Author: Denis Avetisyan
Researchers introduce a framework that proactively identifies privacy risks throughout the entire lifecycle of artificial intelligence systems, from data collection to model deployment.
PriMod4AI leverages large language models and retrieval-augmented generation to address both data-centric and model-centric privacy threats, aligned with the LINDDUN privacy threat model.
While artificial intelligence offers unprecedented capabilities, its lifecycle introduces complex and often overlooked privacy risks beyond traditional data handling concerns. To address this gap, we present ‘PriMod4AI: Lifecycle-Aware Privacy Threat Modeling for AI Systems using LLM’, a novel framework that unifies established privacy taxonomies-like LINDDUN-with emerging model-centric attacks, leveraging large language models and retrieval-augmented generation. This approach delivers comprehensive, lifecycle-aware threat assessments grounded in structured knowledge, identifying both classical and AI-specific vulnerabilities. Can this hybrid methodology provide a scalable and consistent foundation for proactive privacy engineering in increasingly complex AI deployments?
The Inevitable Erosion: Understanding AI’s Privacy Risks
Artificial intelligence systems are fundamentally data-driven, and their growing sophistication necessitates access to increasingly detailed and sensitive information about individuals. This reliance extends far beyond simple personal identifiers to encompass biometric data, location history, financial records, and even predictive inferences about behavior and future actions. Consequently, the potential for privacy breaches and misuse of personal data is amplified significantly. Unlike traditional data processing, AI algorithms can often infer sensitive attributes not explicitly provided, creating “privacy leakage” even from seemingly anonymized datasets. The sheer scale of data collection and the complex, often opaque, nature of AI algorithms pose substantial challenges for safeguarding individual privacy, demanding new approaches to data governance and algorithmic accountability.
