Author: Denis Avetisyan
A new framework systematically charts the common failure points of large language models, offering a crucial step towards more reliable and understandable AI.
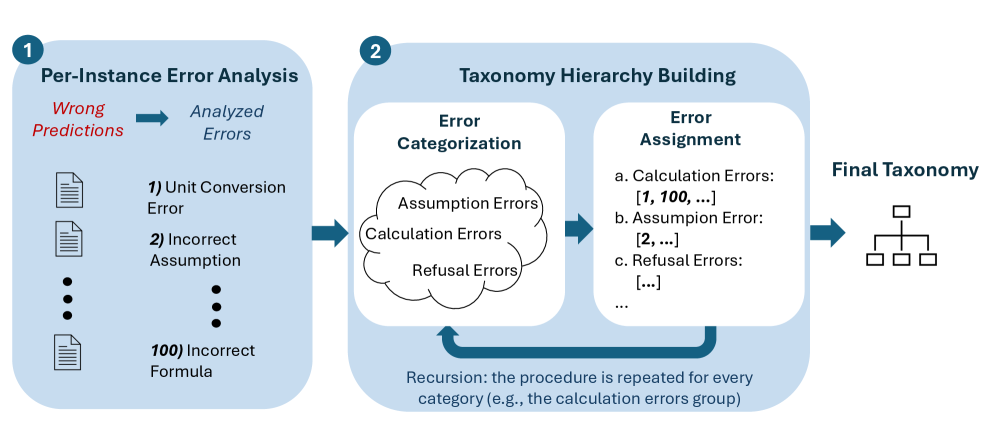
Researchers introduce ErrorMap, a taxonomy of language model errors, and ErrorAtlas, a resulting resource for improved debugging and interpretability.
While current benchmarks reveal when large language models fail, they offer little insight into why. This limitation motivates the work presented in ‘ErrorMap and ErrorAtlas: Charting the Failure Landscape of Large Language Models’, which introduces a novel method, ErrorMap, for systematically charting the sources of LLM failure and constructing ErrorAtlas, a resulting taxonomy of error types. By shifting focus from success rates to granular failure modes-including omissions and misinterpretations-this research exposes hidden weaknesses and offers a deeper layer of evaluation applicable across models and tasks. Will this refined understanding of LLM failure patterns ultimately accelerate progress towards more robust and reliable artificial intelligence?
Unveiling the Nuances of LLM Error: A Systemic Challenge
Despite their impressive capacity to generate human-quality text, Large Language Models (LLMs) are demonstrably fallible, exhibiting errors that range from factual inaccuracies and logical inconsistencies to subtle biases and stylistic oddities. These aren’t simply random glitches; the errors often manifest in nuanced ways, reflecting the complex interplay between the model’s training data, architectural limitations, and the inherent ambiguity of natural language. An LLM might confidently assert a false statement, convincingly fabricate supporting evidence, or produce grammatically correct but semantically nonsensical output. This susceptibility to error isn’t a barrier to progress, but rather a fundamental characteristic demanding careful investigation; understanding how and why these models stumble is paramount to refining their capabilities and ensuring their responsible deployment in real-world applications.
While metrics like accuracy and precision effectively quantify how often a Large Language Model (LLM) fails, they offer little explanation of why those failures occur. A model achieving 90% accuracy, for example, still contains a 10% error rate – but understanding the specific patterns within that 10% remains elusive with these broad measures. Is the model consistently failing on questions requiring common sense reasoning, or is it struggling with nuanced linguistic structures? Without this granular insight, developers are left addressing symptoms rather than root causes, leading to inefficient and often ineffective improvements. Targeted refinement requires dissecting error types – identifying whether failures stem from factual inaccuracies, logical fallacies, contextual misunderstandings, or biases embedded within the training data – a level of detail traditional metrics simply cannot provide.
The pursuit of genuinely reliable artificial intelligence hinges on dissecting not just what large language models get wrong, but precisely why. Superficial metrics fail to illuminate the nuanced ways in which these systems falter – whether through logical inconsistencies, factual inaccuracies, susceptibility to adversarial prompts, or biases embedded within training data. A granular understanding of these failure modes is therefore paramount, enabling developers to move beyond simply improving overall accuracy and toward crafting targeted interventions that bolster robustness and trustworthiness. This detailed analysis allows for the creation of more resilient systems, capable of handling unforeseen inputs, mitigating harmful outputs, and ultimately, fostering greater confidence in their real-world application. Without this deep dive into the roots of error, progress towards truly trustworthy AI remains significantly hampered.
