Author: Denis Avetisyan
As network conditions evolve, maintaining accurate traffic classification requires continuous adaptation and a robust understanding of underlying data stability.
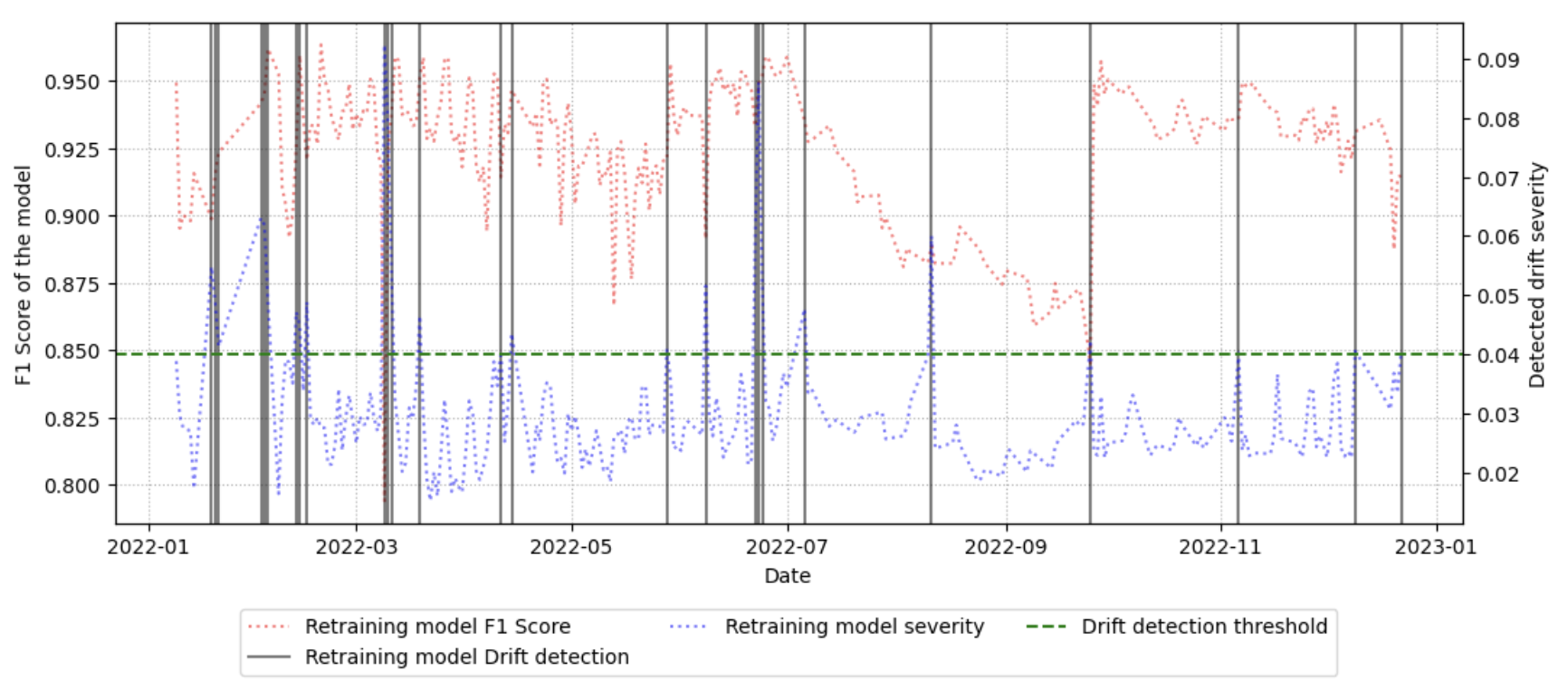
This work introduces a new benchmark and drift detection method that leverages feature importance to optimize model retraining and ensure long-term accuracy in network traffic classification tasks.