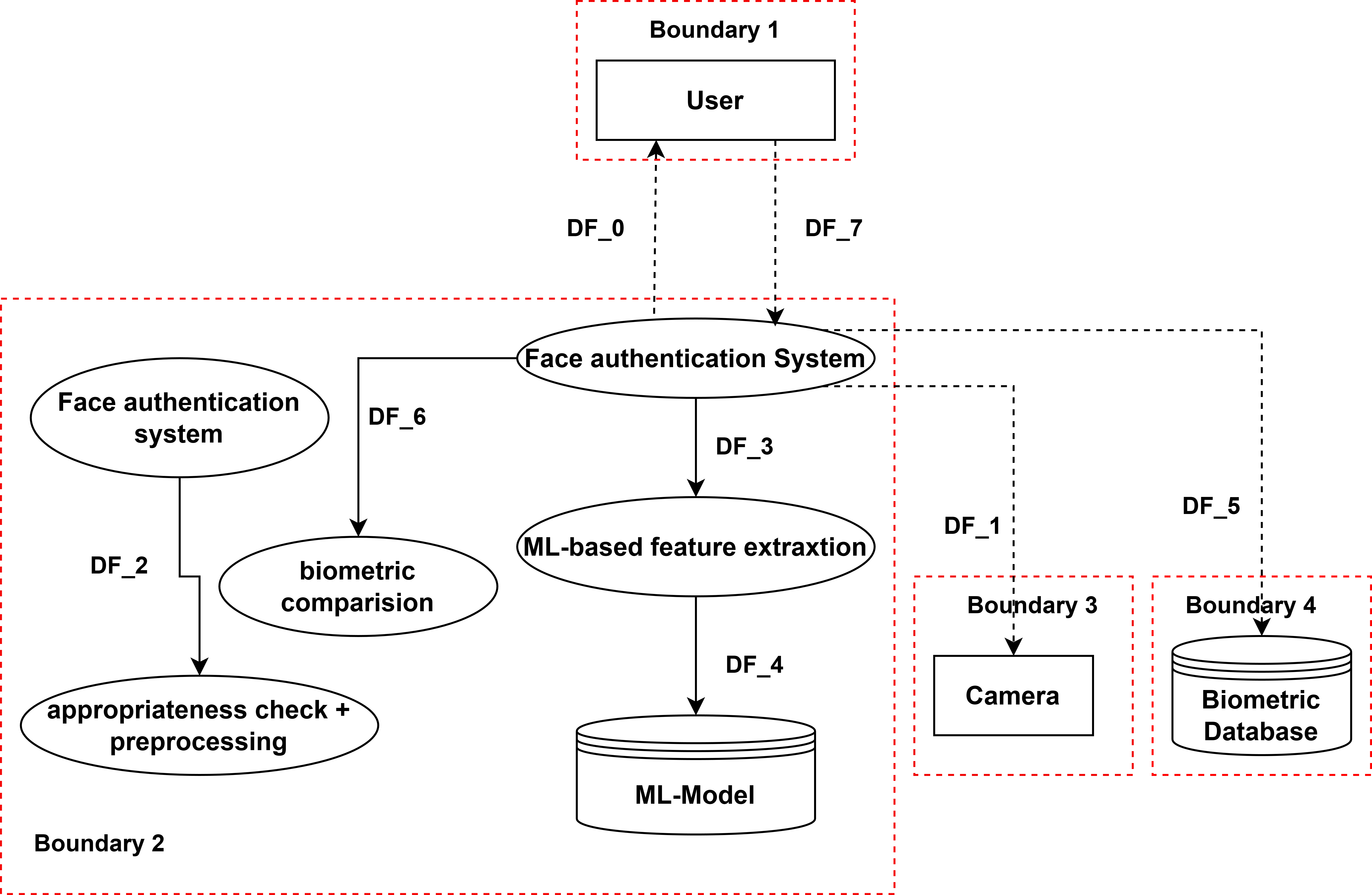
Conventional privacy safeguards, designed for data at rest or in transit, are proving inadequate against the dynamic and often opaque nature of modern artificial intelligence. Systems like face authentication and autonomous driving present unique challenges; they don’t simply store sensitive data – they infer information, building detailed profiles from subtle patterns and continuous observation. This inferential capacity bypasses traditional consent mechanisms and data minimization principles. For instance, a face authentication system might not store a user’s address, but it can reliably predict their likely commute route, revealing personal habits. Similarly, autonomous driving systems collect a constant stream of data, not only about the driver but also about pedestrians, businesses, and even the vehicle’s surroundings, creating a pervasive surveillance footprint. The scale and complexity of these AI models, coupled with their ability to learn and adapt, mean that established privacy techniques – such as anonymization or encryption – often fail to provide meaningful protection, necessitating the development of entirely new approaches to safeguard individual privacy in the age of intelligent machines.
The journey of an artificial intelligence system, from its initial development through training, testing, and ultimate deployment, introduces a cascade of potential vulnerabilities. Each stage-data collection, model training, and ongoing operation-represents an attack surface that malicious actors could exploit. Compromised training data can introduce biases or backdoors, while model extraction techniques threaten intellectual property and allow for adversarial manipulation. Even after deployment, continuous monitoring and updates, though essential for performance, create opportunities for attackers to intercept data or inject malicious code. Consequently, a proactive, lifecycle-focused approach to security – incorporating techniques like differential privacy, federated learning, and robust monitoring – is crucial to mitigate these risks and ensure the trustworthy operation of AI systems.
