Author: Denis Avetisyan
Researchers are harnessing the power of language to automatically identify bug reports stemming from tricky concurrency issues in software.

This review details a method for classifying concurrency bug reports using linguistic patterns and fine-tuned language models, improving fault localization in software engineering.
Despite the increasing prevalence of multi-core architectures, identifying concurrency bugs within complex software systems remains a significant challenge. This paper, ‘Identifying Concurrency Bug Reports via Linguistic Patterns’, addresses this issue by introducing a novel framework that automatically detects these bugs through the analysis of linguistic patterns found in bug report descriptions. Our approach, leveraging both traditional machine learning and fine-tuned pre-trained language models, achieves up to 93% precision on large-scale open-source projects. Could this method pave the way for more efficient and accurate automation of bug triage in concurrent systems?
Deconstructing the Bug Report: Unmasking Concurrency’s Hidden Complexity
Concurrency bugs, arising from the complexities of managing simultaneous access to shared resources, pose a substantial threat to software reliability. Unlike many other error types, these bugs are often non-deterministic and difficult to reproduce, making traditional debugging methods ineffective. Their impact can range from subtle data corruption to complete system crashes, particularly in multi-threaded applications and distributed systems. Consequently, a robust and efficient system for identifying and triaging concurrency issues is paramount. The increasing prevalence of parallel computing architectures further exacerbates this challenge, demanding scalable solutions capable of handling a growing volume of potentially problematic interactions between different computational threads or processes. Addressing this requires not only advanced detection techniques but also streamlined workflows for developers to quickly understand, prioritize, and resolve these often-elusive defects.
The traditional process of identifying and categorizing software bugs within incoming reports presents a substantial bottleneck in modern development. Manual triage, where engineers painstakingly read and interpret each submission, is inherently slow, especially given the increasing complexity of concurrent systems. This human-driven approach is also susceptible to inconsistencies; subjective interpretations of ambiguous descriptions can lead to misclassification, delayed responses, and ultimately, prolonged software release cycles. The sheer volume of reports, coupled with the need for specialized knowledge to understand subtle concurrency issues, exacerbates these challenges, frequently overwhelming development teams and impeding their ability to rapidly iterate and deliver high-quality software.
Automated bug report analysis frequently falters when addressing concurrency issues due to the subtle linguistic cues that often indicate these complex errors. Unlike straightforward bugs described with direct error messages, concurrency problems – arising from the interplay of multiple processes – are often reported through indirect descriptions of unexpected behavior, such as intermittent failures or data inconsistencies. Current natural language processing techniques struggle to reliably identify these nuanced indicators – terms like “race condition,” “deadlock,” or even vague descriptions of timing-dependent errors – within the large volume of bug reports. The lack of standardized terminology and the prevalence of paraphrasing further complicate matters, leading to a high rate of false negatives and requiring significant manual effort to validate potential concurrency-related bugs. Consequently, developers continue to rely heavily on manual triage, hindering the scalability and efficiency of software development lifecycles.
Linguistic Fingerprints: Revealing Patterns in the Noise
Linguistic Patterns (LPs) are defined as specific textual elements within bug reports that suggest the presence of concurrency-related defects. These patterns extend beyond isolated keywords to include characteristic phrases, complete sentences, and the surrounding contextual information present in the report. The identification of LPs is predicated on the observation that certain language consistently appears in reports detailing issues like race conditions, deadlocks, and data corruption caused by concurrent access. Specifically, LPs encompass terms referencing threads, locks, synchronization primitives, shared memory, and asynchronous operations, as well as descriptive language indicating contention or inconsistent state resulting from concurrent execution. The comprehensive inclusion of report context is crucial for disambiguation and accurate identification of concurrency issues, as keywords alone can be insufficient.
Traditionally, the identification of Linguistic Patterns (LPs) – keywords, phrases, and contextual elements indicative of concurrency bugs – has been a labor-intensive, manual process requiring significant engineering time and domain expertise. LLM-assisted LP generation automates much of this process by leveraging large language models to analyze bug reports and associated code, extracting potential LPs with greater efficiency. This automation reduces the need for exhaustive manual review and pattern discovery, accelerating the creation of an LP library. The LLM’s ability to process natural language and code context enables it to suggest patterns that might otherwise be missed, lowering the overall effort required to build a comprehensive and accurate LP set for bug classification.
