Author: Denis Avetisyan
New research demonstrates how artificial intelligence can anticipate the likelihood of disclosed corporate risks becoming real-world problems.
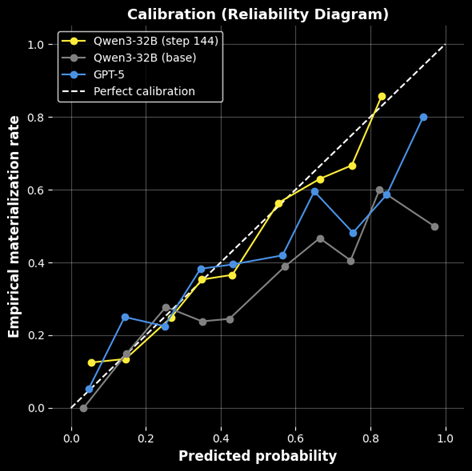
Large language models, trained on SEC filings with an automated supervision pipeline, accurately forecast risk materialization and produce well-calibrated probabilistic estimates without manual labeling.
Despite the prevalence of risk disclosures in SEC filings, their lack of quantified likelihood limits their utility for probabilistic analysis. This limitation motivates ‘Foresight Learning for SEC Risk Prediction’, which introduces a fully automated pipeline to transform qualitative disclosures into temporally grounded, supervised data. The study demonstrates that a compact large language model, trained on this pipeline-generated data, can accurately predict the materialization of disclosed risks and produce well-calibrated probability estimates without relying on manual labeling or proprietary data. Could this approach unlock a general pathway for learning calibrated, decision-relevant signals directly from the wealth of naturally occurring text within enterprise documents?
The Illusion of Foresight: Why Predicting Risk is a Losing Game
The ability to anticipate future risks, as revealed through Securities and Exchange Commission filings, fundamentally underpins sound investment strategies. These disclosures represent a corporation’s assessment of potential events that could materially impact its financial performance, offering critical foresight for investors seeking to mitigate losses and capitalize on opportunities. Accurate prediction isn’t merely about identifying potential problems, but gauging the likelihood and timing of their realization, allowing for proactive portfolio adjustments. Without this predictive capability, investors operate with incomplete information, increasing exposure to unforeseen negative events and hindering the potential for maximizing returns. Consequently, advancements in techniques that can effectively extract and interpret these forward-looking statements are essential for fostering a more informed and resilient financial market.
Current methods of assessing risk within Securities and Exchange Commission filings often falter when confronted with the sheer volume of textual information. Manual reviews are painstakingly slow and prone to human bias, while early natural language processing techniques lack the sophistication to discern nuanced threats embedded within lengthy disclosures. These traditional approaches struggle to efficiently categorize, prioritize, and analyze the countless pages of text, hindering a timely and comprehensive understanding of potential financial hazards. Consequently, critical warning signs can be overlooked, or their significance underestimated, ultimately impacting investment strategies and market stability. The escalating complexity of financial instruments and regulatory reporting further exacerbates these challenges, demanding more advanced analytical tools to effectively navigate the data deluge.
Predictive models analyzing regulatory filings face a persistent hurdle: discerning when a disclosed risk might actually impact a company. Simply identifying a risk – such as shifts in market conditions or emerging litigation – isn’t enough; investors need to understand the probable timeframe for materialization to make informed decisions. Current approaches often treat risk disclosures as static events, overlooking the crucial temporal dimension embedded within the text. A risk mentioned as a distant possibility carries significantly less weight than one described as currently unfolding, yet many models struggle to differentiate these nuances. Consequently, there’s a critical need for methods that can extract and interpret temporal cues – phrases indicating immediacy, duration, or likelihood over time – to provide a more accurate and actionable assessment of future risk exposure.
Automated Scrying: RAG and Gemini as Modern Divination Tools
A Retrieval-Augmented Generation (RAG) pipeline is utilized to automate the creation of ‘Risk Queries’ derived from Securities and Exchange Commission (SEC) filings. This process leverages the Gemini language model, which accesses and processes information directly from the source documents-the SEC filings-during query generation. The RAG approach differs from traditional language model applications by dynamically incorporating relevant context retrieved from these filings, allowing the model to formulate queries specifically related to disclosed risks. This automated generation streamlines the identification of potential risks outlined in financial disclosures, reducing manual review requirements.
The process of converting unstructured text from SEC filings into structured propositions involves identifying key risk factors and representing them as discrete, logical statements. This transformation utilizes natural language processing techniques to extract entities, relationships, and events indicative of potential risks. The resulting structured data, typically formatted as subject-predicate-object triples or similar knowledge graph representations, facilitates targeted prediction tasks. Specifically, these propositions allow for the application of machine learning models to assess the likelihood and impact of identified risks, enabling more precise risk scoring and analysis compared to working directly with raw text.
The generation of ‘Risk Queries’ utilizes a Retrieval-Augmented Generation (RAG) pipeline that directly references source text from SEC filings to constrain the output. This grounding process mitigates the potential for hallucination inherent in large language models by ensuring all generated content is traceable back to documented statements within the filings. Specifically, the RAG pipeline retrieves relevant passages from the filings, and Gemini uses this retrieved context to formulate queries; this dependency on source material improves both the factual accuracy and the relevance of the generated queries to the specific risks disclosed in the filings.
