Author: Denis Avetisyan
A new machine learning framework pinpoints the minimal data needed to accurately predict lake water clarity, streamlining monitoring efforts and improving resource management.
This research details a data-driven approach to time-series forecasting of lake water quality, specifically addressing the challenges posed by missing data and identifying key features for reliable predictions.
Reliable forecasting of lake water quality is often hampered by incomplete and irregularly sampled data, particularly in long-term monitoring programs. This research, ‘Data-driven Lake Water Quality Forecasting for Time Series with Missing Data using Machine Learning’, addresses this challenge by developing a framework to predict lake clarity (Secchi Disk Depth) while quantifying the minimal data requirements for accurate results. Our analysis of three decades of Maine lake data reveals that approximately 176 recent samples and just four key features are sufficient to achieve within 5% of full-history, full-feature accuracy. Could this joint feasibility strategy-unifying sample size and feature selection-fundamentally reshape lake monitoring efforts, enabling more efficient and targeted data collection?
Lakes: A Slow Burn We Can’t Ignore
Lake ecosystems provide invaluable services, from freshwater resources and recreation to biodiversity support, yet their health is increasingly threatened by a confluence of factors. Traditional lake monitoring programs, while foundational, often struggle to keep pace with these rapidly changing conditions. Historically, assessments have relied on periodic manual sampling and laboratory analysis, a process that is both time-consuming and limited in its spatial and temporal coverage. This infrequent data collection hinders the ability to detect subtle shifts in water quality, particularly the early warning signs of developing problems like nutrient imbalances or the onset of Harmful Algal Blooms. Consequently, responses to deteriorating lake health are often reactive rather than proactive, necessitating a shift towards more comprehensive, frequent, and responsive monitoring strategies to ensure the long-term sustainability of these vital resources.
Lake water quality isn’t simply a matter of measuring a few key indicators; it’s the result of a delicate interplay between physical properties like temperature and sunlight, chemical components such as nutrient levels and pH, and a vast web of biological organisms – from microscopic phytoplankton to larger plants and fish. A truly comprehensive assessment, therefore, necessitates gathering data across all these domains, recognizing that changes in one area can cascade through the entire system. For instance, increased phosphorus levels – a chemical factor – can fuel excessive phytoplankton growth – a biological response – which then alters water clarity – a physical characteristic – and potentially leads to oxygen depletion, impacting aquatic life. Understanding these interconnectedness requires a holistic approach to data collection and analysis, moving beyond single-factor assessments to reveal the true health of a lake ecosystem.
The escalating prevalence of Harmful Algal Blooms (HABs) presents a significant and growing threat to freshwater ecosystems and public health, underscoring the critical need for more vigilant lake water quality monitoring. These blooms, often fueled by nutrient pollution and warming temperatures, can produce toxins harmful to humans and animals, disrupt aquatic food webs, and even diminish recreational opportunities. Traditional monitoring approaches, while valuable, frequently lack the temporal and spatial resolution to detect the early warning signs of HAB development, leaving ecosystems vulnerable to rapid deterioration. Consequently, a shift towards proactive, high-frequency monitoring-leveraging technologies like remote sensing and automated sensors-is paramount to enable timely interventions and mitigate the increasingly severe consequences associated with these blooms, protecting both ecological integrity and human well-being.
Lake water quality assessment has historically relied on manual sampling techniques, a practice now increasingly challenged by the dynamic nature of freshwater ecosystems. These conventional methods, while providing valuable baseline data, are often constrained by logistical limitations – infrequent sampling windows and a restricted number of locations monitored. Consequently, subtle shifts in water chemistry or the early stages of ecological stress, such as the proliferation of cyanobacteria, can go undetected until conditions significantly deteriorate. This limited spatial and temporal resolution hinders proactive management, delaying interventions necessary to mitigate harmful algal blooms and preserve overall lake health. The inability to capture the full complexity of a lake’s condition with these methods underscores the need for more frequent, widespread, and technologically advanced monitoring approaches.
Seeing the Whole Lake: Beyond Point Samples
Remote sensing technologies, including satellite and aerial platforms equipped with various sensors, offer a significantly more comprehensive method for assessing lake conditions compared to traditional manual sampling. Manual sampling is inherently limited by the number of locations and time points that can be realistically accessed, providing only a sparse and potentially biased representation of the entire lake system. In contrast, remote sensing can acquire data across the entire water surface, generating spatially continuous datasets of parameters such as temperature, chlorophyll-a concentration, turbidity, and water depth. This capability allows for the identification of spatial patterns and gradients in lake characteristics that would be missed by point-based measurements, and facilitates the monitoring of changes over time with greater accuracy and temporal resolution.
Machine learning (ML) algorithms utilize remotely sensed data to establish predictive models for various water quality parameters. These algorithms, including regression and classification techniques, are trained on datasets linking spectral reflectance values to measured in-situ water quality metrics such as chlorophyll-a concentration, turbidity, and dissolved organic matter. Once trained, the models can estimate these parameters across the entire lake surface area from remotely sensed imagery, offering a spatially comprehensive assessment. This predictive capability facilitates proactive lake management by enabling timely interventions based on forecasted water quality conditions and allowing resource allocation to areas exhibiting the greatest need or potential for degradation. Furthermore, continuous model refinement with new data improves predictive accuracy and expands the range of detectable parameters.
