Author: Denis Avetisyan
New research demonstrates how advanced AI can sift through online intelligence to identify potential cyberattacks before they fully materialize.
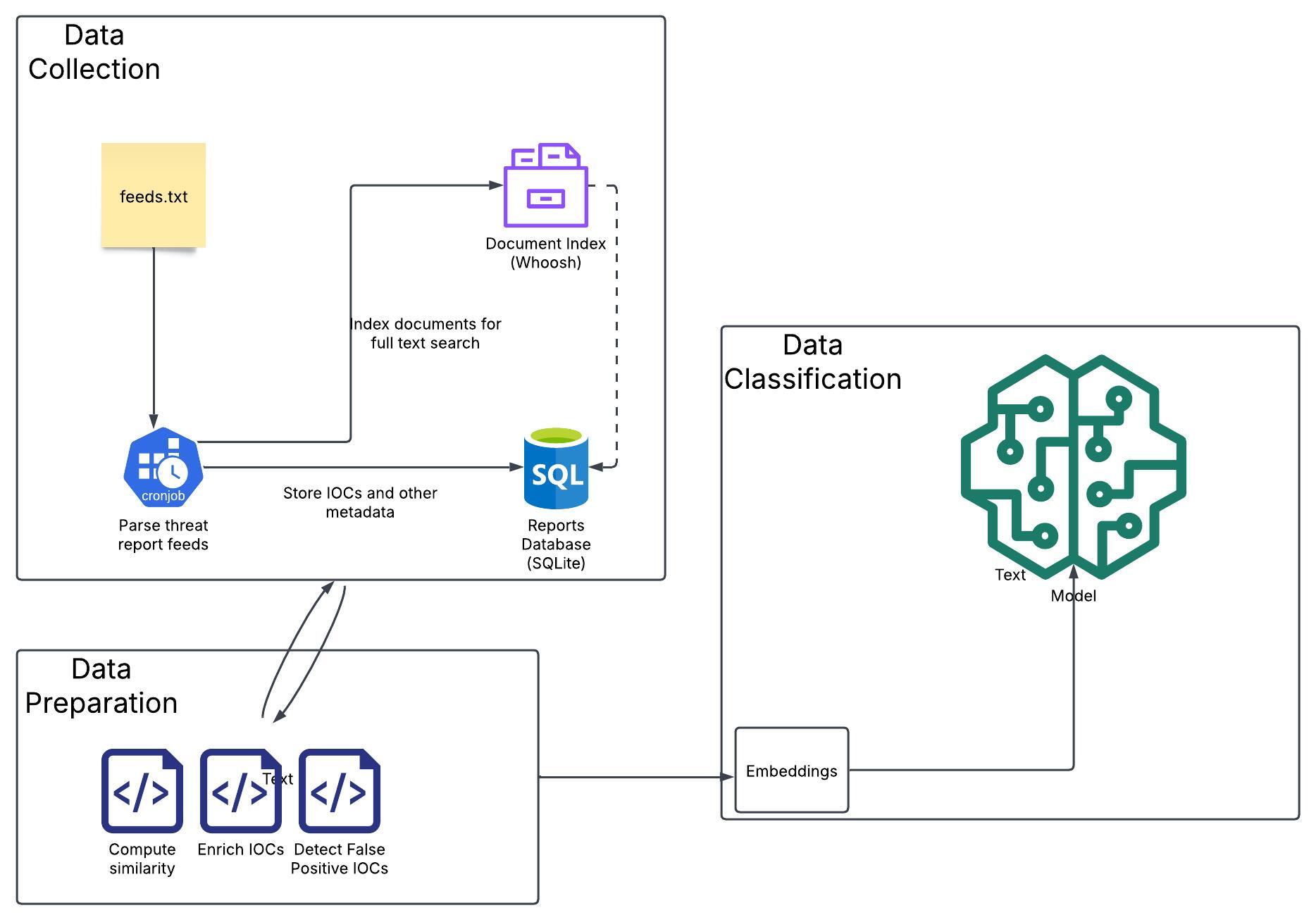
This review explores the application of large language models to proactively detect Indicators of Compromise from web-based threat reports, leveraging frameworks like STIX and MITRE ATT&CK.