ErrorMap: A System for Granular Error Profiling
ErrorMap introduces a method for LLM error analysis that moves beyond aggregate metrics to examine failures at the individual instance level. This instance-level profiling allows for the precise identification of specific input characteristics and contextual factors contributing to incorrect outputs. By analyzing each failed instance, ErrorMap aims to pinpoint the exact failure points within the LLM’s processing of a given input, offering a granular understanding of model weaknesses not achievable through traditional error rate measurements. This detailed analysis facilitates targeted improvements to model training data or architectural design, addressing the root causes of specific failure modes.
Layered Taxonomy Construction, utilized within ErrorMap, establishes a multi-level classification system for LLM errors. This begins with broad error categories – such as factual inaccuracy, logical reasoning failure, or stylistic issues – which are then recursively subdivided into more specific error subtypes. For example, a ‘factual inaccuracy’ category might branch into ‘temporal error’ (incorrect dates), ‘entity error’ (incorrect names or places), or ‘attribute error’ (incorrect details about an entity). This hierarchical structure allows for granular error profiling, moving beyond simple error counts to pinpoint precise weaknesses in LLM performance and facilitate targeted improvements. The layering enables aggregation of data at different levels of specificity, offering both a high-level overview of error distributions and detailed insights into the root causes of failures.
Error categorization within the ErrorMap framework relies on GPT-oss-120b acting as an automated judge to maintain consistency and reduce subjective bias. This large language model is prompted to evaluate LLM outputs and assign them to specific error types defined within the Layered Taxonomy. Utilizing a consistent judge eliminates variability introduced by human annotators, ensuring that errors are classified according to pre-defined criteria regardless of evaluator. The model’s judgements are then used to populate the error profiles, providing a reliable and objective assessment of LLM performance at the instance level. This approach minimizes inter-annotator disagreement and allows for repeatable, quantifiable error analysis.

ErrorAtlas: Establishing a Static Taxonomy for Comparative Analysis
ErrorAtlas is a statically defined taxonomy constructed through analysis using the ErrorMap methodology. This taxonomy categorizes errors made by Large Language Models (LLMs) into a pre-defined, consistent set of error types, moving beyond simple pass/fail metrics. The static nature of ErrorAtlas ensures reproducibility and comparability of error analyses across different LLMs and evaluation datasets. This standardized framework enables researchers to systematically identify, quantify, and compare the specific error profiles of various models, providing a detailed understanding of their performance characteristics beyond aggregate scores. The taxonomy is designed to facilitate comprehensive error analysis, supporting granular investigation of model weaknesses and strengths.
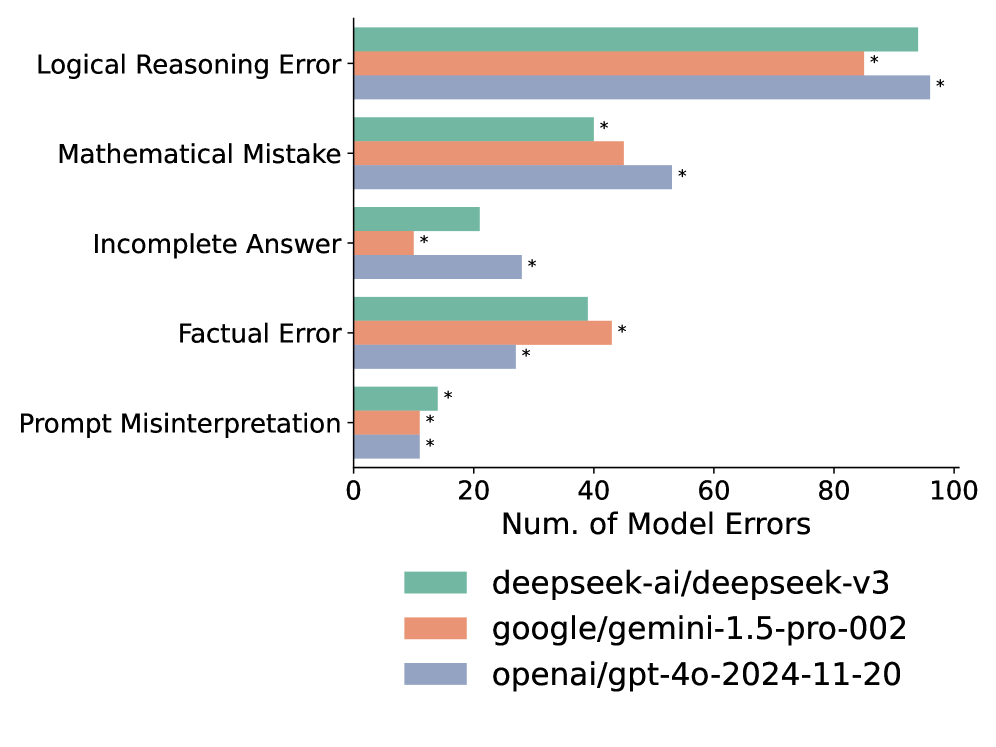
ErrorAtlas enables comparative analysis of Large Language Models by moving beyond aggregate performance metrics to specifically categorize error profiles. Researchers can benchmark LLMs not solely on accuracy or overall task completion, but also on the types of errors generated – such as factual inaccuracies, logical fallacies, or stylistic inconsistencies. This granular approach allows for identification of specific strengths and weaknesses across different models, revealing which models excel in avoiding certain error classes while struggling with others. By quantifying the distribution of error types, ErrorAtlas facilitates a more nuanced comparison, informing model selection for specific applications and guiding targeted development efforts to address prevalent failure modes.
