn’t random; rather, it’s a systematic deconstruction intended to disrupt potentially stagnating solution structures and expose underlying, possibly superior, configurations. The removal creates “destruction,” generating a partial solution that is subsequently repaired using constructive heuristics. By strategically removing elements – whether based on randomness, weakness, or other criteria – the search algorithm effectively explores a wider range of possible solutions and escapes local optima, ultimately increasing the potential for improvement.
Random Removal and Worst Removal represent distinct approaches to solution space exploration within Adaptive Large Neighborhood Search (ALNS). Random Removal indiscriminately selects elements for removal, offering broad, unbiased diversification and potentially escaping local optima by chance. Conversely, Worst Removal identifies and eliminates elements deemed most detrimental to the objective function based on current evaluation criteria; this strategy prioritizes immediate improvement but risks converging prematurely on local optima. The effectiveness of each operator is problem-dependent; Random Removal performs well when the objective function is relatively flat or noisy, while Worst Removal excels when clear performance differentiators exist among solution elements. ALNS leverages both operators, dynamically adjusting their selection probabilities based on historical performance to balance intensification and diversification.
Learning to Adapt: A Fragile Victory
The Dual Actor-Critic model represents an advancement over Adaptive Large Neighborhood Search (ALNS) by integrating reinforcement learning to dynamically optimize the selection of destroy and repair operators. Traditional ALNS relies on fixed or manually tuned operator weights; this model instead learns these weights through interaction with the problem space. By framing the operator selection process as a reinforcement learning problem, the model aims to identify operator combinations that maximize solution quality based on observed performance. This adaptive approach allows the system to move beyond pre-defined heuristics and adjust its search strategy based on the specific characteristics of each instance, leading to improved performance and potentially greater robustness across different problem landscapes.
The Dual Actor-Critic model utilizes a pair of Actor networks to independently learn policies for the destroy and repair phases of the Adaptive Large Neighborhood Search (ALNS) algorithm. Each Actor network receives the current solution state as input and outputs a probability distribution over available operators for its respective process. The destroy Actor determines the probabilities for selecting operators that remove solution components, while the repair Actor governs the selection of operators used to rebuild the solution. This separation allows for specialized learning of optimal operator selection strategies for each phase, enabling the model to adapt to problem characteristics and improve solution quality beyond traditional, heuristically-defined operator weights.
The Dual Actor-Critic model incorporates a Critic network to assess the efficacy of the destroy and repair operator policies selected by the Actor networks. This evaluation functions as a reward signal within a Markov Decision Process, enabling the Actor networks to refine their policies through reinforcement learning. Empirical results demonstrate a statistically significant improvement of 0.31% over traditional Adaptive Large Neighborhood Search (ALNS) implementations when tested on large-scale Capacitated Vehicle Routing Problem (CVRP) instances, indicating the model’s ability to learn and adapt operator selection strategies for enhanced performance.
Mapping the Chaos: A Representation of Inevitable Failure
Graph Neural Networks (GNNs) represent the state of a routing problem by encoding the relationships between nodes – representing locations to be visited – as a ‘State Space’. This encoding moves beyond simple coordinate-based representations by explicitly modeling the connectivity and dependencies within the problem instance. The graph structure, comprising nodes and edges, allows the GNN to capture topological information, such as distances, travel times, and capacity constraints between locations. This representation is crucial because routing problems are inherently relational; the optimal solution depends not only on individual location characteristics but also on how those locations connect to each other and to the overall network. By learning a representation of this graph, the GNN provides a rich and informative state representation to downstream components, like Actor networks responsible for decision-making.
Graph Neural Networks (GNNs) facilitate the extraction of path features by analyzing the topological relationships within a routing problem’s graph structure. These features, derived from node and edge attributes as well as network connectivity, are then provided as input to the Actor network. Specifically, the GNN identifies characteristics like path length, congestion levels along edges, and the number of alternative routes available. This information allows the Actor network to assess the potential impact of different routing actions – such as adding, removing, or modifying paths – leading to more informed decision-making and improved solution quality. The extracted features effectively represent the spatial and contextual information inherent in the routing problem, which is critical for optimizing routes and minimizing costs.
The model leverages graph neural networks to assess how the structure of the current routing solution impacts the efficacy of subsequent solution modification operations, specifically destroy and repair actions. Empirical evaluation on large-scale Vehicle Routing Problem with Time Windows (VRPTW) instances demonstrates a statistically significant performance improvement of -0.44% using this approach, as indicated by a p-value less than 0.001. This result suggests the model’s ability to learn and exploit topological features within the solution space leads to demonstrably better routing outcomes.
