Author: Denis Avetisyan
New research reveals that the core components of large language models exhibit surprising instability, challenging assumptions about the consistency of their learned representations.
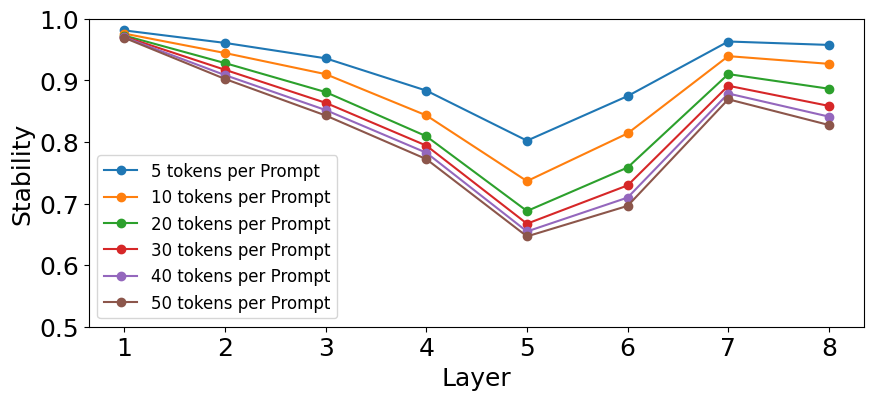
Quantifying attention-head stability across training runs demonstrates that mid-layer features are particularly sensitive to initialization, complicating efforts in mechanistic interpretability and circuit discovery.
Despite increasing progress in mechanistic interpretability, the robustness of discovered neural circuits remains largely unexamined across independent model instantiations. This work, ‘Quantifying LLM Attention-Head Stability: Implications for Circuit Universality’, systematically quantifies the stability of attention head representations across multiple training runs of transformer language models. Our findings reveal that mid-layer heads are particularly unstable, exhibiting the greatest divergence between runs, and that instability correlates with increased functional importance in deeper models. Does this inherent variability challenge the notion of universally consistent internal representations, and what safeguards are necessary to ensure reliable oversight of increasingly complex AI systems?
The Fragility of Understanding: Seeds of Instability in Transformers
The remarkable performance of Transformer models belies a surprising fragility: even minor alterations to the random number generator’s starting point – the ‘seed’ – during initial parameter assignment can yield drastically different learned representations. This sensitivity isn’t merely a cosmetic issue; it implies that two identically structured and trained Transformer networks, differing only in their seed, can develop substantially divergent internal understandings of the same data. Consequently, results obtained from one training run aren’t reliably reproducible in another, even with identical hyperparameters and datasets, creating a significant hurdle for scientific validation and practical deployment, particularly as models grow in complexity and scale. The implication is that the learned features aren’t as robustly defined by the data itself, but are, to a degree, artifacts of the specific random initialization process.
The escalating sensitivity to random number generator seeds presents a significant hurdle as Transformer models grow in complexity. While seemingly innocuous, differing seeds during training can yield drastically different model behaviors, even with identical data and hyperparameters. This poses a critical challenge to reproducibility – the ability to consistently recreate results – and threatens the reliability of these models in real-world applications. As models scale to billions, and even trillions, of parameters, this seed sensitivity isn’t merely a nuisance; it becomes a fundamental concern, demanding new techniques for stabilizing training and ensuring consistent performance across different runs and deployments. The implications extend beyond academic research, impacting the trustworthiness of AI systems built upon these large-scale models and necessitating careful consideration of variance in performance metrics.
The observed instability in Transformer models at scale doesn’t appear to stem from fundamental architectural defects, but rather from vulnerabilities in the training process itself. Current research suggests these models struggle with robustness – the ability to consistently learn and retain meaningful information despite minor perturbations. During training, the network’s internal representations can be highly sensitive to initial conditions and the specific sequence of data encountered. This means that even with identical architectures and datasets, different training runs, initiated with different random seeds, can result in drastically divergent learned features and performance. The core challenge, therefore, lies not in redesigning the Transformer, but in developing techniques that enhance the stability and consistency of information processing and retention throughout the training regime, potentially through improved regularization, normalization, or data augmentation strategies.
