Author: Denis Avetisyan
A new approach leverages the power of large language models and real-time notebook data to pinpoint and understand crashes in machine learning code.

CRANE-LLM augments language models with runtime information to improve crash detection and diagnosis in ML notebooks.
Despite the widespread adoption of Jupyter notebooks for iterative machine learning development, they remain surprisingly prone to runtime crashes that hinder experimentation. This paper introduces CRANE-LLM, a novel approach for detecting and diagnosing these crashes by augmenting large language models with structured runtime information extracted from the notebook’s kernel state. Our experiments demonstrate that integrating this runtime context improves crash prediction and root cause analysis by 7-10 percentage points in accuracy across multiple state-of-the-art LLMs and ML libraries. How can we further leverage runtime insights to build more robust and self-debugging machine learning environments?
Unmasking the Silent Failures Within Machine Learning
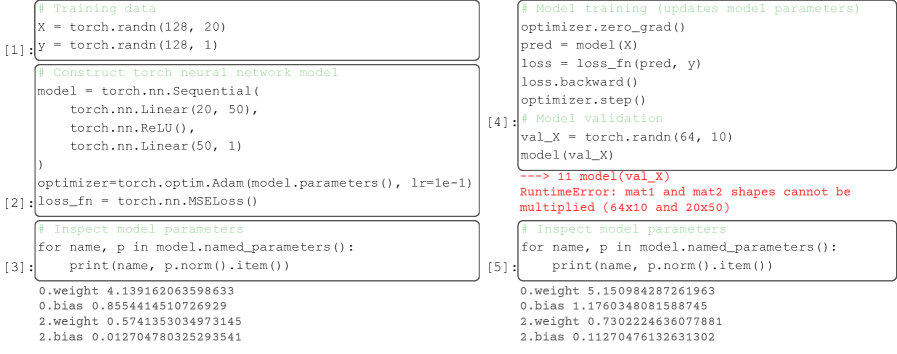
The foundation of any machine learning model is built upon carefully constructed data structures – lists, dictionaries, tensors, and more – yet subtle errors within these structures frequently escape detection during the training phase. These runtime errors, often manifesting as incorrect data types, mismatched dimensions, or out-of-bounds access, can propagate silently through the model, leading to inaccurate predictions only revealed upon deployment in real-world scenarios. The resulting costs extend beyond mere financial implications; flawed models can damage reputations, erode user trust, and necessitate costly rework, highlighting the critical need for robust error detection mechanisms throughout the entire machine learning lifecycle. Addressing these ‘silent errors’ is paramount to ensuring the reliability and responsible application of increasingly complex machine learning systems.
The increasing complexity of machine learning workflows, particularly within interactive notebook environments, often renders traditional debugging techniques inadequate. These environments encourage iterative experimentation and rapid prototyping, leading to deeply nested code and intricate data dependencies that obscure the origins of runtime errors. Standard debuggers struggle to effectively trace execution paths and inspect the state of variables across multiple cells and kernel sessions. Consequently, subtle errors-such as incorrect data types, unexpected null values, or logic flaws in data transformations-can propagate silently through a pipeline, ultimately leading to inaccurate model predictions or deployment failures. This is further complicated by the transient nature of notebook sessions and the difficulty in reproducing specific error states, making proactive error detection a substantial challenge for data scientists.
Data scientists face a significant hurdle in preventing errors not because of a lack of tools, but due to the inherent difficulty in observing the internal workings of the Notebook Kernel State. This kernel, the runtime environment for code execution within a notebook, maintains a complex and often hidden state encompassing variables, data structures, and dependencies. Unlike traditional debugging scenarios where memory and variables are readily inspectable, the notebook environment obscures this crucial information. This opacity makes it exceedingly difficult to proactively identify potential errors – such as data corruption or unexpected type conversions – before they manifest as failures during training or, more critically, after deployment. The result is a reliance on reactive debugging, where issues are discovered only when a model produces incorrect results, leading to costly rework and potential real-world consequences. Addressing this challenge requires new approaches to kernel introspection and state visualization, enabling data scientists to move beyond simply fixing errors to preventing them in the first place.
Decoding Runtime: Revealing the Seeds of Failure
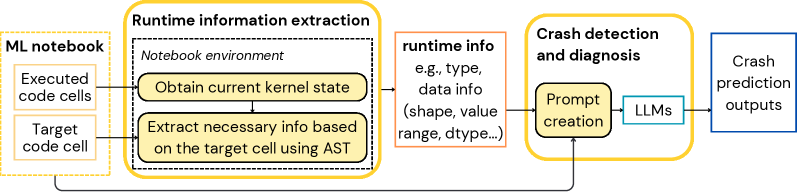
Runtime Information Extraction serves as the initial step in preemptive crash detection by systematically collecting data generated during notebook execution. This data encompasses details about the operations performed, the resources utilized, and the state of variables throughout the notebook’s lifecycle. Specifically, the extraction process focuses on capturing dynamic attributes that are not available through static analysis, such as the dimensions of tensors at runtime, the values of variables during specific operations, and the call stack at various execution points. The collected information forms the basis for identifying potential issues, like out-of-bounds access, type errors, or resource exhaustion, before they manifest as crashes, enabling proactive intervention and improved application stability.
