Author: Denis Avetisyan
A new framework combines the power of large language models with traditional machine learning to intelligently correct and enhance existing industrial applications.
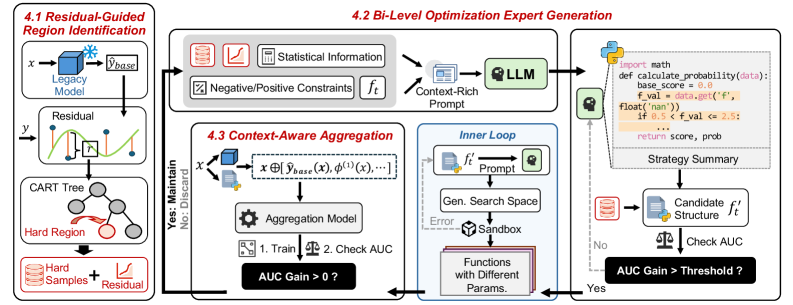
NSR-Boost leverages neuro-symbolic AI and residual learning to improve performance, interpretability, and latency of established models without complete retraining.
Despite the dominance of gradient boosted decision trees in industrial applications, updating legacy models presents significant challenges regarding cost and systemic risk. To address this, we introduce ‘NSR-Boost: A Neuro-Symbolic Residual Boosting Framework for Industrial Legacy Models’, a novel approach that non-intrusively repairs failing models by leveraging large language models to generate interpretable symbolic corrections. This framework achieves substantial performance gains across multiple datasets, including a real-world financial risk control system, while maintaining low latency and enhancing capture of long-tail risks. Could this neuro-symbolic approach redefine the paradigm for safe, low-cost evolution of critical industrial machine learning systems?
Beyond Mere Replacement: Augmenting Legacy Models
A significant portion of deployed machine learning systems aren’t built from scratch with each new advancement; instead, they depend on pre-trained models already integrated into existing workflows – often termed ‘legacy models’. These models represent a substantial investment, not only in initial training costs but also in the engineering effort required for their implementation and maintenance. Completely retraining or replacing these systems with newer architectures is frequently impractical due to the sheer computational expense, the potential disruption to ongoing operations, and the need for extensive validation and re-certification. Consequently, organizations often find themselves constrained by the limitations of their existing models, seeking incremental improvements rather than wholesale changes, highlighting the critical need for strategies that leverage existing assets.
Discarding a pre-trained model in favor of a complete replacement disregards the substantial investment already embodied within its parameters – a learned representation of data that would otherwise need to be entirely rebuilt. This approach isn’t merely inefficient from a computational standpoint; it introduces significant operational costs, demanding complete re-validation, re-deployment, and potential disruption of existing services. The process of verifying a new model’s performance across all relevant use cases is time-consuming and resource-intensive, and the risk of introducing unforeseen errors or regressions is considerable. Consequently, a full replacement strategy often presents a greater overall burden than strategies focused on refining or augmenting the capabilities of the existing model.
Rather than discarding established machine learning models for newer iterations, a compelling strategy centers on augmentation – the addition of specialized components designed to enhance specific capabilities. This approach acknowledges the substantial knowledge already encoded within existing ‘legacy’ models and sidesteps the significant computational expense and data requirements of full retraining. By integrating modular add-ons – perhaps a focused network for handling edge cases or a refined layer for improved feature extraction – performance gains can be realized without disrupting the core functionality. Such a method not only offers a cost-effective path to improvement but also promotes adaptability, allowing systems to evolve incrementally and maintain relevance as new data and challenges emerge. It represents a shift from wholesale replacement towards a more sustainable and resourceful model of machine learning development.

NSR-Boost: A Neuro-Symbolic Framework for Enhancement
NSR-Boost establishes a novel framework by integrating gradient boosting machines (GBMs) with large language models (LLMs). GBMs are utilized for their established performance in structured data prediction and efficiency, while LLMs contribute reasoning and generalization capabilities. The framework doesn’t replace the GBM; instead, it augments it. Specifically, the LLM is employed to generate corrective components – referred to as ‘symbolic experts’ – that address specific failure modes of the existing GBM. This combination allows NSR-Boost to leverage the predictive power of the GBM and the reasoning abilities of the LLM, resulting in a system that aims to outperform traditional methods, particularly in scenarios requiring complex decision-making or generalization to unseen data.
NSR-Boost addresses model inaccuracies by generating targeted ‘symbolic experts’ in the form of executable code snippets. These experts are specifically designed to correct errors identified in the predictions of a pre-existing, or ‘legacy’, model. The system analyzes instances where the legacy model fails and then produces code – typically Python functions – that, when applied to those specific inputs, yield the correct output. This approach allows for localized corrections without requiring retraining of the entire model, and focuses computational resources on regions where performance is demonstrably lacking. The generated code acts as a corrective layer, overriding the legacy model’s output only when a known error condition is detected.