Despite the increasing reliance on machine learning for network traffic classification, deployed models often suffer performance degradation due to evolving network behaviors and obsolete datasets-a phenomenon known as concept drift. This paper introduces a novel workflow for benchmarking dataset stability, detailed in ‘Drift-Based Dataset Stability Benchmark’, utilizing a feature-weighted drift detection method to pinpoint weaknesses and optimize retraining strategies. Our approach demonstrates improved accuracy and provides an initial stability benchmark for the CESNET-TLS-Year22 dataset, highlighting areas for targeted data refinement. Can this methodology establish a standardized approach to proactively address dataset drift and ensure the long-term reliability of network security applications?
The Inevitable Erosion of Simple Solutions
For decades, identifying network traffic – determining whether data streams represent email, video streaming, or file transfers – depended on deep packet inspection. This process involved scrutinizing the actual content of data packets as they traversed the network. However, the widespread adoption of encryption technologies, such as Encrypted Server Name Indication (ESNI), fundamentally challenges this approach. ESNI, designed to enhance privacy by encrypting the server name within a secure connection, effectively obscures crucial identifying information from traditional inspection methods. Consequently, deep packet inspection is becoming increasingly blind to the type of traffic it analyzes, rendering it less reliable for network management, security applications, and quality of service provisioning. This erosion of effectiveness is driving a critical need for innovative traffic classification techniques that can operate without relying on access to plaintext packet content.
As encryption protocols like ESNI become increasingly prevalent, traditional methods of network traffic classification – reliant on examining packet content – are losing efficacy. Consequently, research is pivoting towards indirect network inspection, a strategy that analyzes metadata associated with network flows rather than the data itself. This metadata, encompassing information such as packet size, timing intervals, and connection patterns, offers a viable alternative for identifying application types and malicious activity without decrypting the content. By focusing on these external characteristics, systems can maintain visibility into network behavior while respecting user privacy and circumventing the limitations imposed by widespread encryption, presenting a necessary evolution in network security and management.
Contemporary network traffic presents an escalating challenge to traditional classification methods due to its inherent complexity. The proliferation of applications, coupled with dynamic protocols and increasingly sophisticated evasion techniques, necessitates classification systems capable of continuous adaptation. Static signatures and simple heuristics prove inadequate against traffic that is constantly morphing and blending, demanding techniques that move beyond pattern matching to embrace machine learning and behavioral analysis. These advanced approaches allow systems to not merely identify traffic, but to understand its characteristics and adjust classifications in real-time, ensuring accurate categorization even as network patterns evolve. This adaptability is not simply a matter of improved accuracy; it is crucial for maintaining network security, optimizing quality of service, and enabling effective network management in an increasingly complex digital landscape.

The Illusion of Static Defense
Machine learning (ML) classifiers automate network traffic classification by learning patterns from labeled data. Traditional methods rely on static signatures or port numbers, which are easily evaded by modern applications and encryption. ML models, including algorithms like decision trees, support vector machines, and neural networks, analyze packet features – such as flow duration, packet size distribution, and inter-arrival times – to categorize traffic without requiring pre-defined rules. This adaptive capability allows for the identification of applications and security threats based on observed behavior, even in the absence of known signatures. Furthermore, automated analysis reduces the need for manual intervention and enables scalable monitoring of large network environments.
Machine learning-based network traffic classifiers are susceptible to performance degradation due to a phenomenon known as data drift. This occurs when the statistical properties of the network traffic change over time, causing a discrepancy between the data the model was originally trained on and the current incoming traffic. These shifts can be caused by factors such as new application deployments, evolving user behavior, or changes in network infrastructure. Consequently, the model’s predictive accuracy decreases, leading to misclassification of traffic and potentially impacting network security and quality of service. The extent of performance loss is directly related to the magnitude and frequency of these changes in traffic patterns.
Mitigating the effects of data drift on machine learning models necessitates a continuous monitoring and adaptation strategy. This involves regularly evaluating model performance using metrics such as precision, recall, and F1-score against a held-out validation dataset or, ideally, live network traffic. Significant performance degradation triggers a model adaptation process, which can include retraining the model with newly labeled data, employing techniques like incremental learning to update the model without full retraining, or dynamically adjusting model weights based on observed changes in feature distributions. Automated retraining pipelines and A/B testing of different model versions are crucial for scaling these adaptive processes and ensuring sustained classification accuracy in dynamic network environments.