Attention’s Ephemeral Grasp: A Seed of Inconsistency
Attention heads, a core component of transformer models, exhibit significant sensitivity to random weight initialization, manifesting as seed instability. This means that training the same model architecture with identical data and hyperparameters can produce substantially different results – in terms of both final performance and the learned internal representations – simply due to variations in the initial random values assigned to the attention head weights. This behavior is not typically observed in other model layers to the same degree, indicating a particular fragility within the attention mechanism. The variance in behavior across different seeds suggests that the optimization landscape for attention heads is complex and potentially contains numerous local optima, leading to inconsistent learning outcomes and requiring careful hyperparameter tuning or regularization to achieve robust performance.
Examination of Attention Score Matrices during model training consistently demonstrates a lack of stable attention patterns. While models are exposed to identical datasets and utilize fixed hyperparameters, the resulting attention distributions-indicating which input tokens each head focuses on-vary substantially across independent training runs. This inconsistency is not merely superficial noise; analysis reveals that the specific tokens receiving high attention scores are not reliably reproduced, even after extended training. This suggests the learning process for attention weights is sensitive to random initialization and does not consistently converge on a deterministic set of attention relationships within the input data.
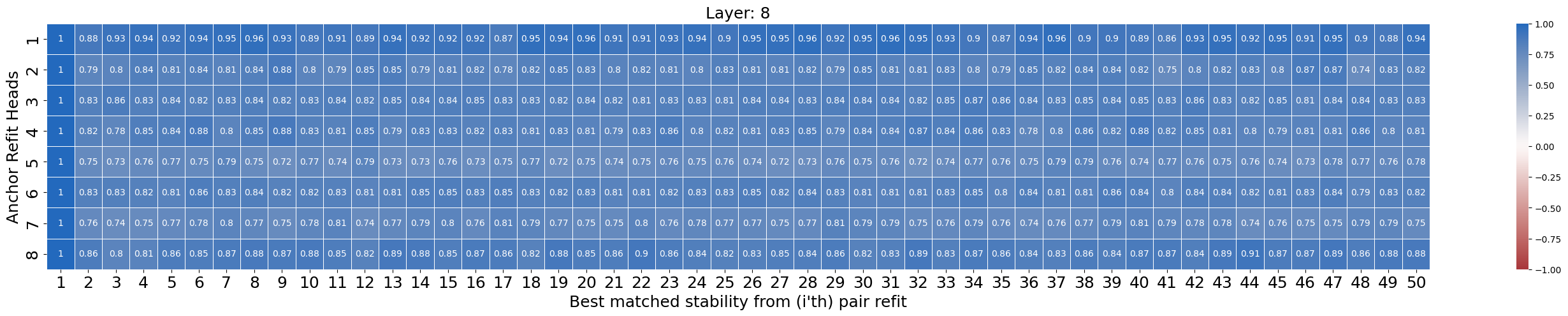
Ablation studies, conducted by systematically removing attention heads and measuring the resulting Post-Ablation Perplexity (PAP), indicate significant redundancy within multi-head attention mechanisms. These studies consistently demonstrate that a substantial proportion of attention heads exhibit negligible impact on model performance when removed; the increase in PAP following their ablation is minimal, often within the margin of error. This suggests that many models are over-parameterized with respect to attention heads, implying computational inefficiency and potential for model compression without significant performance degradation. Further analysis has shown that the specific heads identified as redundant vary across different model sizes and datasets, but the overall trend of substantial redundancy remains consistent.
The Residual Stream: A Foundation of Stability
Analysis of model training across multiple random seeds indicates that residual streams, created via skip connections, exhibit substantially greater stability than attention heads. This stability is measured by the variance in weight distributions observed across these different training runs; lower variance signifies higher stability. Specifically, the standard deviation of weights within the residual streams consistently remains lower than that of attention head weights under identical training conditions. This suggests that the direct information pathways established by skip connections are less sensitive to the specific random initialization of model parameters, resulting in more consistent and predictable behavior during training compared to the attention mechanism.
