Author: Denis Avetisyan
A new approach leverages token-level loss to more accurately forecast how well a model will perform on unseen tasks.
NeuNeu, a neural network-based predictor, surpasses traditional scaling laws by utilizing quantile regression and meta-learning techniques to improve downstream task performance prediction.
While power-law relationships effectively capture aggregate improvements in language model performance with increased compute, predicting downstream task accuracy remains surprisingly difficult due to diverse scaling behaviors and limitations of existing methods. This paper introduces ‘Neural Neural Scaling Laws’, a novel approach that frames scaling law prediction as a time-series extrapolation problem solved with a neural network-NeuNeu-which combines token-level validation losses with observed accuracy trajectories. NeuNeu achieves a 38% reduction in mean absolute error compared to logistic scaling laws when predicting performance on 66 downstream tasks and notably generalizes to unseen model families and tasks. Could this data-driven approach unlock more reliable and nuanced predictions of language model capabilities at scale?
The Erosion of Linear Returns
The pursuit of increasingly powerful language models has largely focused on scaling – boosting the number of parameters, the size of training datasets, and computational resources. However, recent research indicates that this relationship between scale and performance isn’t linear. While larger models generally do perform better on many benchmarks, the improvements aren’t consistently proportional to the increase in size. Gains become incrementally smaller, suggesting diminishing returns; doubling the model size doesn’t necessarily translate to a doubling of capability. This phenomenon implies that simply adding more of the same – more parameters and data – may hit a point of saturation, where further scaling yields only marginal benefits and that fundamental breakthroughs in model architecture, rather than sheer size, are needed to achieve significant advancements in artificial intelligence.
Current methods for predicting language model performance, often reliant on scaling laws derived from validation loss, demonstrate a troubling inconsistency as models grow larger. These laws, while reasonably accurate for smaller models, begin to falter when extrapolated to the scale of contemporary systems, consistently underestimating capabilities and failing to capture emergent behaviors. This divergence isn’t merely a matter of recalibration; it suggests that the relationship between model size, dataset size, and performance is not a simple power law extending indefinitely. Consequently, researchers are actively pursuing new predictive frameworks that incorporate factors beyond sheer scale – such as architectural innovations, training methodologies, and the inherent quality of the training data – to more accurately forecast the potential of future language models and guide resource allocation towards genuinely impactful advancements.
Current research indicates that simply amplifying the scale of language models – increasing the number of parameters, the volume of training data, and computational power – yields diminishing returns when it comes to achieving genuine reasoning abilities. While larger models often demonstrate improved performance on benchmark tasks, this progress doesn’t consistently translate into enhanced capabilities like common sense reasoning, complex problem-solving, or robust generalization. This suggests that a fundamental limitation isn’t in the quantity of resources applied, but rather in the underlying architectural design of these models. Existing architectures may lack the necessary structures to effectively process information and establish the complex relationships required for true understanding, implying a need for innovative approaches that go beyond simply scaling up existing paradigms. The pursuit of artificial general intelligence, therefore, necessitates a focus on architectural innovation alongside continued scaling efforts.
