Author: Denis Avetisyan
A new deep learning framework, Phi-SegNet, boosts the accuracy of medical image analysis by incorporating often-overlooked phase information from the frequency domain.
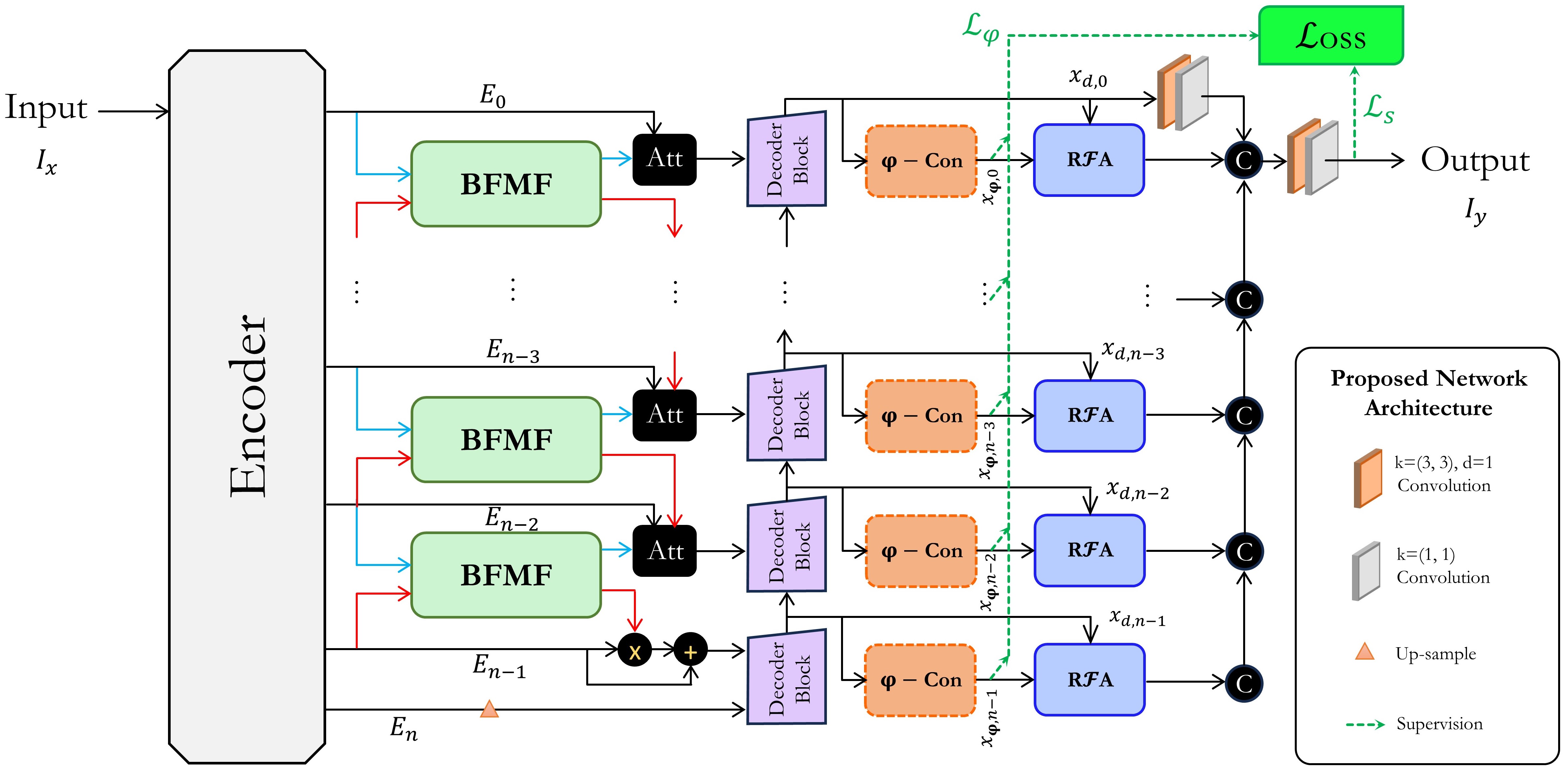
Phi-SegNet utilizes phase-integrated supervision and a reverse attention mechanism to enhance boundary delineation in complex medical images.
