Author: Denis Avetisyan
A new framework empowers artificial intelligence to learn more efficiently by retrospectively analyzing past experiences and assigning credit where it’s due.
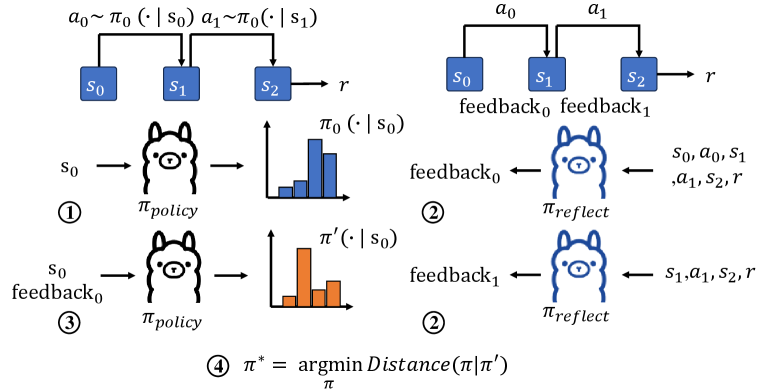
Researchers introduce RICOL, a reinforcement learning method leveraging large language models and in-context learning for improved temporal credit assignment and sample efficiency.
Efficiently learning from sparse rewards remains a central challenge in reinforcement learning, often hindered by difficulties in assigning credit for delayed actions. This paper, ‘Retrospective In-Context Learning for Temporal Credit Assignment with Large Language Models’, introduces a novel framework, RICOL, that leverages the knowledge embedded within large language models to transform these sparse signals into dense, actionable feedback. By employing retrospective in-context learning, RICOL accurately estimates advantage functions and identifies critical states with significantly improved sample efficiency compared to traditional online reinforcement learning algorithms. Could this approach unlock more generalizable and data-efficient RL paradigms, paving the way for agents that learn more like humans?
The Challenge of Sparse Rewards: A Fundamental Obstacle
Many reinforcement learning systems struggle when faced with environments that offer only infrequent rewards, a phenomenon known as sparse rewards. This poses a significant challenge because agents rely on feedback to understand which actions contribute to success; without consistent signals, it becomes incredibly difficult to discern effective strategies. Imagine an agent tasked with navigating a complex maze where a reward is only given upon reaching the exit – most exploratory actions yield no immediate feedback, leaving the agent to wander aimlessly. Consequently, algorithms designed for dense reward environments often fail to learn in these sparse scenarios, requiring specialized techniques to facilitate exploration and credit assignment over extended periods of time. The difficulty isn’t necessarily the complexity of the task, but rather the lack of guidance during the learning process, hindering the development of robust and effective policies.
A fundamental challenge in reinforcement learning arises when agents must navigate complex sequences of actions to achieve a distant reward; traditional methods often falter in these scenarios due to difficulties in credit assignment. These algorithms typically rely on immediate or short-term feedback, struggling to accurately determine which actions, taken many steps prior, ultimately contributed to a positive outcome. This limitation is particularly pronounced in sparse reward environments where feedback is infrequent, creating a significant delay between action and consequence. Consequently, the agent may fail to reinforce beneficial behaviors initiated earlier in the sequence, leading to slow learning or even complete failure to acquire an effective policy. The inability to bridge this temporal gap effectively restricts the agent’s capacity to learn from extended interactions and master intricate tasks requiring long-term planning.
Successfully navigating complex environments hinges on an agent’s ability to discern which actions, potentially taken many steps prior, ultimately led to a positive outcome-a process known as credit assignment. The challenge intensifies when rewards are delayed or infrequent, requiring the agent to effectively trace the impact of each action across extended sequences. Algorithms must move beyond simply reinforcing the immediately preceding step and instead build a comprehensive understanding of how earlier decisions shaped the final result. This demands sophisticated techniques capable of propagating information backwards through time, accurately weighting the contribution of each action to the overall trajectory, and ultimately guiding the agent towards more effective long-term strategies. Without this capability, agents remain trapped in local optima, unable to unlock the full potential of complex, sequential tasks.
