Author: Denis Avetisyan
New research reveals that current artificial intelligence systems struggle to accurately and urgently translate critical information during rapidly unfolding emergencies.
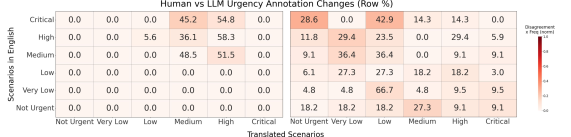
Large language models demonstrate shortcomings in crisis-specific machine translation, necessitating improved benchmarks and evaluation metrics for cross-lingual communication.
While large language models (LLMs) offer promising solutions for multilingual crisis communication, their reliability in high-stakes scenarios remains largely unproven. This is the central question addressed in ‘LLM-Powered Automatic Translation and Urgency in Crisis Scenarios’, which investigates the performance of both LLMs and dedicated machine translation systems in preserving critical urgency cues when translating crisis-related information across 32 languages. The study reveals substantial performance degradation and, crucially, that even linguistically accurate translations can distort perceived urgency, with LLM-based classifications varying significantly by language. Given these findings, how can we develop robust, crisis-aware evaluation frameworks to ensure responsible deployment of these technologies when lives are on the line?
The Imperative of Precise Communication in Crisis
In the face of any crisis – be it a natural disaster, public health emergency, or humanitarian conflict – the swift and accurate dissemination of information is fundamentally crucial for effective response and minimizing harm. However, linguistic diversity frequently introduces significant obstacles, slowing down vital communication channels and diminishing situational awareness. When critical warnings, instructions, or requests for aid cannot be readily understood by affected populations, response efforts are hampered, potentially leading to increased suffering and loss of life. This communication breakdown isn’t simply a matter of direct translation; cultural context, nuanced phrasing, and the rapid evolution of information during a crisis all contribute to the challenge, underscoring the need for innovative strategies to bridge linguistic divides and ensure everyone receives the information they need, when they need it.
Conventional translation practices, reliant on human expertise, often falter when faced with the time-sensitive demands of crisis communication. The intricate subtleties of language – idioms, cultural context, and implied meaning – are easily lost or misinterpreted, particularly when dealing with languages possessing limited digital resources and fewer trained translators. This scarcity exacerbates the problem, leading to delays in disseminating critical information and potentially compromising response efforts. Consequently, vital warnings, public health advisories, or evacuation instructions may arrive too late, be misunderstood, or fail to reach vulnerable populations who lack access to readily available, high-quality translations, underscoring the urgent need for innovative solutions that bridge linguistic divides during emergencies.
The speed at which crises unfold necessitates automated translation tools, but simply converting words isn’t enough; preserving the meaning – especially the sense of urgency – presents a significant hurdle. Recent research demonstrates that nuances crucial for conveying immediate threat or critical instructions are often lost in translation, even with sophisticated algorithms. This isn’t merely a matter of linguistic difference; the cultural framing of urgency varies, and direct equivalents often fail to elicit the necessary response. Consequently, developers are focusing on systems that prioritize the accurate transmission of core informational elements – the ‘what,’ ‘where,’ and ‘how’ of a crisis – alongside indicators of severity, rather than striving for literal, word-for-word replication. The goal is to create tools that ensure vital messages resonate with the same immediacy, regardless of the recipient’s native language, ultimately bolstering effective disaster response and saving lives.
The Evolution from Rules to Statistical Inference
Early machine translation systems, exemplified by Apertium, operated on the principle of explicitly defined linguistic rules created by human experts. These systems required substantial manual effort to develop dictionaries, morphological analyzers, and transfer rules for each language pair. The process involved defining grammatical structures, lexical correspondences, and translation patterns through formal rules. While providing a degree of control and predictability, this approach proved difficult to scale to multiple languages or complex linguistic phenomena, as the number of rules grew exponentially with each added feature or language. Consequently, maintaining and expanding these rule-based systems became increasingly resource-intensive and limited their adaptability to nuanced or previously unseen text.
Neural machine translation (NMT) represents a fundamental change from prior methods by eliminating the need for explicitly programmed linguistic rules. Traditional systems required human experts to define grammatical structures, vocabulary, and translation equivalencies. NMT, however, utilizes large parallel corpora – datasets containing text in multiple languages – to statistically learn the complex relationships between languages. This data-driven approach allows the model to identify and generalize translation patterns autonomously, improving both translation quality and adaptability to new linguistic data without requiring manual rule updates. The model learns to represent words and phrases as vectors in a high-dimensional space, enabling it to capture semantic similarities and generate translations based on probabilistic calculations of word sequences.
The DARPA LORELEI program, initiated in 2017, focused on developing Neural Machine Translation (NMT) systems tailored for high-accuracy, low-resource language translation in the context of health-related crisis situations. Specifically, the program prioritized translation between English and Arabic and Swahili, languages critical for disseminating information during humanitarian crises in the Middle East and Africa. LORELEI’s advancements included techniques for handling data scarcity, improving robustness to noisy input, and enhancing the translation of specialized medical terminology. The program culminated in the creation of openly available datasets and translation models designed to support rapid response efforts and facilitate effective communication during public health emergencies.
Leveraging Large Language Models for Multilingual Response
Large Language Models (LLMs) are increasingly integrated into automated translation workflows and crisis response systems due to their capacity for nuanced language processing. Traditional machine translation often struggled with idiomatic expressions and contextual ambiguities, resulting in inaccurate or unnatural outputs; LLMs mitigate these issues by analyzing text holistically, considering surrounding information to determine meaning and generate more fluent translations. In automated triage applications, LLMs assess incoming reports-such as those detailing disaster impacts or urgent needs-by interpreting the semantic content and identifying key indicators of severity. This enables prioritization of resources and facilitates a more efficient and effective response compared to rule-based or keyword-driven systems.
