Author: Denis Avetisyan
Researchers have developed a novel method for integrating textual information with time series data to improve the accuracy of future predictions.

Spectral Text Fusion leverages frequency domain analysis to effectively combine multimodal data for enhanced time series forecasting performance.
Effective multimodal time-series forecasting requires reconciling the distinct temporal dynamics of numerical data and contextual information like text, yet existing methods often struggle to capture the long-range influences of textual context. This paper introduces ‘Spectral Text Fusion: A Frequency-Aware Approach to Multimodal Time-Series Forecasting’, a novel framework that addresses this limitation by integrating textual embeddings directly into the frequency domain of time-series data. By adaptively reweighting spectral components based on textual relevance via a cross-attention mechanism, SpecTF achieves improved forecasting accuracy with fewer parameters than state-of-the-art models. Could this frequency-domain fusion approach unlock new possibilities for effectively leveraging multimodal data in a wider range of forecasting applications?
The Limits of Looking Back: Why Traditional Forecasting Falls Short
Conventional time series forecasting, while effective in stable conditions, frequently encounters limitations when dealing with the intricacies of real-world phenomena. These methods often assume a degree of stationarity and linearity that rarely holds true, particularly in systems influenced by a multitude of interacting factors. External events – geopolitical shifts, sudden economic changes, or even viral social media trends – can introduce non-linear dependencies and unpredictable volatility that traditional statistical models, like ARIMA or exponential smoothing, struggle to capture. Consequently, forecasts based solely on historical numerical data can exhibit significant errors, especially when complex relationships between variables are obscured or when unforeseen circumstances disrupt established patterns. The inherent difficulty in modeling these multifaceted interactions necessitates more sophisticated approaches capable of acknowledging and incorporating the influence of external forces and non-linear dynamics.
Conventional forecasting techniques often operate in isolation, analyzing numerical time series data without considering the wealth of information contained in related text. News articles, social media posts, and industry reports frequently provide crucial context – explaining why certain trends emerge, anticipating shifts in consumer behavior, or highlighting unforeseen events that impact future values. The failure to integrate this contextual understanding represents a significant limitation; models reliant solely on historical numbers struggle to discern subtle influences or react effectively to novel circumstances. Consequently, predictions can be inaccurate or lack the nuanced insight offered by a more holistic approach that incorporates the descriptive power of language and the complex relationships it reveals.
The increasing complexity of modern forecasting challenges necessitate a shift beyond traditional methods reliant solely on numerical time series data. Current predictive models often operate in isolation, failing to capitalize on the wealth of information contained within associated text – news articles, social media posts, or expert reports – which can provide crucial context and leading indicators. Integrating these disparate data types, known as multimodal learning, allows for a more holistic understanding of underlying patterns and external influences. This approach enables models to discern nuanced relationships, anticipate unexpected shifts, and ultimately generate more accurate and robust predictions across diverse fields, from financial markets and supply chain management to public health and climate modeling. The ability to effectively synthesize numerical trends with textual insights is no longer a desirable feature, but a fundamental requirement for navigating an increasingly interconnected and data-rich world.
