Author: Denis Avetisyan
A new language model, FiMI, is being developed to better understand and operate within the unique complexities of India’s financial landscape.
This paper details the development of FiMI, a domain-specific language model for the Indian financial ecosystem, achieving performance gains through supervised fine-tuning and focusing on operational efficiency.
While large language models demonstrate broad capabilities, their performance often lags in specialized domains requiring nuanced understanding and tool utilization. This paper introduces ‘FiMI: A Domain-Specific Language Model for Indian Finance Ecosystem’, a novel language model designed to address the unique challenges of India’s digital payment landscape. Through a multi-stage training process-including pre-training on 68 billion tokens of financial and multilingual data-FiMI achieves significant gains in finance reasoning and tool-calling proficiency, outperforming comparable models by up to 87%. Could this approach, prioritizing supervised fine-tuning and operational workflows, represent a paradigm shift in building effective language-based agents for complex financial systems?
The Illusion of Expertise: Why LLMs Still Need a Human Touch
Despite their impressive ability to generate human-quality text and perform various language-based tasks, Large Language Models frequently stumble when applied to specialized fields like financial analysis. These models, trained on vast datasets of general text, often lack the deep contextual understanding and precise reasoning capabilities required to interpret complex financial data, regulatory filings, or market trends. While proficient at identifying patterns in language, they may misinterpret nuanced terminology, fail to account for industry-specific conventions, or struggle with the probabilistic reasoning crucial for accurate forecasting and risk assessment. This limitation underscores the need for models specifically adapted to the intricacies of particular domains, ensuring reliable and insightful results beyond broad linguistic competence.
Large language models, despite their impressive ability to generate human-quality text, frequently stumble when confronted with tasks demanding specialized knowledge. This limitation stems from their training on vast, generalized datasets, which, while broad, lack the depth required for nuanced understanding within specific fields. Consequently, these models often struggle with domain-specific reasoning – accurately interpreting information, drawing logical conclusions, and making informed predictions within a particular industry or area of expertise. This gap between general proficiency and specialized competence significantly hinders their practical application, as reliable performance necessitates a level of contextual awareness that generalized training simply cannot provide. Without focused adaptation, the potential of these powerful tools remains largely unrealized in sectors requiring precision and in-depth understanding.
Large language models, while exhibiting impressive versatility, achieve true utility when tailored to the intricacies of particular industries. Adapting these models moves beyond generic text processing and enables specialized reasoning capabilities; this is accomplished through techniques like fine-tuning with domain-specific datasets and incorporating industry-specific knowledge graphs. Such customization allows the models to not only understand the unique terminology and conventions of a field, but also to apply that understanding to complex tasks, ultimately unlocking their full potential for practical application and delivering more accurate, reliable, and insightful results. The process transforms a broadly capable tool into a focused expert, capable of addressing nuanced challenges within a defined area of expertise.
The financial sector poses a uniquely demanding test case for large language model specialization. Beyond common language intricacies, it operates with a dense lexicon of specialized terms – from complex derivatives to nuanced accounting principles – and is governed by a constantly evolving web of regulations like Dodd-Frank and Basel III. Successfully navigating this landscape requires not just linguistic proficiency, but also a deep understanding of financial principles, risk management, and legal compliance. However, the potential rewards are substantial; a properly adapted LLM can automate tasks like fraud detection, regulatory reporting, and investment analysis with unprecedented speed and accuracy, ultimately driving efficiency and innovation within the financial industry. This makes finance an ideal, though challenging, proving ground for unlocking the true capabilities of specialized large language models.
FiMI: A Pragmatic Approach to Domain-Specific AI
FiMI utilizes a focused development strategy by building upon the Mistral Small 24B Base model, a pre-trained large language model. This approach avoids de novo LLM creation, instead adapting existing general language capabilities to the financial domain. Leveraging a foundational model like Mistral Small 24B provides inherent advantages in language understanding, grammatical correctness, and contextual awareness. Subsequent training and fine-tuning then specialize these capabilities for financial applications, reducing the computational resources and data requirements typically associated with training an LLM from scratch. This method allows for faster development cycles and efficient resource allocation while maintaining a high level of linguistic proficiency.
