Author: Denis Avetisyan
Researchers have developed a streamlined machine learning framework that significantly improves the accuracy of short-term river flow and peak flood predictions.
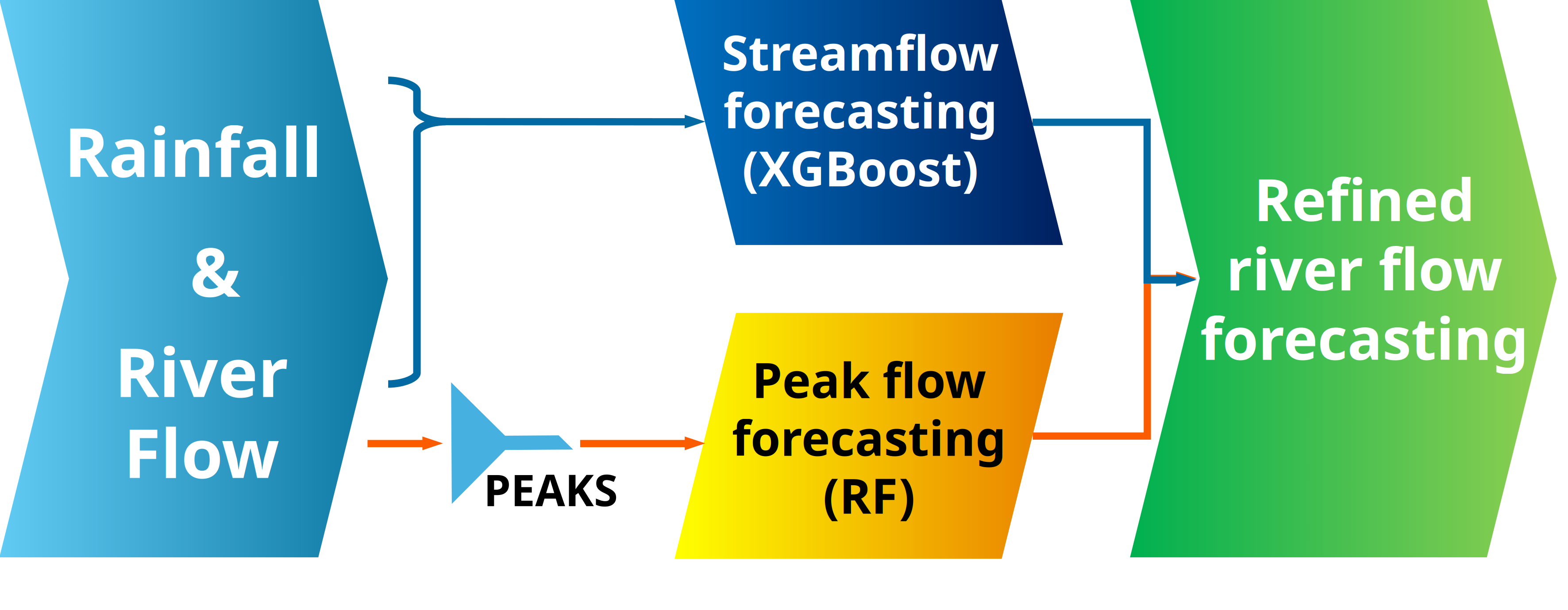
A hybrid XGBoost and Random Forest model demonstrates superior performance in short-term peak-flow forecasting compared to existing hydrological systems like EFAS.
Despite advances in hydrological modeling, accurately forecasting peak river flows-critical for effective flood management-remains a persistent challenge, particularly during extreme events. This study introduces ‘A Hybrid Machine Learning Framework for Improved Short-Term Peak-Flow Forecasting’ which couples the strengths of XGBoost and Random Forest to enhance both continuous streamflow and peak-flow prediction. Results across a large catchment dataset demonstrate substantially improved forecasting accuracy and a reduction in false alarms compared to established systems like EFAS. Could this lightweight, transferable framework represent a new paradigm for operational flood forecasting, and how might it be further integrated with evolving hydrological understanding?