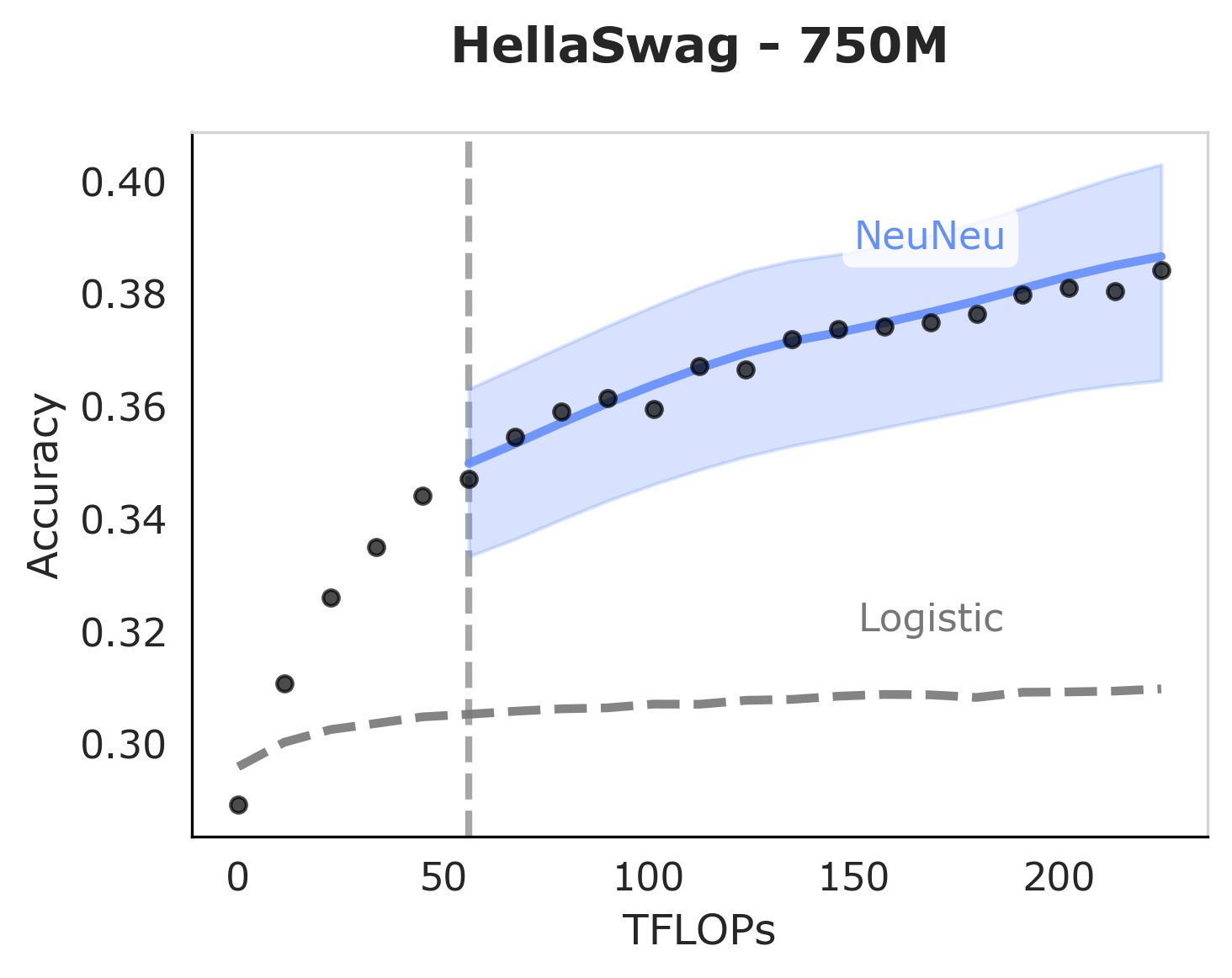
Beyond Aggregated Signals: Unveiling Learning Trajectories
Traditional scaling laws in machine learning predominantly utilize average validation loss as the primary metric for assessing model performance and guiding resource allocation. However, this metric represents a single, aggregated value that inherently discards crucial information about the underlying learning process. Specifically, averaging obscures the distribution of loss values across individual data points or tokens. A model can achieve a low average loss while still exhibiting significant variance in its predictions, potentially indicating poor generalization or overfitting to specific subsets of the training data. Furthermore, averaging fundamentally loses information about the probabilities assigned to different tokens, as it only considers the correctness of the prediction, not the confidence or distribution of possible outputs. This simplification limits the ability to diagnose learning dynamics and optimize model training effectively.
The Accuracy Trajectory, representing the sequence of validation accuracy values recorded throughout training, provides a more granular view of model learning than a single, final accuracy score. By observing this trajectory, researchers can identify instances of rapid initial progress followed by plateaus, suggesting potential limitations in model capacity or data quality. A consistently decreasing trajectory indicates stable learning, while an increasing trajectory followed by a decline can signal overfitting, where the model performs well on the training data but poorly on unseen data. Analysis of the slope and curvature of the trajectory allows for quantitative assessment of learning rate and the onset of generalization issues, enabling more precise tuning of hyperparameters and regularization techniques compared to relying solely on average validation loss.