Recent Large Language Models, specifically NLLB-1.2B and X-ALMA, have demonstrated translation capabilities extending to previously underrepresented languages like Somali and Kinyarwanda. While both models achieve high-quality results, performance is not uniform across all languages; quantitative evaluation using spBLEU scores, detailed in Table 1, reveals differing strengths. NLLB-1.2B generally exhibits more consistent performance across a wider range of languages, whereas X-ALMA demonstrates superior translation quality specifically for Somali and Kinyarwanda, suggesting a specialized training focus or data representation advantage for those languages.
Leveraging Large Language Models (LLMs), automated triage systems analyze incoming crisis reports to determine severity and prioritize response efforts. These systems process textual data – such as reports from field teams or social media – identifying key indicators of urgent need, like reported casualties, infrastructure damage, or displacement numbers. LLMs enable the assessment of contextual information beyond keyword spotting, improving accuracy in differentiating critical incidents from routine reports. This allows organizations to allocate resources – personnel, supplies, and financial aid – more efficiently, focusing on the most pressing needs and reducing response times in emergency situations. The output of this triage process is typically a prioritized list of reports, categorized by severity level and requiring specific actions.
The Imperative of Rigorous Validation and Equitable Performance
The fidelity of translation proves critical in high-stakes scenarios, extending far beyond simple linguistic equivalence. Inaccurate translations aren’t merely a matter of miscommunication; they introduce the potential for profound consequences, ranging from delayed aid delivery to misdiagnosis and inappropriate treatment. The nuance of language, particularly in contexts like emergency response and healthcare, demands precision; a mistranslated symptom or instruction could irrevocably alter patient outcomes. Consequently, systems relying on multilingual communication must prioritize translation quality, employing rigorous validation processes and accounting for cultural sensitivities to prevent ambiguities that could jeopardize safety and effectiveness. The stakes are exceptionally high, demanding a level of accuracy that transcends automated processes and often requires human oversight to ensure clarity and prevent potentially life-threatening errors.
Rigorous multilingual assessment is crucial for crisis communication technologies, extending beyond simple translation accuracy to examine potential biases and ensure equitable performance across all supported languages. Disparities in effectiveness can arise not only from linguistic inaccuracies but also from cultural nuances or algorithmic biases embedded within the system, potentially leading to delayed or inappropriate responses for certain language groups. Thorough evaluation involves testing with diverse datasets representing various linguistic backgrounds and crisis scenarios, analyzing performance metrics for each language, and identifying any systematic differences in accuracy, speed, or clarity. This process helps developers mitigate biases, refine algorithms, and ultimately deliver crisis information that is equally accessible and impactful for all populations, regardless of their primary language.
The integration of automated translation technologies into healthcare, particularly during crisis situations demanding rapid triage, requires meticulous attention to detail beyond simple linguistic conversion. Recent studies demonstrate that both specialized translation systems and cutting-edge large language models struggle with the nuances of medical terminology and, critically, the accurate conveyance of urgency-a misstep that could have life-threatening consequences. Preserving the integrity of crucial patient information, including specific symptoms, medication details, and allergy alerts, is paramount, yet current systems often exhibit inaccuracies or omissions when processing crisis-related content. This highlights a critical need for robust evaluation metrics that assess not only translational accuracy but also the faithful preservation of vital clinical data and the emotional weight of emergency communications, ensuring equitable and effective healthcare delivery across linguistic barriers.
The pursuit of automated translation, particularly within the critical domain of crisis communication, reveals a fundamental challenge: preserving semantic integrity alongside nuanced urgency. The article demonstrates how current Large Language Models, while proficient in general translation, falter when conveying the gravity of time-sensitive information. This echoes Donald Davies’ observation that “Simplicity is a prerequisite for reliability.” The complexities inherent in natural language, compounded by the need for accurate urgency detection, demand a rigorous focus on foundational principles. Just as a mathematical proof requires unwavering precision, so too must crisis translation systems prioritize provable correctness over mere functional performance. Let N approach infinity – what remains invariant is the necessity for unambiguous communication when lives are at stake.
What’s Next?
The observed deficiencies in translating crisis-related content with preserved urgency are not merely practical setbacks; they represent a fundamental failure of current systems to grasp semantic precision. The notion that a statistically probable sequence of words constitutes ‘translation’ remains, demonstrably, an oversimplification. A rigorously defined formalization of ‘urgency’ – beyond ad-hoc heuristics – is paramount. Without a mathematically sound representation, any claim of ‘urgency detection’ is, at best, a computationally expensive approximation.
Future work must prioritize the development of crisis-specific benchmarks. Existing datasets, constructed for general language understanding, offer little insight into the nuances of time-sensitive communication. These benchmarks require not only lexical accuracy but also the preservation of temporal relationships and the correct signaling of critical information. The evaluation metrics themselves demand re-examination; BLEU scores and similar measures are inadequate proxies for conveying life-or-death instructions.
Ultimately, the problem transcends mere machine translation. It necessitates a deeper engagement with the cognitive processes underlying human communication in high-stress scenarios. Until systems can formally represent and reason about the intent behind a message – not just its surface form – the promise of truly effective cross-lingual crisis communication will remain elusive. The field requires, not incremental improvements, but a re-evaluation of its foundational principles.
Original article: https://arxiv.org/pdf/2602.13452.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- All Itzaland Animal Locations in Infinity Nikki
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- How to Get to the Undercoast in Esoteric Ebb
- A Dark Scream Theory Rewrites the Only Movie to Break the 2-Killer Rule
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- Crimson Desert: Disconnected Truth Puzzle Guide
- Gold Rate Forecast
- BloxStrike codes (March 2026)
2026-02-18 01:58