Author: Denis Avetisyan
New research reveals that artificial intelligence tools designed to detect cognitive impairment may unfairly underestimate the abilities of multilingual individuals in the UK.
A study of real-world speech data demonstrates potential biases in AI-powered cognitive assessments for multilingual English speakers with mild cognitive impairment.
Despite increasing reliance on artificial intelligence for early cognitive assessment, current tools may not accurately evaluate individuals from diverse linguistic backgrounds. This study-’Can we trust AI to detect healthy multilingual English speakers among the cognitively impaired cohort in the UK? An investigation using real-world conversational speech’-investigated potential biases in AI models designed to detect cognitive decline, focusing on the performance differences between monolingual and multilingual speakers in the UK. Results revealed that while automatic speech recognition systems showed no significant bias, classification and regression models exhibited a tendency to misclassify healthy multilingual individuals as cognitively impaired, particularly those with South Yorkshire accents. This raises critical questions about the generalizability and equitable application of AI-driven cognitive assessments in increasingly diverse populations.
The Growing Imperative of Early Cognitive Assessment
The rising prevalence of cognitive decline presents a growing public health concern, impacting individuals and healthcare systems alike. While conditions like Alzheimer’s disease and other dementias are becoming more common due to aging populations, the ability to identify these changes in their earliest stages remains a substantial challenge. This difficulty stems from the often subtle nature of initial symptoms, which can be easily mistaken for normal age-related changes or other health issues. Consequently, many individuals do not receive a diagnosis until the condition has progressed, limiting opportunities for timely intervention and potentially effective management strategies. Addressing this gap in early detection is crucial not only for improving patient outcomes but also for reducing the long-term burden of cognitive impairment on both individuals and society.
Comprehensive cognitive assessments traditionally rely on neuropsychological testing and specialist evaluations, processes that present substantial barriers to widespread early detection. These methods frequently involve significant financial costs, requiring trained personnel, specialized equipment, and considerable time commitments from both clinicians and patients. Consequently, access is often limited, disproportionately affecting vulnerable populations – including those in rural areas, with lower socioeconomic status, or facing linguistic or cultural barriers. This inequity delays diagnosis, hindering timely intervention and exacerbating the impact of cognitive decline on individuals and healthcare systems. The logistical complexities and expense associated with conventional assessments underscore the urgent need for more affordable, accessible, and scalable diagnostic tools to address this growing public health challenge.
The progression of cognitive decline is often insidious, and consequential delays in accurate diagnosis significantly diminish the potential benefits of available interventions. While pharmacological and non-pharmacological strategies exist to manage symptoms and potentially slow disease progression, their effectiveness is demonstrably higher when implemented in the early stages. Later diagnoses often mean that irreversible neurological damage has already occurred, limiting the capacity for these interventions to meaningfully improve outcomes. This delay not only impacts an individual’s cognitive function, but also extends to their emotional wellbeing, social engagement, and overall quality of life, placing increased strain on both the individual and their support networks. Timely identification of cognitive changes, therefore, is paramount to maximizing therapeutic opportunities and preserving a person’s independence and dignity for as long as possible.
Automated speech recognition (ASR) technologies are increasingly explored for cognitive assessment, but inherent limitations in transcription accuracy pose a critical challenge. Recent evaluations of prominent ASR models – Whisper, Wav2Vec 2.0, and NeMo – reveal a Word Error Rate (WER) ranging from 0.40 to 0.57. This means that, on average, between 40 to 57 out of every 100 words are incorrectly transcribed. While seemingly small, these errors could significantly distort linguistic analysis used to detect subtle cognitive changes, potentially leading to misdiagnosis or delayed intervention. The implications are particularly concerning when assessing nuanced speech patterns, as even minor transcription inaccuracies can obscure crucial indicators of cognitive function, necessitating careful consideration of error mitigation strategies and validation protocols when deploying these technologies in clinical settings.