Histogram representation of token probabilities provides a more complete picture of model behavior than scalar loss values by capturing the full distribution of predicted probabilities for each token. Instead of solely focusing on the average or most likely token, a histogram bins probability values, revealing the spread and shape of the distribution. This allows for the identification of characteristics such as high-confidence predictions, uncertainty in predictions (indicated by a wider spread), and potential issues like overconfidence or ambiguity in the model’s predictions. By tracking changes in these histograms throughout training, researchers can gain insights into how the model refines its predictions and its evolving understanding of the data distribution, offering a more granular assessment of learning than is possible with aggregated metrics.
![The model integrates token-level validation probabilities, historical downstream accuracies, and compute gaps into a BERT-style Transformer to predict downstream accuracy distributions via quantile regression on the <span class="katex-eq" data-katex-display="false">[CLS]</span> token.](https://arxiv.org/html/2601.19831v1/x2.png)
NeuNeu: Predicting Performance Through Learned Dynamics
The Neural Neural Scaling Law utilizes a neural network to predict performance on downstream tasks by analyzing observed accuracy trajectories during training and incorporating token-level information. This approach moves beyond traditional scaling laws which typically rely on aggregate metrics like average validation loss. By modeling the complete accuracy trajectory – the sequence of accuracy values observed over training steps – and conditioning on token-level losses, the model captures a more granular signal of learning progress. This allows for predictions of final performance based on early-stage training data, potentially enabling more efficient resource allocation and model selection.
Traditional methods for predicting model performance rely heavily on average validation loss as a primary indicator of learning progress; however, this metric provides a limited view, obscuring information about individual data points and the nuances of the learning process. Incorporating token-level loss, which calculates loss for each token in a sequence, provides a significantly more granular signal. This allows the model to assess performance on individual examples and identify specific areas of difficulty, leading to a more accurate representation of learning dynamics and improved predictive capability compared to methods utilizing only aggregate loss values. The increased detail captured by token-level loss enables a finer-grained analysis of the learning trajectory, offering insights beyond what average validation loss can provide.