Deconstructing the Threat: The LINDDUN Framework
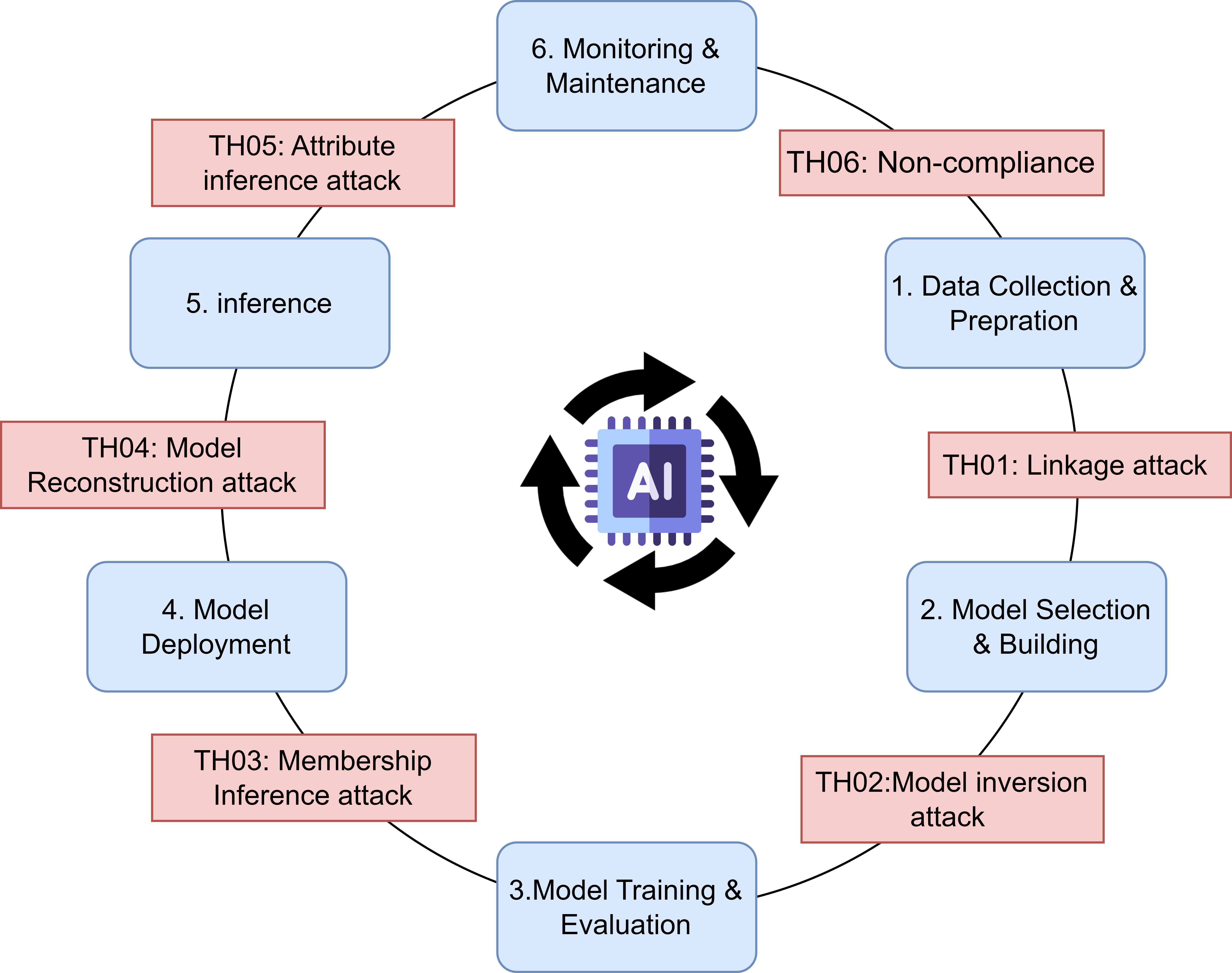
The LINDDUN framework systematically identifies data-centric privacy threats in AI systems by decomposing the AI pipeline into six layers: Logic, Inference, Networking, Data, Deployment, and User. Each layer is then analyzed across three threat categories – Availability, Integrity, and Confidentiality – resulting in 18 specific threat vectors. This structured approach allows threat analysts to move beyond generalized risk assessments and pinpoint vulnerabilities related to data handling at each stage of the AI lifecycle. The methodology focuses on how data is processed, stored, and transmitted, considering potential breaches impacting privacy from the initial data input through to the AI system’s output and user interaction.