The refinement of generated symbolic experts within NSR-Boost is achieved through a bi-level optimization process. This process consists of an inner loop that optimizes the parameters of each individual expert code snippet to minimize errors on specific data instances where the legacy model fails. An outer loop then optimizes the weighting and selection of these experts, considering their collective impact on the overall model performance across the entire dataset. This hierarchical approach ensures that experts not only correct errors locally, but also contribute to a globally improved model without introducing unintended side effects or overfitting. The objective function for the outer loop balances overall accuracy with the complexity of the ensemble of experts, preventing the selection of overly complex or redundant code.
Identifying Error Regions to Guide Symbolic Expert Generation
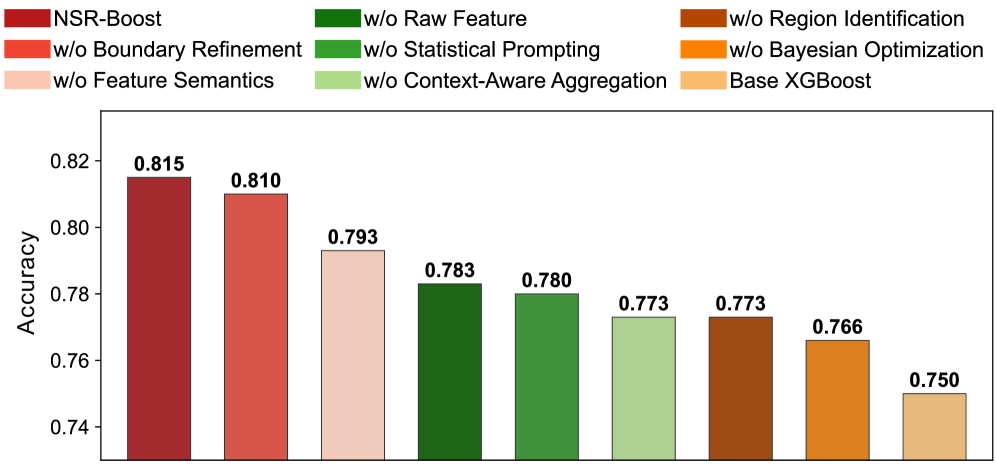
NSR-Boost utilizes decision trees as a method for error analysis of a pre-existing, or legacy, model. These trees are trained on the legacy model’s outputs and associated ground truth data to identify input regions – termed ‘hard regions’ – where the model consistently produces inaccurate predictions. The decision tree structure allows for the partitioning of the input space based on feature values, effectively highlighting the specific data characteristics that correlate with increased error rates. This process doesn’t require knowledge of the internal workings of the legacy model; it is based solely on observed input-output behavior, making it applicable to a wide range of model types. The identified hard regions then serve as the primary target for subsequent expert generation and refinement.
Following identification of error-prone regions, the NSR-Boost framework utilizes the Seed-OSS-36B-Instruct large language model to automatically generate code-based symbolic experts. These experts are specifically designed as programmatic corrections for the identified weaknesses in the legacy model. The Seed-OSS-36B-Instruct model receives prompts detailing the error patterns within the ‘hard regions’ and outputs functional code – typically Python – that aims to rectify these errors during inference. This automated generation process eliminates the need for manual expert creation, enabling rapid adaptation to specific error profiles and scaling the corrective capacity of the system.
Bayesian optimization is utilized to refine the parameters governing the symbolic experts generated to address errors identified by NSR-Boost. This process employs a probabilistic model to efficiently explore the parameter space, balancing exploration of novel configurations with exploitation of previously successful settings. Specifically, Bayesian optimization iteratively proposes parameter sets, evaluates their performance based on a defined reward function – in this case, the degree of error correction – and updates the probabilistic model to guide subsequent proposals. This iterative refinement maximizes the corrective power of the experts and ensures optimal performance by identifying parameter configurations that yield the greatest improvement in overall accuracy without requiring exhaustive search methods.
Context-aware aggregation operates by dynamically weighting the predictions from both the legacy model and the newly generated symbolic experts based on input characteristics. This process utilizes a gating network, trained to assess the reliability of each source – legacy model versus expert – for a given input. The gating network outputs a weight between 0 and 1, determining the contribution of each model to the final prediction. Inputs identified as falling within ‘hard regions’ – where the legacy model previously exhibited high error rates – receive a higher weighting from the corresponding symbolic expert. Conversely, inputs where the legacy model performs well are given greater reliance. This adaptive weighting scheme facilitates a robust prediction by leveraging the strengths of both models and mitigating the weaknesses of each, ultimately improving overall accuracy and generalization performance.
