Author: Denis Avetisyan
New research introduces a method for identifying and eliminating redundant information in multi-modal datasets, boosting analytical performance and reducing storage costs.
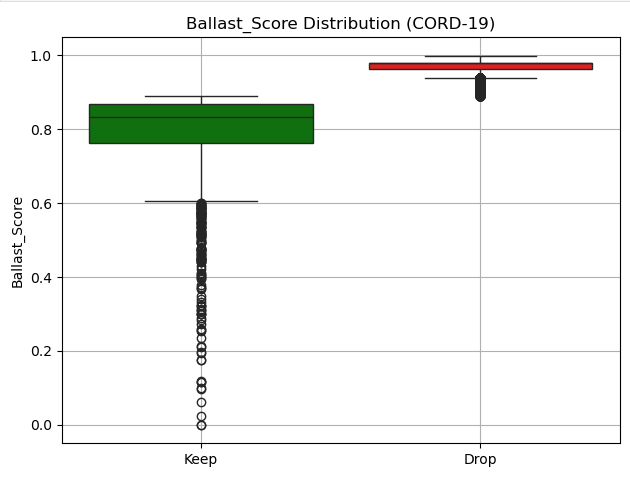
This work quantifies and systematically reduces ‘ballast information’-data that adds computational burden without contributing to meaningful insights-using machine learning and information theory.
Modern datasets increasingly suffer from redundant or low-utility information that inflates dimensionality and computational cost without contributing to analytical value. This challenge is addressed in ‘ML-driven detection and reduction of ballast information in multi-modal datasets’, which introduces a generalized framework for identifying and pruning such ‘ballast’ across structured, semi-structured, unstructured, and sparse data. By integrating information-theoretic measures, feature selection techniques, and dimensionality reduction methods-culminating in a novel Ballast Score-this work demonstrates that substantial portions of feature space can often be removed with minimal performance impact, and even improved classification accuracy. Could this approach unlock more efficient and interpretable machine learning pipelines, particularly in resource-constrained environments?
The Illusion of Signal: Why More Data Isn’t Always Better
Contemporary datasets, though seemingly comprehensive due to their sheer volume, frequently incorporate what is termed ‘ballast information’ – data that, while technically valid and conforming to expected formats, contributes little to meaningful analysis. This isn’t necessarily erroneous data; rather, it represents observations with minimal signal relative to the noise, or features that lack predictive power for the intended task. The proliferation of automated data collection and the increasing granularity of measurements contribute to this phenomenon, resulting in datasets bloated with details that obscure genuinely informative elements. Consequently, analyses must contend with increased computational demands, extended processing times, and a diminished capacity to discern true patterns, highlighting a critical need for strategies to identify and manage this hidden inefficiency within big data.
Modern datasets, while seemingly valuable due to their sheer size, frequently contain a substantial proportion of non-informative data – termed ‘ballast’ – which significantly impacts analytical efficiency. Studies reveal this ballast, technically valid but lacking meaningful signal, can account for between 15% and 40% of the total data volume across various data types, including images, text, and sensor readings. This excess data directly increases computational costs for storage and processing, obscures the relevant patterns researchers seek, and ultimately diminishes the performance of machine learning models trained on these datasets. Consequently, the presence of this ballast represents a hidden inefficiency, demanding novel data handling strategies to maximize the utility of increasingly large datasets.
Current data preparation techniques commonly operate under the assumption that all collected data points contribute meaningfully to analytical outcomes. This approach, while simplifying the preprocessing pipeline, overlooks the inherent variability in data informativeness – a critical flaw when datasets contain substantial ‘ballast information’. Standard methods like normalization, cleaning, and feature scaling are applied uniformly, regardless of whether a particular data element genuinely strengthens model signal or merely adds computational burden. Consequently, valuable resources are allocated to processing data that offers little to no predictive power, ultimately diminishing analytical efficiency and potentially obscuring genuinely important patterns within the data. This uniform treatment stands in contrast to the potential benefits of strategies that prioritize and emphasize the most informative data elements, allowing for leaner, more effective model building.