Despite substantial advances in deep learning for medical image segmentation, achieving robust generalization across diverse imaging modalities remains a persistent challenge, often overlooking valuable frequency-domain information. This limitation motivates the development of ‘Phi-SegNet: Phase-Integrated Supervision for Medical Image Segmentation’, a novel CNN-based architecture that incorporates phase-aware information at both architectural and optimization levels via Bi-Feature Mask Former modules and Reverse Fourier Attention blocks. Our results demonstrate that explicitly leveraging spectral priors-and aligning features with structural priors through a dedicated phase-aware loss-consistently achieves state-of-the-art performance and improved cross-dataset generalization. Could this phase-integrated approach unlock a new paradigm for generalized medical image segmentation frameworks capable of excelling in fine-grained object localization?
The Illusion of Precision: Why Boundaries Remain Elusive
Accurate medical image segmentation forms the cornerstone of modern diagnosis and treatment planning, enabling clinicians to precisely identify and measure anatomical structures and pathological lesions. However, traditional segmentation techniques often falter when confronted with the inherent complexities of medical imagery – namely, indistinct boundaries and the subtle variations in tissue characteristics. These methods, frequently reliant on manual intervention or simplistic algorithms, struggle to reliably differentiate between similar tissues or trace irregularly shaped objects, leading to inaccuracies that can compromise clinical decision-making. The challenge isn’t merely identifying an object, but defining its precise extent, a task demanding nuanced analysis and robust algorithms capable of overcoming the limitations of image noise, anatomical variability, and the often-subtle features that distinguish healthy from diseased tissue.
Convolutional Neural Networks (CNNs), and particularly architectures like U-Net, currently underpin much of the progress in medical image segmentation due to their capacity for automated feature extraction. However, a fundamental limitation of these networks lies in their receptive field – the region of the input image that a neuron considers at any given moment. While effective at identifying local patterns, this restricted view hinders the network’s ability to understand the broader spatial relationships and global context within an image. Consequently, delineating structures with ambiguous or subtle boundaries becomes challenging, as the network may lack the necessary information from distant regions to make accurate predictions. This constraint motivates ongoing research into architectures designed to expand this contextual awareness, allowing for more comprehensive and reliable segmentation results.
Recent advancements in medical image segmentation have seen the development of architectures designed to overcome the limitations of traditional Convolutional Neural Networks. Networks such as CE-Net and CPFNet represent iterative improvements by strategically addressing the issue of limited receptive fields – the area of an image a network can ‘see’ at once. CE-Net achieves this through a progressive learning approach, refining segmentation maps at increasing resolutions, while CPFNet incorporates contextual pathways to capture both local details and broader spatial relationships. These designs effectively allow the network to consider a wider area when making predictions, improving the accuracy of boundary delineation and the identification of subtle features within complex medical images. While not a complete solution, these architectures demonstrate the ongoing effort to integrate more comprehensive contextual understanding into automated segmentation processes.
Despite considerable progress in medical image segmentation using architectures like CE-Net and CPFNet, precise delineation of anatomical structures continues to pose a substantial challenge. Current methods, while adept at local feature extraction, often struggle with ambiguous boundaries, subtle contrast variations, and the inherent complexity of biological tissues. This limitation isn’t merely a matter of refining existing convolutional neural networks; it suggests that relying solely on spatial information-the pixel arrangements within an image-is insufficient. Consequently, researchers are increasingly motivated to investigate supplementary approaches that integrate contextual information beyond immediate pixel neighborhoods, such as temporal data, multi-modal imaging, or even incorporating prior anatomical knowledge, to achieve truly robust and accurate segmentation results.
Beyond Pixels: A Different Way of Looking at the Problem
Frequency domain modeling represents images not as arrangements of pixel values – the focus of spatial-domain methods – but as a summation of sinusoidal waves of varying frequencies, magnitudes, and phases. This transformation, typically achieved via the Fourier Transform, decomposes the image into its constituent frequencies, allowing analysis of the global characteristics of the signal rather than localized pixel data. Low frequencies represent slowly varying image features like smooth backgrounds and broad shapes, while high frequencies correspond to edges, textures, and fine details. By representing an image as a frequency spectrum, operations can be performed to emphasize or suppress specific frequencies, effectively altering image characteristics like sharpness or noise levels, and providing a different perspective than traditional spatial analysis.