The Inevitable Rise and Fall of Forecasts
Conventional flood prediction relies on intricate models attempting to synthesize atmospheric conditions – rainfall, temperature, evaporation – with the physical characteristics of a river basin, including topography, soil composition, and channel geometry. However, these systems frequently falter because the relationships between these factors are rarely linear; small changes in rainfall can trigger disproportionately large flood events due to complex feedback loops and cascading failures within the watershed. Furthermore, accurately representing these interactions requires enormous computational power and detailed, high-resolution data, often unavailable, especially in rapidly changing or remote environments. Consequently, predictions can be significantly off, leading to underestimated risks, inadequate preparation, and ultimately, increased vulnerability for communities situated within floodplains.
Existing flood prediction models often falter due to an inability to synthesize the multitude of factors influencing river behavior. Traditional methods typically treat data streams – such as rainfall, snowmelt, soil moisture, and river gauge readings – in isolation, overlooking crucial interactions. River systems, however, rarely respond linearly to these inputs; a small increase in rainfall, combined with already saturated ground, can trigger disproportionately large flooding. Furthermore, topographic complexity, vegetation cover, and even human infrastructure create intricate feedback loops that are difficult for conventional models to represent accurately. Consequently, predictions often fail to capture the full range of possible outcomes, particularly during extreme events, highlighting the need for more holistic and adaptive modeling techniques capable of embracing the inherent non-linearities of these dynamic systems.
Recognizing the shortcomings of conventional flood prediction, researchers are increasingly focused on developing novel frameworks powered by advanced machine learning. These systems move beyond traditional physics-based models by embracing data-driven approaches capable of identifying complex, non-linear relationships within hydrological systems. By integrating diverse datasets – encompassing real-time precipitation measurements, river gauge readings, topographical information, and even satellite imagery – machine learning algorithms can learn to predict flood events with greater accuracy and lead time. This shift promises not only improved forecasts, but also the ability to quantify uncertainty and provide probabilistic predictions, ultimately enabling more effective risk management and mitigation strategies for vulnerable communities.
Bridging the Gap: A Hybrid Approach to Flow Prediction
The streamflow forecasting component of this framework leverages the XGBoost regression algorithm due to its demonstrated capacity for modeling non-linear relationships within time series data. XGBoost achieves high accuracy by iteratively building an ensemble of decision trees, with each subsequent tree correcting errors made by prior trees. This process, combined with regularization techniques to prevent overfitting, allows the model to effectively utilize historical data-specifically, past streamflow measurements and associated predictor variables-to generate precise streamflow predictions. Feature engineering, involving the creation of lagged variables and rolling statistics, further enhances XGBoost’s ability to capture temporal dependencies and improve forecasting performance.
Random Forest is utilized for peak flow forecasting due to its capacity to model non-linear relationships within hydrological data, which is essential for accurately predicting extreme flow events. Unlike linear regression models, Random Forest, an ensemble learning method constructed from multiple decision trees, can capture complex interactions and thresholds that govern peak flow generation. This is achieved by randomly selecting subsets of features and data points for each tree, reducing overfitting and improving generalization performance on unseen data. The algorithm’s inherent ability to handle high-dimensional data and identify important variables makes it well-suited for the complex processes driving peak flows, where multiple factors interact in non-linear ways to produce extreme events.
To improve the accuracy of the XGBoost streamflow forecasting model, the system incorporates both lag features and rolling statistics calculated from historical rainfall and river discharge data. Lag features represent past values of these variables at different time steps, allowing the model to recognize temporal dependencies. Specifically, these features include rainfall and discharge values from previous days, weeks, or months. Rolling statistics, such as mean, standard deviation, and percentiles, are calculated over a defined moving window, capturing the recent trends and variability in the data. These features provide the XGBoost model with a richer dataset, enabling it to better discern patterns and improve predictive performance by accounting for the influence of past conditions on current streamflow.
