Author: Denis Avetisyan
A new approach to graph neural networks dynamically adjusts connections to improve performance and efficiency, even under critical conditions.
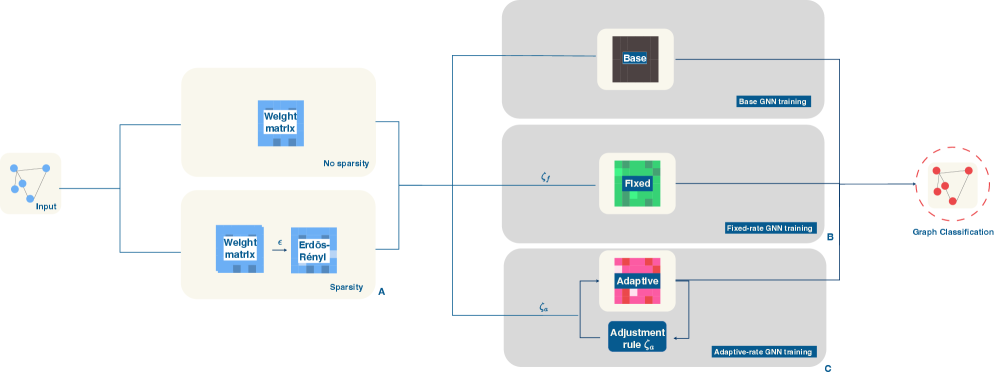
This review explores adaptive rewiring techniques in graph neural networks for enhanced sparsity, regularization, and robustness, with applications to power grid reliability analysis.
Despite the increasing success of Graph Neural Networks (GNNs), their computational demands and memory footprint often limit scalability to large, complex graphs. This paper, ‘Exploring the impact of adaptive rewiring in Graph Neural Networks’, investigates sparsity and adaptive rewiring techniques as a means of regularizing GNNs and improving their efficiency. Our results demonstrate that dynamically adjusting network connectivity during training-particularly when combined with early stopping-can enhance both performance and generalization, as validated on benchmark datasets and a critical application in N-1 contingency assessment for power grid reliability. Can these insights into adaptive sparsity unlock further advancements in deploying GNNs to increasingly complex real-world challenges?
The Inevitable Weight of Calculation
The remarkable advancements in deep learning are increasingly shadowed by a substantial demand for computational power. Modern neural networks, particularly those achieving state-of-the-art results in areas like natural language processing and computer vision, require vast datasets and prolonged training times, often necessitating specialized hardware such as GPUs and TPUs. This escalating resource consumption isn’t merely a matter of cost; it presents a significant barrier to entry for researchers and developers lacking access to these expensive tools. Furthermore, deploying these computationally intensive models-even after training-poses challenges for real-time applications and resource-constrained devices, limiting their widespread adoption and hindering progress towards truly ubiquitous artificial intelligence. The trend suggests that continued innovation will necessitate not only algorithmic improvements but also breakthroughs in hardware and energy efficiency to overcome this growing computational bottleneck.
The relentless increase in computational requirements poses a significant barrier to the widespread adoption of deep learning. As models grow in complexity to tackle increasingly nuanced problems, the hardware needed to train and deploy them becomes prohibitively expensive and energy-intensive. This creates a disparity, limiting access to cutting-edge AI capabilities for researchers and developers with constrained resources. Furthermore, the difficulty in scaling these models restricts their application in real-time scenarios and large-scale deployments, hindering progress in fields like personalized medicine, autonomous systems, and scientific discovery where immediate and comprehensive analysis is crucial. The inability to efficiently run these complex algorithms effectively bottlenecks innovation and prevents the full realization of deep learning’s potential.
The Promise of Deliberate Absence
Deep neural networks, characterized by a large number of parameters, often exhibit substantial computational redundancy. This inefficiency stems from the fact that not all parameters contribute equally to the network’s predictive power. Sparsity addresses this by intentionally setting a significant percentage of these weights to zero. This reduction in active parameters directly translates to fewer multiply-accumulate operations during both training and inference. The computational cost of these operations dominates the processing time in deep learning, and their minimization is therefore critical for scalability and deployment on resource-constrained devices. Furthermore, storing zero-valued weights requires less memory, decreasing the overall model size and bandwidth requirements.