CognoMemory: A Platform for Proactive Screening
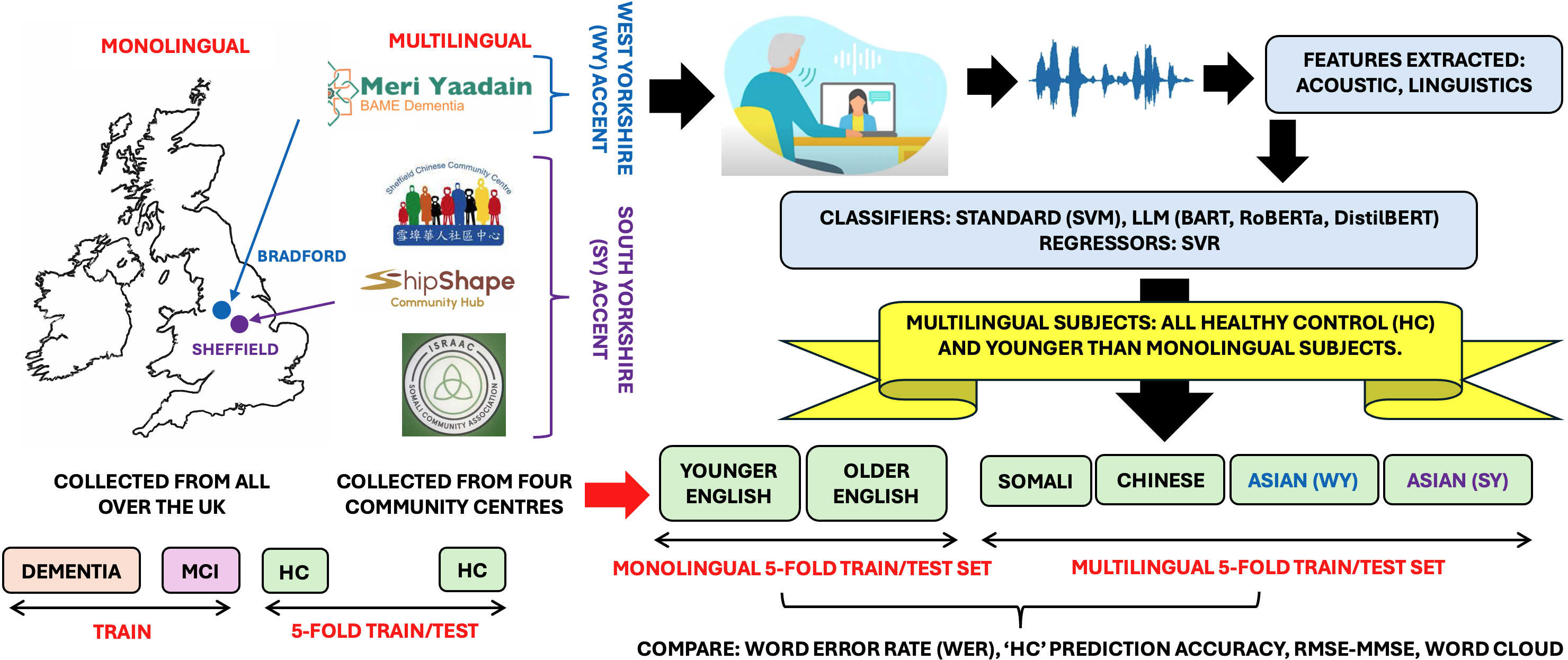
CognoMemory is a remotely accessible, web-based platform intended for the initial screening of individuals for cognitive impairment. The tool functions by collecting speech samples from users and subjecting these recordings to automated analysis. Unlike traditional cognitive assessments which often require in-person clinical visits and standardized testing protocols, CognoMemory aims to provide a convenient and scalable method for identifying potential cognitive decline. The platform is designed to be used as a preliminary screening tool and is not intended to provide a diagnosis; positive screenings would necessitate further evaluation by qualified healthcare professionals. Data collected through CognoMemory is intended to support early detection and intervention strategies for conditions such as Alzheimer’s disease and other forms of dementia.