Despite escalating cybersecurity threats, current detection methods largely remain reactive, responding after malicious activity occurs. This paper, ‘Proactively Detecting Threats: A Novel Approach Using LLMs’, introduces and systematically evaluates the application of large language models (LLMs) to proactively identify indicators of compromise (IOCs) extracted from unstructured, web-based threat intelligence. Our findings reveal significant performance variations among LLMs, with Gemini 1.5 Pro achieving near-perfect recall alongside high precision in malicious IOC identification. Could this approach herald a shift towards truly predictive cybersecurity, anticipating threats before they materialize?
Decoding the Threat Avalanche: When Volume Obscures the Signal
The digital landscape is witnessing an unprecedented surge in threat intelligence data, a phenomenon that is rapidly exceeding the capacity of conventional analytical techniques. Security professionals are increasingly inundated with alerts, indicators, and reports, creating a situation where critical threats can be obscured within a vast ocean of information. Traditional methods, reliant on manual review and human expertise, struggle to keep pace with both the volume and the velocity of these emerging dangers. This data deluge isn’t simply about quantity; the sheer scale hinders effective prioritization, delaying response times and increasing the potential for successful attacks. Consequently, organizations face a growing challenge in differentiating between genuine threats and false positives, demanding innovative solutions to efficiently process and interpret the escalating flow of intelligence.
Current cybersecurity systems frequently falter when faced with the sheer volume of Indicators of Compromise (IOCs) generated daily. While threat data accumulates exponentially, the capacity of analysts and traditional security tools to efficiently sift through it remains limited. This results in a significant backlog of potential threats, where critical IOCs – those signaling active attacks or vulnerabilities – are often buried amongst false positives or simply overlooked due to time constraints. Consequently, security teams are forced to react after a breach has occurred, rather than proactively identifying and mitigating risks before they materialize. The inability to effectively prioritize IOCs represents a fundamental challenge in modern cybersecurity, hindering timely responses and increasing the potential for significant damage.
The escalating volume of cyber threats, coupled with the limitations of manual analysis, frequently positions security teams in a reactive stance. Rather than anticipating and preventing attacks, many organizations find themselves responding to incidents after they have occurred, often incurring significant damage and disruption. This reactive posture stems from an inability to efficiently process the overwhelming flood of threat intelligence data, leading to delayed identification of critical vulnerabilities and a diminished capacity to proactively mitigate risks. Consequently, organizations are consistently playing catch-up, dedicating resources to containment and recovery instead of focusing on preventative measures and strengthening their overall security posture. This cycle of reaction perpetuates vulnerabilities and increases the likelihood of future successful attacks.
The escalating volume of threat intelligence necessitates a shift towards automated analysis of Indicators of Compromise (IOCs) to effectively manage security risks. A recent examination of just 479 web pages revealed a staggering density of potential threats – containing 711 IPv4 addresses, 502 IPv6 addresses, and 1445 domains – illustrating the impracticality of manual review. This sheer scale of data underscores the critical need for automated systems capable of rapidly extracting, prioritizing, and analyzing IOCs, enabling security teams to move beyond reactive responses and proactively mitigate emerging threats before they can cause significant damage. Without such automation, valuable intelligence remains buried within an overwhelming flood of information, leaving organizations vulnerable to increasingly sophisticated attacks.

LLMs: Automating Threat Dissection and Proactive Defense
Large Language Models (LLMs) present a significant opportunity to automate the extraction of Indicators of Compromise (IOCs) from the substantial volume of unstructured text found in threat reports, blog posts, and security advisories. Traditionally, IOC extraction relied on manual analysis or rule-based systems requiring significant human effort and often failing to scale with the increasing threat landscape. LLMs, through techniques like Named Entity Recognition and relationship extraction, can identify and categorize IOCs – such as IP addresses, domain names, file hashes, and malware families – directly from natural language text. This automated process reduces analysis time, improves the accuracy of IOC identification, and facilitates the rapid dissemination of actionable threat intelligence to security tools and teams. The ability of LLMs to understand context and nuance within threat reports also allows for the identification of previously unknown or obfuscated IOCs, enhancing proactive threat detection capabilities.