Validation and the Measured Performance of Prediction
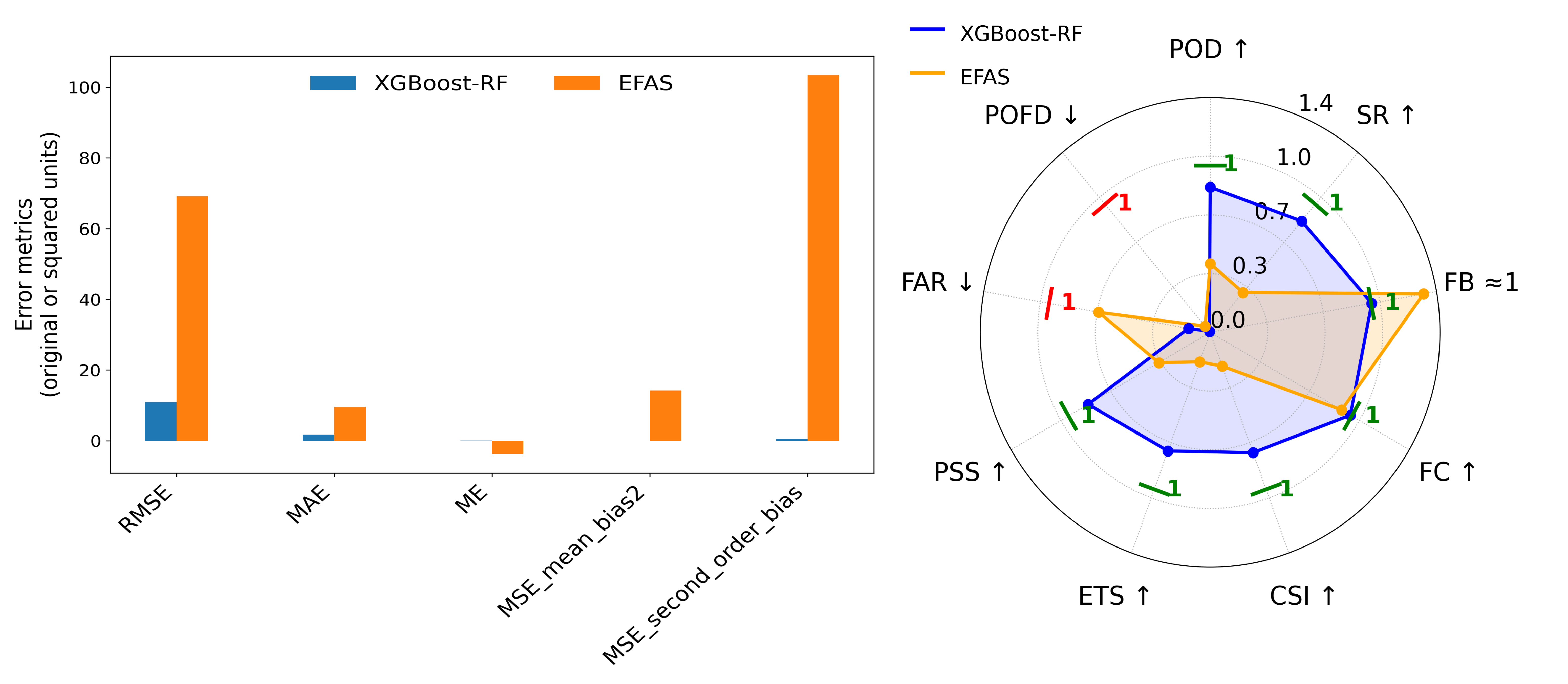
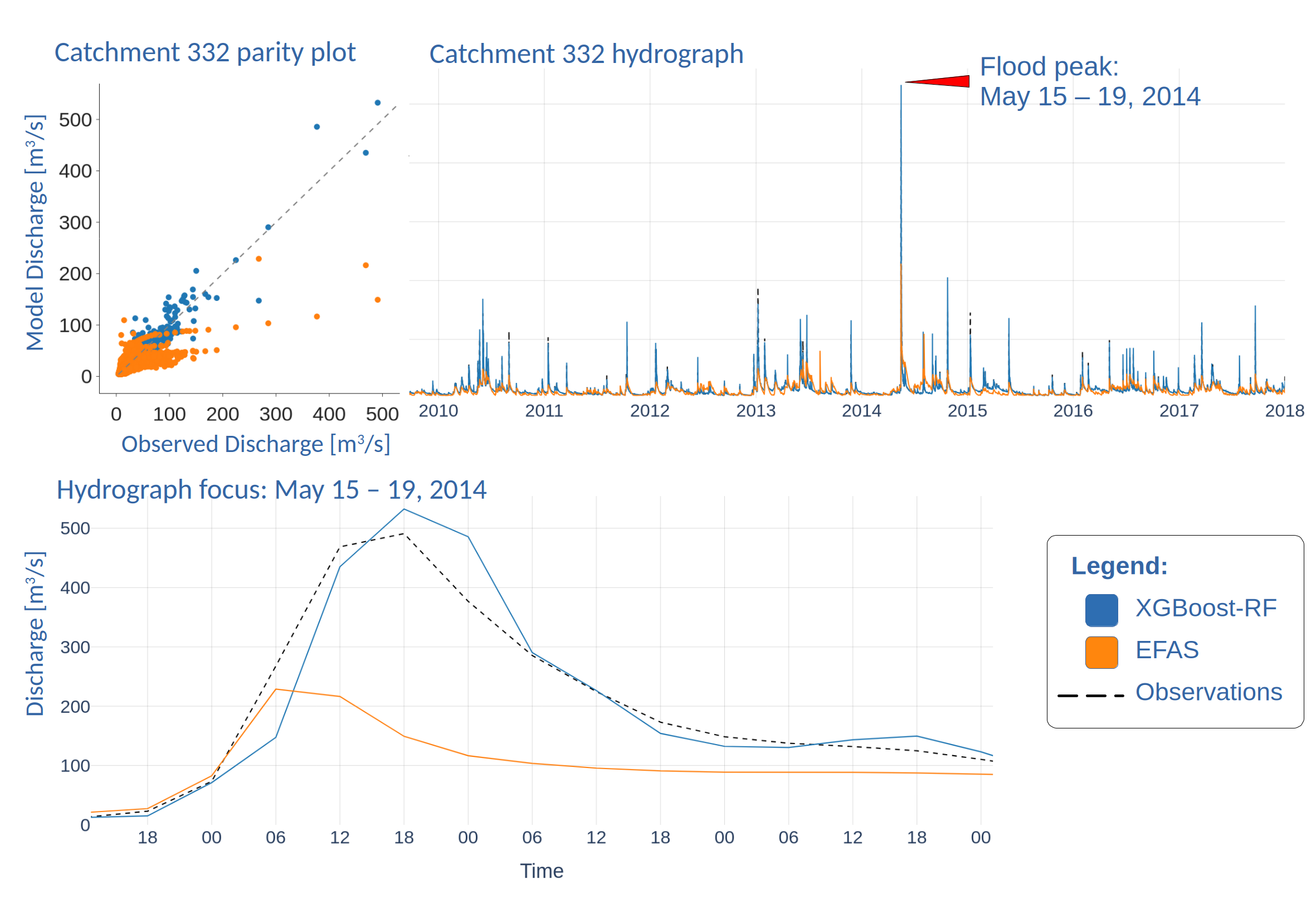
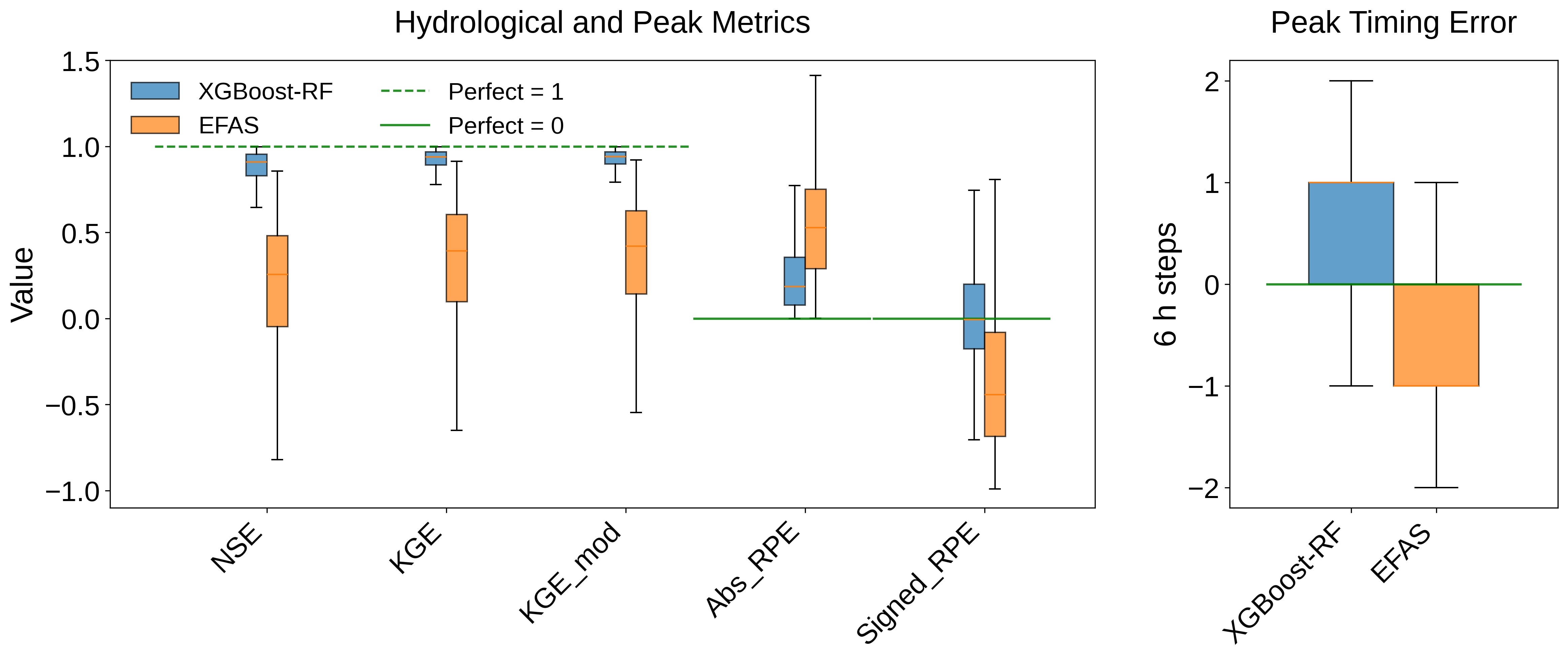
The proposed framework underwent rigorous evaluation utilizing the LamaH-CE dataset, yielding demonstrably improved performance based on established hydrological metrics. Specifically, the framework achieved a higher Nash-Sutcliffe Efficiency (NSE) and Kling-Gupta Efficiency (KGE) score compared to baseline models when tested against the LamaH-CE dataset. These metrics quantify the accuracy of predicted streamflow against observed values, with higher scores indicating better model performance and a reduced tendency for over- or under-estimation. The LamaH-CE dataset provided a comprehensive and diverse set of hydrological data for robust assessment of the framework’s predictive capabilities.
Binary verification metrics were employed to rigorously assess the reliability and skill of flood forecasts generated by the proposed framework. These metrics, focusing on event-based prediction, categorize forecasts and observations into binary outcomes – event/no-event – allowing for the calculation of statistics like Probability of Detection (POD), False Alarm Rate (FAR), and Success Ratio (SR). POD quantifies the proportion of observed flood events that were correctly forecast, while FAR indicates the proportion of forecasts that incorrectly predicted a flood when none occurred. SR represents the ratio of correctly forecast flood events to all forecasts related to flood events, providing a comprehensive measure of forecast accuracy for identifying and predicting flood occurrences.
Comparative analysis with the European Flood Awareness System (EFAS) demonstrates enhanced predictive capabilities in our framework for both streamflow and peak flow events. The framework achieved an 87% detection rate with a corresponding false alarm rate of approximately 13%. Quantitative metrics reveal a Probability of Detection (POD) of 0.87, a substantial improvement over EFAS’s POD of 0.41. Furthermore, the framework’s Success Ratio (SR) of 0.87 significantly exceeds EFAS’s SR of 0.31, indicating a higher proportion of correctly predicted events among all predicted events.
