Author: Denis Avetisyan
Researchers have developed a framework that dramatically reduces the energy demands of large language models without sacrificing performance.
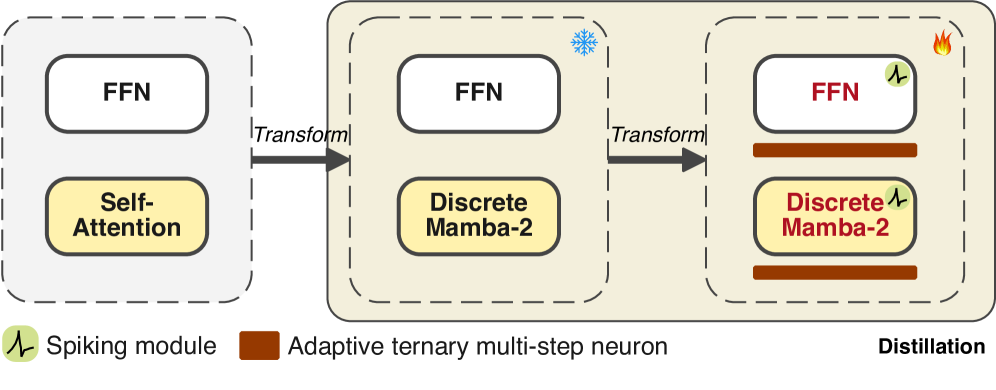
This work introduces MAR, a novel approach combining State Space Models, Spiking Neural Networks, and bidirectional knowledge distillation to refine language model architectures for improved energy efficiency.
Despite the remarkable capabilities of Large Language Models (LLMs), their computational demands pose a significant barrier to widespread deployment. This paper introduces ‘MAR: Efficient Large Language Models via Module-aware Architecture Refinement’, a novel framework that tackles this challenge by integrating State Space Models and Spiking Neural Networks with a bidirectional distillation strategy. Experimental results demonstrate that MAR substantially reduces inference energy consumption while restoring performance comparable to dense models-even outperforming efficient alternatives of similar scale. Could this module-aware refinement pave the way for truly practical and sustainable LLMs across diverse applications?
The Scaling Imperative: Confronting the Limits of Attention
The rapid advancement of Large Language Models (LLMs) has undeniably unlocked impressive capabilities in natural language processing, yet this progress comes at a considerable cost. Training and deploying these models requires immense computational resources, translating to substantial energy consumption and significant financial investment. This creates a critical barrier to entry, limiting access to researchers and developers with fewer resources and hindering broader innovation in the field. Beyond accessibility, the environmental impact of these energy demands raises concerns about the sustainable development of LLMs, prompting a growing need for more efficient architectures and training methodologies that can deliver comparable performance with a reduced carbon footprint. The current trajectory, if unchecked, risks concentrating the benefits of this technology within a limited sphere, while simultaneously exacerbating environmental pressures.