The LINDDUN Knowledge Base facilitates systematic privacy vulnerability mapping by categorizing threats across six dimensions: Linkability, Identifiability, Non-repudiation, Detectability, Disclosure of information, and Unawareness. This categorization allows analysts to move beyond generic risk assessments and pinpoint specific vulnerabilities related to data processing within AI systems. The Knowledge Base provides pre-defined threat patterns and associated mitigation strategies for each dimension, enabling a structured approach to identifying how data flows could lead to privacy breaches. By applying these patterns to specific AI system architectures and data handling practices, analysts can comprehensively map potential vulnerabilities and prioritize remediation efforts based on the severity of each identified risk.
The LINDDUN framework facilitates proactive privacy risk management by integrating threat analysis throughout the entire AI Lifecycle, encompassing stages from initial data collection and model training to deployment and ongoing monitoring. This lifecycle approach enables organizations to identify and address potential vulnerabilities before they manifest as breaches or compliance violations. Specifically, LINDDUN supports the implementation of preventative controls during data processing, differential privacy techniques during model development, and robust auditing mechanisms post-deployment. By systematically assessing threats at each stage, organizations can build privacy-preserving AI systems and demonstrate adherence to relevant data protection regulations, reducing both legal and reputational risks.
Automated Vigilance: PriMod4AI in Action
PriMod4AI functions as an automated privacy threat identification pipeline by integrating three distinct data sources: the LINDDUN Knowledge Base, the AI Privacy Knowledge Base, and system-specific metadata. The LINDDUN Knowledge Base provides a structured representation of privacy principles and legal requirements, while the AI Privacy Knowledge Base details potential vulnerabilities and attack vectors specific to machine learning models. System metadata, encompassing details about the model architecture, training data, and deployment environment, is then combined with these knowledge bases. This fusion enables PriMod4AI to contextualize privacy risks based on the specific characteristics of the deployed AI system, facilitating a more accurate and targeted threat analysis.
The PriMod4AI pipeline automates the identification of Model-Centric Privacy Attacks by integrating Large Language Models (LLMs) with a Retrieval-Augmented Generation (RAG) approach. This methodology enables the system to detect attacks such as Membership Inference – determining if a specific data point was used in model training – Model Inversion, which aims to reconstruct training data from the model, and Training Data Extraction, focusing on directly obtaining portions of the training dataset. RAG enhances LLM performance by grounding responses in structured knowledge from the LINDDUN Knowledge Base and the AI Privacy Knowledge Base, providing contextual information relevant to potential privacy violations and improving the accuracy of attack identification.
PriMod4AI demonstrates a consistent level of agreement between different Large Language Model (LLM) variants when identifying AI-specific privacy threats through the use of Retrieval-Augmented Generation. Quantitative analysis, using Cohen’s Kappa statistic, reveals moderate to substantial agreement ranging from 0.61 to 0.70. Specifically, the Autonomous Driving System achieved a Cohen’s κ of 0.61, indicating moderate agreement, while the Face Authentication System showed a higher level of agreement with a Cohen’s κ of 0.70. These results suggest that PriMod4AI provides a reliable and consistent automated approach to privacy risk analysis, despite utilizing different LLM implementations.
Beyond Reaction: Towards a Proactive Future
The advent of PriMod4AI signals a fundamental shift in how artificial intelligence systems address privacy concerns, moving beyond the traditional cycle of identifying vulnerabilities after a breach to a model of preventative design. Historically, privacy engineering has largely been a reactive process – patching flaws as they are discovered through adversarial testing or real-world exploits. PriMod4AI, however, automates the identification of potential privacy threats – such as data leakage through model inversion or membership inference – during the development phase. This allows developers to anticipate and mitigate these risks before deployment, embedding privacy directly into the AI’s architecture. By proactively addressing these vulnerabilities, PriMod4AI fosters the creation of more resilient and trustworthy AI systems, ultimately reducing the need for costly and often disruptive post-deployment fixes and strengthening user confidence.