The Illusion of Progress: Extending the Inevitable
The convergence of reinforcement learning and graph neural networks within the Adaptive Large Neighborhood Search (ALNS) framework promises a new era of dynamic and resilient routing capabilities. Traditional optimization algorithms often struggle with the complexities of real-world vehicle routing, such as fluctuating demand or unexpected disruptions; however, this integrated approach allows for the development of policies that learn to intelligently navigate these challenges. By leveraging graph neural networks to represent the problem space and reinforcement learning to guide the search process, ALNS can move beyond static solutions and adapt to evolving conditions. This results in routing plans that are not only efficient under normal circumstances but also remarkably robust when confronted with unforeseen events, offering a significant advantage in dynamic logistical operations and similar optimization tasks.
Traditional Adaptive Large Neighborhood Search (ALNS) relies on a suite of operators – like Greedy Repair, Random Repair, and Regret Repair – to iteratively refine solutions; however, these operators often lack the ability to dynamically adjust to the nuances of specific problem instances. Recent advancements demonstrate that integrating learned policies, derived from Graph Neural Networks and Reinforcement Learning, significantly enhances their performance. These policies effectively guide the operators, allowing them to prioritize promising moves and avoid unproductive search paths, ultimately leading to demonstrably improved solution quality. The learned policies act as a sophisticated decision-making layer, transforming formerly heuristic-based operators into adaptive components capable of responding intelligently to the problem landscape and accelerating the convergence towards optimal or near-optimal solutions.
The innovative framework extends far beyond the confines of vehicle routing problems, offering a powerful new lens through which to address a diverse range of optimization challenges within logistics and beyond. The demonstrated success of the DAC-T model – specifically, its maintained performance on unseen Capacitated Vehicle Routing Problem (CVRP) instances – highlights a remarkable capacity for generalization. Statistical analysis confirms this transferability, yielding a p-value of less than 0.0039, which suggests the model’s ability to effectively navigate novel scenarios and maintain solution quality even when faced with previously unencountered data distributions. This adaptability positions the approach as a versatile tool with the potential to unlock significant efficiency gains across multiple sectors reliant on complex logistical operations and resource allocation.
The pursuit of optimized operator selection, as detailed within this work, echoes a fundamental truth about complex systems. It isn’t about imposing a rigid structure, but fostering an environment where adaptability flourishes. This research, with its integration of deep reinforcement learning and graph neural networks, recognizes that the most robust solutions aren’t built – they emerge. As Tim Berners-Lee observed, “The web is more a social creation than a technical one.” This mirrors the adaptive Large Neighborhood Search’s reliance on learning from interactions within the problem space – a collective intelligence shaping the solution. Monitoring the performance of these operators isn’t simply about identifying failures; it’s the art of fearing consciously, anticipating shifts and allowing the system to reveal its inherent tendencies.
What Lies Ahead?
The pursuit of adaptive heuristics, as demonstrated by this work, isn’t about crafting the perfect tool – it’s about cultivating a responsive ecosystem. The application of deep reinforcement learning to operator selection within a Large Neighborhood Search framework reveals a crucial truth: the algorithm isn’t mastering the problem, it’s learning to tolerate its inherent messiness. Each carefully chosen operator isn’t a precise instrument, but a tendril, reaching for stability in a shifting landscape.
Future work will likely focus on extending this tolerance. The current paradigm assumes a relatively static problem structure, even while the search space expands. However, real-world vehicle routing, and optimization more broadly, rarely offer such consistency. A truly adaptive system must learn to anticipate, and even embrace, changes in the underlying problem itself – a move towards meta-learning, where the algorithm adapts how it adapts.
Furthermore, the reliance on graph neural networks, while effective, introduces a fragility. These models excel at recognizing patterns, but struggle with the genuinely novel. The next generation of adaptive search might explore mechanisms for constructive forgetting, allowing the system to shed obsolete knowledge and rebuild its understanding when faced with unforeseen conditions. The goal isn’t to eliminate failure, but to build a system that fails gracefully, and learns from the wreckage.
Original article: https://arxiv.org/pdf/2601.11414.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Solo Leveling’s New Manhwa Chapter Revives a Forgotten LGBTQ Story After 2 Years
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- How to Get to the Undercoast in Esoteric Ebb
- TikToker’s viral search for soulmate “Mike” takes brutal turn after his wife responds
- Nintendo Officially Rewrites Princess Peach After 41 Years
- Invincible Season 4 Episode 6 Release Date, Time, Where to Watch
- ‘Timur’ Trailer Sees Martial Arts Action Collide With a Real-Life War Rescue
- Mewgenics vinyl limited editions now available to pre-order
2026-01-20 20:49