The CognoMemory platform utilizes Automatic Speech Recognition (ASR) technology to convert spoken language into text, enabling the quantitative analysis of cognitive indicators. This process yields two primary data types: Acoustic Features, which analyze properties of the speech signal itself – such as pitch, intensity, and articulation rate – and Linguistic Features, derived from the transcribed text, including measures of vocabulary, syntax, and semantic complexity. These features are then extracted and used as quantifiable biomarkers, allowing for computational assessment of cognitive function based on speech patterns. The combined analysis of both acoustic and linguistic data aims to provide a comprehensive and sensitive evaluation of an individual’s cognitive state.
Acoustic and linguistic features extracted from speech analysis provide objective, quantifiable measures correlated with cognitive function. Traditional cognitive screening relies heavily on subjective assessments and performance-based tasks, which can be influenced by factors like education, motivation, and cultural background. In contrast, CognoMemory’s feature extraction focuses on characteristics inherent in speech production – such as prosody, articulation rate, and lexical diversity – that demonstrably change with cognitive decline. These features offer a non-invasive method of assessment, requiring only a short audio recording, and preliminary data suggests they may detect subtle changes indicative of cognitive impairment earlier than conventional methods, potentially improving the sensitivity of screening procedures.
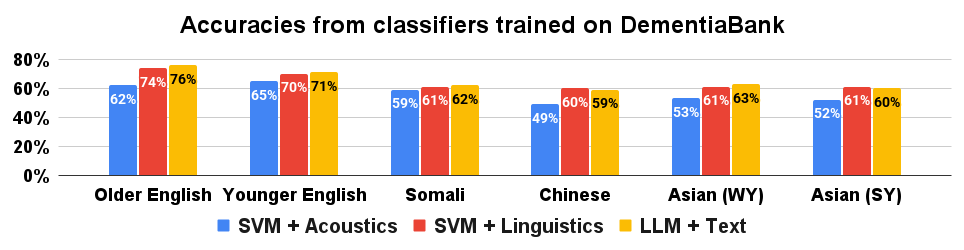
Initial evaluations of the CognoMemory screening tool utilized Support Vector Machine (SVM) classifiers to assess the discriminatory power of acoustic and linguistic features derived from speech samples. Results indicate an accuracy of 0.67±0.09 when utilizing solely acoustic features, and 0.71±0.19 with linguistic features. The reported accuracies represent the mean accuracy across testing folds, with the ± value denoting the standard deviation. These preliminary findings suggest that both feature types offer viable signals for cognitive assessment, and further investigation into combined feature sets may yield improved classification performance.
Addressing Disparities in Cognitive Assessment: A Critical Imperative
Epidemiological data consistently demonstrate that ethnic minority populations exhibit a higher prevalence of dementia compared to their White counterparts. This disparity is compounded by significant barriers to accessing diagnostic services, including geographical limitations, socioeconomic factors, language barriers, and a lack of culturally competent healthcare providers. These barriers result in delayed diagnoses, reduced access to appropriate care, and ultimately, poorer health outcomes for these vulnerable populations. Furthermore, existing diagnostic tools are often normed on predominantly White, monolingual populations, potentially leading to misdiagnosis or underdiagnosis in individuals from diverse backgrounds.