RICL: An LLM-Based Solution for Advantage Estimation
Retrospective In-Context Learning (RICL) utilizes large language models (LLMs) to directly estimate advantage functions, a core component of reinforcement learning. Instead of training a separate value function approximator, RICL frames advantage estimation as an in-context learning problem for the LLM. The LLM is prompted with a sequence of past trajectories – states, actions, and rewards – and then tasked with predicting the advantage associated with subsequent actions. This allows the model to learn a contextual understanding of action values without explicit gradient updates to a value function, offering a potentially more efficient and accurate method for credit assignment in complex environments. The advantage, A(s,a) = Q(s,a) - V(s), represents the relative benefit of taking action a in state s compared to the average value of being in state s.
Retrospective In-Context Learning (RICL) utilizes the capability of large language models to evaluate action quality by providing the LLM with sequential data representing past agent interactions, or trajectories. Specifically, the LLM is conditioned on a history of states, actions, and resulting rewards, allowing it to predict the expected cumulative reward, or advantage, of subsequent actions within that specific context. This conditioning process enables the LLM to learn a context-dependent value assessment without explicit training on a value function; instead, the LLM infers the value of an action based on the patterns and relationships observed within the provided trajectory data. The advantage estimation is therefore directly derived from the LLM’s understanding of the sequential data, capturing complex dependencies and contextual nuances that may be missed by traditional methods.
Traditional reinforcement learning algorithms rely on value function approximation to estimate the long-term reward associated with specific states or state-action pairs; however, these approximations introduce error and can hinder effective credit assignment. Retrospective In-Context Learning (RICL) circumvents this requirement by directly leveraging the predictive capabilities of large language models. Rather than learning a separate value function, RICL conditions the LLM on complete trajectory data, enabling it to assess the relative value of actions based on observed sequences of states and rewards. This approach allows for a more nuanced and potentially more accurate evaluation of action effectiveness, as the LLM can implicitly consider complex dependencies and contextual information present within the trajectory, thereby improving credit assignment without the limitations of parametric function approximation.
The LLM Reflector component is central to the RICL framework, functioning as a feedback mechanism for observed trajectories. It receives as input a sequence of state-action pairs representing a completed or partial trajectory and outputs a scalar reward signal. This reward is not pre-defined but is generated by the LLM based on its learned understanding of optimal behavior within the given environment. The Reflector’s output serves as the immediate reward used for policy gradient updates, effectively providing an intrinsic signal for reinforcement learning without requiring externally specified reward functions. The LLM Reflector’s parameters are fixed during training, ensuring a consistent evaluation of trajectories and isolating the learning process to the policy network.
RICOL: Online Policy Learning with LLM Feedback
Retrospective In-Context Online Learning (RICOL) builds upon the foundation of Retrospective In-Context Learning (RICL) by integrating techniques for online policy improvement. While RICL focuses on leveraging LLM feedback on past experiences, RICOL actively utilizes this feedback to refine the agent’s policy during interaction with the environment. This is achieved by treating the LLM as a ‘reflector’ providing insights into observed trajectories, which are then used to guide incremental adjustments to the policy without requiring full model retraining. The combination enables continuous learning and adaptation, allowing the agent to improve its performance based on real-time experience and LLM-provided critiques.
The RICOL framework employs a fixed Large Language Model (LLM) policy, meaning the core weights of the LLM are not updated during the learning process. Instead, policy refinement occurs through feedback generated by the LLM Reflector, which analyzes observed trajectories-sequences of states, actions, and rewards. This feedback, typically in the form of preference labels or direct policy suggestions, is then used to adjust the policy’s action selection probabilities without modifying the underlying LLM. This approach decouples policy improvement from full model retraining, enabling more efficient and targeted updates based on experience.
The RICOL framework achieves efficient policy updates by leveraging feedback from the LLM Reflector to refine a fixed actor LLM policy, rather than necessitating complete retraining of the model’s parameters. This approach minimizes computational cost and time; policy improvements are implemented through adjustments informed by the LLM’s evaluation of observed trajectories. Consequently, the actor LLM retains its pre-existing knowledge base while benefiting from targeted refinements, resulting in a faster adaptation to new tasks or environments without the resource demands of full-scale retraining procedures.