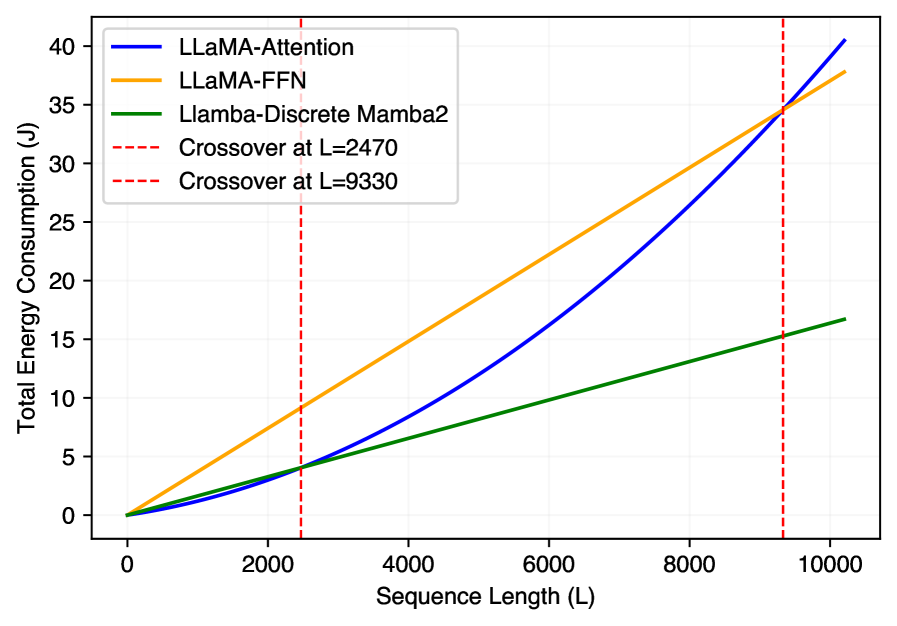
The power of Large Language Models hinges on their ability to weigh the importance of different words in a sequence, a process traditionally handled by ‘attention’ mechanisms. However, these mechanisms suffer from a critical limitation: their computational demands increase dramatically – specifically, quadratically – as the length of the input sequence grows. This means that doubling the text length quadruples the processing required, quickly becoming unsustainable for lengthy documents or complex reasoning tasks. Consequently, LLMs struggle to effectively capture ‘long-range dependencies’ – the connections between words that are far apart but crucial for understanding context and meaning. This scaling bottleneck restricts the model’s ability to process extensive information, hindering performance on tasks demanding comprehensive understanding and ultimately limiting the potential of these powerful systems.
The quadratic scaling of traditional attention mechanisms presents a substantial obstacle to effective complex reasoning within large language models. As sequence lengths increase – a necessity for grasping nuanced contexts and long-range dependencies – computational demands and memory requirements grow exponentially, quickly exceeding the capabilities of even the most powerful hardware. This limitation isn’t merely a matter of processing speed; it fundamentally impacts a model’s ability to synthesize information across extended texts, hindering performance on tasks demanding intricate logical inference, contextual understanding, and the identification of subtle relationships. Consequently, researchers are actively investigating alternative architectural designs – including sparse attention, linear attention, and state space models – that aim to achieve comparable performance with significantly improved efficiency, paving the way for more accessible and sustainable large language models capable of tackling increasingly sophisticated challenges.
Attention-Free Architectures: A Paradigm Shift in Efficiency
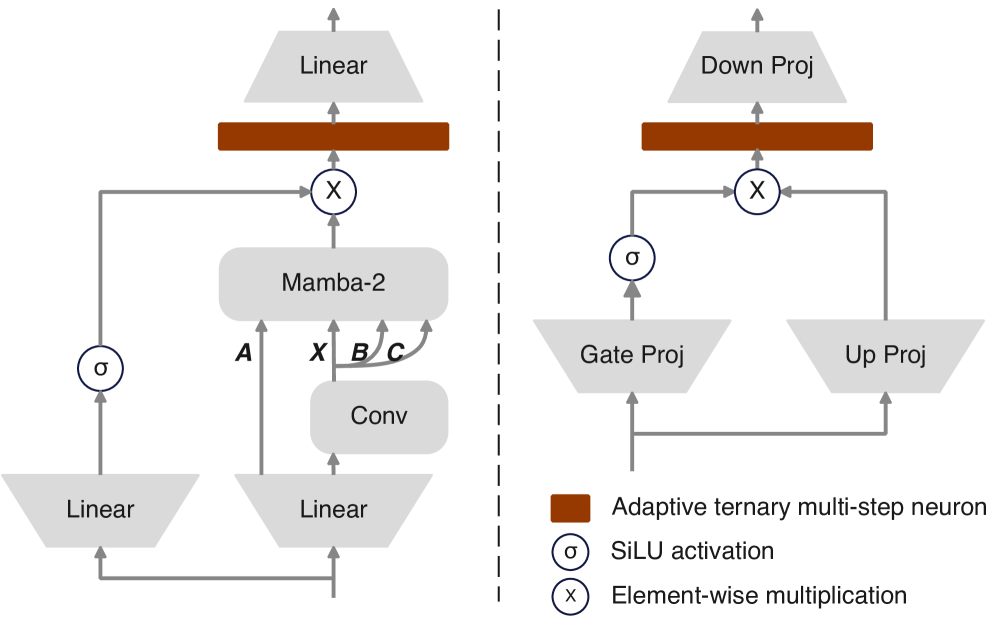
Llamba departs from the traditional Transformer architecture by eliminating attention mechanisms, instead utilizing discrete multi-head Mamba-2 modules for sequence processing. These Mamba-2 modules, based on a selective state space model (SSM), offer linear scaling in sequence length, contrasting with the quadratic complexity of attention. This is achieved through hardware-aware parallel algorithms that efficiently process sequences by selectively propagating information across the state space. The discrete implementation further enhances computational efficiency by reducing the precision requirements of the SSM, enabling faster processing and reduced memory footprint compared to continuous-time SSMs used in other attention-free models. This approach allows Llamba to achieve competitive performance on language modeling tasks while significantly reducing computational cost and latency.