Skip connections, forming the residual stream, provide a direct pathway for information flow, mitigating the impact of random weight initialization. Unlike attention mechanisms which rely on learned relationships and thus are sensitive to initial conditions, the residual stream offers a consistent, unmodulated route for gradients and activations. Empirical results demonstrate that variations in training seed have a demonstrably smaller effect on the residual stream’s behavior compared to attention heads; this indicates a higher degree of stability stemming from the direct connection and a reduced dependence on the potentially unstable dynamics of the attention process. Consequently, the residual stream’s performance is less susceptible to the ‘lottery ticket hypothesis’ effects associated with finding well-initialized weights, offering a more predictable training trajectory.
Analysis of model training across multiple seeds demonstrates a consistently higher stability value for the residual stream, formed by skip connections, compared to individual attention heads. This discrepancy is quantified as the ‘Stability Gap’ (\Delta S), calculated as the difference between the residual stream’s stability and that of the attention heads. Empirical results indicate that \Delta S increases proportionally with model depth; deeper models exhibit a more pronounced difference in stability, suggesting that the direct information pathway of the residual stream becomes increasingly advantageous in mitigating the effects of initialization variance as network complexity grows.
Mapping Robustness: CKA and Meta-SNE Reveal Stable Representations
Centered Kernel Alignment (CKA) was employed to quantify the similarity of learned representations across multiple random seeds during training. CKA calculates the cosine similarity between the centered kernel matrices of two sets of representations, providing a metric for representation stability. Results demonstrated that representations derived from the residual stream consistently exhibited higher CKA scores compared to those obtained from attention heads. This indicates that the information propagated through the residual connections is less sensitive to variations in initialization and training dynamics, resulting in more stable and reproducible feature maps across different training runs.
Meta-SNE, a dimensionality reduction technique particularly suited for visualizing high-dimensional data, was employed to assess the stability of learned representations. Visualizations consistently demonstrated that representations originating from the residual stream exhibited tighter clustering compared to those derived from attention heads. This tighter clustering indicates that, despite variations in random initialization (different seeds), the residual stream consistently produces more similar representations across multiple training runs. The observed pattern suggests a robustness in the information captured by the residual connections, leading to reduced variance in the resulting embedding space when visualized with Meta-SNE.
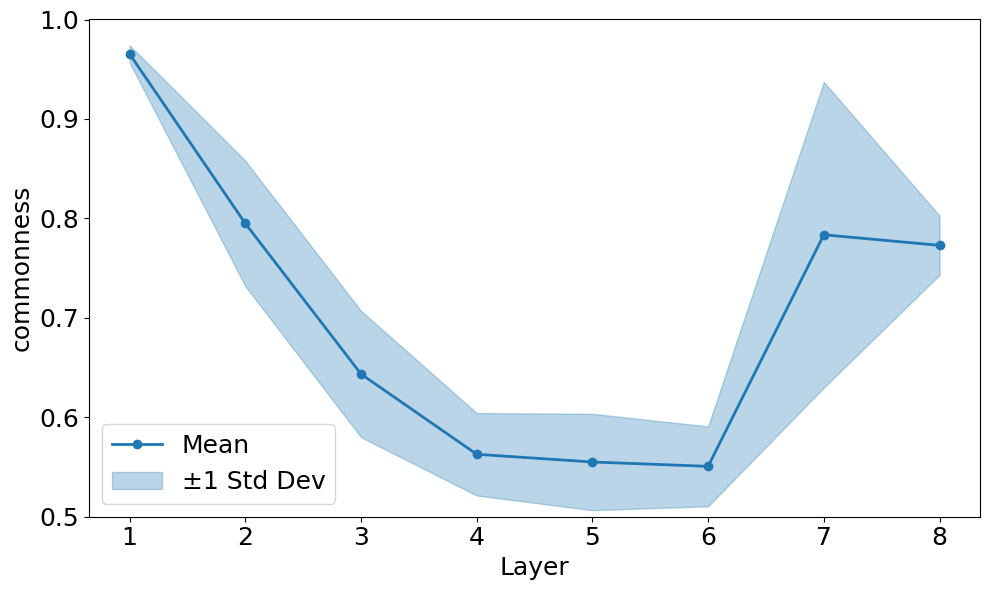
Analysis of an 8-layer model revealed that the fifth layer exhibited the lowest representation stability, quantified by a CKA score of approximately 0.70. This indicates a heightened sensitivity to variations in model initialization compared to other layers. Lower CKA scores signify greater dissimilarity in learned representations across different random seeds, suggesting that layer 5’s feature maps are more prone to change based on initial parameter settings. This vulnerability may necessitate specific regularization techniques or initialization schemes when training models with similar architectures to improve the robustness of features learned at this depth.