KL-Regularization is implemented within the RICOL framework to maintain policy stability during online learning. This technique adds a penalty term to the policy update step, proportional to the Kullback-Leibler (KL) divergence between the new and old policies. The KL divergence, D_{KL}(π_{θ}(a|s) || π_{θ_{old}}(a|s)), measures the information lost when using the new policy π_{θ}(a|s) to approximate the old policy π_{θ_{old}}(a|s). By constraining the magnitude of policy updates via this penalty, RICOL prevents the actor LLM from making excessively large changes based on limited feedback, thereby improving learning stability and preventing performance degradation.
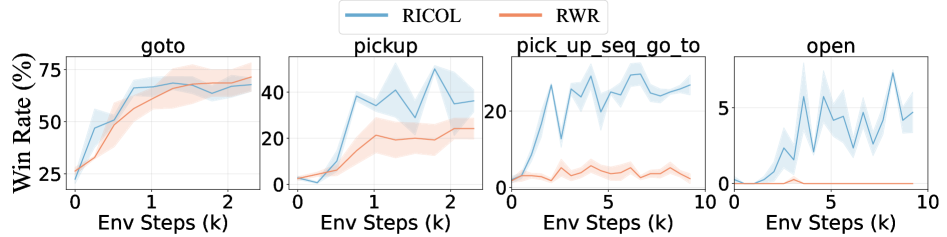
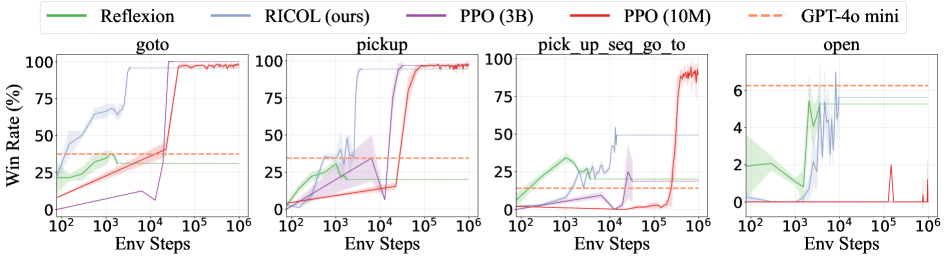
Evaluations of the Retrospective In-Context Online Learning (RICOL) framework in BabyAI environments demonstrate a significant improvement in sample efficiency. Specifically, RICOL achieves a 100x increase in sample efficiency when compared to a baseline Proximal Policy Optimization (PPO) implementation utilizing a 3 billion parameter model (3B) . This result indicates that RICOL requires substantially fewer interactions with the environment to achieve comparable or superior performance to traditional reinforcement learning algorithms, highlighting its potential for applications where data collection is expensive or time-consuming.
Towards Generalizable and Efficient RL Agents
Recent advances in reinforcement learning often struggle when rewards are infrequent, a common obstacle in complex environments. The RICOL framework proposes a solution by integrating large language models (LLMs) to guide the learning process, even when positive reinforcement is sparse. This approach leverages the LLM’s pre-existing knowledge and reasoning abilities to interpret agent states and generate informative prompts, effectively providing an internal reward signal where external rewards are lacking. Consequently, the agent can explore more efficiently and discover successful strategies without relying solely on trial-and-error in challenging scenarios, demonstrating a significant step towards more robust and adaptable artificial intelligence.