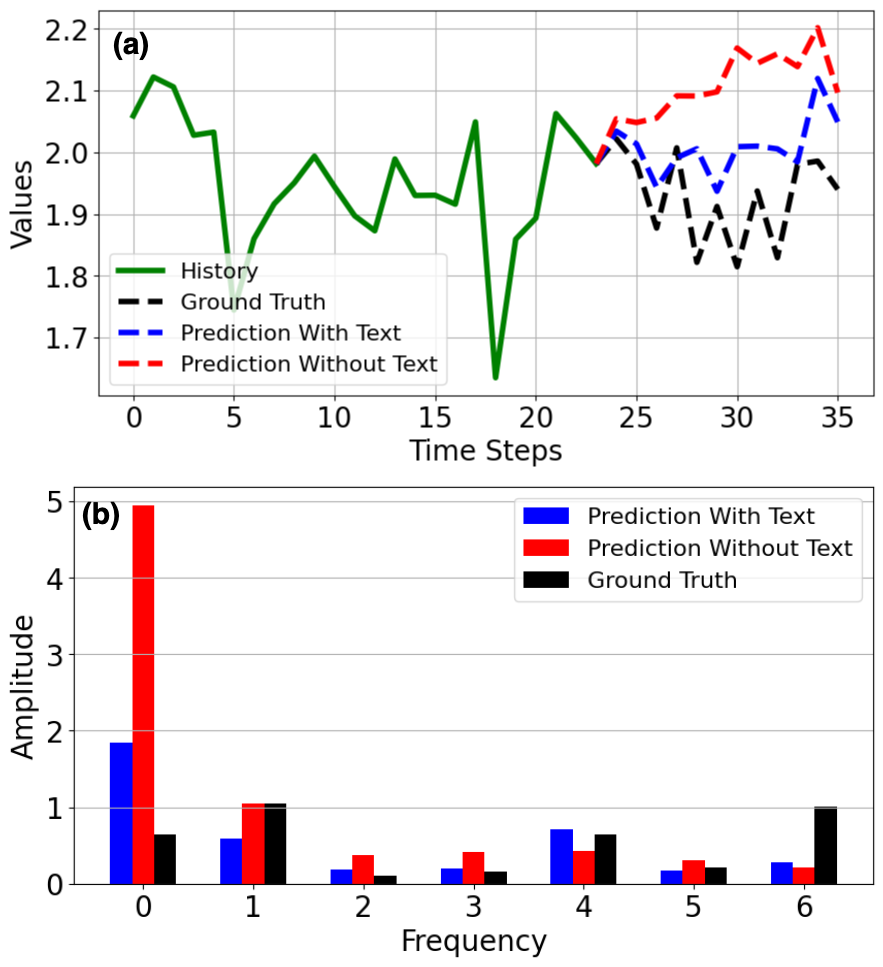
Beyond the Timeline: A Frequency-Based Approach to Forecasting
Spectral Text Fusion (SpecTF) represents a departure from traditional multimodal forecasting techniques that primarily operate within the time domain. Instead of directly processing raw time series and text data, SpecTF transforms these inputs into the frequency domain using the Discrete Fourier Transform (DFT) and its optimized implementation, the Real Fast Fourier Transform (RFFT). This frequency-domain representation allows the model to analyze data based on the constituent frequencies present, offering an alternative perspective for identifying patterns and relationships. By shifting the focus from temporal order to frequency components, SpecTF aims to improve the model’s capacity to capture complex interactions between different data modalities and enhance forecasting accuracy, particularly for long-horizon predictions.
Spectral Text Fusion (SpecTF) employs the Discrete Fourier Transform (DFT) to convert both time series and textual data into a spectral representation. The DFT decomposes a signal into its constituent frequencies, effectively transforming the data from the time or token domain into a frequency domain where each point represents the amplitude and phase of a specific frequency. To improve computational efficiency, SpecTF utilizes the Real Fast Fourier Transform (RFFT), an optimized algorithm for computing the DFT of real-valued signals, which is suitable for typical time series data. This embedding process results in a spectral space where time series and text are represented as frequency components, enabling subsequent analysis and fusion based on their spectral characteristics. The resulting spectral representations are complex-valued, containing both magnitude and phase information, which is crucial for capturing the full signal characteristics.
SpecTF’s utilization of the frequency domain, achieved through the Discrete Fourier Transform, enables the application of the Convolution Theorem to multimodal fusion. This theorem states that convolution in one domain-such as time-corresponds to multiplication in another-the frequency domain. Consequently, interactions between time series and text embeddings are computed via element-wise multiplication in the spectral space, significantly reducing computational complexity compared to direct convolution in the time domain. This allows for efficient cross-modal attention mechanisms and feature interactions, effectively fusing information from both modalities without the quadratic complexity associated with time-domain attention calculations; mathematically, this is represented as F(x <i> h) = F(x) </i> F(h), where F denotes the Fourier Transform, x represents the time series, and h represents the text embedding.
Operating in the frequency domain enables the capture of long-range dependencies within time series data that are often attenuated or lost in time-domain analyses. Traditional time-domain methods frequently struggle with vanishing or exploding gradients when processing sequences over extended periods, hindering their ability to model distant interactions. By transforming data into the frequency domain via the Discrete Fourier Transform, SpecTF effectively decomposes the signal into its constituent frequencies, allowing the model to identify and leverage relationships between frequencies that correspond to long-range temporal patterns. Furthermore, this spectral representation facilitates the detection of subtle relationships and nuanced correlations that may not be immediately apparent in the time domain, as frequency components can reveal underlying periodicities or harmonic structures indicative of complex interactions.