ErrorAtlas-based benchmarking provides detailed insights into Large Language Model performance beyond aggregate scores, enabling identification of specific error types each model exhibits. This granular analysis facilitates targeted model improvement by directing development efforts towards addressing prevalent weaknesses. Validation demonstrates a 91.1% average agreement rate between expert human evaluations and error classifications generated using the ErrorAtlas taxonomy, establishing a high degree of reliability and consistency in its application for comparative analysis and error profiling.
Ensuring Robustness: Validating the Reliability of Error Analysis
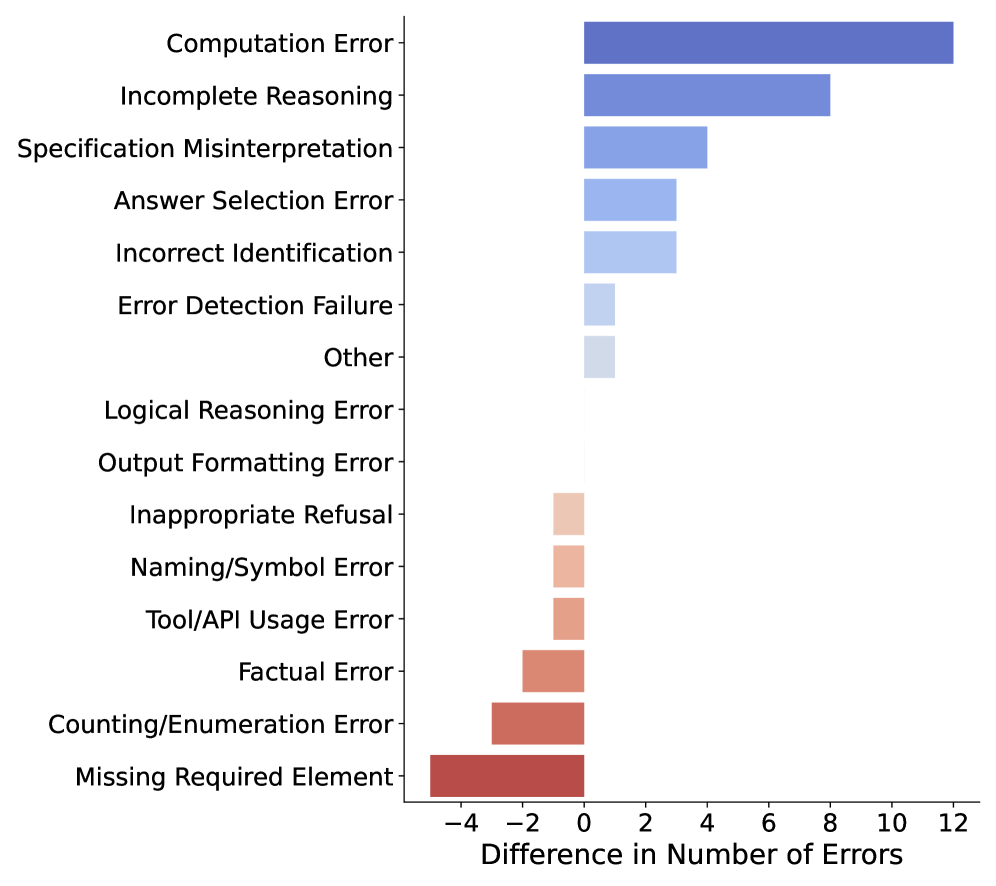
Robustness analysis, facilitated by the ErrorMap framework, rigorously evaluates how consistently an error analysis identifies and categorizes failures across diverse conditions. This process doesn’t simply identify what went wrong, but assesses whether the same errors are consistently flagged, even with slight variations in input phrasing, model parameters, or evaluation settings. By systematically introducing perturbations and observing the stability of error categorization, ErrorMap quantifies the reliability of the analysis itself, moving beyond a single snapshot to reveal potential vulnerabilities in the evaluation methodology. A consistent error analysis is paramount; unreliable identification of failure modes hinders effective model improvement and can mask critical weaknesses, making robustness testing an indispensable component of trustworthy large language model development.