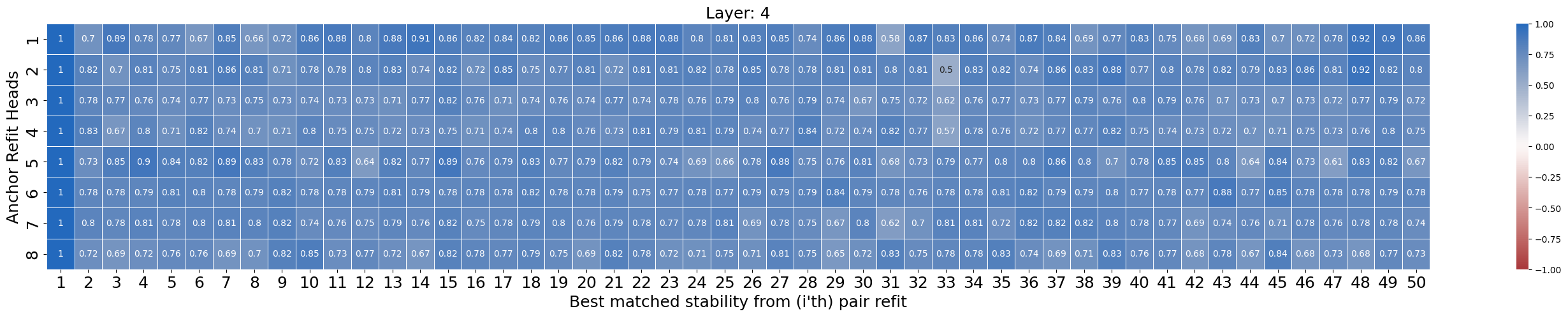
Reinforcing Consistency: Optimization and the Pursuit of Stable Learning
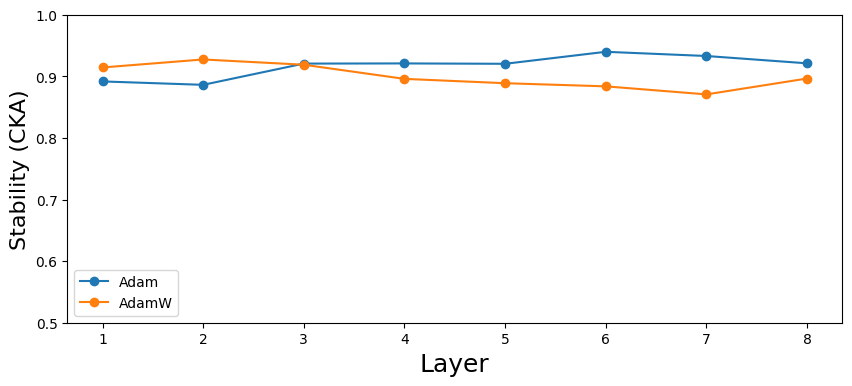
The implementation of the AdamW optimizer, coupled with judicious weight decay, proved instrumental in bolstering seed stability within Transformer models. Traditional optimization algorithms often struggle with the sensitivity of randomly initialized neural networks, leading to unpredictable training trajectories and inconsistent results across different ‘seeds’ – instances initiated with varying random number generators. However, AdamW’s decoupled weight decay-applying regularization directly to the weights rather than incorporating it into the gradient update-effectively mitigated these issues. This approach allows for a more precise control over weight magnitude, preventing runaway activations and promoting smoother convergence, even with substantial variations in initial conditions. Consequently, the use of AdamW significantly reduced the performance disparity between different seeds, fostering more reliable and reproducible results throughout the training process and ultimately leading to more robust and dependable Transformer architectures.