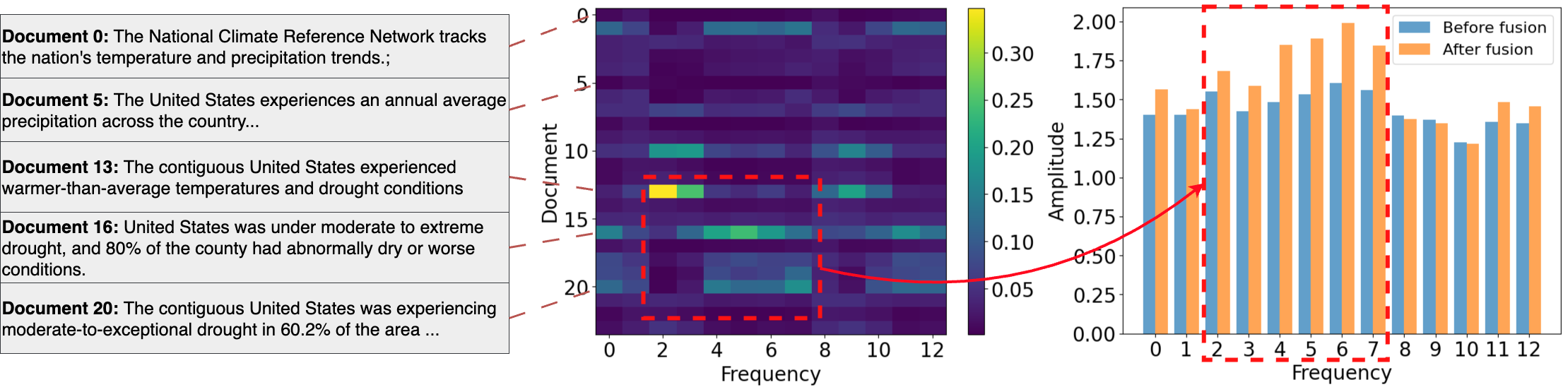
Attention in the Frequency Domain: Sifting Signal from Noise
Frequency Cross-Modality Fusion employs an attention mechanism to dynamically weigh the contribution of textual data during the processing of time series spectral components. This attention mechanism calculates relevance scores between textual embeddings and frequency-domain features – typically obtained via a Short-Time Fourier Transform or wavelet decomposition – allowing the model to prioritize textual information most pertinent to specific spectral characteristics. The resulting weighted combination of textual and spectral representations is then used for downstream tasks, effectively enabling the model to focus on the most informative aspects of both modalities and improve predictive performance. This selective integration differs from simple concatenation or element-wise averaging, as it adapts to the relationships between text and spectral data.
Selective textual integration, facilitated by the attention mechanism, improves predictive performance by weighting the contribution of each textual element based on its relevance to specific spectral features. This dynamic weighting process allows the model to prioritize informative textual segments while downplaying noise or irrelevant details, leading to increased accuracy. Furthermore, focusing on the most pertinent textual information enhances the model’s robustness against variations in text length, phrasing, and the presence of distracting content. The attention mechanism effectively filters the input text, ensuring that only the most predictive elements contribute to the final output.
The proposed method directly operates on spectral representations utilizing complex numbers, which are fundamental to signal processing and inherently encode both amplitude and phase information. Unlike methods that treat these as separate entities, this approach leverages complex multiplication to simultaneously consider the effects of both components during feature fusion. Specifically, complex multiplication (a + bi)(c + di) = (ac - bd) + (ad + bc)i inherently modulates the amplitude ( \sqrt{(ac-bd)^2 + (ad+bc)^2} ) and adjusts the phase ( \arctan2(ad+bc, ac-bd) ) of the signal, allowing the model to learn relationships that depend on the interplay between these two spectral characteristics without requiring separate processing or explicit phase unwrapping.