Reducing the number of active parameters through sparsity directly impacts computational efficiency. Dense neural networks require substantial memory to store all weights; a sparse network, with a significant proportion of weights set to zero, proportionally reduces this memory footprint. During both training and inference, computations are only performed on the non-zero weights. This selective computation translates to fewer multiply-accumulate operations, accelerating processing speed and reducing energy consumption. The magnitude of these gains is directly correlated to the achieved sparsity level; higher sparsity typically yields greater reductions in memory usage and faster processing, although excessive sparsity can negatively impact model accuracy.
Methods for achieving sparsity in deep networks broadly fall into several categories. Weight pruning techniques directly remove connections based on magnitude, often iteratively, and can be unstructured – removing individual weights – or structured – removing entire filters or channels. Regularization-based approaches, such as L1 regularization, encourage sparsity during training by adding a penalty proportional to the absolute value of the weights to the loss function. More recently, dynamic sparsity methods introduce sparsity during training and maintain it through techniques like gradient-based pruning or learned masks, while quantization-aware training can induce sparsity by effectively setting small weights to zero after quantization. The selection of a particular method depends on factors like the desired level of sparsity, hardware constraints, and the specific network architecture.
The Network in Flux: Adapting to the Inevitable
Fixed-Rate Rewiring establishes a foundational method for introducing dynamic sparsity into neural networks by systematically replacing a predetermined percentage of the network’s weights during training. This approach maintains a consistent level of sparsity throughout the learning process, offering a simple mechanism for regularization and potential computational efficiency. However, the performance of Fixed-Rate Rewiring is constrained by its inflexible nature; the fixed replacement rate may not be optimal for all stages of training or network configurations, potentially hindering the network’s ability to fully optimize its performance and leading to suboptimal results compared to more adaptive techniques.
Adaptive rewiring improves upon fixed-rate sparsity by modulating the frequency at which network weights are replaced during training. Instead of a constant fraction of weights being rewired, the rewiring rate is adjusted based on performance on a validation dataset; improvements in validation accuracy indicate a beneficial sparsity pattern and maintain or increase the rewiring rate, while declines trigger a reduction. This dynamic adjustment allows the network to learn an optimal sparsity configuration tailored to the specific task, effectively balancing network size and performance by prioritizing the retention of impactful connections and pruning less significant ones.
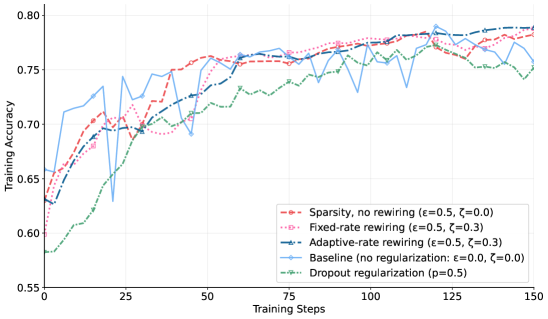
Implementation of dynamic rewiring, in conjunction with early stopping, has yielded a peak accuracy of 99% when evaluated on the N-1 contingency analysis dataset. This result signifies a substantial improvement in performance relative to fixed-rate rewiring and other sparsity-inducing techniques. The N-1 contingency analysis dataset, used for benchmarking, presents a challenging scenario for network robustness, and achieving near-perfect accuracy demonstrates the effectiveness of the adaptive rewiring process in maintaining performance during structural changes. The reported accuracy represents the highest achieved on this dataset using this methodology, indicating a significant gain in model reliability and predictive power.
The Illusion of Control: Sparsity and the Pursuit of Efficiency
Established regularization techniques like Dropout and sparsity, though both aimed at improving a model’s performance on unseen data, achieve this through distinct mechanisms. Dropout operates by randomly disabling neurons during training, effectively creating an ensemble of thinned networks and forcing the model to avoid over-reliance on any single neuron – a form of intentional redundancy. In contrast, sparsity directly addresses model complexity by minimizing the number of parameters, seeking to identify and eliminate less important connections within the network. This parameter reduction not only lowers computational costs but also promotes a more concise and potentially more interpretable model, differing fundamentally from Dropout’s approach of maintaining a full network with stochastic deactivation.
Distinct approaches to enhancing model efficiency are exemplified by dropout and sparsity techniques. Dropout functions by introducing stochasticity during training; it randomly disables neurons, compelling the network to develop robust feature representations and avoid over-reliance on any single neuron – essentially building redundancy. In contrast, sparsity directly addresses model complexity by actively minimizing the number of parameters. This is achieved by pruning connections or neurons, resulting in a smaller, more computationally efficient network without necessarily relying on redundant pathways. While both methods aim to improve generalization, dropout prioritizes robustness through redundancy, and sparsity focuses on direct model size and cost reduction, representing fundamentally different strategies for optimization.