The Fourier Transform and Cosine Transform are fundamental techniques used to decompose an image into its constituent frequencies. The Fourier Transform expresses an image as a sum of complex exponentials, revealing the amplitude and phase of each frequency component; this representation shifts analysis from the spatial domain (pixel values) to the frequency domain. Conversely, the Cosine Transform, specifically the Discrete Cosine Transform (DCT), utilizes only cosine functions, resulting in a real-valued frequency representation commonly used in image compression standards like JPEG. Both transforms allow for targeted manipulation of frequencies – for example, high-frequency components representing edges and details can be enhanced or suppressed, while low-frequency components capture overall image structure. The resulting frequency spectrum provides valuable information for image analysis, filtering, and reconstruction, and forms the basis for many advanced image processing algorithms.
Recent network architectures, including MEW-UNet, FDFUNet, and GFUNet, incorporate frequency domain processing directly into their segmentation pipelines. These models utilize techniques such as Fourier transforms to decompose images into their constituent frequencies, enabling analysis and manipulation of spectral components alongside traditional spatial data. Initial results indicate that integrating frequency information enhances segmentation accuracy, particularly in challenging scenarios involving low contrast or complex textures. Specifically, FDFUNet employs a frequency domain feature unmixing module, while MEW-UNet utilizes a multi-scale enhancement weighting strategy in the frequency domain. GFUNet leverages global frequency information to guide local feature learning. These approaches demonstrate the potential for frequency-based methods to improve performance in image segmentation tasks.
The integration of both spatial and frequency domain analysis in image segmentation models provides increased robustness by capturing complementary information. Spatial domain analysis focuses on pixel intensities and their immediate relationships, while frequency domain analysis reveals global patterns and recurring textures. Models leveraging this combined approach can better discern subtle boundaries and features that might be obscured in either domain alone. This is achieved by decomposing images into frequency components – such as \sin and \cos waves – allowing the model to identify dominant frequencies associated with specific structures. Consequently, these models demonstrate improved performance in challenging conditions like low contrast, noise, or occlusion, resulting in a more comprehensive understanding of underlying image structures compared to methods relying solely on spatial information.

Parallel Processing: Doubling Down on Feature Extraction
Dual-domain networks, exemplified by architectures like DBL-Net and D2LNet, achieve enhanced performance through the utilization of parallel encoding streams. These networks simultaneously process input data in both the spatial domain – directly analyzing pixel or voxel values – and the frequency domain, typically via Fourier transforms or related techniques. This parallel structure enables the extraction of complementary features; spatial encoders capture localized details and textures, while frequency encoders identify global patterns and relationships. By processing these domains concurrently, the network avoids the sequential bottlenecks inherent in traditional single-domain approaches and generates a more robust and comprehensive feature representation for downstream tasks.
Dual-domain architectures achieve enhanced feature representation by processing input data concurrently through both frequency and spatial encoders. This parallel processing pathway enables the network to extract features characterizing both the spatial location of image elements and their frequency components – effectively capturing both where an object is and what textures or patterns define it. Unlike sequential processing which relies on features derived from one domain informing the other, simultaneous extraction allows for a more complete initial feature set. This comprehensive representation facilitates improved discrimination and ultimately enhances performance in tasks requiring nuanced understanding of image content, as each domain contributes complementary information to the overall feature map.
SLf-UNet and tKFC-Net build upon dual-domain architectures by incorporating mechanisms to improve feature discrimination. SLf-UNet introduces spectral recalibration units which adaptively rescale feature channel responses based on spectral characteristics, effectively emphasizing informative features and suppressing noise. tKFC-Net utilizes twin-kernel convolutions, employing parallel convolutions with different kernel sizes to capture multi-scale contextual information. This parallel processing allows the network to simultaneously extract both fine-grained details and broader contextual cues, improving the ability to differentiate between subtle features and ultimately enhancing segmentation accuracy.