An LP-Based Classification system utilizes identified Linguistic Patterns (LPs) to automatically categorize bug reports. This system functions by analyzing incoming reports for the presence of pre-defined LPs – keywords, phrases, or sentence structures indicative of specific bug types, particularly concurrency issues. The presence and weighting of these LPs within a report determine its assigned category, enabling automated triage and routing to the appropriate development team. The system’s robustness derives from the comprehensive set of LPs and the accuracy of their association with defined bug categories, reducing the need for manual review and accelerating the bug resolution process.
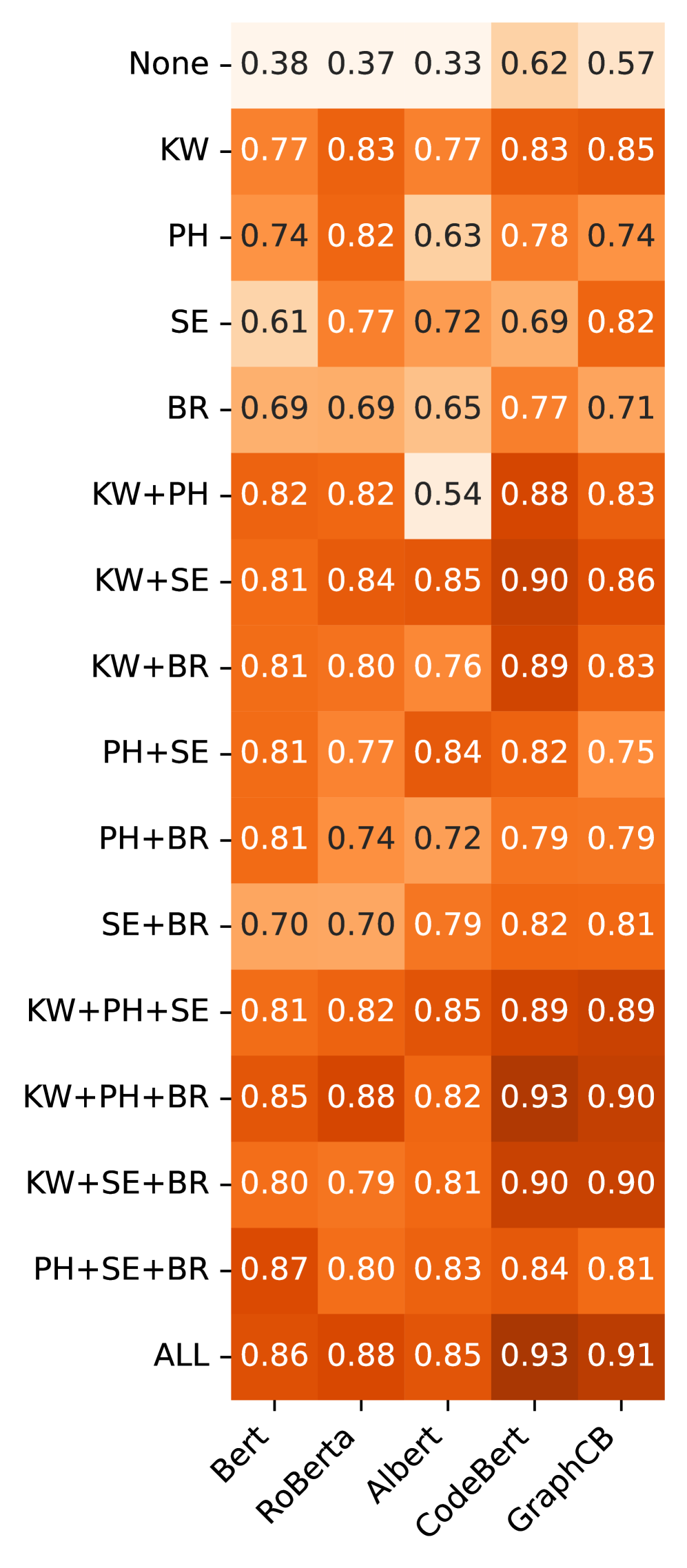
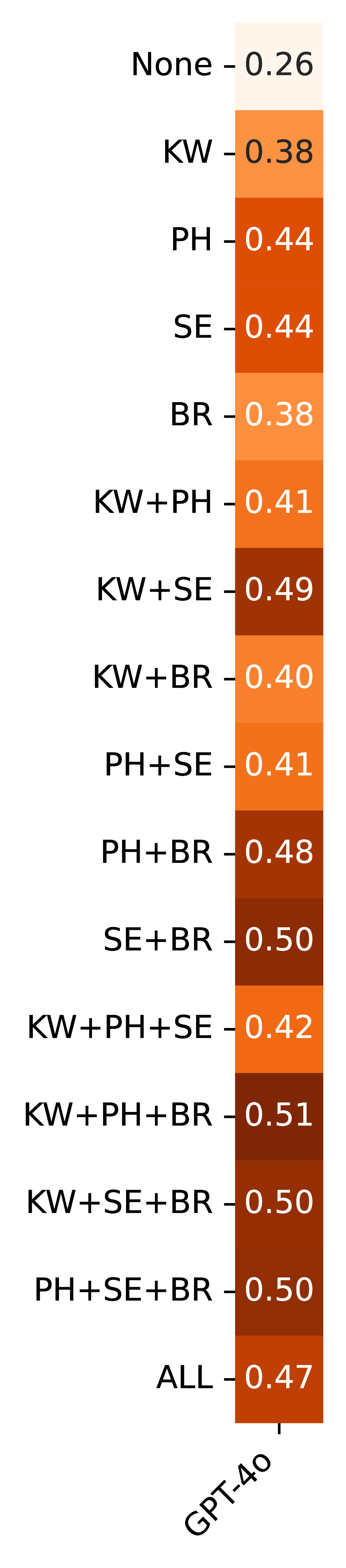
Dissecting the Patterns: Methods for Automated Classification
Matching-Based Classification, a core component of our LP-Based Classification system, operates by directly comparing incoming bug reports against a predefined set of patterns. These patterns, representing known bug characteristics, are established through analysis of previously categorized reports. Classification occurs when a report’s content precisely matches a stored pattern; this approach is particularly effective for identifying recurring issues with clearly defined signatures. While limited in its ability to generalize beyond exact matches, Matching-Based Classification provides a rapid and deterministic method for categorizing simple, consistently reported bugs, serving as a foundational element within the broader LP-Based system.
Learning-Based Classification utilizes machine learning algorithms trained on labeled bug report data to identify patterns indicative of concurrency issues; these models learn to associate report features with specific bug types, enabling classification beyond simple keyword matching. Prompt-Based Classification, conversely, employs large language models (LLMs) by formulating bug report analysis as a prompting task; the LLM receives the report as input alongside a carefully crafted prompt instructing it to categorize the bug, leveraging the model’s pre-existing knowledge and reasoning capabilities. Both approaches allow for the identification of complex relationships within bug reports, including semantic similarities and contextual cues, which are often missed by simpler methods.
Fine-Tuned PLM Classification improves classification accuracy by leveraging the capabilities of pre-trained language models (PLMs) and adapting them to the nuances of concurrency bug reports. This process involves utilizing a PLM initially trained on a large corpus of general text data and then further training it with a dataset specifically composed of labeled concurrency bug reports. This adaptation, often achieved through techniques like transfer learning, allows the model to better understand the specific vocabulary, phrasing, and patterns commonly found in these reports, resulting in more accurate identification and categorization of concurrency issues compared to models trained on broader datasets or relying on simpler pattern matching techniques.