Module-aware architecture refinement focuses on optimizing both attention mechanisms and Feed-Forward Networks (FFNs) within Large Language Models (LLMs) to enhance efficiency and performance. This approach moves beyond uniformly applying architectural choices, instead tailoring network components based on their specific roles and interactions. Specifically, it involves analyzing the contribution of each module – attention heads and FFN layers – and adjusting their parameters, layer ordering, or even replacing them with more efficient alternatives. The goal is to reduce redundancy and computational overhead, leading to faster inference times and lower memory requirements without sacrificing model accuracy. This optimization extends to both the forward and backward passes, ensuring efficient gradient flow during training and minimizing the overall computational cost associated with LLM operation.
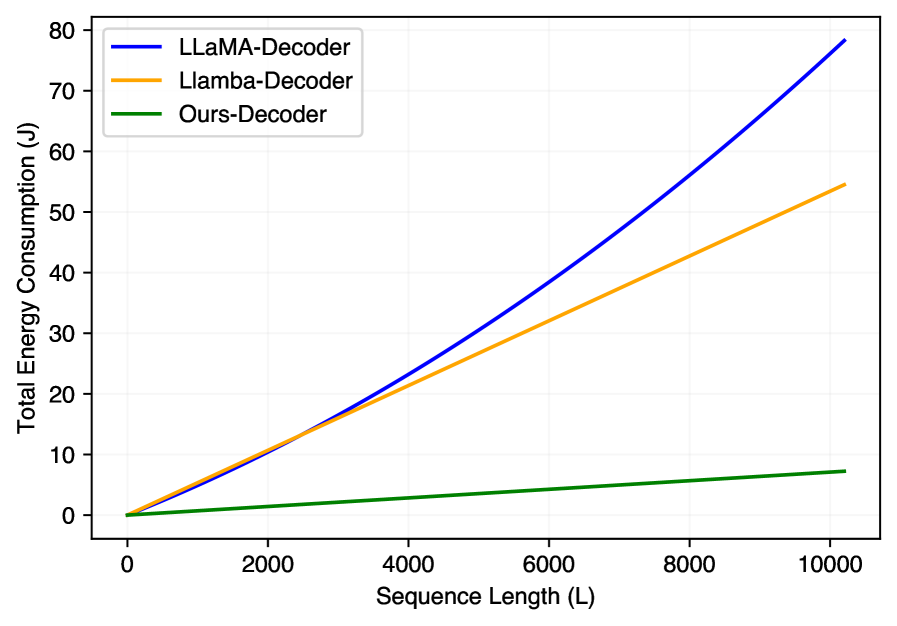
Reductions in computational complexity and energy consumption are critical for extending the applicability of Large Language Models (LLMs) to devices with limited resources. Traditional LLMs, particularly those based on the Transformer architecture, exhibit quadratic scaling with sequence length, demanding substantial memory and processing power. Innovations such as attention-free architectures and module-aware refinement aim to address this limitation by reducing the number of parameters and operations required for sequence processing. This enables the potential deployment of LLMs on edge devices, mobile phones, and other resource-constrained platforms, broadening access and facilitating real-time applications without relying on cloud-based infrastructure.