Evaluations of dual-domain architectures, including DBL-Net and D2LNet variations, consistently demonstrate performance gains on challenging image segmentation datasets. Specifically, these models achieve higher Intersection over Union (IoU) and Dice scores compared to single-domain counterparts when tested on datasets with low contrast, complex textures, or significant noise. Improvements are particularly notable in scenarios requiring fine-grained boundary delineation, indicating that the combined frequency and spatial feature representation facilitates more accurate object identification and segmentation. Quantitative results across multiple benchmarks confirm that the simultaneous analysis of both domains provides a more robust and discriminative feature set, leading to enhanced segmentation accuracy and reduced error rates in difficult conditions.
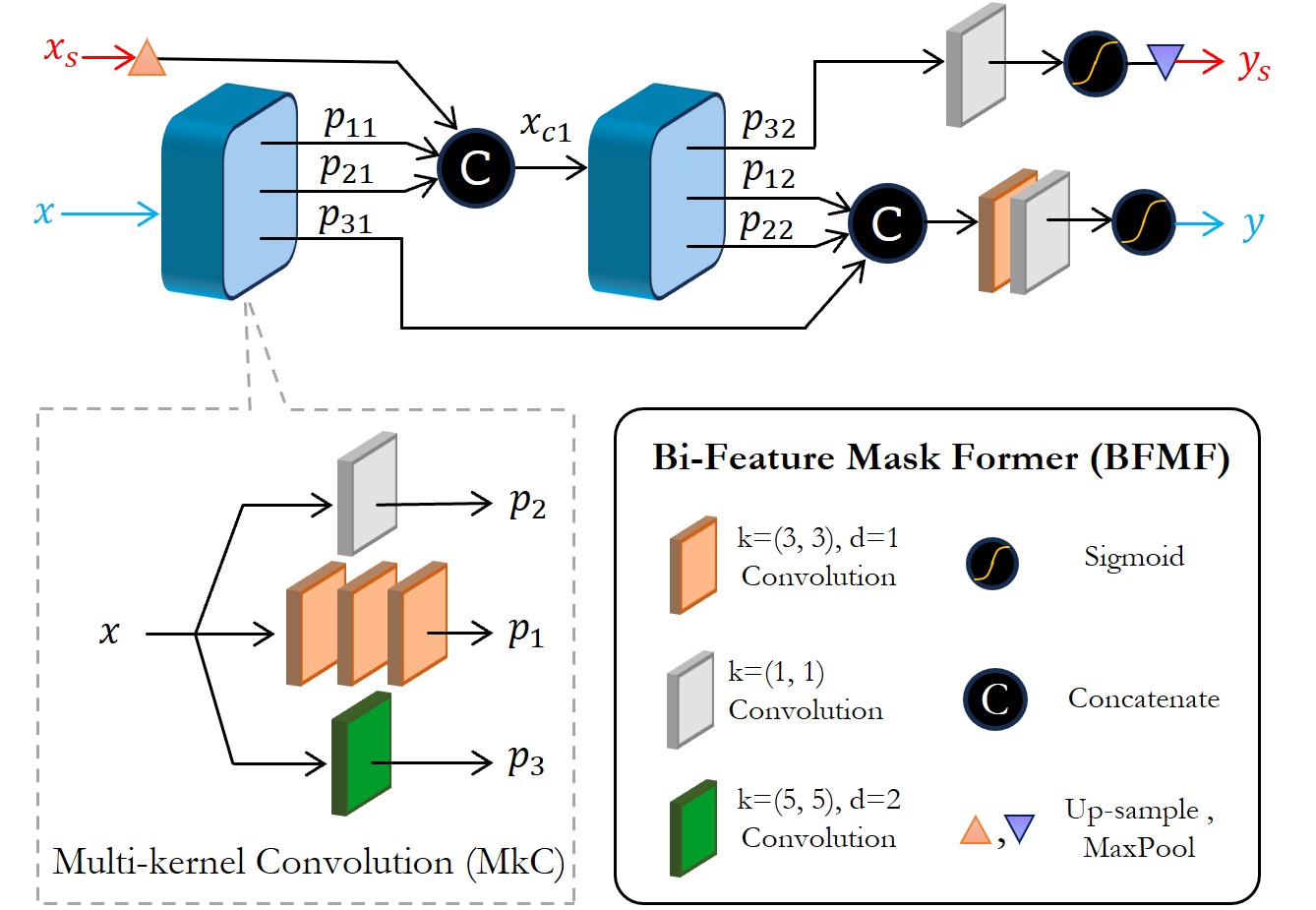
Spectral Transformers: The Latest Iteration – And Perhaps, a More Principled Approach
The burgeoning field of medical image segmentation has recently seen a paradigm shift with the introduction of spectral-domain-focused Transformer architectures. Models like BAWGNet and LACFormer exemplify this trend, moving beyond traditional spatial-domain processing to leverage the rich information contained within the frequency spectrum of images. These advancements recognize that crucial details for accurate segmentation – subtle textural differences, edges, and boundaries – often manifest more clearly in the frequency domain. By operating directly on the spectral representation of images, these architectures can more effectively capture and utilize these features, leading to improved performance and robustness compared to conventional methods. This focus on spectral analysis allows for a more nuanced understanding of image content, ultimately contributing to more precise and reliable segmentation results, paving the way for advancements in diagnostic and therapeutic applications.