Runtime Information Extraction encompasses the capture of three core data types to comprehensively characterize notebook execution state. Structural Runtime Information details the organization and relationships between code elements, such as function calls and control flow. Type/Representation Runtime Information focuses on the data types and internal representations of variables and objects during execution, including details like object shapes and memory layouts. Finally, Value-based Runtime Information captures the actual values held by variables and data structures at specific points in the notebook’s execution. The combination of these three categories provides a complete picture of the runtime environment, enabling detailed analysis and prediction of potential issues.
Analyzing Structural, Type/Representation, and Value-based Runtime Information allows for the identification of potential failure points before execution completes. This contrasts with traditional reactive debugging, which addresses errors only after they occur. By establishing a baseline of expected runtime characteristics and monitoring deviations, the system can flag anomalous behavior indicative of an impending crash. These anomalies may include unexpected type changes, out-of-bounds data access, or the propagation of invalid values. The resulting proactive approach enables intervention – such as halting execution or triggering corrective actions – minimizing runtime errors and improving overall notebook reliability.
CRANE-LLM: Anticipating Failure with Intelligence
CRANE-LLM employs Large Language Models (LLMs) for crash detection, operating prior to runtime error manifestation to enable preventative debugging. This contrasts with traditional reactive debugging methods which address errors after they occur. The LLM analyzes code to identify potential error-causing patterns and predicts crashes before execution, allowing developers to address vulnerabilities proactively. This predictive capability is achieved through the LLM’s ability to understand code semantics and identify potentially problematic code constructs, effectively shifting the debugging paradigm from post-incident analysis to pre-emptive error prevention.
CRANE-LLM incorporates LLM-based Crash Diagnosis to provide developers with explanations for predicted runtime errors. This diagnosis functionality goes beyond simple error detection by analyzing the code and execution context to identify the root cause of potential crashes. The system outputs a textual explanation detailing the identified issue, allowing developers to understand why a crash is predicted and facilitating targeted code revisions. This diagnostic output is designed to be actionable, providing specific insights into the problematic code section and the nature of the anticipated failure, thereby reducing debugging time and improving code quality.
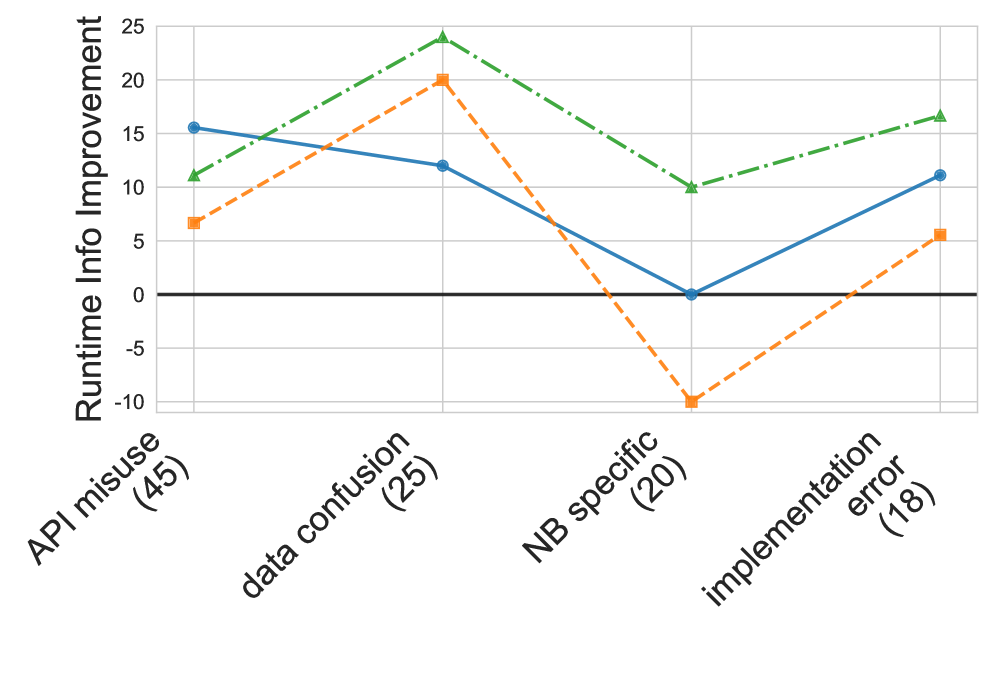
Evaluation of CRANE-LLM’s proactive crash prediction and diagnosis capabilities was performed using the JunoBench dataset, comprising 111 machine learning notebooks. Results indicate a performance improvement of up to 9.3% in F1-score when utilizing runtime information, alongside an accuracy improvement ranging from 7.2% to 9.4%. Further validation involved human assessment of the diagnoses generated by the framework, which yielded a Cohen’s Kappa score of 0.89, demonstrating a high degree of agreement between the LLM-generated explanations and human expert evaluations.
