Author: Denis Avetisyan
A new approach dynamically adjusts training to prioritize challenging examples from underrepresented classes, improving performance on imbalanced datasets.
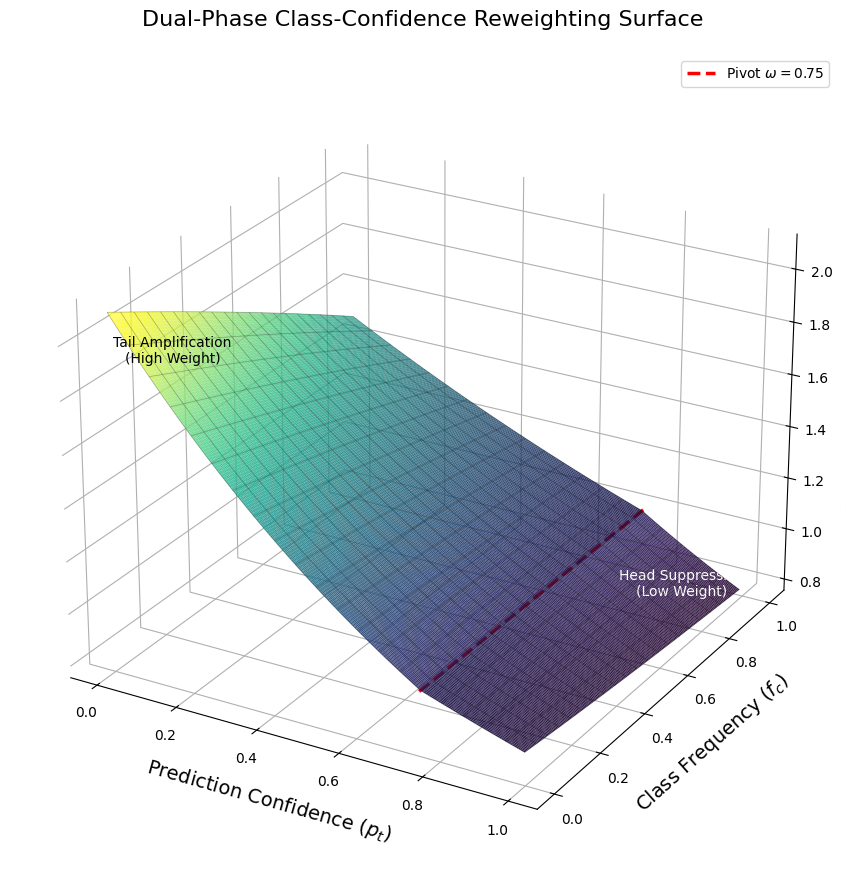
This paper introduces a gradient reweighting strategy that combines class frequency with prediction confidence to optimize learning in long-tailed distributions.
Deep neural networks struggle with imbalanced datasets where a few classes dominate, hindering performance on rare but important categories. This limitation motivates the work ‘Class Confidence Aware Reweighting for Long Tailed Learning’, which introduces a novel re-weighting scheme that adaptively modulates training gradients based on both class frequency and the confidence of individual predictions. By focusing optimization on challenging examples from under-represented classes, this approach demonstrably improves performance on long-tailed benchmarks like CIFAR-100-LT and ImageNet-LT. Could this confidence-aware reweighting strategy offer a broadly applicable solution for effectively learning from imbalanced data across diverse deep learning applications?
The Inevitable Skew: Why Imbalance Dooms Most Models
The prevalence of class imbalance represents a substantial challenge in modern data science, arising when the distribution of classes within a dataset is heavily skewed. This commonly manifests as a scenario where a small number of classes account for the vast majority of instances, while others are represented by only a few examples – a phenomenon increasingly observed across diverse fields like fraud detection, medical diagnosis, and anomaly detection. For instance, in a credit card fraud dataset, legitimate transactions typically far outnumber fraudulent ones, creating a significant imbalance. This skewed distribution isn’t merely a statistical quirk; it fundamentally impacts the ability of machine learning algorithms to learn effectively, as models tend to prioritize the dominant classes and overlook the rarer, yet potentially critical, minority classes. Consequently, a model trained on such data might achieve high overall accuracy by simply predicting the majority class most of the time, failing to identify the instances that require focused attention.
The prevalence of class imbalance in datasets directly manifests as predictive bias, where machine learning models consistently underperform on less frequent classes. This occurs because algorithms are naturally optimized to maximize overall accuracy, and thus prioritize the dominant classes during training – effectively learning to ignore the nuanced patterns within the minority classes. Consequently, a model might achieve high accuracy by correctly classifying the majority, while failing to recognize critical instances belonging to the under-represented groups. This diminished performance isn’t merely a technical limitation; it introduces significant fairness concerns, especially in applications like fraud detection, medical diagnosis, or loan approvals, where accurate identification of minority class instances is crucial to avoid discriminatory outcomes and ensure equitable treatment. Addressing this bias is therefore not simply about improving algorithmic performance, but about building responsible and trustworthy artificial intelligence systems.