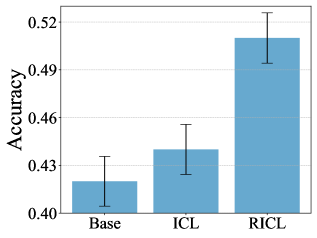
A significant hurdle in reinforcement learning is the substantial amount of trial-and-error required for an agent to learn, especially when rewards are infrequent. This framework addresses this challenge by prioritizing in-context learning, a technique where the agent learns from a few demonstrated examples provided within the current context, rather than relying on massive datasets or prolonged training periods. This approach dramatically reduces the need for extensive data collection, as the agent can rapidly adapt and generalize from limited information. By leveraging the power of large language models to understand and interpret these examples, the framework enables faster learning and improved performance, particularly in complex environments where obtaining labeled data is costly or impractical. This streamlined process represents a crucial step towards building reinforcement learning agents that are both efficient and readily deployable in real-world applications.
The development of reinforcement learning agents capable of thriving in unpredictable, real-world environments remains a significant challenge, often hampered by the need for extensive training data and limited generalization abilities. Recent advances suggest a pathway towards overcoming these hurdles by focusing on approaches that prioritize efficiency and adaptability. This involves leveraging the power of large language models to guide the learning process, enabling agents to rapidly acquire skills and apply them to novel situations without requiring massive datasets. Ultimately, this line of research aims to create agents that are not merely proficient in specific tasks, but possess a broader capacity for problem-solving and can effectively navigate the complexities inherent in dynamic, real-world scenarios – representing a crucial step towards truly intelligent and versatile artificial intelligence.
The integration of the Retroformer architecture significantly bolsters the prompt generation capabilities within the reflector component of the RICOL framework. This enhancement stems from the Retroformer’s unique ability to retain and leverage information from a long-context history, allowing it to craft prompts that are not only relevant to the current state of the reinforcement learning environment, but also informed by a deeper understanding of past interactions. Consequently, the reflector can formulate more insightful and nuanced prompts, guiding the language model towards more effective exploration and exploitation strategies, particularly crucial when dealing with sparse reward scenarios where immediate feedback is limited. This refined prompting process unlocks a pathway to more efficient learning and improved generalization capabilities for the resulting agent.

The pursuit of efficient reinforcement learning, as detailed in this work, echoes a sentiment held by G. H. Hardy: “A mathematician, like a painter or a poet, is a maker of patterns.” This framework, RICOL, isn’t merely about achieving results; it’s about constructing a logically sound and provable method for temporal credit assignment. The paper’s emphasis on in-context learning and sample efficiency isn’t simply about optimization; it’s about building an elegant algorithm – one where each component contributes to a clear, demonstrable pattern of improvement. Like a carefully constructed mathematical proof, the system’s efficacy isn’t accidental, but derived from its inherent structure and the logical connections within it.
What Remains to be Proven?
The presented framework, while demonstrating empirical gains in sample efficiency, skirts the fundamental question of provable convergence. The elegance of a solution is not measured by its performance on a curated set of tasks, but by the certainty that it will yield a deterministic result given any valid input. The reliance on large language models, black boxes inherently lacking in transparency, introduces a stochastic element that is, frankly, unsettling. The observed improvements may stem from clever prompting or spurious correlations within the training data, rather than a genuine advancement in the underlying learning process.
Future work must address the issue of reproducibility. If the ‘optimal’ policy shifts with each execution, despite identical parameters and observations, the entire edifice crumbles. A rigorous mathematical analysis of the credit assignment mechanism is essential – not simply demonstrating that it works, but proving why it works, and under what precise conditions. The current approach treats the language model as an oracle; a more satisfying solution would involve incorporating principles of formal verification to ensure the validity of its outputs.
Ultimately, the true test lies in scaling this framework beyond toy problems. Real-world reinforcement learning environments are rife with noise, partial observability, and adversarial dynamics. Whether this approach can maintain its efficacy in such conditions remains to be seen. The promise of online learning is alluring, but only if the resulting policies are not merely approximations, but solutions demonstrably closer to optimality.
Original article: https://arxiv.org/pdf/2602.17497.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Mewgenics vinyl limited editions now available to pre-order
- How to Get to the Undercoast in Esoteric Ebb
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- NASA astronaut reveals horrifying tentacled alien is actually just a potato
- Businessman debunks AI art claims after backlash over Scottish mural
- DTF St. Louis Recap: Time Alone from the World
2026-02-23 00:57