LP-based classification systems utilize patterns at varying levels of granularity to identify and categorize bug reports. Keyword-Level Patterns focus on the presence of specific terms, offering a broad but potentially imprecise method. Phrase-Level Patterns expand on this by considering sequences of words, improving accuracy through contextual analysis. Sentence-Level Patterns analyze complete sentences to capture more complex relationships between terms, while Bug Report-Level Patterns consider the entire report content for holistic categorization. The selection of granularity level impacts both the precision of classification and the computational resources required for pattern matching.

Beyond the Benchmarks: Real-World Impact and Future Explorations
A comprehensive evaluation of the proposed approach utilized three distinct datasets – DatasetGit, sourced from GitHub, DatasetJira, and a temporally-focused DatasetPost – to rigorously assess its performance and adaptability. This multi-faceted testing strategy was crucial in demonstrating the robustness of the system across varying codebases and project management styles. The consistent results obtained from these diverse sources confirm not only the accuracy of the classification method, but also its generalizability beyond the specific conditions of any single development environment. By successfully navigating the complexities of each dataset, the research establishes a strong foundation for wider implementation and reliable bug triage in real-world software engineering practices.
The developed approach exhibits considerable promise for substantially improving both the efficiency of bug triage and the overall reliability of software systems, as evidenced by a consistently high overall F1-score of 93%. This metric indicates a strong balance between precision and recall in identifying and categorizing software defects, suggesting a practical ability to reduce the time required for developers to address critical issues. Such advancements translate directly into faster release cycles, reduced maintenance costs, and a more stable user experience, ultimately benefiting both software providers and end-users. The consistent performance across diverse datasets-including those representing code repositories, issue trackers, and temporal data-underscores the generalizability and robustness of the methodology, making it a viable solution for a broad range of software development contexts.