Conventional machine learning algorithms are typically designed with the assumption of balanced class distribution, leading to suboptimal performance when confronted with imbalanced datasets. These algorithms prioritize overall accuracy, often achieving high scores by correctly classifying the majority class while largely ignoring the minority class-a phenomenon known as the “majority class dominance” effect. Consequently, predictive models exhibit a strong bias towards the prevalent classes, resulting in poor recall and precision for the under-represented classes. To address this, specialized techniques such as oversampling minority class instances, undersampling majority class instances, or employing cost-sensitive learning algorithms are crucial. These methods aim to re-balance the dataset or modify the learning process to give greater weight to the minority classes, thereby improving the model’s ability to generalize and accurately predict instances from all classes, even those with limited representation.
CCAR: A Pragmatic Attempt to Wrest Control From the Majority
CCAR, or Class-aware Confidence-based Adaptive Resampling, is a training methodology designed to refine optimization at the individual sample level. This is achieved by dynamically weighting each sample’s contribution to the loss function based on two primary factors: the frequency of its associated class within the training dataset and the prediction confidence assigned to that sample by the model. Specifically, CCAR addresses class imbalance by up-weighting samples from minority classes, while simultaneously down-weighting easily classified, high-confidence samples. This modulation of sample weights aims to focus optimization efforts on informative examples – those that are both rare and difficult to classify – ultimately enhancing model generalization performance.
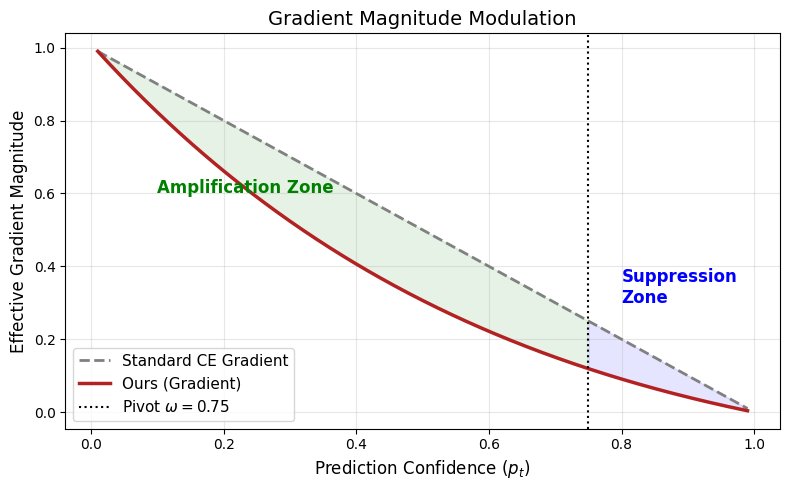
CCAR employs the Maximum Entropy Principle to establish a weighting function for individual samples during training. This function is derived by maximizing entropy subject to constraints based on both the observed class frequencies and the model’s prediction confidence for each sample. Specifically, the weighting assigned to a sample is inversely proportional to its predicted probability and directly proportional to the inverse of its class frequency; this ensures that infrequent classes and difficult examples – those with low confidence scores – receive greater emphasis during optimization. The resulting weighting scheme, formalized as w_i = \frac{1}{p_i \cdot f(y_i)}, where w_i is the weight for sample i, p_i is the model’s prediction confidence, and f(y_i) represents the frequency of the true class label, dynamically adjusts sample contributions without requiring manual hyperparameter tuning.
CCAR improves model generalization by dynamically weighting training samples based on prediction confidence. Samples with low confidence, identified as ‘hard examples’, receive increased weight in the loss function, forcing the model to focus on more challenging cases. Conversely, easily classified samples with high prediction confidence are down-weighted, reducing their influence on parameter updates. This approach prevents the model from being overly influenced by simple examples and promotes learning from informative, difficult cases. Empirical results on the ImageNet-LT dataset demonstrate that CCAR achieves an accuracy gain of up to 4.02% compared to standard training procedures, indicating a significant improvement in performance on long-tailed distributions.
Validation: Does It Actually Work? (Surprisingly, Yes)
CCAR was subjected to comprehensive evaluation utilizing three established long-tailed datasets: ImageNet-LT, CIFAR-100-LT, and iNaturalist2018. ImageNet-LT consists of a highly imbalanced distribution of images across 1000 classes, while CIFAR-100-LT presents a long-tailed distribution within its 100 classes, specifically with an imbalance factor (IF) of 200 used for testing. iNaturalist2018, a more complex dataset, comprises images from a broader range of 8142 species, providing a realistic challenge for evaluating performance on naturally occurring imbalanced data. These datasets were selected to provide a robust assessment of CCAR’s capabilities in scenarios where class frequencies are significantly uneven.
Comparative evaluation of CCAR against established techniques – Balanced Softmax, Loss Re-weighting, and Logit-Level Adjustment – demonstrates consistent performance gains on the ImageNet-LT dataset. Specifically, CCAR achieved a Top-1 Accuracy of 45.62% on ImageNet-LT, indicating a measurable improvement over the performance of these existing methods when applied to long-tailed distributions. This result establishes CCAR as an effective approach for addressing the challenges presented by imbalanced datasets in image classification tasks.