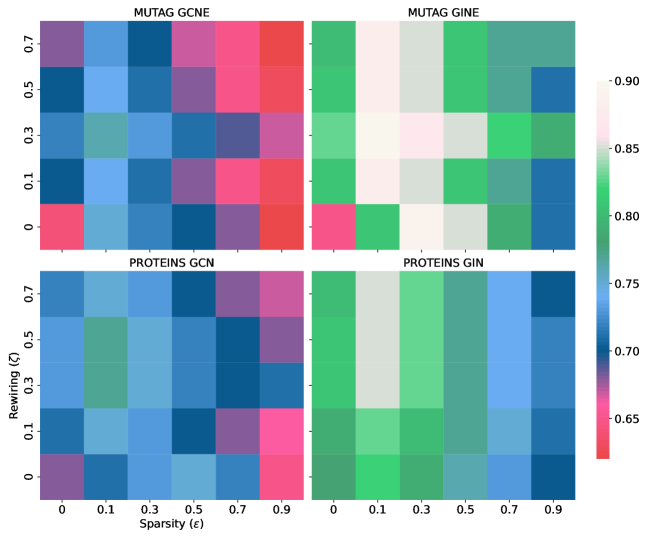
Recent investigations demonstrate that adaptive rewiring, when paired with early stopping techniques, yields compelling results in graph neural networks. Specifically, this combined approach achieves accuracies of 0.87 on the MUTAG dataset – a standard benchmark for molecular property prediction – and 0.90 on the PROTEINS dataset, indicating robust performance across diverse graph structures. Crucially, these high accuracy levels are not achieved at the expense of model complexity; the methodology simultaneously facilitates significant reductions in model parameters – by as much as 30% – through increased sparsity. This suggests a pathway towards more efficient and scalable graph neural networks, capable of maintaining predictive power while minimizing computational demands and storage requirements.
The pursuit of efficient and robust systems, as demonstrated by this exploration of adaptive rewiring in Graph Neural Networks, echoes a fundamental truth about complexity. It isn’t about imposing rigid structures, but fostering a capacity for graceful degradation and self-correction. As Carl Friedrich Gauss observed, “Few things are more deceptive than a simple solution.” The researchers’ approach – introducing sparsity and allowing the network to rewire connections – embodies this sentiment. It acknowledges that a system’s strength doesn’t lie in preventing failure, but in its ability to tolerate it, much like a power grid maintaining stability even with N-1 contingency events. The network, like a garden, adapts and evolves, pruning what is unnecessary and reinforcing what remains vital.
What Lies Ahead?
The pursuit of sparsity in Graph Neural Networks, as demonstrated by this work, feels less like engineering and more like tending a garden. Pruning and rewiring aren’t about achieving a static optimum; they are acts of controlled demolition, anticipating future overgrowth. Scalability is, after all, just the word used to justify complexity. The gains made in efficiency on benchmarks and power grid analysis are significant, but the true challenge isn’t minimizing computation-it’s preserving adaptability. Every optimized connection hardens the network against unforeseen circumstances.
The application to power grid reliability, while promising, highlights a fundamental tension. These networks model systems already built on layers of contingency planning. An N-1 contingency analysis finds weakness, but it doesn’t prevent failure – it prepares for it. To truly leverage these models, the focus must shift from prediction to proactive rewiring-allowing the network to learn not just from past failures, but to anticipate and avoid future ones.
The perfect architecture is a myth to keep people sane. The real path forward lies in embracing impermanence-designing networks that are not robust, but resilient-capable of continually reshaping themselves in response to an ever-changing world. This is not about building a better model; it’s about cultivating a system that can evolve beyond its initial design.
Original article: https://arxiv.org/pdf/2602.10754.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Gold Rate Forecast
- How to Solve the Glenbright Manor Puzzle in Crimson Desert
- How to Get to the Undercoast in Esoteric Ebb
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- 8 Actors Who Could Play Blackbeard In One Piece Live-Action Season 3
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- A Dark Scream Theory Rewrites the Only Movie to Break the 2-Killer Rule
- Love Story Recap: Gilded Cage
- Blind Tekken 8 player reaches one of the game’s highest ranks after two years of grinding
2026-02-12 20:57