Qwen3-32B: A Sophisticated Algorithm, But Still Just a Guessing Machine
The risk prediction model is built upon Qwen3-32B, a decoder-only transformer architecture comprising 32 billion parameters. This model utilizes a causal language modeling objective, predicting the next token in a sequence based on preceding tokens. The decoder-only structure allows for efficient generation and probabilistic modeling of risk events. Qwen3-32B was selected for its demonstrated capabilities in natural language understanding and generation, and its ability to effectively process sequential data, which is crucial for analyzing the temporal evolution of risk factors. The model’s architecture facilitates the learning of complex relationships between various risk indicators and their eventual materialization.
The risk prediction model employs a foresight learning framework where future, resolved outcomes are utilized as supervisory signals during training. This technique differs from traditional predictive modeling by explicitly incorporating information about the eventual status of a risk event. Rather than solely relying on contemporaneous data, the model learns to associate current conditions with future resolutions – whether a predicted risk materializes or not. This allows the model to optimize its predictions based on a complete understanding of the event lifecycle, effectively treating future outcomes as ground truth for present-day assessments and improving predictive performance.
The model’s capacity to learn the temporal dynamics of risk materialization stems from its training process, which incorporates future-resolved outcomes as direct supervisory signals. This allows the model to not only identify potential risks but also to understand when those risks are likely to manifest, enhancing predictive performance. Quantitative evaluation demonstrates this improvement, with the model achieving a Brier score of 0.0287 – a metric indicating the calibration and accuracy of probabilistic predictions, and representing a statistically significant advancement over baseline methods.
Synthetic Certainty: Propping Up Predictions with Fabricated Data
Model calibration, the alignment between predicted probabilities and actual outcomes, is paramount for reliable machine learning systems. A miscalibrated model might, for example, confidently predict an outcome that rarely occurs, eroding trust and hindering practical application. To rigorously assess calibration, researchers employ metrics like Expected Calibration Error (ECE), which quantifies the difference between a model’s predicted confidence and its observed accuracy. Through careful optimization techniques, a recent study achieved an ECE of 0.0287, demonstrating a high degree of confidence in the model’s probabilistic predictions and suggesting a robust ability to generalize to unseen data. This level of calibration is crucial for applications where understanding the certainty of a prediction is as important as the prediction itself.
The study leverages an Automated Data Generation Pipeline to address limitations inherent in relying solely on real-world data for model training. This pipeline systematically creates synthetic data, expanding the dataset and providing nuanced examples that augment the learning process. By intelligently supplementing existing data, the pipeline facilitates improved model generalization and performance, particularly in scenarios where acquiring sufficient real-world data is challenging or expensive. The generated data isn’t simply additive volume; it’s designed to enhance the model’s understanding of complex relationships, leading to more robust and accurate predictions across a wider range of inputs.
The study demonstrates a significant improvement in model reliability achieved through an automated data generation pipeline. By supplementing real-world data with synthetically created examples, the training process is enhanced, leading to better generalization capabilities. This approach yielded a nearly 80% reduction in calibration error, decreasing from 0.1419 in the pretrained base model to a remarkably low value. Importantly, the resulting model not only surpasses the performance of the initial baseline but also outperforms a leading frontier large language model, highlighting the effectiveness of synthetic data in building more trustworthy and accurate predictive systems.
The pursuit of probabilistic forecasting, as demonstrated by this work with large language models and SEC disclosures, inevitably courts the same fate as all ‘revolutionary’ frameworks. It attempts to codify risk materialization, to predict the unpredictable. Donald Davies observed, “The real problem is that people think things will continue as they have been.” This paper’s success in calibrating probability estimates-avoiding overconfidence despite inherent uncertainty-is notable, yet it merely delays the inevitable. Production will, eventually, reveal unforeseen edge cases, and the model’s elegant predictions will be revealed as another layer of illusion atop complex systems. The calibration is a temporary reprieve, not a permanent solution. One suspects future iterations will simply refine the crutches, not eliminate the need for them.
What’s Next?
The demonstrated capacity to forecast risk materialization from regulatory filings, without relying on painstakingly curated datasets, feels… efficient. Too efficient, perhaps. History suggests this automated supervision pipeline, while elegant in its current form, will quickly become a maintenance burden. Production data rarely conforms to research datasets; edge cases will proliferate, and the initial calibration will inevitably drift. The question isn’t whether the model will fail, but where and when – and how much it will cost to patch.
Future work will undoubtedly focus on scaling these models to broader datasets and incorporating alternative data sources. But a more pressing challenge lies in addressing the fundamental limitations of forecasting itself. Disclosed risks, by their very nature, represent known unknowns. The truly disruptive events – the black swans – will remain stubbornly opaque, even to the most sophisticated language models. Expect to see increasingly complex attempts to model ‘unknown unknowns’, which, if code looks perfect, no one has deployed it yet.
Ultimately, the value proposition of this research hinges on its ability to reduce false positives – to avoid needlessly flagging immaterial risks. The pursuit of perfect precision, however, is a fool’s errand. It’s a constant trade-off between sensitivity and specificity, a Sisyphean task of chasing diminishing returns. The real innovation won’t be in building more accurate models, but in developing more robust systems for managing the inevitable errors.
Original article: https://arxiv.org/pdf/2601.19189.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- All Itzaland Animal Locations in Infinity Nikki
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- How to Get to the Undercoast in Esoteric Ebb
- Gold Rate Forecast
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- A Dark Scream Theory Rewrites the Only Movie to Break the 2-Killer Rule
- 6 Ways Invincible Season 4’s Hell Episode Rewrites The Comics
- Fire Force Season 3 Part 2 Episode 24 Release Date, Time, Where to Watch
2026-01-28 07:16