Knowledge Distillation: Compressing Intelligence for Efficiency
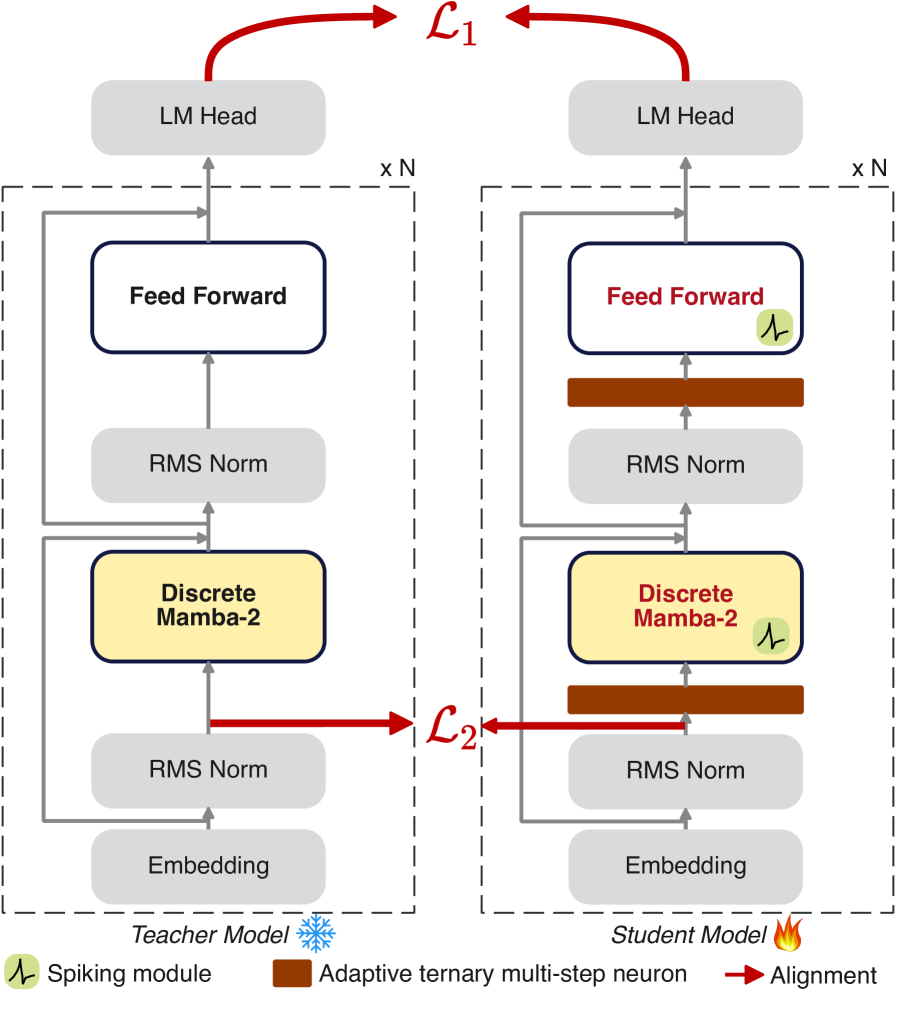
The Spike-aware Bidirectional Distillation Strategy facilitates knowledge transfer from a larger, more complex teacher model to a smaller, computationally efficient student model. This process involves not only mimicking the teacher’s outputs but also explicitly considering the “spikes” – high-activation neurons – within the teacher’s network. By focusing on these critical activations, the student model learns to prioritize the most salient features and representations. The bidirectional aspect refers to a two-way knowledge transfer process, potentially including feedback mechanisms or alignment losses that refine both the student and, in some implementations, the teacher model during training. This approach aims to compress the knowledge of a large model into a smaller one without significant performance degradation.
