Author: Denis Avetisyan
A new approach uses artificial intelligence to automatically identify and categorize potential risks disclosed in company filings.
This paper details a system for taxonomy-aligned risk extraction from 10-K filings using large language models, semantic embeddings, and an LLM-as-a-judge validation loop for continuous improvement.
Extracting structured insights from the rapidly growing volume of corporate disclosures remains challenging due to the prevalence of unstructured text. This is addressed in ‘Taxonomy-Aligned Risk Extraction from 10-K Filings with Autonomous Improvement Using LLMs’, which introduces a novel methodology leveraging large language models, semantic embeddings, and an LLM-as-a-judge validation system to extract and categorize risk factors from 10-K filings with high precision. The approach not only achieves significant improvements in embedding separation-demonstrated by a 104.7\% gain in a case study-but also incorporates autonomous taxonomy maintenance for continuous refinement. Could this framework, capable of generalizing across domains, unlock new efficiencies in regulatory compliance and risk management through self-improving information extraction systems?
Decoding the Noise: Unveiling Hidden Risks in Corporate Disclosure
Corporate entities produce extensive textual disclosures, most notably in mandatory filings such as 10-K reports, creating a data deluge for investors and regulators alike. However, pinpointing genuinely critical risk factors within these documents presents a substantial hurdle. The sheer volume of text, often exceeding hundreds of pages, necessitates considerable time and resources for manual review, while the nuanced and often legally-laden language employed can obscure key threats. Identifying genuinely material risks – those that could significantly impact a company’s performance – requires not just reading the text, but also understanding its context and implications, a task proving increasingly difficult with the escalating complexity of modern business and regulatory landscapes. Consequently, automated approaches to risk factor extraction and analysis are gaining prominence as essential tools for navigating this complex information environment.
Analyzing corporate risk through traditional methods often proves inefficient due to the sheer volume of unstructured textual data contained within documents like 10-K filings. Manual review is incredibly time-consuming and prone to human error, while keyword searches frequently miss nuanced expressions of potential threats. Consequently, vital risk factors can be overlooked or miscategorized, leading to incomplete or inaccurate risk assessments. This limitation hinders investors, regulators, and the companies themselves from proactively addressing potential vulnerabilities and making informed decisions, particularly given the evolving and increasingly complex nature of modern business operations and the subtle ways in which risk can be communicated.
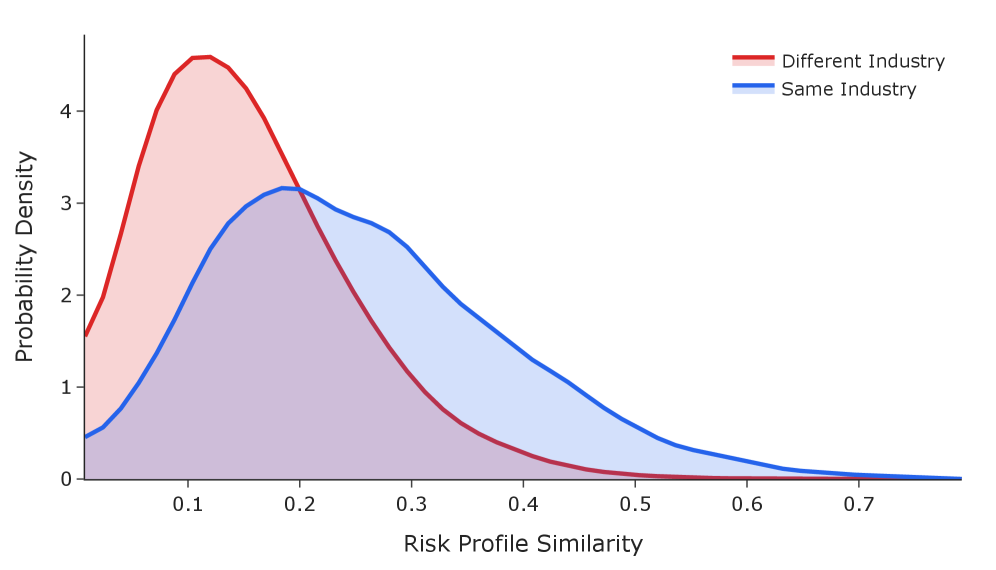
The escalating complexity of corporate filings demands innovative approaches to risk assessment. Companies now produce immense quantities of textual data detailing potential hazards, far exceeding the capacity of manual review. Recognizing this challenge, a novel automated system was developed to efficiently analyze these disclosures and identify key risk factors. Initial results demonstrate a significant capacity to discern nuanced risk profiles; the system consistently reveals 63% greater similarity in risk exposure among companies operating within the same industry, compared to those in disparate sectors. This heightened accuracy suggests the technology effectively captures industry-specific vulnerabilities, offering a valuable tool for investors, regulators, and corporate governance professionals seeking timely and precise risk intelligence.