The National Payments Corporation of India (NPCI) initiated and led the development of the Financial Inclusion Model for AI (FiMI). This strategic direction ensures the model is specifically tailored to the unique requirements and complexities of the Indian financial sector. NPCI’s involvement guarantees FiMI’s compatibility with existing Indian financial infrastructure, regulatory frameworks, and data standards. By directly addressing the needs of the Indian market, NPCI aims to foster innovation and broaden access to financial services through AI-driven applications, leveraging their position as the central organization operating India’s retail payment systems and settlement infrastructure.
FiMI’s architecture prioritizes interoperability with the Unified Payments Interface (UPI), India’s widely adopted real-time payment system. This integration allows FiMI to directly access and process UPI transaction data, facilitating applications such as fraud detection, risk assessment, and personalized financial recommendations within the UPI ecosystem. The design enables the development of AI-powered services for bill payments, peer-to-peer transfers, and merchant payments, all leveraging the speed and accessibility of UPI. Furthermore, FiMI’s UPI connectivity supports the creation of conversational AI agents capable of handling financial transactions and providing customer support directly through UPI-linked applications.
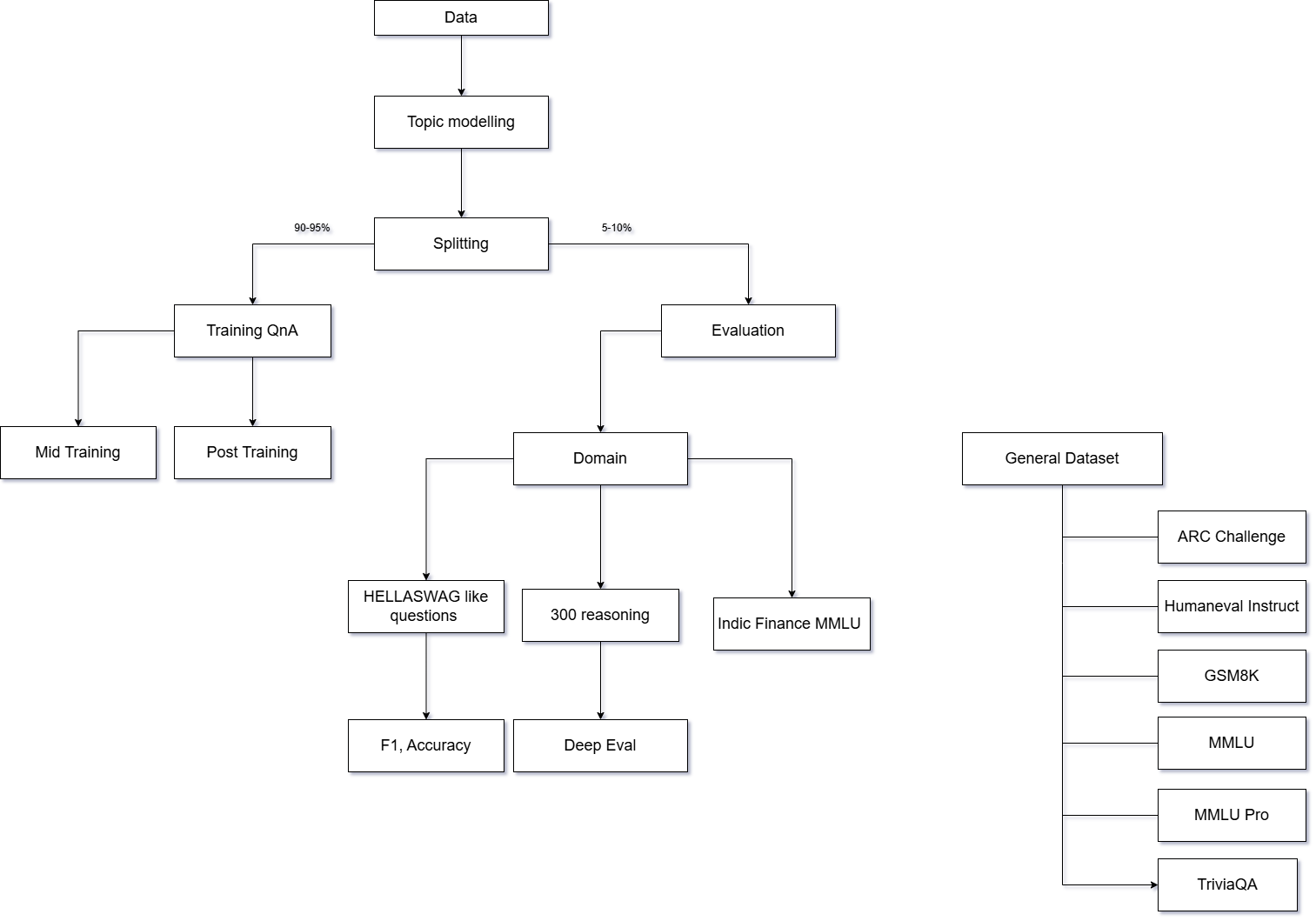
The FiMI model’s performance is driven by a two-stage training pipeline. Initial Continuous Pre-Training leverages a large corpus of financial text data to refine the base Mistral Small 24B model’s understanding of financial terminology and concepts. This is followed by Instruction/Supervised Fine-Tuning, where the model is trained on a curated dataset of financial tasks and instructions, optimizing it for specific applications. This process yields measurable improvements in key metrics, including accuracy on financial question answering, transaction fraud detection, and the ability to generate compliant financial reports. The pipeline is designed for iterative refinement, allowing for ongoing model improvement as new data becomes available.
UPI Help: A Demonstration of FiMI’s Practical Application
UPI Help represents a practical deployment of the FiMI framework, functioning as an agentic support system specifically designed for users of the Unified Payments Interface (UPI) platform. This implementation provides automated assistance with common UPI-related tasks, leveraging multiple specialized agents to address user queries and facilitate operations. Unlike traditional chatbot systems, UPI Help employs an agentic approach, enabling it to autonomously utilize tools and resources to resolve issues, thereby offering a more comprehensive and efficient support experience directly within the UPI ecosystem. This real-world application serves as a demonstration of FiMI’s capabilities in a live, customer-facing environment.