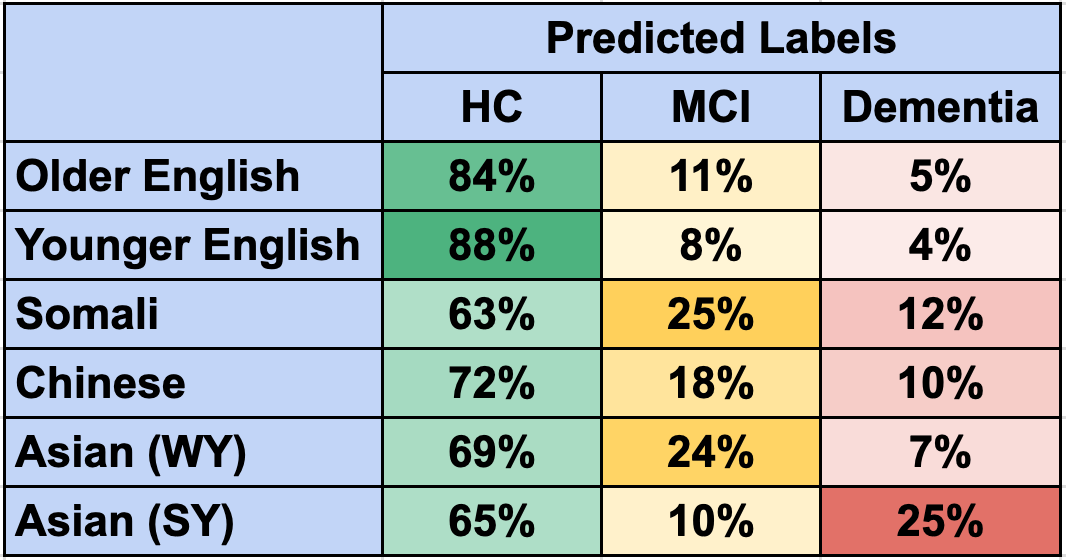
The prevalence of multilingualism within ethnic minority populations presents a significant challenge to the accurate interpretation of standard cognitive assessments. These assessments are frequently normed on monolingual individuals and rely heavily on language-based tasks, potentially underestimating cognitive abilities in those proficient in multiple languages. Differences in linguistic patterns, vocabulary access, and code-switching can all influence performance on these tests, leading to misdiagnosis or delayed diagnosis of cognitive impairment. Consequently, relying solely on traditional language assessments may not provide a valid measure of underlying cognitive function for individuals with diverse linguistic backgrounds, necessitating the development and implementation of culturally and linguistically sensitive evaluation methods.
CognoMemory employs a linguistic analysis technique that assesses language skills by evaluating patterns of word usage, specifically utilizing Term Frequency-Inverse Document Frequency (TF-IDF) to determine the importance of individual words within a subject’s speech or writing. This approach moves beyond simple vocabulary counts by weighting words based on their frequency within the sample and rarity across a larger corpus, allowing for a more nuanced understanding of cognitive function. The system’s design intends to account for variations in language expression, potentially mitigating the impact of differing linguistic backgrounds, and offering a more sensitive measure of cognitive ability even in multilingual individuals, though current validation data indicates performance disparities exist between monolingual and multilingual speakers.
Rigorous validation of cognitive assessment tools, such as utilizing the DementiaBank dataset which incorporates data from individuals with Mild Cognitive Impairment (MCI), is essential for establishing performance across varied populations. However, analysis demonstrates a significant performance disparity; accuracy on DementiaBank is reported at 0.70±0.05 for monolingual speakers, but decreases to 0.58±0.04 for multilingual speakers. This difference indicates a measurable bias within the assessment tool, suggesting that its ability to accurately evaluate cognitive function is compromised when applied to individuals with multilingual backgrounds.
Statistical analysis of CognoMemory’s performance reveals a significant disparity in accuracy between monolingual and multilingual speakers (p<0.01). This indicates a systematic bias within the current model, where its ability to accurately assess cognitive function is notably diminished when applied to individuals with multilingual backgrounds. The observed difference is statistically significant, meaning it is unlikely due to random chance, and necessitates further refinement of the assessment algorithms to ensure equitable performance across all linguistic groups. Addressing this bias is critical for providing fair and reliable cognitive assessments for a diverse population.

Towards Proactive Cognitive Healthcare: A Vision for the Future
The potential for proactive cognitive healthcare hinges on the ability to identify subtle changes indicative of decline long before noticeable symptoms emerge. Tools like CognoMemory offer a pathway to this early detection, enabling timely interventions – such as lifestyle adjustments, targeted therapies, or increased cognitive stimulation – that may demonstrably slow disease progression. This is particularly crucial given that many neurodegenerative conditions begin impacting the brain years, even decades, before clinical diagnosis. By facilitating earlier access to care, platforms designed for continuous cognitive assessment not only address the underlying pathology but also empower individuals to maintain independence, quality of life, and active engagement within their communities for a longer duration.