Demonstrable Gains in Performance and Interpretability
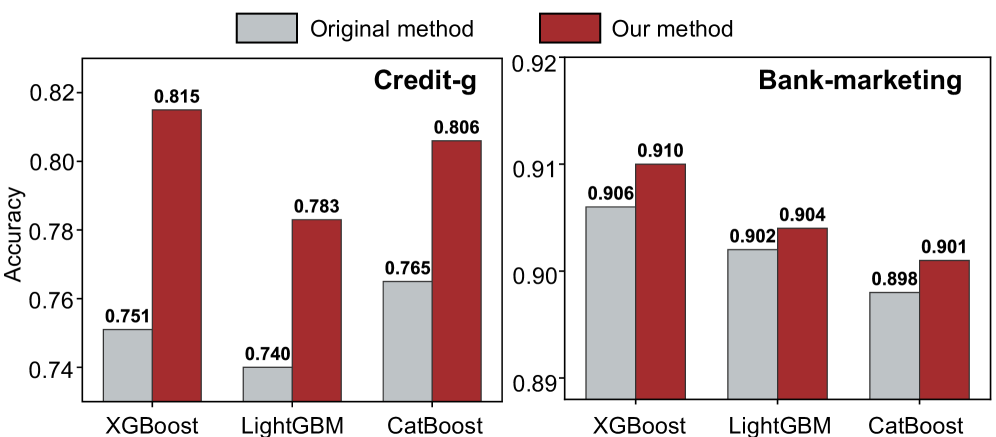
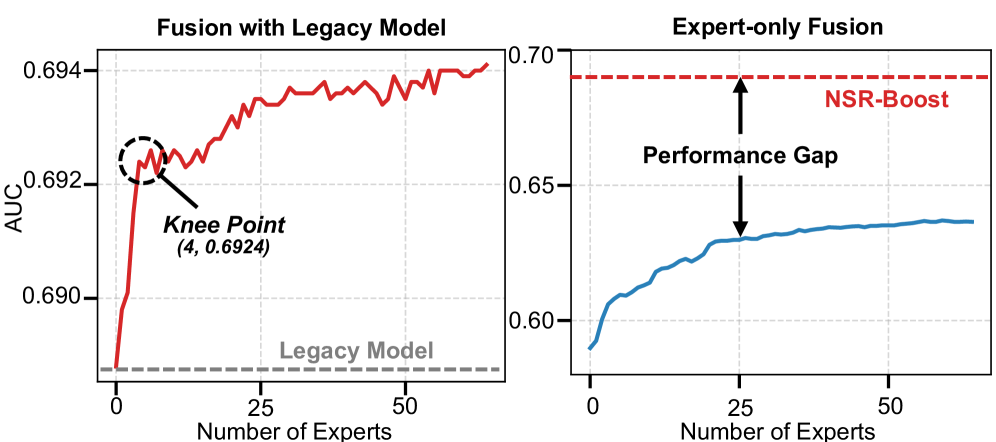
Rigorous empirical evaluation reveals that NSR-Boost consistently surpasses the performance of established machine learning models on tabular data. Across a diverse range of datasets, NSR-Boost demonstrably outperforms algorithms such as XGBoost, LightGBM, TabNet, FT-Transformer, OpenFE, AutoFeat, and CAAFE, establishing a new benchmark for predictive accuracy. This consistent outperformance isn’t merely incremental; the framework achieves substantial gains in key metrics, indicating a robust and reliable improvement over existing state-of-the-art methods. These results confirm NSR-Boost’s efficacy and potential for widespread adoption in applications demanding high predictive power from tabular datasets.
NSR-Boost demonstrably advances the state-of-the-art in tabular data analysis, consistently delivering improved predictive power on challenging datasets. Empirical evaluations reveal performance gains of up to 1.17% in Area Under the Curve (AUC) and 1.81% in Kolmogorov-Smirnov (KS) statistic when applied to real-world financial data. Importantly, these substantial improvements in accuracy are achieved without compromising computational efficiency; the framework maintains inference latency below 1 millisecond, ensuring practical applicability even in time-sensitive scenarios. This combination of enhanced performance and rapid processing positions NSR-Boost as a compelling solution for organizations seeking to maximize the value derived from their tabular data assets.