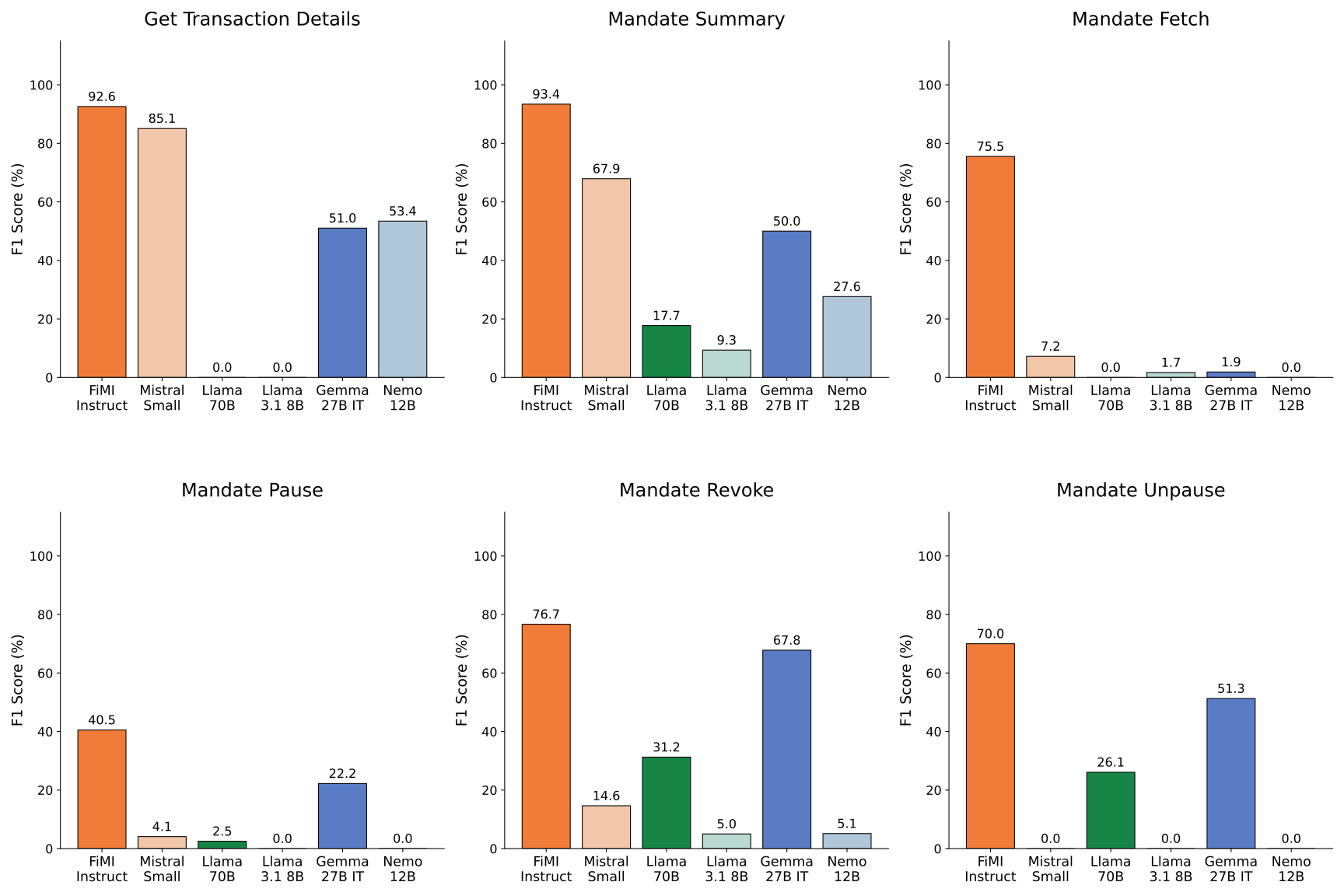
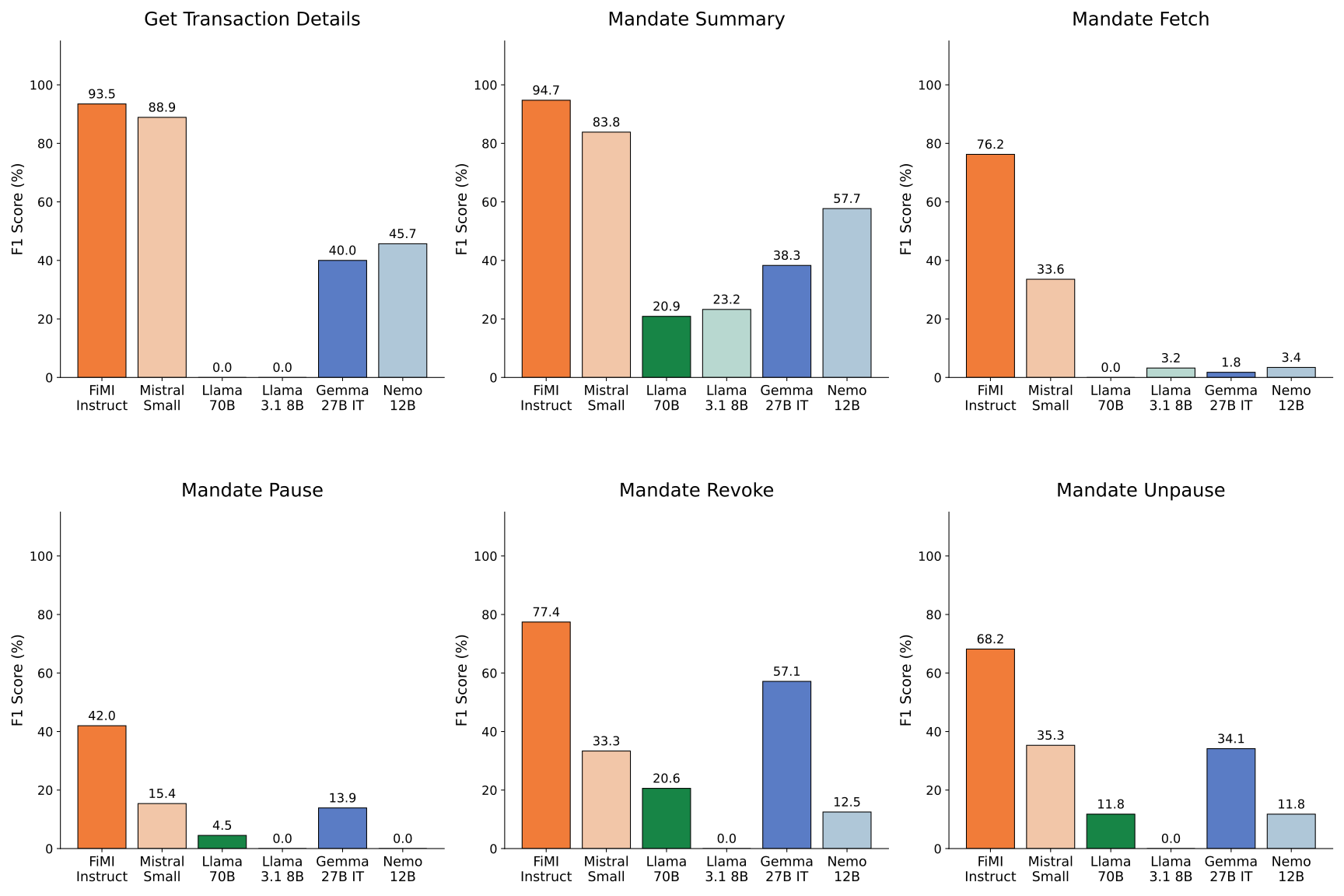
UPI Help leverages tool calling capabilities to automate and improve the accuracy of mandate operations within the UPI platform. Specifically, the system achieves a 76.24% success rate in completing these operations. This performance represents a significant improvement over the base model, which lacks the ability to utilize external tools for task completion. Tool calling allows the system to access and interact with necessary APIs and data sources to accurately process and fulfill user requests related to mandates, such as creation, modification, or cancellation.
UPI Help employs a Model Context Protocol and Swarm Architecture to deliver comprehensive customer support by coordinating multiple specialized agents. This architecture moves beyond a single, monolithic model; instead, distinct agents are assigned specific tasks, such as mandate verification or transaction inquiries. The Model Context Protocol governs the exchange of information between these agents, ensuring each has access to the necessary data to perform its function. This coordinated approach allows UPI Help to address a wider range of customer issues than would be possible with a single model, improving both efficiency and the quality of support provided. Each agent operates within a defined scope, contributing to a more robust and scalable support system.
Evaluations demonstrate FiMI’s robust safety alignment capabilities. The system achieves a 90% safety score utilizing minimal prompting techniques, indicating a high degree of responsible AI behavior. This is a significant improvement over the unprompted model, which registered a 0% safety score. Furthermore, FiMI exhibits a 90% block rate against potentially unsafe queries, effectively preventing the generation of harmful responses, compared to a 0% block rate without prompting. These metrics indicate that FiMI, even with limited guidance, consistently prioritizes safe and responsible outputs.
Beyond the Benchmarks: Assessing FiMI’s True Impact
Rigorous model evaluation forms a cornerstone of FiMI’s development, employing established benchmarks such as the Massive Multitask Language Understanding (MMLU) dataset to gauge its capacity for general knowledge and complex reasoning. This process moves beyond simple accuracy metrics, probing FiMI’s ability to synthesize information and apply it to diverse challenges across a spectrum of subjects-from history and law to mathematics and engineering. By systematically assessing performance on MMLU, researchers can pinpoint areas where the model excels and identify those requiring further refinement, ultimately ensuring FiMI’s reliability and trustworthiness before deployment in critical applications.