Multispectral imagery, acquired through remote sensing platforms like satellites and aircraft, captures data across specific wavelengths of the electromagnetic spectrum beyond visible light. These wavelengths correspond to varying degrees of absorption and reflectance by water constituents such as chlorophyll, dissolved organic matter, and suspended sediments. This spectral information is crucial for machine learning models, serving as input features to identify and quantify these components, thereby enabling the assessment of water composition and clarity. The number and specific wavelengths captured vary depending on the sensor, but commonly include bands in the blue, green, red, near-infrared, and shortwave infrared regions, each providing unique insights into water properties. Data from these bands are then processed and used to train algorithms that can estimate parameters like turbidity, chlorophyll-a concentration, and total suspended solids.
The integration of remote sensing and machine learning facilitates consistent, large-scale observation of lake ecosystems, enabling the identification of subtle shifts in water quality indicators that may precede significant ecological events. This continuous monitoring capability surpasses the temporal and spatial restrictions of traditional sampling methods, allowing for near real-time detection of anomalies such as algal blooms, turbidity increases, or thermal stratification changes. Consequently, management agencies benefit from extended lead times for implementing mitigation strategies, reducing the potential impacts of threats like harmful algal blooms or oxygen depletion events on aquatic life and water resources.
Ridge Regression: Finding the Signal in the Noise
Ridge Regression is a linear regression technique designed to address multicollinearity – a common issue in ecological datasets where predictor variables are highly correlated. Unlike ordinary least squares regression, Ridge Regression introduces a regularization penalty – specifically, the L2 norm of the coefficient vector – to the loss function. This penalty shrinks the magnitude of regression coefficients, reducing their variance and improving the model’s generalization performance, particularly when dealing with high-dimensional data or datasets with strong interdependencies between predictors. The method achieves this by adding a value,
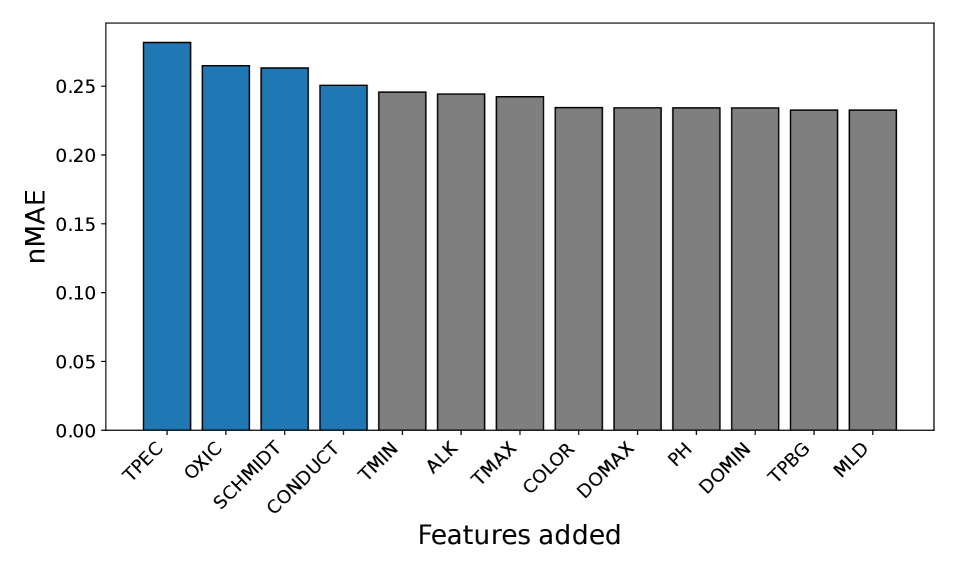
The predictive model utilizes a suite of seven key parameters to estimate water quality. These include Total Phosphorus, a nutrient often limiting algal growth; Chlorophyll-a, a proxy for algal biomass; Mixed-Layer Depth, which influences light and nutrient availability; Schmidt Stability, a measure of water column resistance to mixing; TPEC (Total Phosphorus Effluent Concentration), representing phosphorus loading; OXIC, indicating dissolved oxygen levels; and Conductivity, a measure of the water’s ability to conduct electricity, often correlated with dissolved ions and salinity. The inclusion of these parameters allows the model to capture complex relationships influencing water quality characteristics within the studied aquatic ecosystems.
Feature importance was assessed using Mean Decrease in Impurity (MDI), a method that calculates the reduction in model error achieved by each predictor variable. Specifically, MDI quantifies the average decrease in impurity – measured as variance in the case of linear regression – across all decision trees within the Ridge Regression model. Higher MDI values indicate a greater contribution of that variable to predictive accuracy. Analysis identified Total Phosphorus, Chlorophyll-a, Conductivity, and Mixed-Layer Depth as consistently important predictors across multiple lakes, suggesting these parameters are key drivers of water quality variations. The relative importance of each parameter was determined by normalizing MDI values, allowing for comparison of influence despite differing scales and units of measurement.