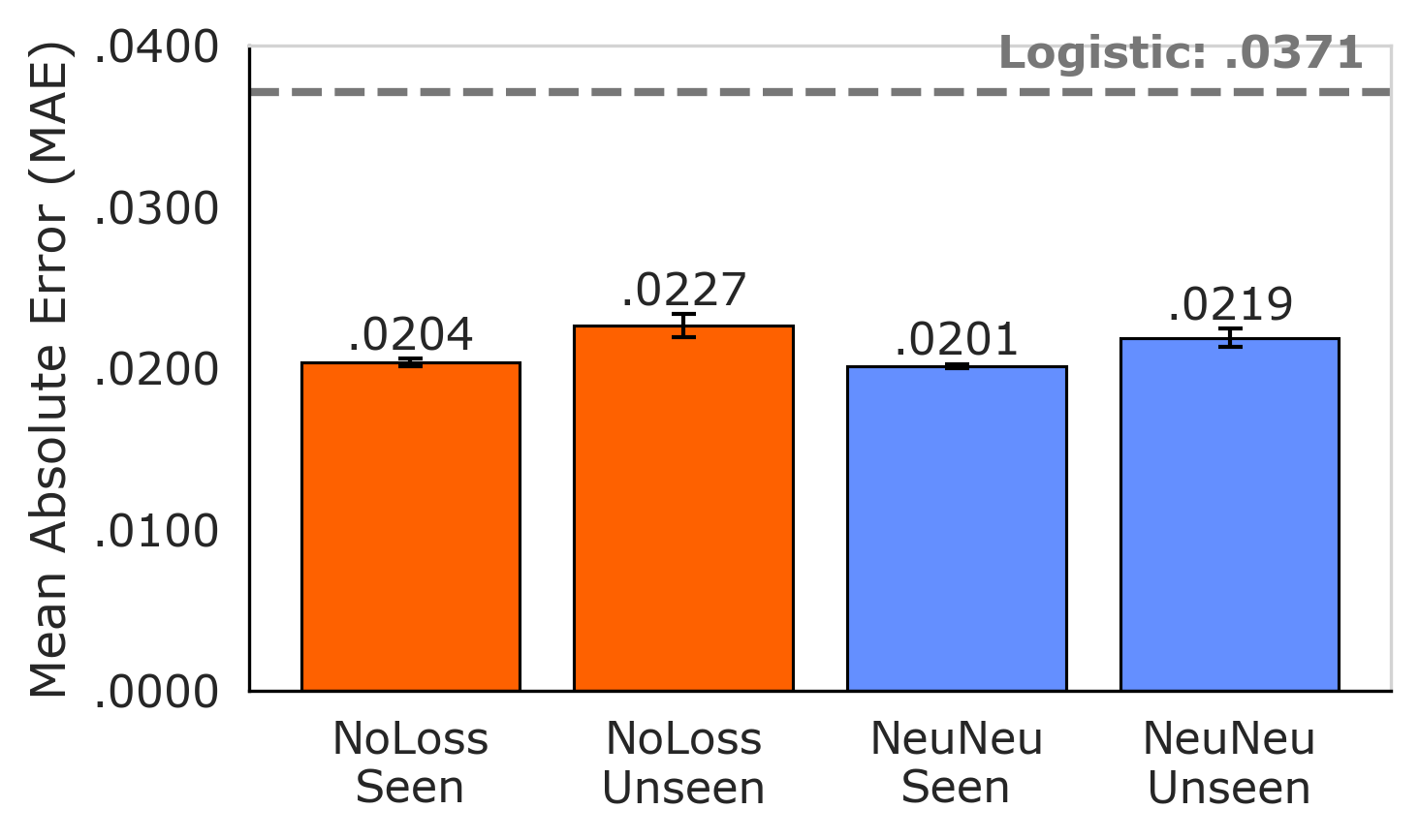
Quantile regression was implemented to move beyond single-point predictions of downstream task performance, instead providing a probabilistic range of potential outcomes. This approach models the conditional quantiles of the performance distribution, enabling the estimation of uncertainty alongside the central tendency. Results demonstrate a 38% reduction in Mean Absolute Error (MAE) – decreasing from 3.29% with traditional logistic scaling laws to 2.04% – indicating improved predictive accuracy and a more reliable assessment of potential performance variations. The method provides a more nuanced understanding of model scalability than methods that output a singular predicted value.
Towards a More Organic Intelligence
The prevailing approach to artificial intelligence often prioritizes achieving a desired outcome, treating the learning process as a black box. However, recent work with NeuNeu indicates that focusing solely on the final state of a model overlooks critical information. This research suggests that the dynamics of learning – how a model changes and adapts over time – are fundamentally important for building genuinely intelligent systems. By analyzing these dynamic changes, NeuNeu demonstrates an ability to predict which model configurations will ultimately perform better, highlighting that understanding how a model learns can be as valuable, if not more so, than simply knowing what it has learned. This shift in perspective opens new avenues for AI development, potentially allowing researchers to design systems that not only achieve goals but also learn and adapt in a more robust and human-like manner.
The research establishes a compelling link between the observed learning dynamics in NeuNeu and the principles of ‘World Model’ learning – a paradigm where artificial intelligence doesn’t just learn what to predict, but builds an internal simulation of how the world changes. This approach allows models to anticipate future states and plan accordingly, moving beyond simple pattern recognition. By demonstrating that tracking the process of learning is more informative than solely assessing the final performance, the study suggests a path towards AI systems capable of robust generalization and adaptation. The success of NeuNeu hints at the possibility of creating models that actively ‘imagine’ different scenarios – a crucial capability for navigating complex and unpredictable environments, mirroring the predictive abilities found in biological intelligence.