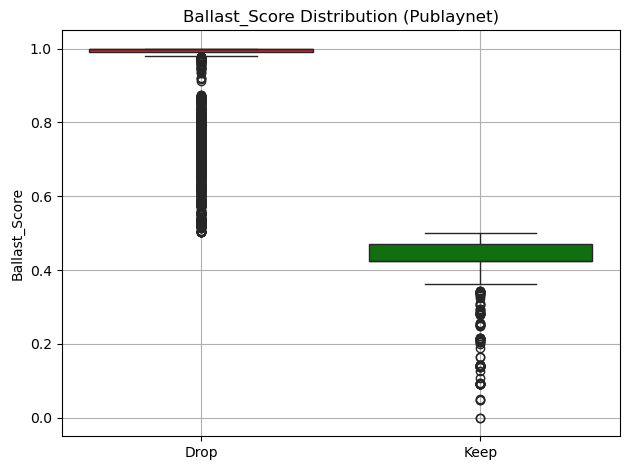
Stripping the Fat: A Framework for Data Efficiency
The Ballast Detection Framework is designed to systematically identify and mitigate the effects of low-value data, defined as data that contributes minimally to predictive power or analytical insight. This is achieved through a multi-stage process involving data profiling to establish baseline metrics, feature evaluation using statistical methods to determine relevance, and targeted reduction of non-contributing features or data points. The framework doesn’t simply remove data; it quantifies the impact of removal on key performance indicators, allowing for a data-driven assessment of the trade-off between data volume and analytical efficacy. This comprehensive approach ensures that data reduction efforts are demonstrably beneficial and do not inadvertently compromise model accuracy or analytical robustness.
The Ballast Detection Framework employs feature selection and dimensionality reduction to enhance data efficiency by identifying and removing low-value data, termed “ballast.” Feature selection techniques prioritize the most relevant features, while dimensionality reduction methods, such as Principal Component Analysis (PCA) or t-distributed stochastic neighbor embedding (t-SNE), transform the data into a lower-dimensional space while preserving essential information. This process minimizes storage requirements and computational load, leading to improved model training times and reduced resource consumption. Specifically, the framework utilizes sparse matrix representations, like Compressed Sparse Row (CSR) format, to efficiently store and process semi-structured data, demonstrated by a 95.68% storage reduction in recent tests.
The Ballast Detection Framework assesses feature relevance through correlation analysis and statistical dependence measures to identify and eliminate low-value data. Specifically, the framework utilizes sparse matrix compression, employing the Compressed Sparse Row (CSR) format, on semi-structured datasets. Implementation of CSR compression resulted in a demonstrated storage reduction of 95.68% during testing, indicating a significant improvement in data storage efficiency by minimizing redundant or irrelevant feature representation.
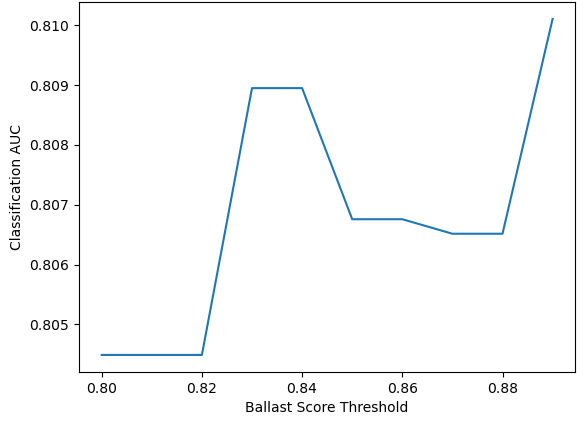
Dissecting the Signal: Methods for Feature Relevance
Lasso Regression, a linear regression technique incorporating L1 regularization, effectively identifies and eliminates irrelevant features in structured datasets by shrinking the coefficients of less important variables to zero. This feature selection process is performed during model training, simplifying the model and reducing overfitting. Complementing Lasso, SHAP (SHapley Additive exPlanations) values provide a game-theoretic approach to explain the output of any machine learning model, including those built with Lasso Regression. SHAP values quantify the contribution of each feature to the prediction, allowing for a granular assessment of feature relevance and validation of the features eliminated by Lasso. Combined, these methods offer both automated feature selection and interpretable insights into feature importance, enhancing model robustness and understanding.