The consistency of identifying and categorizing errors in large language models is paramount for trustworthy evaluation, and this is increasingly quantified through techniques borrowed from machine learning. Binary classification, for instance, assesses whether an error falls into a specific category – such as factual inaccuracy or logical fallacy – providing a clear, quantifiable metric for agreement between different assessments or iterations of the error analysis process. Further bolstering this stability measurement is the use of Cosine Similarity, which evaluates the angle between vectors representing error categorizations; a smaller angle – and therefore a higher similarity score – indicates strong agreement and a robust, reliable categorization scheme. These methods effectively transform subjective error analysis into objective, measurable data, providing confidence in the identification of critical failure modes and the efficacy of mitigation strategies.
A dependable error analysis is paramount for building confidence in large language model (LLM) evaluations and for proactively addressing potential system failures. Rigorous testing reveals that this approach maintains a high degree of consistency, demonstrating an upper bound similarity of 88% across varied conditions and a lower bound precision of 88% in error categorization. This level of reliability indicates a stable and trustworthy framework for identifying and mitigating critical failure modes, ultimately providing a solid foundation for continued LLM development and deployment with increased assurance of performance and safety.

The pursuit of comprehensive error analysis, as detailed in the creation of ErrorMap and ErrorAtlas, reveals a fundamental truth about complex systems. It’s not enough to simply identify that something failed; understanding how and why requires meticulous categorization. This echoes Claude Shannon’s insight: “The most important thing is to get the message across. If the system looks clever, it’s probably fragile.” A taxonomy of failure modes, like the one presented, isn’t about showcasing ingenuity; it’s about building a robust understanding of limitations. The architecture of ErrorMap prioritizes clarity – a direct acknowledgment that structure dictates behavior, and a well-defined structure is essential for effective debugging and model improvement. If the taxonomy becomes too complex, its utility diminishes, much like an over-engineered solution obscuring the core problem.
The Shifting Sands
The construction of ErrorMap and ErrorAtlas, while a necessary step, merely clarifies the contours of a problem that will inevitably expand. Every categorization, every taxonomy, is a provisional scaffolding erected against the chaotic tide of emergent behavior. The very act of labeling a failure mode invites its refinement, its splitting into sub-categories, its eventual obsolescence as models evolve. This is not a deficiency, but the inherent property of complex systems: the map is never the territory, and the territory is constantly reshaping itself.
Future work must resist the temptation to treat these atlases as definitive. Instead, the methodology should be viewed as a dynamic process – a continuous cycle of observation, categorization, and revision. A crucial direction lies in understanding the relationships between error types. ErrorMap, in its current form, provides a static snapshot. The real leverage will come from charting the dependencies – how one failure mode preconditions another, creating cascading errors. Every new dependency is the hidden cost of freedom, and every ‘fix’ introduces new potential points of failure.
Ultimately, the goal isn’t to eliminate errors – an impossible task – but to build systems that degrade gracefully, revealing the structure of their failures. A transparent failure is far more valuable than a silent one. The pursuit of interpretability, therefore, isn’t about achieving perfect understanding, but about constructing a legible landscape of vulnerabilities – a landscape that can be navigated, and perhaps, even anticipated.
Original article: https://arxiv.org/pdf/2601.15812.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- Gold Rate Forecast
- How to Solve the Glenbright Manor Puzzle in Crimson Desert
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- All Itzaland Animal Locations in Infinity Nikki
- 8 Actors Who Could Play Blackbeard In One Piece Live-Action Season 3
- All 10 Potential New Avengers Leaders in Doomsday, Ranked by Their Power
- A Dark Scream Theory Rewrites the Only Movie to Break the 2-Killer Rule
2026-01-24 09:19