Toward Resilience: Adapting to the Inevitable Flow of Time
This integrated framework delivers increasingly precise flood predictions, fundamentally shifting the capacity for proactive disaster management. Accurate forecasts enable authorities to issue timely warnings, allowing communities to prepare and evacuate, thereby significantly reducing potential loss of life and property damage. Beyond immediate safety, reliable predictions empower informed decision-making regarding infrastructure protection, resource allocation, and the implementation of preventative measures such as bolstering flood defenses or adjusting water management strategies. Consequently, this approach moves beyond reactive disaster response toward a more resilient and sustainable relationship with flood events, minimizing their disruptive impact on both human populations and critical infrastructure.
Contemporary flood risk assessment and management are undergoing a transformation through the synergistic integration of diverse data sources and advanced machine learning techniques. Historically reliant on limited hydrological data, current approaches now incorporate satellite imagery, terrain models, meteorological forecasts, and even social media reports to create a more holistic picture of flood potential. Machine learning algorithms, particularly deep learning models, are then employed to analyze these complex datasets, identifying subtle patterns and predicting flood events with increasing accuracy. This allows for the creation of high-resolution risk maps, improved early warning systems, and the optimization of mitigation strategies, ultimately bolstering community resilience and minimizing the devastating impacts of flooding on critical infrastructure and human life.
Ongoing development prioritizes a dynamic system capable of leveraging continuously updating information; researchers aim to integrate real-time data streams from sources like river gauges, weather radar, and citizen science initiatives to refine predictive accuracy. Furthermore, exploration of ensemble modeling – combining multiple predictive models to account for uncertainty – promises more robust and reliable flood forecasts. Crucially, this framework is not intended as a universal solution; future efforts will concentrate on adapting the methodology to the unique hydrological characteristics and topographical features of diverse geographical regions and river basins, ensuring its effectiveness in a variety of environmental contexts and enhancing localized flood resilience.
The pursuit of accurate peak-flow forecasting, as demonstrated by this hybrid machine learning framework, reveals a fundamental truth about complex systems. While the combination of XGBoost and Random Forest offers improved performance over existing models like EFAS, it doesn’t halt the inevitable march of entropy. Each model, no matter how refined, operates within a temporal context; its predictive power will diminish as conditions evolve. As Leonardo da Vinci observed, “Every painter who does not make something new is not a painter.” Similarly, every forecasting system requires continual adaptation and refinement, acknowledging that stability is often merely a delay of the inherent instability within hydrological systems. The framework’s success isn’t about achieving a static perfection, but about gracefully managing the decay inherent in all predictive endeavors.
What Lies Ahead?
The presented framework, while demonstrating a refinement in short-term peak-flow forecasting, merely shifts the inevitable entropy. Every commit is a record in the annals, and every version a chapter, yet the fundamental challenge of hydrological prediction-extrapolating from incomplete and noisy data-remains. The gains achieved through this hybrid approach are not about solving the problem, but about delaying its symptomatic failures. The system’s lightweight nature is a pragmatic concession, acknowledging that complexity isn’t always progress, but frequently a prelude to brittle cascades.
Future iterations must address the limitations inherent in any data-driven model: the creeping influence of non-stationarity, the difficulty of representing extreme events within historical bounds, and the unavoidable accumulation of forecast error. A crucial step involves explicit incorporation of uncertainty quantification-not as an afterthought, but as a foundational element of the framework. Delaying fixes is a tax on ambition; acknowledging the limits of prediction is not defeatism, but a necessary condition for responsible forecasting.
The field now faces a choice: pursue ever-more-elaborate models, or focus on developing robust methods for assessing and communicating predictive uncertainty. The former risks accelerating the system’s decay, while the latter offers a path towards graceful aging. The true metric isn’t accuracy, but resilience – the capacity to maintain utility even as the underlying assumptions erode.
Original article: https://arxiv.org/pdf/2601.09336.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Mewgenics vinyl limited editions now available to pre-order
- Invincible Season 4 Episode 6 Release Date, Time, Where to Watch
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Crimson Desert Guide – How to Pay Fines, Bounties & Debt
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
2026-01-15 17:59