Frequency-domain Multi-Layer Perceptrons (MLPs) are integral to the processing of spectral representations derived from time series data. These MLPs operate directly on the magnitude and phase components of the spectral features – typically obtained via the Short-Time Fourier Transform or Wavelet Transform – allowing for non-linear transformations and feature extraction in the frequency domain. Unlike traditional MLPs applied to raw time series, frequency-domain MLPs leverage the inherent properties of spectral data, enabling the model to learn complex relationships between frequency components and target variables. The architecture typically involves fully connected layers with activation functions applied to both the real and imaginary parts of the complex spectral values, facilitating the learning of frequency-specific patterns.
Beyond Benchmarks: Real-World Impact and Future Directions
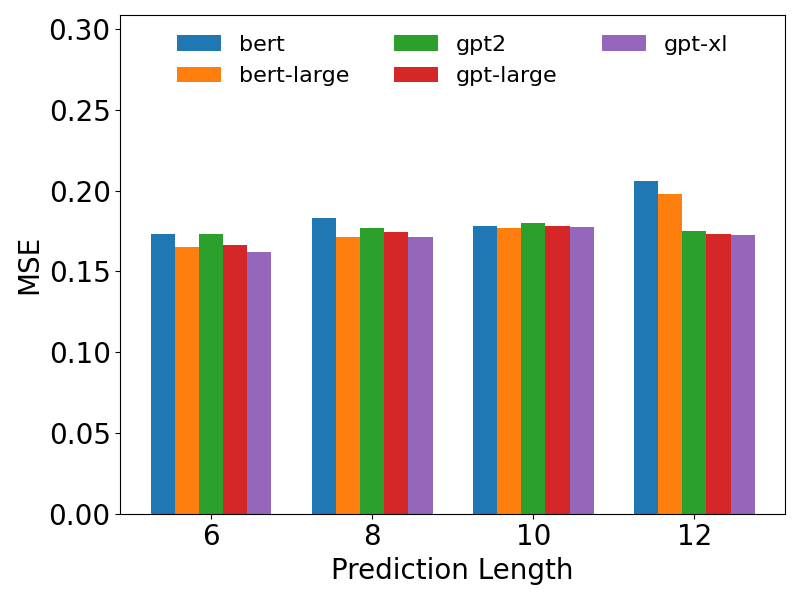
Recent evaluations confirm SpecTF’s position at the forefront of multimodal time series forecasting, as evidenced by its state-of-the-art performance on both the Time-MMD Benchmark and the challenging TimeText Corpus. This achievement isn’t merely incremental; the model consistently surpasses existing methodologies, indicating a fundamental advancement in forecasting capabilities. Rigorous testing demonstrates SpecTF’s ability to more accurately predict future values across a diverse range of temporal data, from financial indicators to climatic patterns and medical diagnostics. The consistent outperformance on these established benchmarks solidifies SpecTF as a powerful tool for analysts and researchers seeking to leverage the predictive potential of complex time series data, offering improved accuracy and reliability in forecasting applications.
Rigorous evaluation demonstrates that SpecTF consistently surpasses the performance of established forecasting techniques. Across a diverse benchmark of nine datasets, the model achieves a noteworthy reduction in prediction error, evidenced by an average improvement of 3.82% in Mean Squared Error (MSE) and 2.25% in Mean Absolute Error (MAE). These gains indicate a substantial enhancement in predictive accuracy and reliability, suggesting that SpecTF effectively captures the underlying patterns and dependencies within complex time series data. This consistent outperformance highlights the efficacy of the spectral approach and its potential to deliver more accurate forecasts in a variety of real-world applications.
Evaluations conducted on the TimeText Corpus reveal substantial performance gains with SpecTF, notably within specialized domains. The model demonstrated an 8.81% reduction in Mean Squared Error MSE when forecasting climate data, indicating a significantly improved ability to predict complex environmental patterns. Furthermore, in the medical domain, SpecTF achieved a 5.90% decrease in Mean Absolute Error MAE, suggesting enhanced accuracy in forecasting crucial health-related time series. These results highlight SpecTF’s capacity to capture nuanced temporal dynamics within specific, challenging datasets and represent a considerable advancement over existing forecasting techniques in these critical fields.
