Author: Denis Avetisyan
Researchers are leveraging the power of artificial intelligence to better understand economic choices by analyzing the underlying reasoning revealed in survey responses.
This paper introduces a framework utilizing large language models to extract latent economic mechanisms from survey instruments and validate them with out-of-sample econometric analysis, improving the quality and interpretability of economic measurement.
Traditional economic measurement from surveys often relies on pre-defined constructs, potentially obscuring nuanced behavioral drivers. This is addressed in ‘AI Assisted Economics Measurement From Survey: Evidence from Public Employee Pension Choice’, which introduces an iterative framework leveraging large language models to directly extract latent economic mechanisms from survey instruments. The approach maps survey responses to underlying constructs, validates this mapping with out-of-sample econometric tests, and identifies key semantic components driving choices-specifically, disentangling beliefs from constraints in retirement planning. Could this methodology offer a portable audit for survey design and unlock more robust and interpretable economic measurement across diverse contexts?
The Fragility of Measurement: Unraveling Conceptual Blending
Economic understanding is frequently built upon data gathered through survey instruments, questionnaires designed to quantify subjective states like consumer confidence or perceived financial well-being. However, a significant challenge arises from what is known as construct contamination – the tendency for a single survey question to inadvertently capture multiple, distinct concepts. This occurs because human experiences are rarely neatly compartmentalized; a question about ‘job satisfaction’, for instance, may simultaneously reflect feelings about salary, coworkers, and opportunities for advancement. Consequently, the measured response becomes a composite of these interwoven elements, obscuring the true underlying construct and introducing noise into economic analyses. This blending of concepts compromises the validity of economic measurement, potentially leading to inaccurate conclusions and flawed policy recommendations, and necessitates careful questionnaire design and advanced statistical techniques to disentangle these complex relationships.
The integrity of economic measurement hinges on the clarity with which it assesses intended concepts, yet construct contamination-the insidious blending of multiple ideas within a single measurement item-poses a significant threat. This occurs when a seemingly straightforward question inadvertently taps into several underlying constructs, obscuring the true signal of the intended variable. For example, a survey question aiming to measure ‘job satisfaction’ might simultaneously capture elements of ‘pay satisfaction’, ‘work-life balance’, and ‘perceptions of management’. Consequently, observed relationships between variables become muddied, statistical analyses yield unreliable results, and the validity of economic inferences is compromised. Addressing construct contamination requires meticulous item design, rigorous testing through techniques like factor analysis, and a nuanced understanding of the psychological processes underlying survey responses, ultimately ensuring that economic measurements accurately reflect the phenomena they intend to capture.
The interwoven nature of concepts within seemingly precise economic indicators introduces significant challenges to understanding genuine economic relationships. When a single measurement captures multiple, overlapping constructs, it becomes difficult to isolate the specific drivers of observed phenomena. This conceptual blending doesn’t simply add noise; it actively distorts the underlying signals, leading to spurious correlations and inaccurate interpretations. Consequently, policies informed by these contaminated measures may prove ineffective, or even counterproductive, as they address symptoms rather than root causes. The resulting analytical difficulties demand increasingly sophisticated methodological approaches to disentangle these complex interactions and achieve a more nuanced understanding of economic realities, requiring researchers to move beyond simple observation toward rigorous identification strategies.
Mapping the Semantic Landscape: LLMs and Taxonomy Induction
Large Language Models (LLMs) are employed to conduct semantic analysis of survey items, a process that extends beyond simple keyword matching or syntactic parsing. This involves utilizing the LLM’s contextual understanding to determine the underlying meaning and relationships within each item’s text. Specifically, LLMs are able to identify synonyms, understand nuanced phrasing, and resolve ambiguity, allowing for a deeper comprehension of the concepts being measured. This capability enables the system to move past surface-level interpretations and discern the semantic content of each item, even when expressed using different vocabulary or sentence structures. The resulting semantic representations are then used as input for subsequent taxonomy induction processes.
Taxonomy induction, facilitated by semantic analysis of survey items, generates a hierarchical classification structure. This process moves beyond simple categorization by establishing relationships between items based on shared underlying meaning, not just superficial keyword matches. The resulting taxonomy represents a multi-level organization where broader concepts are broken down into increasingly specific subcategories. This allows for a nuanced understanding of complex constructs and facilitates the identification of distinct dimensions within them, enabling more granular analysis and interpretation of survey data. The hierarchical structure is typically represented as a tree-like diagram, visually demonstrating the relationships between concepts and their subcomponents.