Towards a Robust Machine Learning Future
The efficiency of machine learning development hinges on swift identification and resolution of errors, and early crash detection systems significantly accelerate this process. By pinpointing the exact location of code failures during execution – rather than surfacing ambiguous errors after lengthy computations – developers can drastically reduce debugging time. This proactive approach not only streamlines the workflow but also fosters a more robust final model; errors identified and addressed early are less likely to cascade into larger, more complex issues affecting overall performance and reliability. The ability to quickly isolate and rectify problems allows for more iterative experimentation and refinement, ultimately leading to higher-quality machine learning solutions.
CRANE-LLM fundamentally shifts machine learning development from a reactive to a proactive stance, cultivating a system built on reliability and trust. Rather than identifying errors post-execution, the framework anticipates and flags potential issues during the model building process itself. This preemptive error handling minimizes the propagation of flawed code, reducing debugging cycles and bolstering the overall integrity of the resulting models. By consistently delivering stable and predictable outcomes, CRANE-LLM empowers developers to confidently deploy machine learning solutions across critical applications, fostering greater faith in the technology and accelerating innovation in fields like finance, healthcare, and autonomous systems.
The proactive error detection offered by this system extends beyond mere debugging convenience, promising substantial efficiency gains for machine learning-driven industries. Sectors like finance, where algorithmic trading relies on consistently functioning models, healthcare, where diagnostic tools demand unwavering accuracy, and autonomous systems, where safety is paramount, all stand to benefit from reduced downtime and faster iteration cycles. Detailed analysis indicates a significant time savings – approximately 1103 seconds – achievable by preventing unnecessary kernel restarts and re-executions, translating directly into accelerated development, reduced operational costs, and ultimately, more reliable and trustworthy machine learning applications across a diverse range of critical fields.
The pursuit of robust machine learning systems necessitates a willingness to dissect and understand failure. This research, introducing CRANE-LLM, embodies that principle by actively seeking out the points of breakage within notebook environments. It’s a calculated deconstruction, leveraging runtime information to illuminate the ‘why’ behind crashes-an exploit of comprehension, if you will. Grace Hopper famously said, “It’s easier to ask forgiveness than it is to get permission.” This sentiment resonates deeply with the work; CRANE-LLM doesn’t simply prevent errors, it actively probes for them, gaining deeper insight through controlled ‘failure’ and extracting valuable diagnostic data from the kernel’s state – essentially, asking forgiveness for the controlled crashes in the name of improved debugging.
Beyond the Crash Report
The augmentation of Large Language Models with runtime data, as demonstrated by CRANE-LLM, isn’t merely a diagnostic improvement; it’s a subtle admission that current LLM reasoning abilities, while impressive in their mimicry of understanding, remain fundamentally detached from actual system states. The system doesn’t know why the code failed; it correlates symbols with observed effects. This is, of course, how all comprehension begins – with pattern recognition, not innate truth. The next iteration won’t be about perfecting the correlation, but about actively probing the system, constructing counterfactuals, and deliberately inducing failures to map the state space.
A persistent limitation lies in the nature of ‘structured runtime information’ itself. Kernels are black boxes, and the data extracted represents only a fraction of the underlying complexity. Future work must address the challenge of incomplete observability – of inferring hidden states and latent variables. One could envision systems that not only detect crashes but actively search for instabilities, preemptively patching vulnerabilities before they manifest.
Ultimately, the goal isn’t better debugging, but a more complete reverse-engineering of the machine learning process itself. The ability to diagnose a crash is simply a byproduct of truly understanding how a notebook functions-its inputs, its transformations, and its ultimate, often unpredictable, outputs. The real challenge lies in moving beyond symptom analysis to systemic comprehension.
Original article: https://arxiv.org/pdf/2602.18537.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Mewgenics vinyl limited editions now available to pre-order
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
- Viral Letterboxd keychain lets cinephiles show off their favorite movies on the go
- Does Mark survive Invincible vs Conquest 2? Comics reveal fate after S4E5
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- Crimson Desert Guide – How to Pay Fines, Bounties & Debt
2026-02-25 03:42