Training Large Language Models (LLMs) on curated threat intelligence data allows for the identification of potential security threats beyond simple signature matching. This process involves exposing the LLM to a corpus of reports detailing Indicators of Compromise (IOCs), threat actor tactics, techniques, and procedures (TTPs), and emerging malware families. The LLM learns to associate patterns within the text with specific threat characteristics, enabling it to recognize novel threats described in new, unseen reports. Specifically, the LLM can predict the likelihood of a new report indicating a threat, categorize the threat based on observed characteristics, and extract relevant IOCs even when they are not explicitly labeled, thereby facilitating proactive security measures and reducing mean time to detection.
Automated threat intelligence relies heavily on the continuous collection of data from publicly available sources. A robust web crawler is essential for this task, systematically retrieving threat reports from diverse origins including, but not limited to, security blogs, vulnerability databases, and RSS feeds. These crawlers must be designed to handle varying website structures, respect robots.txt directives, and manage rate limiting to avoid being blocked. Effective crawlers also incorporate mechanisms for identifying new and updated reports, deduplicating content, and handling different data formats – often requiring parsing of HTML, PDF, and text-based documents. The collected data then forms the foundation for subsequent processing and analysis by Large Language Models.
Regular expressions (regex) are implemented within the data preprocessing stage to standardize and validate text extracted from threat reports prior to input into the Large Language Model. This process includes removing irrelevant characters, normalizing casing, and identifying specific patterns indicative of Indicators of Compromise (IOCs) such as IP addresses, URLs, and file hashes. Regex patterns enforce data consistency by filtering out malformed or incomplete IOCs, reducing noise and improving the accuracy of subsequent LLM analysis. The application of regex minimizes false positives and ensures the LLM receives clean, structured data, enhancing its ability to effectively identify and categorize potential security threats.
Benchmarking LLM Performance: Separating Signal from Noise in IOC Classification
An evaluation was conducted to assess the capabilities of three large language models – Gemini Models, Qwen3 32b, and Llama 70B – in the classification of Indicators of Compromise (IOCs). This assessment focused on determining the models’ ability to accurately identify malicious IOCs within a given dataset. The evaluation process involved submitting a standardized set of IOCs to each model and recording the number of true positives, false positives, true negatives, and false negatives to establish performance metrics. The objective was to provide a comparative analysis of these LLMs for potential application in automated threat detection and security analysis workflows.
Llama 70B achieved a high recall rate in Indicator of Compromise (IOC) classification, successfully identifying 251 true positive instances of malicious indicators. However, this performance was coupled with reduced specificity, indicating a higher rate of false positives. This suggests the model is sensitive to identifying potential threats, but also incorrectly flags a larger proportion of benign indicators as malicious, requiring additional validation steps to confirm legitimate threats and minimize alert fatigue.
Gemini Models demonstrated a strong capacity for accurate identification of malicious Indicators of Compromise (IOCs), achieving a maximum precision of 95.8%. This indicates a low rate of false positives, meaning that when the model flagged an IOC as malicious, it was highly likely to be genuinely malicious. While recall metrics were also positive, the emphasis lies on the model’s ability to minimize incorrect classifications, which is crucial for security operations to reduce alert fatigue and streamline investigation efforts. This balance between minimizing false positives and maintaining a reasonable detection rate positions Gemini Models as a potentially effective tool for IOC classification.
Evaluation of the Qwen3 32b large language model on Indicator of Compromise (IOC) classification tasks yielded lower performance metrics compared to Gemini Models and Llama 70B, identifying 239 true positives. This result underscores the critical importance of careful model selection when addressing IOC classification, as performance varies significantly between models. While Qwen3 32b demonstrated some ability to identify malicious indicators, its overall lower performance suggests it may not be the optimal choice for this specific application without further tuning or augmentation.
Beyond IOCs: Contextualizing Threats and Building a Holistic Defense
Truly effective threat intelligence extends beyond simply cataloging Indicators of Compromise (IOCs); it demands a deep understanding of why those indicators are present and how they fit into a larger attack narrative. Identifying a malicious IP address, for example, is insufficient without knowing what action the attacker was attempting – reconnaissance, data exfiltration, or lateral movement. This contextualization requires correlating IOCs with adversary tactics, techniques, and procedures (TTPs), revealing the attacker’s objectives and methods. By linking individual indicators to broader behavioral patterns, security teams can move from reactive responses to proactive threat hunting and more accurately predict future attacks. Ultimately, understanding the ‘who, what, when, where, and why’ behind each IOC transforms raw data into actionable intelligence, significantly bolstering an organization’s security posture.