The inherent sensitivity of Transformer models to random initial conditions can be substantially lessened through meticulous hyperparameter optimization. Studies reveal that adjusting parameters like Prompt Length – the initial input sequence provided to the model – significantly influences stability during training. Furthermore, the implementation of Layer Normalization, a technique that standardizes the inputs to each layer, consistently demonstrates a capacity to reduce internal covariate shift and dampen the effects of erratic weight initialization. This careful calibration doesn’t eliminate the influence of randomness entirely, but it demonstrably improves the robustness of the model, allowing it to converge more reliably and consistently across different training runs, ultimately leading to more predictable and stable outcomes.
Investigations into the internal dynamics of the Transformer architecture revealed a notable inverse relationship between the magnitude of query weights and layer stability. Specifically, layers characterized by larger norms of their query weights demonstrated a propensity for decreased stability during the initial phases of training. This suggests that high-magnitude query weights may exacerbate the impact of random initialization, leading to more pronounced fluctuations in layer activations and potentially hindering convergence. The observation implies that regulating query-weight norms-perhaps through techniques like weight normalization or careful initialization schemes-could represent a valuable strategy for enhancing the robustness and reliability of Transformer models, particularly when dealing with limited data or complex tasks. Further research is needed to fully elucidate the underlying mechanisms driving this correlation and to explore effective methods for mitigating its effects.
The pursuit of mechanistic interpretability, as evidenced by this study of attention-head stability, reveals a fundamental truth about complex systems. It isn’t enough to simply discover circuits; one must account for their inherent fragility. The varying degrees of seed stability, particularly in mid-layers, suggest that these internal representations aren’t the fixed, universal features many assume. As Edsger W. Dijkstra observed, “It’s not enough to try to understand the system; you must also understand the context in which it operates.” This research underscores that context – the specific training seed – dramatically influences the resulting circuits, and any claim of universality must be tempered with an acknowledgement of this inherent variability. Architecture, after all, is a compromise frozen in time, and time, in this case, manifests as a different random seed.
The Shifting Sands
This work reveals a truth often obscured by the pursuit of mechanistic interpretability: a model isn’t a static map to be deciphered, but a landscape constantly reshaped by unseen currents. The varying stability of attention heads across training runs isn’t merely a technical detail; it’s an admission that universality – the dream of consistent, transferable features – may be a phantom. Each seed represents a different garden grown from the same source, yielding subtly – or not so subtly – different fruit.
The implication isn’t that interpretability is impossible, but that its focus must shift. Resilience lies not in isolating a single ‘correct’ circuit, but in understanding the distribution of circuits – the tolerances, the redundancies, the graceful degradations. A system isn’t built, it’s grown, and pruning for ‘optimal’ performance may inadvertently remove essential buffers against unforeseen change.
Future work will likely necessitate a move beyond feature attribution and towards understanding the dynamics of feature drift. The question isn’t simply “what does this head compute?” but “how reliably does it compute it, and what happens when it fails?”. The pursuit of interpretability, then, becomes less a quest for certainty and more a practice of compassionate understanding – acknowledging the inherent fragility of these complex, emergent systems.
Original article: https://arxiv.org/pdf/2602.16740.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- How to Get to the Undercoast in Esoteric Ebb
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- Warframe Voruna Prime access begins on April 8 for all platforms, new deluxe cosmetic Warframe skins revealed
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- Zendaya’s 4 Big 2026 Movies Could Beat Brie Larson’s Box 2019 Office Record
- Dakota County’s plan to end hunger involves locking mayors in escape rooms
- All Itzaland Animal Locations in Infinity Nikki
2026-02-21 17:30