Phi-SegNet establishes a novel framework for image segmentation by directly incorporating principles of spectral analysis into both the attention mechanisms and the supervisory signals used during training. This frequency-aware approach allows the model to not only process spatial information but also to analyze images in the frequency domain, capturing subtle patterns and textures often missed by traditional methods. By integrating spectral reasoning, Phi-SegNet effectively enhances its ability to discern boundaries and accurately categorize image regions, ultimately leading to improved segmentation performance as demonstrated by its state-of-the-art results on the Kvasir-SEG and BUSI datasets. This culmination of recent advancements positions Phi-SegNet as a significant step towards more robust and accurate image analysis.
Phi-SegNet’s success in medical image segmentation stems from the synergistic interplay of several novel components. The Bi-Feature Mask Former efficiently generates region proposals, while the innovative Reverse Fourier Attention mechanism analyzes images not just in the spatial domain, but also by decomposing them into their constituent phase and magnitude spectra – capturing subtle frequency-based features often missed by conventional methods. This spectral analysis is further reinforced by a Phase-Integrated Supervision Loss, which directly encourages the model to learn robust phase representations. Combined, these elements allow Phi-SegNet to achieve state-of-the-art performance, evidenced by an Intersection over Union (IoU) of 84.96% on the challenging Kvasir-SEG dataset and 84.54% on the BUSI dataset, demonstrating its potential for accurate and reliable medical image analysis.
Phi-SegNet’s performance is notably strengthened by the integration of EfficientNet-B4 as its foundational backbone, yielding both robust and precise segmentation outcomes. Evaluations on established datasets demonstrate its capabilities, achieving an F1-score of 92.24% on the Kvasir-SEG dataset and 91.98% on the BUSI dataset – indicative of high accuracy in identifying and delineating structures. Importantly, this level of performance is achieved while maintaining a manageable model complexity of 59.72 million parameters and a computational cost of 81.91 GFLOPs, allowing for relatively swift processing with an average inference time of 44.41 milliseconds per image.
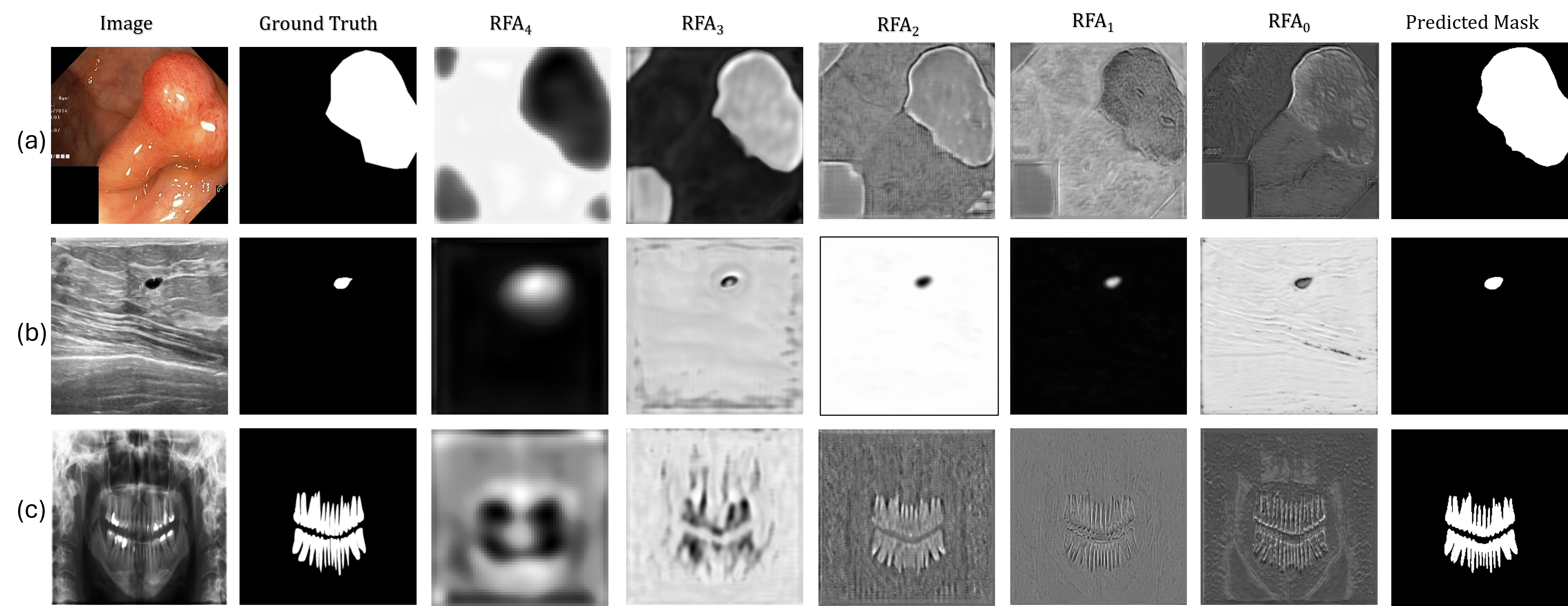