For unstructured and semi-structured datasets, determining feature relevance necessitates techniques beyond those suited for tabular data. Term Frequency-Inverse Document Frequency (TF-IDF) quantifies word importance by weighting terms based on their frequency within a document and rarity across the corpus. Entropy, measured in bits, assesses the uncertainty or information content of word distributions, identifying terms that contribute most to distinguishing documents. Latent Dirichlet Allocation (LDA) is a generative probabilistic model that discovers underlying topical structures within a collection of documents, assigning probabilities to words belonging to each topic and enabling the identification of key themes; this facilitates relevance assessment by highlighting terms strongly associated with dominant topics.
Sparse datasets, typically exhibiting a high number of features relative to samples, necessitate specific methodological considerations for feature selection and dimensionality reduction. Entropy-based methods, while applicable, require careful parameter tuning to avoid instability or the retention of redundant features. In recent analyses of sparse data, the application of targeted feature selection techniques resulted in the retention of only 26 principal components while maintaining 85% of the original data’s variance; this demonstrates an effective reduction in dimensionality without significant information loss, and highlights the potential of these techniques to improve model performance and reduce computational costs in high-dimensional scenarios.
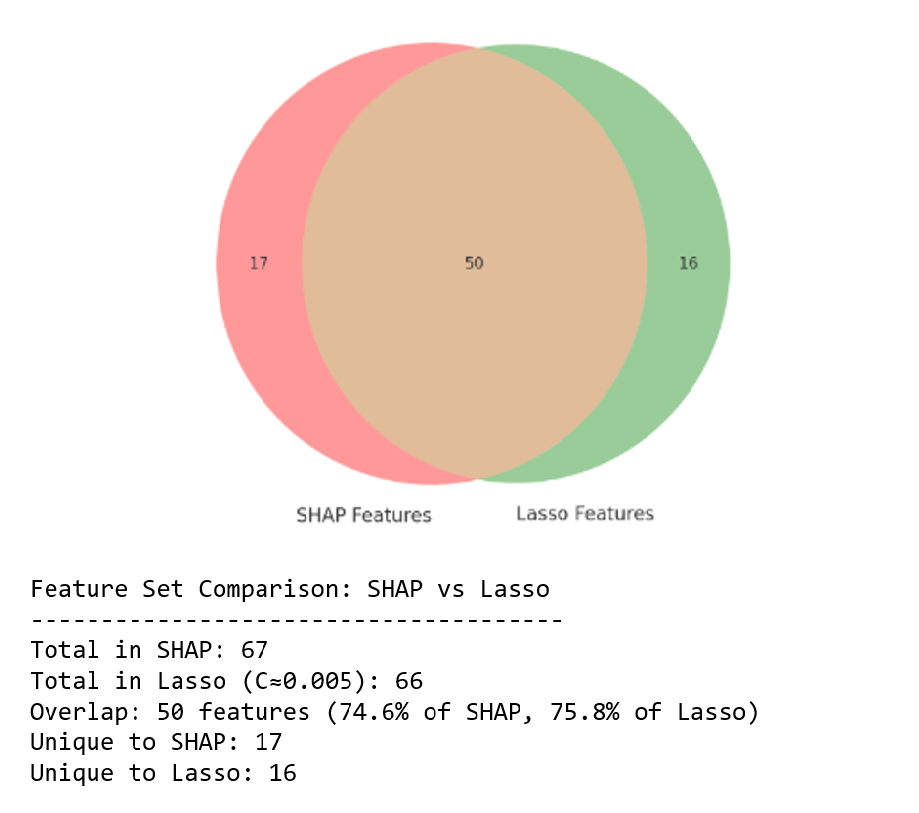
Beyond Correlation: Quantifying Data ‘Noise’
The concept of ‘Ballast’ in data science identifies features that contribute little to a model’s predictive power while simultaneously increasing computational load and obscuring meaningful patterns. A quantifiable ‘Ballast Score’ assesses this redundancy and lack of analytical contribution, moving beyond subjective feature selection. This score isn’t determined by simple correlation; instead, it leverages information-theoretic measures like Entropy and Mutual Information to evaluate a feature’s unique contribution to reducing uncertainty in the target variable. Features yielding high Ballast Scores are essentially ‘dead weight’ – offering minimal insight relative to their cost – and their removal can streamline models, enhance interpretability, and, crucially, improve generalization performance by reducing overfitting to irrelevant noise.