Rigorous evaluation on the DatasetGit benchmark revealed a high degree of accuracy for the CodeBERT+ALL model, achieving a 93% F1-score in bug report classification. This metric indicates a strong balance between the model’s ability to correctly identify relevant bug reports and avoid false positives. Complementing this overall performance, the model demonstrated a precision of 0.91, signifying that approximately 91% of the bug reports flagged as relevant were, in fact, correctly categorized. These results highlight the model’s capacity to efficiently and reliably sift through software development data, offering a promising foundation for automated bug triage systems and improved software quality.
The developed approach exhibits strong performance across diverse datasets, notably achieving a 0.95 F1-score on the DatasetJira, which comprises issue reports from a project management system. Crucially, the system maintained a consistent 0.93 F1-score when evaluated on DatasetPost, a temporally-oriented collection of posts – indicating its robustness over time and its capacity to accurately classify bug reports regardless of when they were submitted. This consistent high performance suggests the model effectively generalizes beyond the specific context of code repositories and can be reliably applied to real-world bug triage scenarios, even as the nature of reported issues evolves.
The developed classification approach is poised for practical implementation through a GitHub Bot Integration, designed to automatically categorize incoming bug reports. This integration aims to streamline the bug triage process by leveraging the model’s ability to accurately assign labels based on report content, thereby reducing manual effort and accelerating response times. By directly embedding this functionality within the GitHub ecosystem, developers can benefit from real-time bug categorization, improved workflow efficiency, and ultimately, a more reliable software product. This automation not only promises to alleviate the burden on development teams but also facilitates better bug tracking and prioritization, ensuring critical issues are addressed promptly.
Current research indicates that refining information retrieval (IR)-based fault localization can benefit significantly from the analysis of linguistic patterns within bug reports and source code. This approach moves beyond simple keyword matching to examine the semantic relationships between reported issues and the code potentially responsible, identifying subtle cues in language that indicate the root cause of errors. By leveraging natural language processing techniques to discern patterns in how developers describe bugs – for example, identifying specific verbs associated with particular types of errors or recognizing phrasing indicative of race conditions – the precision of fault localization can be dramatically improved. This linguistic analysis, when integrated with IR techniques, promises to narrow the search space for developers, reducing the time and effort required to pinpoint and resolve software defects, ultimately leading to more reliable and robust applications.
The pursuit of identifying concurrency bug reports, as detailed in this work, inherently involves a dismantling of assumed correctness. It’s a process of exposing hidden flaws within complex systems – a familiar exercise in reverse engineering. This resonates strongly with Linus Torvalds’ sentiment: “Most good programmers do programming as an exercise in wishful thinking.” The paper’s use of linguistic patterns to classify bug reports isn’t about accepting descriptions at face value; rather, it’s about probing those descriptions, breaking them down to reveal the underlying technical realities of the concurrency issues. The fine-tuning of language models, in effect, becomes a means of systematically testing those linguistic hypotheses, much like a debugger tests code.
Beyond the Signal in the Noise
The identification of concurrency bug reports through linguistic analysis, while demonstrably effective, ultimately exposes the fragility of categorization itself. The system excels at recognizing patterns of failure, yet failure, in its truest form, is often the unexpected – the signal lost in the noise. Future work needn’t focus solely on refining classification accuracy, but on quantifying the distance between a report and any known pattern. A bug report’s peculiarity may, paradoxically, be its most valuable attribute, hinting at entirely novel system vulnerabilities.
This approach currently treats language as a passive indicator, a footprint of the underlying fault. The next iteration should consider language as active – a potential source of diagnostic information. Could the specific phrasing used in a bug report reveal not just that something is broken, but how it is broken, even before code analysis begins? The model currently reverse-engineers failure; the challenge now is to allow the language to prefigure it.
Ultimately, the true test lies not in automating bug identification, but in automating the discovery of new failure modes. One suspects that the most interesting bugs are those that actively resist categorization – those that demand a rethinking of the system’s fundamental assumptions. It is in these anomalies, in the cracks of predictability, that genuine progress resides.
Original article: https://arxiv.org/pdf/2601.16338.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- All Itzaland Animal Locations in Infinity Nikki
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- How to Get to the Undercoast in Esoteric Ebb
- Gold Rate Forecast
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- A Dark Scream Theory Rewrites the Only Movie to Break the 2-Killer Rule
- 6 Ways Invincible Season 4’s Hell Episode Rewrites The Comics
- Fire Force Season 3 Part 2 Episode 24 Release Date, Time, Where to Watch
2026-01-26 23:09