The pursuit of pristine segmentation, as Phi-SegNet attempts with its phase-integrated supervision, echoes a familiar pattern. It optimizes for detail, for the clean line between tissue and anomaly, believing a sharper boundary equates to a more accurate diagnosis. Yet, the system will inevitably encounter the imperfect data of production – noise, artifacts, the subtle variations in human anatomy. As Aristotle observed, “The ultimate value of life depends upon awareness and the power of contemplation rather than merely surviving.” This framework isn’t about achieving perfect delineation, but about building a system resilient enough to function despite the inherent imperfections of the data it processes. It’s a compromise that survived deployment, and that’s often the highest praise one can offer.
What’s Next?
Phi-SegNet’s foray into phase information is a logical, if belated, acknowledgement that pixels are merely the visible symptom of a far more complex signal. The pursuit of frequency-domain representations in medical imaging isn’t new, of course. It merely shifts the burden of abstraction – and thus, the inevitable points of failure – to a different layer. One anticipates a surge in papers demonstrating how perfectly reconstructed phase information still fails to account for inter-patient variability, scanner artifacts, and the simple fact that biology refuses to be neatly represented by Fourier transforms.
The architecture’s reliance on “reverse attention” feels suspiciously like a workaround for inherent limitations in feature extraction. The problem isn’t where attention is directed, but that attention, in its current form, is a crude instrument. Future iterations will undoubtedly explore more nuanced methods for weighting frequency components, likely introducing new hyperparameters and, consequently, new ways to misconfigure the system. The Bi-Feature Mask Former appears, predictably, as yet another attempt to squeeze more performance out of existing convolutional backbones-a testament to the enduring power of diminishing returns.
Ultimately, this work highlights a recurring truth: anything that promises to simplify life adds another layer of abstraction. CI is the temple – one prays nothing breaks when the inevitable edge case arrives. Documentation, as always, remains a myth invented by managers.
Original article: https://arxiv.org/pdf/2601.16064.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- Gold Rate Forecast
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- How to Solve the Glenbright Manor Puzzle in Crimson Desert
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- All Itzaland Animal Locations in Infinity Nikki
- 8 Actors Who Could Play Blackbeard In One Piece Live-Action Season 3
- A Dark Scream Theory Rewrites the Only Movie to Break the 2-Killer Rule
- All 10 Potential New Avengers Leaders in Doomsday, Ranked by Their Power
2026-01-25 00:04