Automated Extraction: Mapping Risk with Language Models
Large language models (LLMs) were utilized for the automated extraction of risk factors from financial disclosures. Processing 2024 filings from all S&P 500 companies (10-K forms), the LLM-based system successfully identified and validated 10,688 distinct risk factors. This automated approach eliminates the need for manual review of these documents, significantly reducing processing time and associated costs while providing a comprehensive dataset for risk analysis.
Extracted risk factors are systematically organized using a predefined Three-Tier Risk Taxonomy, a hierarchical structure designed to facilitate consistent and standardized categorization. This taxonomy enables quantitative and qualitative analysis of identified risks across different entities and reporting periods. The tiered approach allows for both broad risk grouping at the highest level and increasingly granular detail in subsequent tiers, supporting detailed risk assessments and comparative reporting. The implementation of this standardized taxonomy is critical for aggregating risk data, identifying emerging trends, and supporting consistent risk modeling and mitigation strategies.
Embedding-Based Mapping leverages vector representations of both extracted risk factors and predefined taxonomy categories to determine semantic similarity. Each risk factor and taxonomy category is converted into a high-dimensional vector embedding using a pre-trained language model. The cosine similarity between the embedding of an extracted risk and the embeddings of each taxonomy category is then calculated; the category with the highest similarity score is assigned as the best match. This approach avoids reliance on keyword matching or rule-based systems, enabling the identification of risks expressed using varied language but conveying similar meaning to established taxonomy definitions. The resulting mapping facilitates standardized categorization and quantitative analysis of extracted risk data.
Validating the Machine: Ensuring Alignment with Semantic Precision
LLM Validation is implemented to quantitatively assess the fidelity of risk mapping by calculating a semantic match score between identified risks and pre-defined taxonomy categories. This process leverages Large Language Models to determine the degree of conceptual overlap, providing a numerical value that indicates how well each extracted risk aligns with its assigned category. The resulting scores facilitate a data-driven approach to quality control, allowing for the identification of misaligned risks and subsequent refinement of both the extraction and categorization processes. This validation step is crucial for ensuring the reliability and consistency of the risk assessment output.