Automated identification of conceptual boundaries facilitates the decomposition of complex constructs into discrete subdimensions through analysis of semantic relationships. This process involves computationally delineating the limits of each concept within a construct, enabling its division into logically separate and measurable components. The resulting subdimensions represent more focused and specific facets of the original construct, improving analytical precision and reducing the potential for construct ambiguity. This decomposition allows for a more granular understanding of the construct and supports more targeted measurement and interpretation, moving beyond holistic assessments to isolate specific contributing factors.
Validating the Architecture: Item Mapping and Response Harmonization
Item-to-Subdimension Mapping is a weighted process used to establish the relationship between individual survey or test items and the underlying subdimensions they are designed to measure. Each item receives a weight, quantitatively representing its relevance to a particular subdimension; higher weights indicate a stronger conceptual link. This mapping is not necessarily binary – an item can contribute to multiple subdimensions, albeit with varying weights – and is determined through a combination of theoretical justification and empirical analysis, such as factor loadings or expert review. The resulting weights are critical inputs for calculating subdimension scores, ensuring that each item’s contribution accurately reflects its alignment with the construct being measured.
Response Harmonization is a critical step in converting raw survey or assessment data into a standardized format suitable for quantitative analysis. This process addresses the inherent heterogeneity of responses, which may include categorical selections, Likert scale ratings, and free-text entries. Through predefined algorithms and scoring rules, these diverse response types are translated into a unified numeric representation – typically a scale ranging from 0 to 1 or a similar normalized range. This conversion allows for aggregation of data across different items and respondents, enabling statistical modeling and comparative analysis. The specific algorithms employed within Response Harmonization are determined by the nature of the original data and the desired properties of the unified scale, with careful consideration given to maintaining data integrity and minimizing information loss.
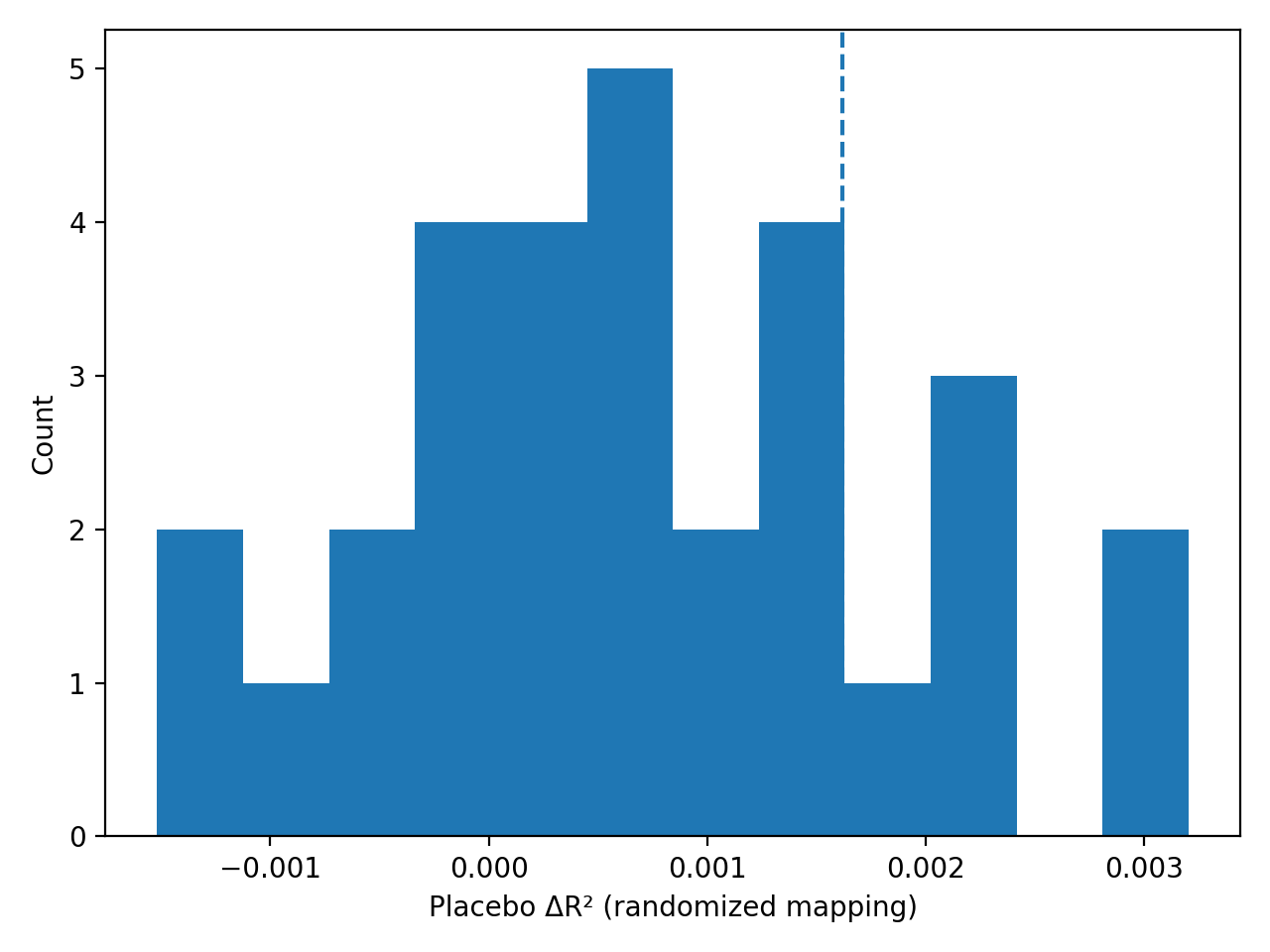
Econometric validation procedures, specifically utilizing incremental validity assessments, were employed to confirm the quality and reliability of the defined constructs. Analysis revealed that the inclusion of financial literacy as a distinct subdimension resulted in incremental gains in Area Under the Curve (AUC) of up to 0.082. This statistically significant improvement demonstrates that incorporating financial literacy provides additional predictive power beyond existing constructs, validating its importance as a separate and measurable dimension within the overall model.