Beyond Surface-Level Symptoms: A Deeper Look at Drift
Model-based Feature Weight Drift Detection (MFWDD) represents a data drift identification technique that moves beyond monitoring input data distributions by instead focusing on the learned parameters of a trained machine learning model. Specifically, MFWDD analyzes changes in feature weights – the coefficients or importance assigned to each input feature during model training – to detect shifts in the underlying data generating process. The rationale is that consistent data distributions will result in stable feature weights, while distributional drift will manifest as changes in these weights. This approach allows for the identification of drift even when input features individually appear stable, as the relationship between features and the target variable is what is being monitored. By tracking these weight changes over time, MFWDD provides an indicator of potential model performance degradation and the need for retraining or model adaptation.
Model-based Feature Weight Drift Detection (MFWDD) employs several statistical tests to quantify differences in feature distributions between reference and production datasets. The Kolmogorov-Smirnov (KS) Test is a non-parametric test assessing the maximum distance between the cumulative distribution functions of two samples. Wasserstein Distance, also known as Earth Mover’s Distance, calculates the minimum cost of transforming one distribution into another. Maximum Mean Discrepancy (MMD) utilizes kernel functions to measure the distance between distributions in a reproducing kernel Hilbert space. Finally, the Page-Hinkley Test (PHT) is a sequential analysis technique detecting changes in the mean of a distribution over time, making it suitable for identifying gradual drift. These tests provide quantitative metrics for assessing distributional shifts, enabling the detection of subtle data drift impacting model performance.
Successful implementation of Model-based Feature Weight Drift Detection (MFWDD) is contingent upon accurate feature importance ranking and a standardized evaluation process for dataset stability. Establishing feature importance allows for focused drift analysis on the most influential variables, improving detection accuracy and reducing noise. A robust benchmark workflow requires defining clear stability thresholds, utilizing representative baseline datasets, and employing consistent data preprocessing techniques. Without these elements, differentiating between genuine drift and natural data variation becomes difficult, potentially leading to false positives or missed critical changes in data distribution. Consistent application of this workflow enables reliable monitoring and timely intervention to maintain model performance.
Testing in the Real World: The Value of Realistic Data
The CESNET-TLS-Year22 dataset is a publicly available resource comprised of long-term network traffic captures designed for evaluating the performance of dataset stability and drift detection methodologies. This dataset originates from a live production network, providing realistic traffic patterns and characteristics not typically found in synthetic or lab-generated data. Specifically, the dataset captures TLS-encrypted traffic over an extended period, allowing researchers to assess how machine learning models degrade over time due to evolving network behavior. Its sustained capture duration is critical for identifying subtle shifts in traffic distributions that would otherwise be missed in shorter-term evaluations, and it facilitates the testing of algorithms intended to mitigate the effects of data drift.
The CESNET-TLS-Year22 dataset facilitates the evaluation of machine learning workflow for drift detection (MFWDD) by enabling the application of algorithms such as XGBoost and K-Medoids to identify evolving traffic patterns. XGBoost, a gradient boosting algorithm, can be utilized for feature importance analysis and predictive modeling of traffic characteristics, while K-Medoids, a clustering algorithm, can segment traffic data based on similarity, revealing shifts in behavior over time. By applying these algorithms to the dataset, researchers can quantify the extent of drift, assess the efficacy of MFWDD in detecting these changes, and ultimately improve the robustness of network security systems against evolving threats.
Implementation of the proposed workflow yielded a 5% enhancement in model stability, achieving a final F1 Score of 91% following a dataset split predicated on identified drift behavior. This improvement was determined by comparing performance metrics on the drift-separated dataset to those calculated using the original, unseparated dataset. Analysis revealed the presence of 53 distinct drift events after performing class separation, indicating a substantial degree of temporal variation within the CESNET-TLS-Year22 dataset and demonstrating the workflow’s effectiveness in adapting to these changes.