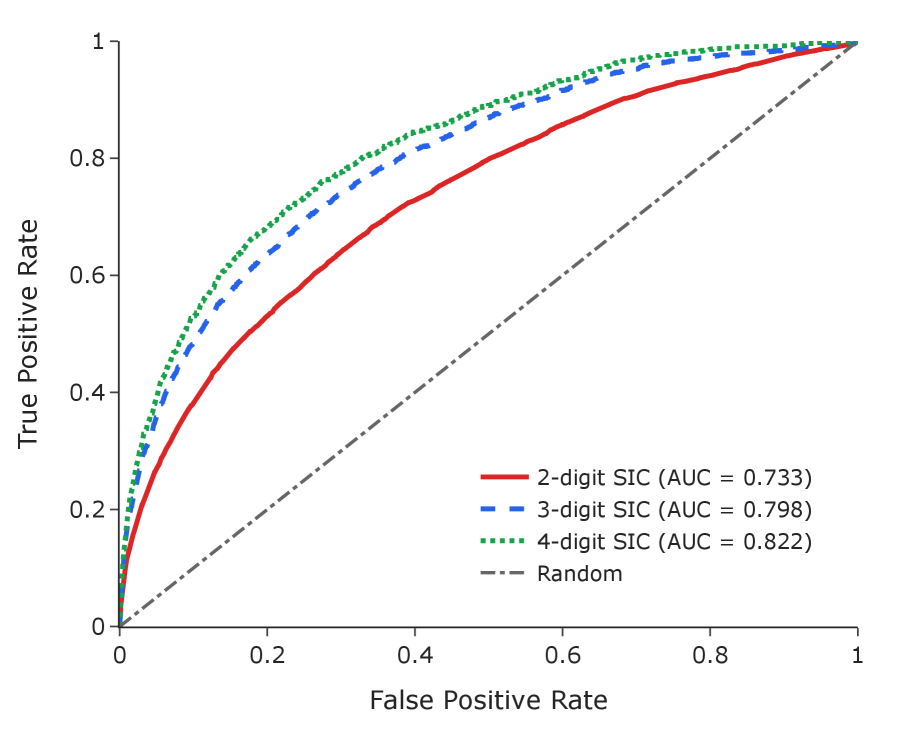
Evaluation Metrics are central to the LLM validation process, providing quantifiable data to assess the performance of risk alignment. These metrics include precision, recall, and F1-score, calculated by comparing the LLM-extracted risks to the established taxonomy categories. Performance is assessed both overall and per-category, enabling the identification of specific areas where the LLM struggles with accurate risk classification. Tracking these metrics over time allows for iterative improvement of the LLM through retraining or adjustments to the taxonomy, and facilitates a data-driven approach to ensuring the reliability of the risk mapping process. Furthermore, metrics such as Cohen’s d are utilized to statistically validate observed improvements in model performance, as demonstrated by a value of 1.06 (p<0.001) indicating a significant improvement in industry clustering following autonomous taxonomy refinement.
The system determines the relationship between extracted risks and predefined taxonomy categories through semantic similarity, leveraging embedding models to represent both as vectors in a multi-dimensional space. Autonomous refinement of the taxonomy, specifically within a pharmaceutical approval category, resulted in a 104.7% improvement in embedding separation – indicating a greater distinction between risk vectors assigned to different categories. This improvement was statistically significant, as demonstrated by a Cohen’s d of 1.06 (p<0.001), confirming robust clustering of risks based on industry-specific taxonomy and validating the effectiveness of the embedding model and refinement process.
Beyond Sectors: Revealing Interconnectedness Through Shared Risk
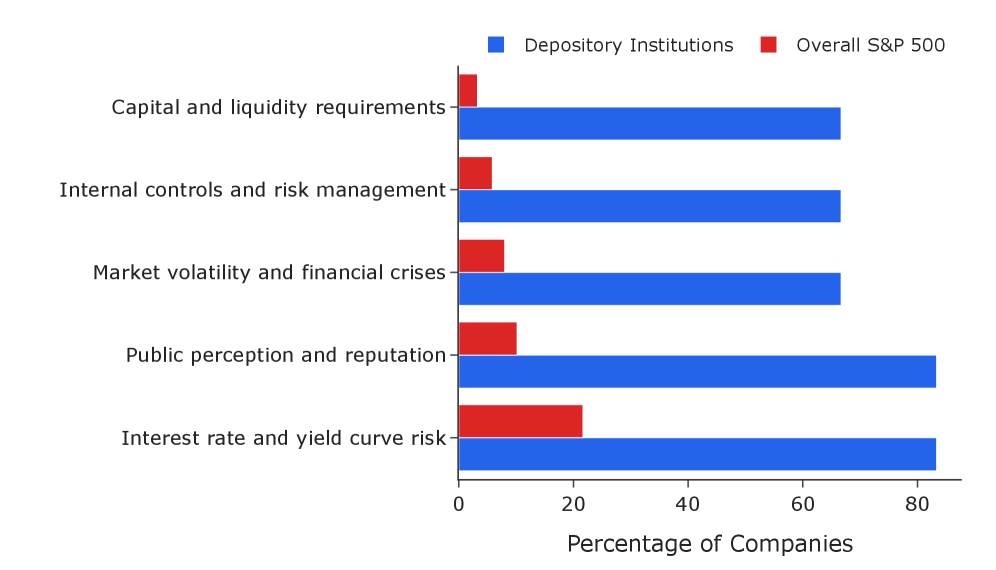
The analysis of extensive financial disclosures enables a novel approach to identifying and grouping companies based on comparable risk exposures. This framework moves beyond traditional sector classifications by pinpointing shared vulnerabilities revealed within 10-K filings and other regulatory documents. By systematically assessing these reports, the system constructs a detailed risk profile for each company, then leverages these profiles to perform industry clustering. The resulting groups aren’t defined by standard industry codes, but rather by genuinely shared risks – allowing for a more granular and accurate understanding of interconnectedness and potential systemic impacts. This method facilitates targeted risk management and provides stakeholders with insights into which companies are most susceptible to the same challenges, offering a dynamic view of industry landscapes.