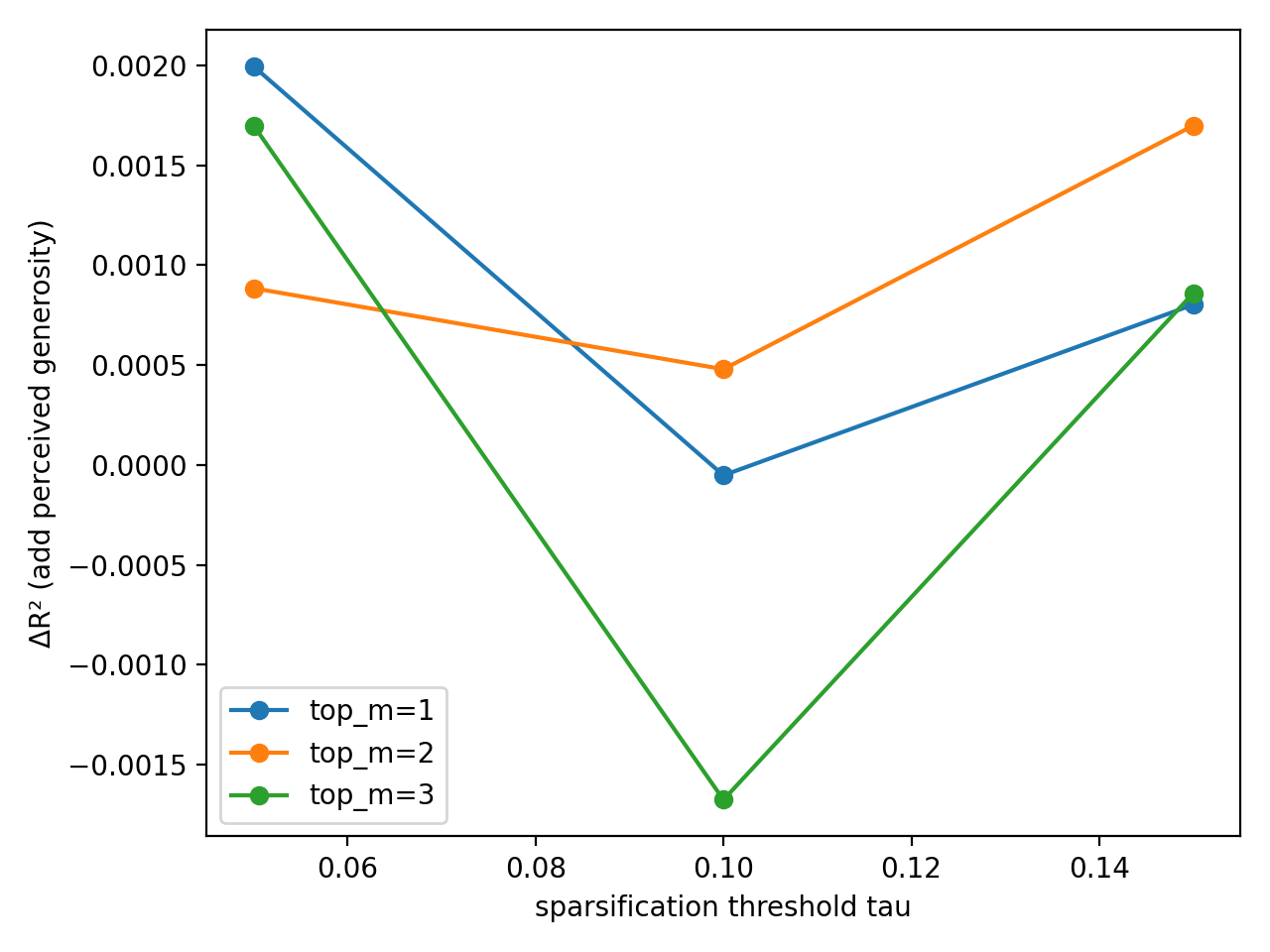
Precision in Foresight: Refining Retirement Valuation
Pension valuation often suffers from an inability to isolate the true drivers of retirement preparedness, as financial literacy and pension plan type-specifically, the contrast between defined benefit and defined contribution plans-are frequently intertwined. This research addresses this limitation through a refined methodology that statistically disentangles these influences, allowing for a more precise assessment of an individual’s financial standing at retirement. By separately examining the effects of cognitive financial skills and the structural characteristics of the pension itself, the analysis yields a clearer picture of how each factor contributes to overall retirement wealth. This granular approach not only improves the accuracy of individual pension valuations, but also provides valuable insights for policymakers seeking to design more effective retirement savings programs and address systemic inequities in wealth accumulation.