Pre-Normalization Alignment and Reverse KL Divergence are key components of the knowledge distillation strategy. Pre-Normalization Alignment enforces representational consistency between the teacher and student models by aligning feature distributions before normalization layers, thereby stabilizing training and improving knowledge transfer. Simultaneously, Reverse KL Divergence prioritizes the distillation of high-confidence predictions; instead of minimizing the difference between the teacher’s and student’s full probability distributions, it focuses on minimizing the divergence only for the teacher’s most probable classes, effectively transferring stronger signals to the student and improving performance on critical examples.
Knowledge distillation techniques successfully reduced the performance disparity between larger and smaller models in experimentation across six distinct tasks. The resulting student model achieved an average accuracy of 57.93%, effectively recovering a significant portion of the performance exhibited by the larger teacher model, which scored 61.88%. This distilled model, containing only 1.4 billion parameters, demonstrated a 5.45 percentage point improvement over the SpikeLLM model, indicating substantial gains in efficiency without significant accuracy loss.
Benchmarking and Validation: Demonstrating Robust Performance
A comprehensive evaluation of the proposed methods utilized a diverse suite of benchmark datasets designed to rigorously assess performance across various reasoning and question-answering challenges. These included HellaSwag, which tests commonsense inference; Winogrande, focused on pronoun resolution; the ARC suite, evaluating knowledge-based reasoning at both easy and challenging levels; Boolean Questions, requiring logical deduction; Physical Interaction QA, probing understanding of physical principles; and InfinityInstruct, a large-scale instruction-following dataset. By benchmarking against these established standards, researchers aimed to demonstrate the models’ generalization capabilities and robustness across a spectrum of cognitive tasks, providing a solid foundation for comparison with existing state-of-the-art approaches and highlighting potential areas for further refinement.
Evaluations across several established benchmarks reveal these efficient models exhibit strong capabilities in areas demanding commonsense reasoning and accurate question answering. Notably, the approach surpasses the performance of Bi-Mamba by a substantial 8.55 percentage points, achieving an overall accuracy of 57.93%. This improvement signifies a considerable step forward in developing models that can effectively navigate complex, nuanced queries and demonstrate a greater understanding of the world, suggesting potential for broader application in areas like virtual assistance and automated reasoning systems.
Refinement of the model’s learning process through bidirectional distillation loss yielded significant gains in accuracy. Specifically, employing optimal hyperparameters – an alpha value of 0.2 and a beta value of 0.7 – enabled the model to achieve an accuracy of 56.40% on key benchmark datasets. This targeted adjustment of the distillation process, which encourages the model to learn from both forward and backward passes, effectively enhanced its ability to generalize and perform robustly on complex reasoning tasks. The observed improvement underscores the sensitivity of the model to hyperparameter tuning and validates the efficacy of bidirectional distillation as a powerful technique for knowledge transfer and performance optimization.
Rigorous evaluation across diverse benchmark datasets confirms the efficacy of this novel approach to commonsense reasoning and question answering. The demonstrated performance, exceeding that of Bi-Mamba by a significant margin, isn’t merely an academic achievement; it signals a viable solution for deployment in environments where computational resources are limited. This is particularly crucial for applications ranging from mobile devices and edge computing to accessibility tools and educational platforms. By achieving strong results with potentially fewer parameters and reduced processing demands, this work paves the way for more inclusive and widespread access to advanced AI capabilities, extending the benefits of intelligent systems beyond traditional, high-powered infrastructure.
Towards Sustainable and Accessible Language AI: A Vision for the Future
The pursuit of sustainable artificial intelligence is gaining momentum through innovative architectural designs and training methodologies. Recent advancements demonstrate that attention-free architectures, which bypass the computationally intensive attention mechanisms common in large language models, can significantly reduce energy consumption without substantial performance loss. Crucially, these streamlined models are paired with effective knowledge distillation strategies, where a larger, more accurate model transfers its knowledge to a smaller, more efficient one. This combination allows for the creation of language AI systems that require fewer computational resources, lowering both the financial and environmental costs associated with their operation. The result is a pathway towards democratizing access to powerful language technologies, potentially enabling deployment on edge devices and broadening applications across resource-constrained settings.