The Ballast Score leverages established information theory principles – specifically, Entropy and Mutual Information – to provide a standardized metric for evaluating feature relevance, irrespective of data modality. Entropy, a measure of uncertainty, quantifies the inherent randomness within a feature, while Mutual Information assesses the reduction in this uncertainty when considering the relationship between a feature and the target variable. By combining these metrics, the Ballast Score effectively determines how much unique information a feature contributes; features exhibiting low scores indicate high redundancy or minimal predictive power. This approach allows for consistent evaluation across diverse data types – from numerical values and categorical variables to text and images – facilitating a universal framework for feature selection and dimensionality reduction. The result is a quantifiable assessment of feature ‘noise’ that isn’t tied to specific algorithms or datasets, ensuring broad applicability and comparability.
Prioritizing features with minimal analytical contribution, as quantified by the Ballast Score, demonstrably refines model efficiency and clarity. Studies reveal that removing these low-value features – often termed ‘ballast’ – leads to a significant reduction in data volume; an average of 41% was observed in unstructured datasets. This streamlining not only lowers computational demands but also consistently improves classification performance, suggesting the elimination of redundant or misleading information – semantic noise – allows models to focus on genuinely predictive signals. The resulting models are therefore not only faster and more cost-effective, but also more transparent and easier to interpret, fostering greater trust and understanding in their outputs.
The pursuit of data efficiency, as outlined in this research regarding ‘ballast information’, feels predictably Sisyphean. It meticulously details methods for identifying and shedding non-contributing data, but one can almost guarantee that ‘ballast’ will simply re-manifest in a new, more insidious form. Donald Davies famously observed, “It’s always the bits you don’t know about that cause the trouble.” And so it is with data; the moment one believes they’ve optimized for sparsity and analytical value, production will inevitably reveal previously unseen dependencies, shadow features, or entirely new dimensions of ‘ballast’ that require further ‘reduction’. They’ll call it AI and raise funding, naturally, but the fundamental problem remains: complexity always outpaces comprehension.
What Remains?
The pursuit of ‘ballast information’-data deemed non-contributory-feels suspiciously like an attempt to legislate against entropy. The framework presented here offers a method for identifying this excess, a welcome development, though one suspects production systems will swiftly demonstrate the limitations of any pre-defined ‘meaningful’ analytical value. What appears superfluous today may prove essential when someone inevitably asks a question no one anticipated.
The emphasis on sparsity is sensible, given current hardware constraints, but it’s a temporary reprieve. The history of computing is largely the history of discarding temporary fixes. Future work will undoubtedly focus on automated ballast detection, and perhaps even ‘just-in-time’ data acquisition. The more intriguing challenge, however, lies in defining ‘information’ itself-a philosophical quagmire disguised as an engineering problem.
Ultimately, this research reinforces a familiar truth: better one carefully curated monolith than a hundred lying microservices, each claiming to hold only ‘essential’ data. The illusion of efficiency is potent, but the logs will always tell the real story.
Original article: https://arxiv.org/pdf/2602.16876.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- How to Get to the Undercoast in Esoteric Ebb
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Warframe Voruna Prime access begins on April 8 for all platforms, new deluxe cosmetic Warframe skins revealed
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- All Itzaland Animal Locations in Infinity Nikki
- Zendaya’s 4 Big 2026 Movies Could Beat Brie Larson’s Box 2019 Office Record
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- Dakota County’s plan to end hunger involves locking mayors in escape rooms
2026-02-21 22:11