Retirement decision-making is significantly shaped by the presence of lock-in mechanisms within pension plans, and recent analysis demonstrates the particularly strong influence of service tenure requirements. These mechanisms, which tie benefits to years of employment, exhibit a substantial predictive power regarding an individual’s retirement timing and accumulated wealth; the study revealed incremental gains in discriminatory power, as measured by the Area Under the Curve (AUC), reaching up to 0.114 when incorporating service tenure lock-in into predictive models. This finding suggests that policies aimed at enhancing retirement security should carefully consider the implications of these lock-in effects, potentially adjusting plan designs to mitigate unintended consequences or leveraging them to encourage longer-term savings. Understanding this dynamic offers valuable insights for policymakers seeking to optimize retirement systems and promote more informed financial planning.
Economic models assessing retirement preparedness often conflate financial understanding with the structural elements of pension plans, leading to imprecise valuations and potentially flawed policy. Recent analysis demonstrates that disentangling these factors-specifically, isolating the impact of service tenure lock-in mechanisms-significantly enhances model accuracy. Researchers found an incremental increase of 0.0089 in the R-squared value when modeling required contribution rates, indicating a substantially improved capacity to explain variance in retirement savings behavior. This refinement minimizes construct contamination, bolstering the reliability of predictions and offering policymakers a more robust foundation for crafting effective retirement strategies and informed financial regulations.
The pursuit of robust economic measurement, as detailed in the study, inherently grapples with the decay of information fidelity over time. Just as a system’s chronicle – logging, in this case – requires constant validation, so too must survey instruments be rigorously tested for construct validity. This mirrors John Locke’s observation: “No man’s knowledge here can go beyond his experience.” The paper’s methodology, employing large language models for semantic analysis and out-of-sample validation, effectively seeks to ground economic understanding in empirically verifiable experience, ensuring that measurements don’t drift from the realities they aim to capture. The timeline of data collection and analysis, therefore, isn’t simply a record of events, but a continuous process of refinement and verification.
What Lies Ahead?
The pursuit of economic measurement, even when aided by large language models, ultimately encounters the inevitable friction of real-world systems. This work demonstrates a path toward extracting latent mechanisms from survey data, but the true test isn’t merely identifying those mechanisms – it’s understanding how gracefully they decay over time. The field will likely move beyond validation through out-of-sample econometrics, towards longitudinal studies that trace the lifespan of these extracted constructs. Systems learn to age gracefully, or they don’t.
A crucial limitation remains the inherent subjectivity embedded within the training data of these models. Language reflects consensus, not necessarily truth. Future research should explore methods for quantifying and mitigating this bias, perhaps through adversarial training or the incorporation of alternative knowledge sources. The focus should shift from simply measuring economic phenomena to understanding the conditions that allow for resilient and interpretable measurement.
Perhaps, at some point, the effort will not be to refine the instruments, but to accept the inherent noisiness of the signal. Sometimes observing the process of decay – the way measurement itself shifts and adapts – is more valuable than attempting to accelerate it towards an idealized, but ultimately unattainable, precision. The aim shouldn’t be to solve economic measurement, but to map its evolution.
Original article: https://arxiv.org/pdf/2602.02604.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Mewgenics vinyl limited editions now available to pre-order
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
- Viral Letterboxd keychain lets cinephiles show off their favorite movies on the go
- Zero Parades – For Dead Spies is launching on May 21 for PC and it will be Steam Deck Verified
- How do you Fast Travel in Crimson Desert?
2026-02-05 05:35