The Long Game: Building Resilient Network Defenses
Network Intrusion Detection Systems (NIDS) often suffer diminished performance over time due to a phenomenon known as data drift – the change in input data characteristics. Methods like Monitoring Feature-wise Drift Detection (MFWDD) address this challenge by proactively identifying shifts in network traffic patterns. These techniques continuously analyze incoming data, comparing current characteristics to a baseline established during initial training. By detecting even subtle drift, the system can trigger adaptive mechanisms – such as model retraining or parameter adjustments – to maintain accuracy and prevent performance degradation. This proactive approach is critical for ensuring the long-term reliability of NIDS, particularly in dynamic network environments where traffic patterns are constantly evolving, and enables continued effective identification of malicious activity despite changes in normal network behavior.
Accurate traffic classification forms the bedrock of effective network intrusion detection, enabling systems to distinguish between benign and malicious activity with greater precision. When a network can reliably categorize traffic types – such as identifying legitimate web browsing from data exfiltration attempts – it dramatically improves the speed and accuracy of threat response. This refined categorization minimizes false positives, reducing alert fatigue for security personnel and allowing them to focus on genuine threats. Furthermore, precise traffic classification facilitates faster containment of malicious activity, as systems can quickly isolate and mitigate suspicious connections before significant damage occurs. The ability to swiftly and accurately identify malicious patterns directly translates to a stronger security posture and reduced risk exposure for network infrastructure.
A robust network intrusion detection system relies on consistent performance, which is increasingly challenged by evolving traffic patterns – a phenomenon known as data drift. Recent advancements demonstrate that integrating sophisticated drift detection techniques with high-quality datasets, such as CESNET-TLS-Year22, significantly bolsters network security. Studies reveal that employing a weighted approach-prioritizing features based on their importance-yields a Drift Detection Sensitivity ranging from 0% to 15%. This represents a substantial improvement over conventional methods, which exhibit sensitivities between 1% and 40%, suggesting a considerable reduction in false positives and a more accurate identification of genuine threats. Consequently, networks equipped with these combined capabilities are better positioned to maintain reliable security, even in the face of dynamic and adversarial conditions.
The pursuit of pristine datasets, as this work on drift-based stability benchmarking demonstrates, is a Sisyphean task. The paper’s focus on feature importance within the MFWDD drift detection method highlights a practical truth: models don’t fail on static data, they succumb to change. As G. H. Hardy observed, “The most profound knowledge is the knowledge that one knows nothing.” This resonates deeply with the core idea of constantly assessing dataset stability; acknowledging the inherent uncertainty in network traffic classification is the first step toward building resilient systems. Every optimization, every carefully engineered feature, will eventually require reassessment as production data inevitably drifts, demanding a pragmatic approach to model retraining rather than a search for absolute, unchanging accuracy.
The Road Ahead
The pursuit of ‘dataset stability’ benchmarks feels predictably optimistic. This work, while a reasonable attempt to quantify the inevitable decay of model performance in network traffic classification, merely formalizes a problem data scientists have battled since the first logistic regression. The MFWDD method, with its focus on feature importance, is a sensible addition to the drift detection toolkit, yet it’s difficult to imagine a scenario where any method permanently solves the issue. Production networks will continue to evolve in ways unforeseen by even the most sophisticated benchmark.
Future effort will likely concentrate on automating the retraining pipeline itself, rather than perfecting drift detection. The real challenge isn’t knowing a model is failing, but minimizing the operational cost of constantly rebuilding it. One anticipates a proliferation of ‘self-healing’ systems – complex, brittle, and ultimately requiring manual intervention when the corner cases, as they always do, begin to accumulate. If all automated retraining tests pass, it will simply mean the tests are insufficient.
Perhaps the most interesting direction lies not in better algorithms, but in accepting inherent impermanence. A shift toward models designed for short lifespans, readily replaced and discarded, could prove more practical than striving for elusive, long-term stability. This approach acknowledges the fundamental truth: elegance in design rarely survives contact with reality.
Original article: https://arxiv.org/pdf/2512.23762.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- All Itzaland Animal Locations in Infinity Nikki
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- How to Get to the Undercoast in Esoteric Ebb
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- A Dark Scream Theory Rewrites the Only Movie to Break the 2-Killer Rule
- Crimson Desert: Disconnected Truth Puzzle Guide
- Gold Rate Forecast
- Superman/Spider-Man #1 Review: Bigger DC-Marvel Crossovers Teased
2026-01-04 14:23