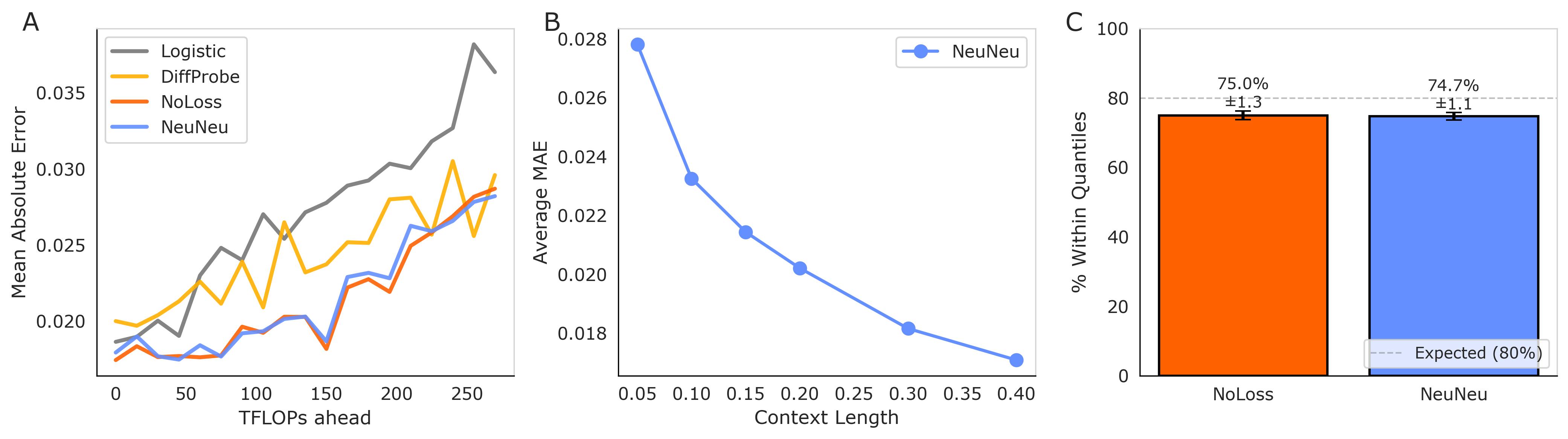
Recent advancements in machine learning model evaluation have yielded a noteworthy performance boost with the development of NeuNeu, a system designed to predict the relative performance of different model configurations. Specifically, NeuNeu achieves a 12.3% improvement in ranking accuracy – reaching 75.6% – when compared to traditional logistic scaling laws, which attain only 63.3% in the same predictive task. This enhanced accuracy isn’t simply a marginal gain; NeuNeu also demonstrates robust calibration, successfully capturing the true performance range approximately 75% of the time within its predicted 10%-90% interquantile range. This suggests that NeuNeu offers not only a more accurate ranking of models, but also a more reliable estimation of their potential, offering valuable insights for efficient resource allocation and hyperparameter optimization in complex machine learning workflows.
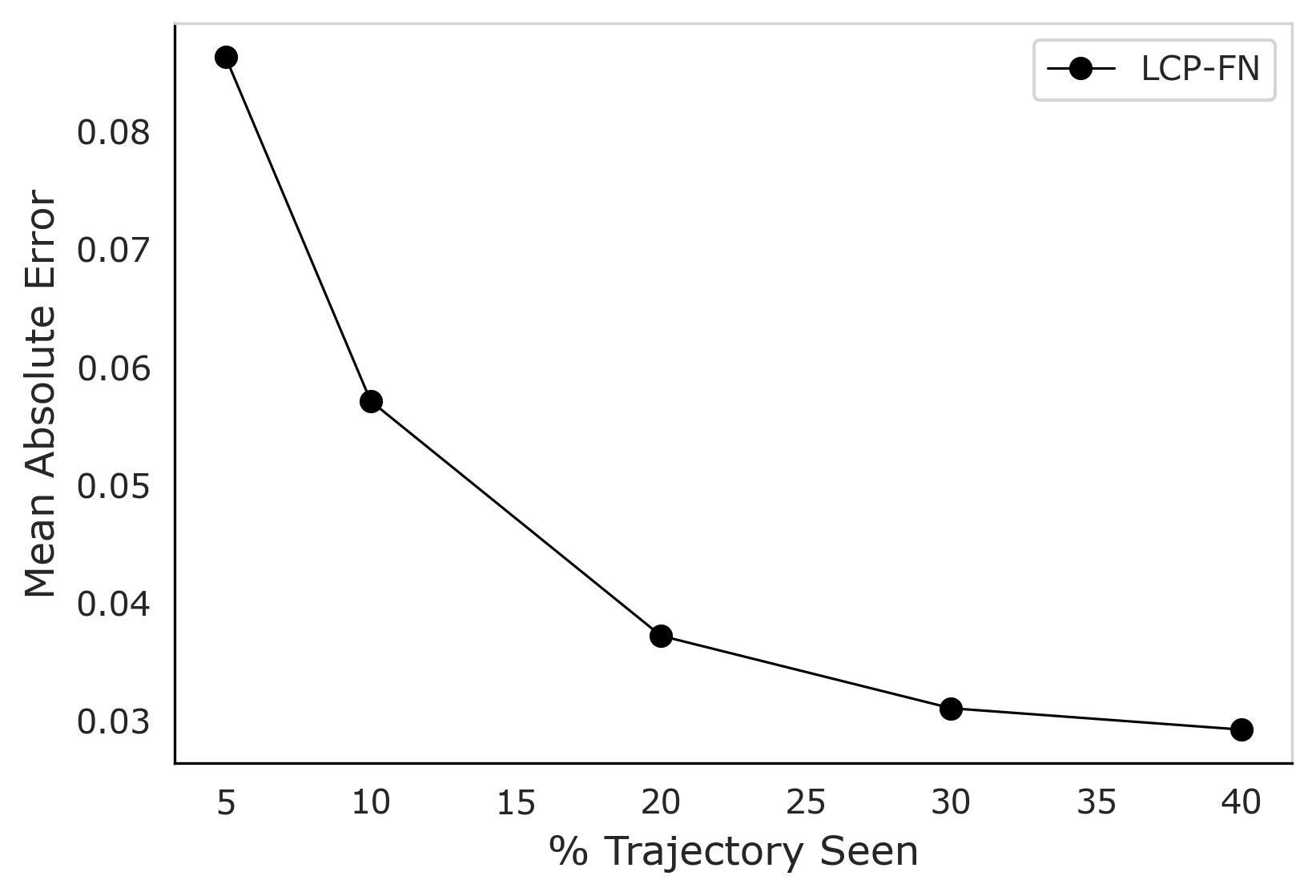
The pursuit of predictable system behavior, as demonstrated by NeuNeu’s capacity to forecast downstream task performance, echoes a fundamental truth about complex systems. While traditional scaling laws offer a simplified view, often failing to account for the nuances of token-level loss, NeuNeu embraces the inherent messiness of data. This approach aligns with the understanding that incidents aren’t failures, but rather necessary steps towards maturity. As Bertrand Russell observed, “The difficulty lies not so much in developing new ideas as in escaping from old ones.” NeuNeu’s success isn’t simply about achieving higher accuracy; it’s about escaping the limitations of outdated predictive models and acknowledging that true understanding emerges from embracing the full spectrum of system behavior.
The Horizon Beckons