CognoMemory’s design prioritizes widespread implementation, making it uniquely suited for both clinical and community settings. The platform is intentionally engineered to be easily integrated into existing healthcare workflows, requiring minimal specialized training for administrators or clinicians. Its digital format also allows for broad distribution via telehealth platforms and mobile devices, significantly expanding access beyond traditional brick-and-mortar facilities. This scalability is particularly beneficial for reaching underserved populations and facilitating preventative care initiatives within community outreach programs, ultimately enabling earlier detection and intervention for a wider range of individuals at risk of cognitive decline.
The wealth of linguistic and acoustic data generated by CognoMemory holds significant promise for unraveling the complexities of cognitive decline. By analyzing subtle patterns in speech – beyond easily identifiable errors – researchers can pinpoint biomarkers indicative of early-stage neurodegenerative processes. These biomarkers, detectable through machine learning algorithms applied to the collected data, may precede traditional clinical symptoms, offering a window for intervention. This detailed analysis isn’t limited to what is said, but how it’s said, examining features like prosody, articulation rate, and pauses. Ultimately, a refined understanding of these biomarkers could lead to the development of targeted therapies and more effective diagnostic tools, shifting the focus from reactive treatment to proactive cognitive healthcare.
The subtle shifts in speech and language – alterations in vocabulary, grammar, or the rhythm of communication – are increasingly recognized as early warning signals of underlying cognitive change. This understanding fuels the development of preventative cognitive care strategies, exemplified by tools capable of detecting these impairments long before traditional clinical symptoms manifest. By analyzing linguistic patterns and acoustic features within natural speech, these platforms offer a non-invasive means of identifying individuals at risk of cognitive decline, allowing for timely interventions focused on lifestyle adjustments, targeted therapies, or further diagnostic evaluation. This proactive approach represents a paradigm shift, moving beyond reactive treatment of diagnosed conditions towards maintaining cognitive health and maximizing quality of life through early detection and personalized care.
The study highlights a critical intersection of system design and real-world impact, echoing Tim Berners-Lee’s sentiment: “The Web is more a social creation than a technical one.” Just as the web’s structure shapes its utility, so too do the underlying algorithms of AI-driven cognitive assessments dictate their accuracy. This investigation into potential biases affecting multilingual speakers reveals that a system’s perceived objectivity is only as sound as the data and design principles informing it. Failing to account for the nuances of linguistic diversity introduces structural flaws, potentially leading to misdiagnosis and impacting the well-being of a vulnerable cohort. The research emphasizes the need for holistic design, recognizing that every component-here, linguistic background-resonates throughout the entire system.
The Road Ahead
The findings suggest a precarious reliance on systems built on convenience, rather than cognitive principle. If the current generation of speech analysis tools misinterprets the linguistic patterns of a significant demographic – multilingual speakers – then the edifice of automated cognitive assessment rests on a foundation of assumption. The study does not merely reveal a technical glitch; it highlights a category error. Treating linguistic diversity as noise, rather than information, is akin to diagnosing a shadow instead of the object casting it.
Future work must move beyond simply ‘fixing’ the algorithms. Modularity, in this context, offers a comforting illusion of control. A more profound approach requires understanding how cognitive architecture inherently manifests in speech, irrespective of linguistic background. The challenge is not to eliminate difference, but to model its influence. If the system survives on duct tape – patching biases with ever-finer calibrations – it’s probably overengineered and fundamentally flawed.
Ultimately, the field needs to confront a difficult truth: a ‘general’ cognitive assessment may be a chimera. The brain is not a monolithic processor. Instead, it’s a complex, adaptive system shaped by experience, and increasingly, by the very tools used to measure it. The pursuit of objective assessment risks creating the very subjectivity it seeks to avoid.
Original article: https://arxiv.org/pdf/2602.13047.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- All Itzaland Animal Locations in Infinity Nikki
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- How to Get to the Undercoast in Esoteric Ebb
- Crimson Desert: Disconnected Truth Puzzle Guide
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- Superman/Spider-Man #1 Review: Bigger DC-Marvel Crossovers Teased
- Gold Rate Forecast
- A Dark Scream Theory Rewrites the Only Movie to Break the 2-Killer Rule
2026-02-16 12:29