Quantitative evaluation of CCAR on long-tailed datasets demonstrates performance gains over baseline methods. On the CIFAR-100-LT dataset, with an imbalance factor (IF) of 200, CCAR achieved a Top-1 Accuracy of 46.20%, representing a 2.9% improvement over the baseline. Furthermore, on the iNaturalist2018 dataset, CCAR attained a Top-1 Accuracy of 70.10%, exceeding the baseline performance by 0.3%.
The Long View: A Step Towards More Robust, Less Naive AI
Class imbalance-where some categories within a dataset are significantly rarer than others-presents a substantial challenge to machine learning algorithms. Conventional methods often prioritize overall accuracy, leading to poor performance on minority classes. The Cost-sensitive Class Adjustment with Re-weighting (CCAR) framework addresses this by dynamically adjusting class weights during training, effectively increasing the influence of under-represented classes without requiring extensive hyperparameter tuning. This principled approach isn’t limited to image classification; the core mechanism of re-weighting based on class frequency and loss characteristics can be readily adapted to diverse machine learning tasks. Applications extend to fields like object detection, where identifying rare objects is crucial, and natural language processing, where certain entities or sentiments may be sparsely represented in text corpora, offering a broadly applicable solution for improving model generalization and fairness across all classes.
The core of the Cost-sensitive Class-Aware Re-weighting (CCAR) method extends beyond image classification due to its adaptable dynamic weighting scheme. This technique, which adjusts sample weights during training to address class imbalance, isn’t limited to pixel-based data; it can be readily integrated into tasks involving diverse data types and model architectures. For example, in object detection, weights can be assigned to bounding box proposals based on the rarity of the detected object, improving performance on uncommon classes. Similarly, within natural language processing, the weighting scheme can prioritize less frequent words or phrases during model training, boosting performance on tasks like sentiment analysis or named entity recognition where minority classes often hold significant meaning. This flexibility positions CCAR as a versatile tool for mitigating the challenges of imbalanced datasets across a broad spectrum of machine learning applications.
Rigorous evaluation demonstrates the substantial performance gains achieved by combining Cost-sensitive Class Adjustment with Logit Adjustment. Specifically, this combined approach attains a Top-1 Accuracy of 52.76% on the challenging ImageNet-LT dataset and 48.91% on CIFAR-100-LT (with an imbalance factor of 100), representing a significant advancement in handling long-tailed distributions. These results underscore the method’s effectiveness not simply as a theoretical construct, but as a practical solution capable of achieving state-of-the-art accuracy even when faced with severely imbalanced data – a common issue in real-world applications ranging from medical diagnosis to fraud detection.
The pursuit of elegant solutions in long-tailed learning feels…familiar. This paper’s confidence-aware reweighting, while clever, simply adds another layer of complexity to an already convoluted problem. It’s a gradient weighting scheme, naturally. They attempt to address the imbalance by focusing on ‘hard examples’ – as if the production data won’t immediately discover new, equally challenging edge cases. One suspects the initial gains will erode quickly as the model encounters unforeseen distributions. As Andrew Ng once said, ‘Simplicity is key.’ The researchers chase better performance on benchmark datasets, but history suggests that each refined loss function is merely a temporary reprieve before the inevitable accumulation of technical debt. It’s not a bad idea, just…predictable.
What’s Next?
The presented gradient modulation offers another degree of freedom in the ongoing struggle against long-tailed distributions. It addresses symptom management-boosting performance on rare classes-but the underlying pathology remains. The field continues to refine loss functions as if a better weighting scheme will fundamentally alter the fact that most deep learning models are exquisitely optimized for the majority class. The inevitable consequence will be a new set of failure modes, exposed by increasingly complex datasets.
Future work will undoubtedly explore adaptive confidence thresholds and more sophisticated methods for estimating ‘hardness.’ However, a critical question remains largely unaddressed: at what point does increasingly granular control over the optimization process yield diminishing returns? The pursuit of elegant solutions often obscures the simple truth – data augmentation and active learning, while less theoretically satisfying, frequently deliver more robust improvements.
The current trajectory suggests a continued emphasis on algorithmic complexity. It is a reasonable expectation that the next iteration will involve yet another layer of meta-learning or self-supervision. The field should perhaps consider a shift in focus. It does not need more microservices-it needs fewer illusions about the inherent limitations of learning from imbalanced data.
Original article: https://arxiv.org/pdf/2601.15924.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- Gold Rate Forecast
- All Itzaland Animal Locations in Infinity Nikki
- A Dark Scream Theory Rewrites the Only Movie to Break the 2-Killer Rule
- How to Get to the Undercoast in Esoteric Ebb
- 8 Actors Who Could Play Blackbeard In One Piece Live-Action Season 3
- Australia’s New Crypto Law: Can They Really Catch the Bad Guys? 😂
- Fire Force Season 3 Part 2 Episode 24 Release Date, Time, Where to Watch
2026-01-25 08:35