The system’s architecture prioritizes efficient data acquisition through Application Programming Interface (API) integration, directly connecting to sources like Massive.com and others to automate the traditionally laborious process of financial document analysis. This seamless access eliminates the need for manual data entry or scraping, significantly reducing both time and potential errors. By automatically retrieving and processing information from these varied sources, the framework allows for a more comprehensive and up-to-date understanding of financial risk factors, ultimately enabling faster and more informed decision-making regarding industry-wide trends and individual company assessments.
The system incorporates a mechanism for autonomous taxonomy refinement, enabling it to dynamically adjust its understanding of financial risks as new information emerges. This adaptive capability moves beyond static risk categorization, allowing the system to identify and incorporate evolving threats as they are disclosed in financial filings. Consequently, companies operating within the same industry demonstrate a 63% greater similarity in their identified risk profiles compared to those in different sectors, indicating a heightened accuracy in pinpointing shared vulnerabilities and providing a more nuanced understanding of industry-specific risk landscapes. This constant recalibration enhances the system’s ability to provide timely and relevant risk assessments, offering a significant advantage in proactive risk management.
The pursuit detailed within this study mirrors a fundamental principle of systems analysis: to truly understand something, one must dissect it, test its boundaries, and expose its underlying structure. The methodology-leveraging large language models to extract risk factors and employing an ‘LLM-as-a-judge’ for validation-isn’t merely data processing; it’s a form of controlled deconstruction. As Bertrand Russell observed, “The whole problem with the world is that fools and fanatics are so certain of themselves, but wiser people are full of doubts.” This applies directly to taxonomy alignment; the system doesn’t assume a fixed truth, but continuously refines its understanding through iterative testing and validation, questioning pre-defined categories and embracing the ambiguity inherent in complex financial data. Reality, in this context, is indeed open source – the filings are the code, and this methodology provides a means to read it.
What’s Next?
The demonstrated capacity to coax structured data from the notoriously verbose swamp of 10-K filings feels less like an achievement and more like a pointed question. If risk factors are, in fact, consistently stated within these documents – even if obscured by legal boilerplate – then the system isn’t so much ‘extracting’ information as it is performing a particularly elaborate form of pattern recognition. The interesting failures, of course, will reveal where the true ambiguity lies-not in the language models, but in the underlying realities of corporate risk itself.
Future iterations will undoubtedly focus on expanding the taxonomy – a perpetually shifting target, given the ingenuity of those tasked with creating risk. But a more fruitful avenue might be to deliberately introduce noise – adversarial examples, constructed ambiguities – to test the system’s breaking point. What kind of linguistic jujitsu can consistently fool a model trained to find order in chaos? That’s where the real insights will surface, suggesting not just what the system can know, but the limits of knowability itself.
Ultimately, the success of this approach isn’t measured by precision and recall-those are merely engineering metrics. The true test will come when the system identifies a risk before it becomes a headline, not by parsing language, but by detecting a subtle shift in the underlying statistical distribution of corporate disclosures. That, however, ventures beyond information extraction and into something resembling divination-a prospect that, while unsettling, is undeniably intriguing.
Original article: https://arxiv.org/pdf/2601.15247.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- Gold Rate Forecast
- How to Solve the Glenbright Manor Puzzle in Crimson Desert
- 8 Actors Who Could Play Blackbeard In One Piece Live-Action Season 3
- All Itzaland Animal Locations in Infinity Nikki
- All 10 Potential New Avengers Leaders in Doomsday, Ranked by Their Power
- A Dark Scream Theory Rewrites the Only Movie to Break the 2-Killer Rule
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
2026-01-23 04:15