Current artificial intelligence models, particularly those driving large language applications, demand substantial computational resources and energy. Emerging research explores radically different neural network architectures to address this challenge. Spiking neural networks, inspired by the biological brain, operate with discrete, event-driven spikes rather than continuous values, promising significant energy efficiency gains. Complementing this, adaptive ternary multi-step neurons-which utilize only three states and multiple processing steps-offer a further reduction in computational complexity. These advancements aren’t simply about miniaturization; they represent a fundamental shift in how AI processes information, potentially enabling deployment on resource-constrained devices and fostering a more sustainable future for artificial intelligence. The continued development of these neuromorphic approaches could dramatically lower the carbon footprint associated with increasingly powerful language technologies.
The pursuit of streamlined, efficient language AI models isn’t merely a technical exercise; it fundamentally reshapes who can leverage these powerful tools. Historically, the substantial computational demands of large language models have concentrated access within organizations possessing significant resources. Reducing those demands, through innovations in model architecture and training, directly lowers the barrier to entry for researchers, developers, and communities previously excluded. This democratization unlocks a cascade of potential – from localized language support for under-represented dialects to accessible educational resources tailored to individual needs, and the deployment of AI-driven solutions in resource-constrained environments. Ultimately, a more sustainable and accessible AI landscape promises to broaden participation in the ongoing evolution of language technology and accelerate its positive impact across a diverse range of fields, fostering innovation far beyond the current limitations.
The pursuit of efficient large language models, as detailed in this work, echoes a fundamental tenet of computational elegance. The framework, MAR, seeks to minimize energy consumption through architectural refinement and distillation-a process inherently focused on identifying and preserving essential computational components. This aligns perfectly with Donald Davies’ assertion: “Simplicity is a prerequisite for reliability.” The paper’s emphasis on state space models and spiking neural networks isn’t merely about achieving lower power usage; it’s about constructing a provably more efficient system. The bidirectional distillation strategy, particularly, exemplifies this; it distills knowledge into a streamlined architecture, mirroring the search for a mathematically pure, and thus reliable, algorithmic solution.
What Lies Ahead?
The pursuit of energy-efficient large language models, as exemplified by this work, inevitably confronts a fundamental tension. While architectural refinement and distillation techniques demonstrably reduce computational cost, the underlying problem remains: the sheer scale of parameters required to achieve compelling performance. Module-aware architecture refinement, though a pragmatic step, does not address the theoretical limitations of current sequence modeling paradigms. A truly elegant solution will likely necessitate a shift towards more mathematically principled approaches-algorithms where reduction in parameters is guaranteed by inherent structure, not merely achieved through empirical optimization.
Furthermore, the reliance on knowledge distillation introduces a subtle, yet crucial, vulnerability. The ‘student’ model, however refined, is inherently bound by the limitations of its ‘teacher’. Reproducibility, a cornerstone of scientific rigor, becomes problematic if the teacher’s internal state is not perfectly captured, or if the distillation process itself introduces stochasticity. The deterministic nature of a provably correct algorithm remains the ideal, a standard against which these approximations must be measured.
The question is not simply ‘how much energy can be saved?’, but rather ‘can we construct a system where computational cost is fundamentally decoupled from model capacity?’. Until the field prioritizes theoretical guarantees over empirical benchmarks, the promise of truly sustainable and reliable large language models will remain, at best, an asymptotic approach.
Original article: https://arxiv.org/pdf/2601.21503.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- How to Get to the Undercoast in Esoteric Ebb
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- All Itzaland Animal Locations in Infinity Nikki
- Warframe Voruna Prime access begins on April 8 for all platforms, new deluxe cosmetic Warframe skins revealed
- Zendaya’s 4 Big 2026 Movies Could Beat Brie Larson’s Box 2019 Office Record
- Dakota County’s plan to end hunger involves locking mayors in escape rooms
2026-02-01 02:06