To rigorously evaluate FiMI’s performance, researchers implemented an innovative judging system utilizing open-source large language models, specifically GPT-OSS-120B. This approach moves beyond subjective human evaluation by leveraging the capabilities of a powerful AI to objectively assess the quality and accuracy of FiMI’s generated outputs. The open-source nature of the judging model ensures transparency and reproducibility of the evaluation process, while its substantial parameter count allows for nuanced and comprehensive assessments. By employing an AI judge, the team aimed to establish a reliable benchmark for FiMI’s reasoning and knowledge, providing a consistent and scalable method for measuring its capabilities and tracking improvements over time.
FiMI’s development strategically incorporates extensive datasets, notably Smoltalk2, to substantially bolster its reasoning prowess. This dataset, rich in complex logical structures and nuanced conversational examples, provides the model with a robust foundation for understanding and generating coherent, reasoned responses. The training process doesn’t simply focus on memorization; instead, exposure to Smoltalk2 allows FiMI to discern underlying patterns in argumentation and problem-solving. Consequently, the model demonstrates an enhanced capacity for tasks requiring inference, deduction, and the application of logical principles, moving beyond superficial pattern matching towards genuine reasoning capabilities. This data-driven approach is pivotal in enabling FiMI to tackle increasingly complex challenges within specialized domains and contribute to more reliable, intelligent systems.
FiMI’s demonstrated aptitude for specialized tasks, coupled with a substantial decrease in the computational cost associated with prompt processing-achieved through Supervised Fine-Tuning-represents a pivotal advancement in the practicality of domain-specific language models. This reduction in ‘prompt token overhead’ not only lowers operational expenses but also facilitates the deployment of these models in resource-constrained environments. Consequently, FiMI’s success extends beyond theoretical capabilities, offering a viable pathway for integrating sophisticated language processing into critical sectors like finance, where precision and efficiency are paramount, and signaling a broader potential for tailored AI solutions across diverse industries.
The pursuit of specialized models, as evidenced by FiMI’s focus on the Indian financial ecosystem, feels less like innovation and more like acknowledging inevitable entropy. Everything optimized will one day be optimized back. This isn’t a failure of design, but a recognition that even the most carefully constructed architectures are, at their core, compromises that survived deployment. The paper highlights performance gains through supervised fine-tuning, sidestepping the allure of prompt engineering as a primary solution. It’s a pragmatic approach; a silent admission that chasing elegance often yields to the brutal realities of production. One might even say, architecture isn’t a diagram, it’s a compromise. As Vinton Cerf observed, “Any sufficiently advanced technology is indistinguishable from magic,” but magic fades; what remains is the meticulous work of sustaining a system against the constant pull of decay.
So, What Breaks First?
The pursuit of domain-specific language models, as exemplified by FiMI, inevitably circles back to a familiar refrain: moving the goalposts. Performance gains achieved through supervised fine-tuning are, at best, temporary reprieves. The Indian financial landscape isn’t static; UPI integrations evolve, regulatory frameworks shift, and the edge cases-the truly interesting ones-will emerge only when placed in production. One anticipates a swift return to the familiar cycle of model drift and the urgent need for retraining, likely on data that was considered ‘synthetic’ just months prior.
The emphasis on operational efficiency over elaborate prompt engineering is… pragmatic. It suggests a healthy skepticism towards the ‘magic’ of large language models and a recognition that robust, scalable infrastructure is paramount. Still, it feels like trading one set of problems for another. A streamlined pipeline merely accelerates the arrival of the inevitable: the first real-world transaction that exposes a previously unseen vulnerability in the model’s understanding of financial nuance.
Ultimately, FiMI, and its successors, will be judged not by benchmark scores, but by the cost of its failures. Everything new is old again, just renamed and still broken. The real innovation won’t be in the model itself, but in the post-mortem analysis-the automated systems designed to detect, isolate, and mitigate the damage when, not if, things go wrong.
Original article: https://arxiv.org/pdf/2602.05794.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Mewgenics vinyl limited editions now available to pre-order
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Invincible Season 4 Episode 6 Release Date, Time, Where to Watch
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Crimson Desert Guide – How to Pay Fines, Bounties & Debt
- ‘Timur’ Trailer Sees Martial Arts Action Collide With a Real-Life War Rescue
2026-02-06 22:12