The development of truly private artificial intelligence necessitates a shift in focus from simply identifying vulnerabilities after they’ve been exploited to proactively anticipating and mitigating them during the design phase. Two critical threats demanding attention are Shadow Model Reconstruction and Embedding Space Leakage. Shadow models, created by malicious actors, can be built by observing an AI system’s outputs to replicate its functionality, potentially revealing sensitive training data. Simultaneously, Embedding Space Leakage occurs when the internal representations – the ‘embeddings’ – used by an AI system inadvertently expose information about the input data itself. By deeply understanding these vulnerabilities, developers can implement techniques such as differential privacy, federated learning, and adversarial training to build AI systems that are inherently more resilient to privacy attacks, ensuring both functionality and data protection are prioritized from the outset.
Recent evaluations of the PriMod4AI framework reveal a noteworthy degree of consistency in its performance across different Large Language Model (LLM) variants. Specifically, the system achieved a Normalized Robustness Coefficient of 0.6117 when applied to an Autonomous Driving System, indicating a moderate ability to maintain privacy-preserving properties despite variations in the underlying LLM. Further analysis of a Face Authentication System yielded a slightly higher coefficient of 0.7018, suggesting enhanced resilience in that particular application. These results demonstrate that PriMod4AI offers a relatively stable foundation for proactive privacy engineering, even as LLM technology continues to evolve, although further refinement may be necessary to achieve even greater consistency and robustness across diverse AI implementations.
The pursuit of resilient systems necessitates acknowledging inherent decay, a principle reflected in PriMod4AI’s lifecycle-aware approach to privacy threat modeling. The framework doesn’t presume static security; rather, it anticipates evolving risks across an AI system’s lifespan, from initial design to deployment and beyond. As Robert Tarjan aptly stated, “Algorithms must be seen as a part of the larger system, and their performance must be evaluated in that context.” This resonates with PriMod4AI’s holistic view, recognizing that model-centric attacks-a core concern addressed by the research-are not isolated incidents but symptoms of systemic vulnerabilities exposed over time. The framework’s use of LLMs and retrieval-augmented generation offers a means to continuously refine and adapt to these emerging threats, allowing the system to age gracefully rather than succumb to rapid deterioration.
What’s Next?
PriMod4AI offers a snapshot-a logging of the current state-of privacy threat modeling as it applies to increasingly complex AI systems. The framework’s strength lies in acknowledging the lifecycle, but this very acknowledgement reveals the inherent challenge: any model of a system is, by definition, a past tense account. Deployment is merely a point on the timeline, and the true risks will invariably emerge in the uncharted territory beyond the initial assessment. The evolution of model-centric attacks, particularly, suggests a need to move beyond identifying static vulnerabilities to anticipating adversarial adaptation.
The reliance on retrieval-augmented generation, while effective, introduces its own decay. The knowledge base, the system’s chronicle, will inevitably become incomplete, biased by the data it contains, or rendered obsolete by novel attack vectors. Future work must address the question of continuous refinement-how to ensure the framework doesn’t become a historical artifact. The current emphasis on LINDDUN is valuable, yet the taxonomy itself is not immutable; the very definitions of privacy will shift with technological and societal norms.
Ultimately, PriMod4AI-and all such frameworks-are exercises in managing uncertainty. The goal isn’t to eliminate risk-that is an asymptotic ideal-but to build systems that age gracefully, that reveal their vulnerabilities before they become critical failures. The true measure of success will not be the completeness of the initial threat model, but the adaptability of the process itself.
Original article: https://arxiv.org/pdf/2602.04927.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Mewgenics vinyl limited editions now available to pre-order
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Invincible Season 4 Episode 6 Release Date, Time, Where to Watch
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Crimson Desert Guide – How to Pay Fines, Bounties & Debt
- ‘Timur’ Trailer Sees Martial Arts Action Collide With a Real-Life War Rescue
2026-02-07 06:59