The advent of NeuNeu marks a familiar juncture: a refinement of predictive capacity, not a transcendence of limitation. Every commit is a record in the annals, and every version a chapter, yet the fundamental challenge remains. Scaling laws, even those informed by the granularity of token-level loss, offer correlation, not causation. The system predicts, but does not explain why performance shifts, and that asymmetry is a debt accruing with each iteration. The extrapolation, while demonstrably improved, is still an exercise in hopeful projection-a gamble against the inevitable decay of model fidelity as it ventures beyond the observed data manifold.
The reliance on meta-learning, while promising, implicitly acknowledges the fragility of transfer. Each downstream task is a new environment, and the learned heuristics, while generally applicable, are subject to unforeseen pressures. Delaying fixes is a tax on ambition; a more robust approach will require a deeper understanding of the underlying mechanisms driving generalization, rather than merely smoothing the curves of observed performance.
The true horizon lies not in predicting what will happen, but in modeling how systems age. The field must shift from quantifying performance to understanding the sources of entropy-the subtle fractures within the network that herald eventual decline. Only then can the ambition of scaling be tempered with the wisdom of graceful decay.
Original article: https://arxiv.org/pdf/2601.19831.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- All Itzaland Animal Locations in Infinity Nikki
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- Crimson Desert: Disconnected Truth Puzzle Guide
- How to Get to the Undercoast in Esoteric Ebb
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- BloxStrike codes (March 2026)
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- 6 Ways Invincible Season 4’s Hell Episode Rewrites The Comics
- Superman/Spider-Man #1 Review: Bigger DC-Marvel Crossovers Teased
2026-01-29 03:30