NSR-Boost distinguishes itself not only through predictive power, but also through a marked increase in model transparency. The framework achieves this by encapsulating corrective actions within dedicated ‘symbolic experts’ – discrete, interpretable units that refine predictions. This isolation allows for a clear tracing of the reasoning behind each outcome, moving beyond the ‘black box’ nature of many machine learning models. Users can readily discern why a particular prediction was made, examining the specific symbolic experts triggered and the adjustments they implemented. This enhanced interpretability is particularly valuable in high-stakes applications, such as financial risk assessment or medical diagnosis, where understanding the basis for a decision is paramount for both trust and effective debugging.
The enhanced interpretability of NSR-Boost is particularly crucial in domains where model transparency is paramount, such as finance and healthcare. A clear understanding of the factors driving predictions isn’t merely academic; it directly builds trust with stakeholders and end-users who require justification for automated decisions. Furthermore, this interpretability streamlines the debugging process, allowing developers to quickly identify and rectify errors or biases within the model’s logic. In highly regulated industries, this capability is essential for demonstrating compliance with auditing requirements and ensuring responsible AI practices, reducing the risk of legal challenges and fostering greater accountability.
Rigorous evaluation across six diverse public datasets demonstrates the consistent efficacy of the framework, achieving a mean rank of 1.01. This superlative performance indicates that, on average, the framework consistently outperforms other evaluated models-effectively securing the top position across a broad spectrum of tabular data challenges. Such a low mean rank isn’t simply a statistical anomaly; it suggests a robust and generalizable approach to feature engineering and model building, capable of adapting to varying data distributions and complexities. The results highlight the framework’s potential as a reliable and high-performing solution for a wide range of tabular learning tasks, establishing a new benchmark for performance in the field.
NSR-Boost distinguishes itself through a design prioritizing seamless integration and broad applicability. The framework’s modular construction allows it to be readily deployed across diverse tabular datasets, circumventing the need for extensive re-engineering when faced with new data characteristics. Crucially, NSR-Boost isn’t limited to novel model development; its adaptable architecture facilitates incorporation into existing, or ‘legacy’, model pipelines. This capability allows organizations to enhance the performance and interpretability of established systems without complete overhauls, reducing both the cost and complexity associated with adopting advanced machine learning techniques. The resulting flexibility ensures NSR-Boost can provide value across a wide spectrum of applications and organizational contexts.
The pursuit of robust and interpretable models, as exemplified by NSR-Boost, aligns with a fundamental principle of computational purity. Robert Tarjan once stated, “If it feels like magic, you haven’t revealed the invariant.” This sentiment perfectly encapsulates the framework’s approach to enhancing legacy models. Rather than treating existing systems as black boxes, NSR-Boost utilizes Large Language Models to discover and articulate the symbolic corrections – the invariants – that improve performance. By explicitly defining these corrections, the framework moves beyond empirical success toward provable improvements and increased transparency, addressing a critical challenge in deploying complex machine learning systems in industrial settings. The framework isn’t simply making things work; it’s revealing why they work.
What Lies Ahead?
The pursuit of augmenting existing models with neuro-symbolic corrections, as demonstrated by NSR-Boost, reveals a fundamental tension. The framework elegantly addresses the practical need for performance gains in legacy systems, but sidesteps the more challenging question of why these corrections are necessary in the first place. While LLM-generated symbolic expressions offer interpretability, they remain, at their core, empirical patches – elegant heuristics, not first-principles solutions. The true test will lie in determining whether these symbolic additions reveal underlying flaws in the original model’s assumptions, or simply mask them with statistically convenient adjustments.
Future work must confront the limitations inherent in relying on LLMs as oracles of symbolic truth. The generation of ‘correct’ symbolic expressions is, inevitably, bound by the biases and imperfections of the training data. A more rigorous approach would involve formal verification techniques, ensuring that the generated corrections not only improve performance on existing datasets, but also adhere to established mathematical or domain-specific constraints. This is not merely a matter of achieving higher accuracy; it is about building systems whose behavior can be demonstrably and provably correct.
Ultimately, the success of this line of inquiry hinges on a shift in focus. The goal should not be to create increasingly complex systems that ‘work well enough’, but rather to develop a deeper understanding of the underlying principles governing the data itself. The pursuit of elegance, in this context, demands mathematical purity – a commitment to solutions that are not merely effective, but inherently, undeniably correct.
Original article: https://arxiv.org/pdf/2601.10457.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Mewgenics vinyl limited editions now available to pre-order
- Invincible Season 4 Episode 6 Release Date, Time, Where to Watch
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Solo Leveling’s New Manhwa Chapter Revives a Forgotten LGBTQ Story After 2 Years
- ‘Timur’ Trailer Sees Martial Arts Action Collide With a Real-Life War Rescue
2026-01-17 10:25