A core principle underpinning SpecTF’s robust performance is its adherence to Parseval’s Energy Conservation Theorem, a fundamental concept in Fourier analysis. This theorem guarantees that the total energy of a signal remains constant whether represented in the time domain or the frequency domain. By operating primarily within the frequency domain, SpecTF inherently preserves signal energy throughout its forecasting process, preventing the amplification of noise or the attenuation of important features that can plague models operating solely in the time domain. This preservation of energy not only contributes to the model’s numerical stability – preventing runaway errors during training and inference – but also directly enhances its accuracy by ensuring that the forecasted time series maintains a realistic energy profile, mirroring the characteristics of the observed data. The consequence is a model less susceptible to spurious fluctuations and more capable of producing reliable and meaningful predictions across diverse time series applications.
A novel forecasting framework, SpecTF, presents a significant advancement in multimodal time series analysis, promising impactful applications across numerous disciplines. Beyond traditional statistical methods, this approach effectively integrates and analyzes data from multiple sources – offering enhanced predictive capabilities for complex systems. In finance, it can refine algorithmic trading strategies and risk assessment; within healthcare, it enables earlier and more accurate disease diagnosis and patient outcome prediction. Furthermore, environmental monitoring benefits through improved weather forecasting, resource management, and anomaly detection in climate patterns. The framework’s adaptability extends to diverse datasets and varying temporal resolutions, positioning it as a versatile tool for researchers and practitioners seeking robust and reliable forecasting solutions in an increasingly data-rich world.
The adoption of a frequency-domain approach, as demonstrated by SpecTF, extends beyond immediate forecasting improvements and establishes a fertile ground for future investigations into spectral data fusion and representation learning. By operating within the spectral realm, the model implicitly learns robust feature representations that capture the underlying oscillatory patterns within the time series data – a characteristic potentially transferable to other multimodal datasets. This opens possibilities for developing novel techniques to effectively combine information from disparate sources, leveraging shared spectral characteristics to enhance predictive power. Furthermore, exploring learned spectral representations could lead to the discovery of new, compact data encodings that retain critical information while reducing dimensionality, ultimately enabling more efficient and scalable time series analysis across diverse scientific and industrial applications.
The pursuit of elegant fusion, as demonstrated by Spectral Text Fusion, inevitably courts the realities of production. This framework, aiming to integrate textual data into the frequency domain for improved forecasting, feels destined to join the ranks of abstractions that eventually succumb to unforeseen data quirks. As Ken Thompson observed, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not going to be able to debug it.” The promise of enhanced accuracy through frequency-domain integration is appealing, yet one anticipates the inevitable edge cases-the anomalies that reveal the limits of even the most mathematically sound approach. It’s a beautifully constructed system, undoubtedly, but one that, like all deployable things, will eventually crash in spectacular fashion.
The Road Ahead
Spectral Text Fusion, as presented, offers a predictably elegant solution – which means the inevitable edge cases are already multiplying. The demonstrated gains from frequency-domain integration are unlikely to persist universally; production data, in its infinite capacity for chaos, will undoubtedly reveal distributions where this spectral alignment is not merely unhelpful, but actively detrimental. The paper glosses over the computational cost of these transformations, a detail that will become brutally relevant when scaled beyond the curated datasets. Anything self-healing just hasn’t broken yet.
Future work will inevitably focus on ‘explainability’, a field dedicated to retroactively justifying decisions made by opaque algorithms. A more pressing concern, though unaddressed, is the fragility of these models to adversarial textual perturbations. A cleverly crafted sentence, designed to exploit the spectral alignment, could induce catastrophic forecasting errors. If a bug is reproducible, it suggests a stable system, but stability is not the same as robustness.
The current reliance on attention mechanisms, while effective, feels suspiciously like a placeholder. The field seems fixated on increasingly complex architectures, conveniently ignoring the fact that documentation is collective self-delusion. True progress will require a fundamental re-evaluation of feature engineering – or, more likely, the acceptance that some data simply resists prediction.
Original article: https://arxiv.org/pdf/2602.01588.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Mewgenics vinyl limited editions now available to pre-order
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Viral Letterboxd keychain lets cinephiles show off their favorite movies on the go
- Does Mark survive Invincible vs Conquest 2? Comics reveal fate after S4E5
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
2026-02-03 21:28