Threat intelligence gains substantial power when Indicators of Compromise (IOCs) are mapped to the MITRE ATT&CK Framework. This integration moves beyond simply identifying what malicious activity occurred, and delves into how and why attackers operate. By correlating IOCs – such as malicious URLs or file hashes – with specific ATT&CK tactics and techniques, analysts can reconstruct attacker methodologies, understand their goals, and predict future behavior. This contextualization is crucial for proactive defense; instead of reacting to individual threats, security teams can anticipate likely attack vectors and strengthen defenses against entire campaigns. Consequently, the ATT&CK Framework serves not merely as a catalog of threats, but as a powerful analytical tool that transforms raw IOC data into actionable intelligence regarding adversary tradecraft.
Cyber Threat Intelligence sharing is significantly advanced by the adoption of STIX 2.0, a standardized language for describing threats, yet the sheer volume of generated data presents a considerable challenge. Current systems collectively produce over 2,006 unique STIX objects daily, representing a flood of information that can overwhelm analysts and hinder effective threat hunting. While standardization enables interoperability and facilitates the exchange of critical data between organizations, the scale of this output necessitates robust automation, advanced filtering techniques, and intelligent analytics to distill actionable insights from the noise. This highlights the need not only for a common language, but also for sophisticated tools capable of managing and interpreting the immense quantity of threat data being generated and shared.
The foundation of robust threat profiles rests upon the precise categorization of Indicators of Compromise (IOCs), encompassing elements like IPv4 addresses, IPv6 addresses, and domain names; however, current systems struggle with efficiency in this area. Despite technological progress aimed at streamlining threat intelligence, analysis reveals that approximately 37.89% of STIX objects originating from individual providers demonstrate redundant information. This duplication not only inflates the volume of data security teams must process, hindering timely responses, but also suggests a lack of standardization in how IOCs are initially classified and reported. Addressing this redundancy is critical, as eliminating duplicated efforts allows analysts to focus on novel threats and build more accurate, actionable intelligence regarding adversary activity and techniques.
The pursuit of proactive threat detection, as detailed in this exploration of LLMs and Indicators of Compromise, inherently demands a willingness to dismantle conventional approaches. It’s a process of dissecting existing cybersecurity frameworks to reveal vulnerabilities, much like a skilled reverse engineer deconstructs a complex system. Vinton Cerf aptly stated, “Any sufficiently advanced technology is indistinguishable from magic.” This sentiment rings true; LLMs, when applied to threat intelligence, appear to magically anticipate malicious activity. However, this “magic” isn’t spontaneous – it’s the result of meticulously analyzing data, identifying patterns, and fundamentally understanding the attacker’s methods – a deliberate act of intellectual ‘hacking’ to build a more resilient defense.
What Breaks Down Next?
The demonstrated capacity of large language models to sift through the noise of threat intelligence reports and extract potentially useful Indicators of Compromise feels less like a solution and more like a beautifully complex escalation. It exposes a fundamental truth: security isn’t about building walls, but about understanding the tools used to dismantle them. If the system yields IOCs, it simultaneously reveals the vulnerabilities inherent in the language used to describe compromise. The next iteration isn’t simply about refining the LLM’s accuracy, but about deliberately probing its limits-feeding it adversarial examples, ambiguous reports, and outright disinformation to map the boundaries of its understanding.
Current efforts largely treat threat reports as static data. A truly proactive system must account for the evolution of attacker language-the deliberate obfuscation, the adoption of new jargon, the shifting narratives designed to mislead automated defenses. The LLM isn’t just a detector; it’s a mirror reflecting the ingenuity of the adversary. Therefore, the true test lies not in identifying known threats, but in predicting the form of future attacks based on the patterns of linguistic innovation within the threat landscape.
Ultimately, this approach invites a crucial question: if a machine can learn to identify compromise, can it also learn to simulate it convincingly? The line between detection and deception blurs, and the most effective defense may well become indistinguishable from a highly sophisticated attack. The pursuit of proactive security, it seems, demands a willingness to dismantle the very systems it seeks to protect, all in the name of thorough understanding.
Original article: https://arxiv.org/pdf/2601.09029.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Invincible Season 4 Episode 6 Release Date, Time, Where to Watch
- Mewgenics vinyl limited editions now available to pre-order
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- Crimson Desert Guide – How to Pay Fines, Bounties & Debt
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
2026-01-15 23:01