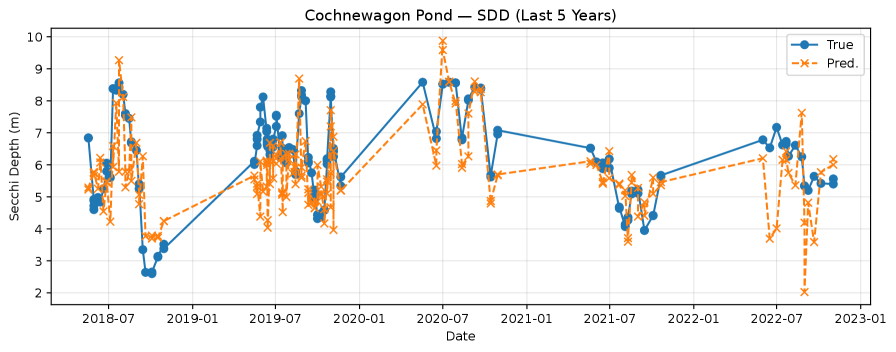
The predictive performance of the Ridge Regression model demonstrates a high degree of efficiency in water quality parameter prediction. Analysis indicates that an average of 176 recent training samples, combined with a minimal feature set consisting of only 4 variables, is sufficient to achieve prediction accuracy within 5% of that obtained using the full historical record. This suggests a limited number of key drivers govern water quality dynamics, allowing for robust predictions even with reduced data requirements and computational cost. Furthermore, the median number of training samples required across the studied lakes was 64, with a median minimal feature set size of just 1 variable, indicating considerable variability in model complexity between individual lake systems.
Analysis across the studied lakes indicated a low data requirement for effective predictive modeling using Ridge Regression. The median number of recent training samples needed to achieve accurate predictions was 64, suggesting the model can generalize well with limited data. Notably, the median minimal feature set size – the fewest number of parameters needed for prediction – was only 1, implying that a single key variable often dominates predictive power in these systems. This finding highlights the potential for simplified monitoring strategies focused on the most influential parameters.
Backward Forecasting utilizes Ridge Regression to improve predictive accuracy by integrating historical data trends into the model. This approach treats past observations not merely as independent data points, but as informative precursors to current conditions. By including lagged values of the target variable as predictor variables within the Ridge Regression framework, the model can leverage temporal autocorrelation – the relationship between a variable’s current value and its past values – to refine its predictions. The effectiveness of this technique stems from the assumption that current water quality parameters are, to some degree, dependent on their recent historical values, a relationship that standard Ridge Regression, trained only on contemporaneous data, may not fully capture. This incorporation of historical trends consistently results in enhanced prediction performance compared to models relying solely on current conditions.
From Reaction to Resilience: A Proactive Future for Lake Management
Recent investigations reveal a compelling case for data-driven strategies in lake management, moving beyond traditional, often infrequent, monitoring programs. By integrating continuous sensor data with historical records and sophisticated analytical techniques, researchers can now detect subtle shifts in water quality indicators – such as dissolved oxygen, temperature, and nutrient levels – with unprecedented speed and accuracy. This proactive approach allows for early identification of potential problems, like algal blooms or pollution events, enabling targeted interventions before they escalate into larger ecological crises. The result is a more efficient allocation of resources, moving from reactive responses to preventative measures, and ultimately fostering healthier, more resilient lake ecosystems. This shift represents a fundamental change in how lakes are understood and protected, offering a path toward sustainable management for generations to come.
Precisely pinpointing the primary factors influencing lake water quality enables conservationists to move beyond generalized strategies and implement highly effective, targeted interventions. Rather than spreading limited resources across numerous potential issues, management efforts can concentrate on addressing the specific drivers-such as nutrient runoff from agricultural lands or failing septic systems-that demonstrably impact a lake’s health. This focused approach not only optimizes the use of funding but also amplifies the positive outcomes of conservation initiatives, fostering a more resilient and sustainable aquatic ecosystem. By understanding which stressors have the greatest effect, lake managers can prioritize remediation efforts, ultimately achieving more substantial improvements in water quality and ecological health with available resources.
The developed analytical framework possesses considerable versatility, extending beyond the specific lake studied to encompass a wide array of freshwater ecosystems. By adjusting input parameters to reflect the unique characteristics of different lakes – variations in morphology, climate, surrounding land use, and pollution sources – the model can provide tailored insights into water quality dynamics. This adaptability is crucial for promoting environmental sustainability on a larger scale, enabling proactive management strategies that address the specific challenges facing each individual lake. Ultimately, the framework offers a scalable solution for monitoring and preserving these vital resources, fostering resilience within diverse aquatic environments and contributing to long-term ecological health.
Continued development of lake monitoring relies on expanding the scope of data utilized in predictive modeling. Current frameworks would benefit from integration of real-time sensor networks, high-resolution satellite imagery, and detailed meteorological data to capture more nuanced environmental changes. Furthermore, refining existing models through the incorporation of advanced machine learning techniques – including deep learning and ensemble methods – promises to improve their ability to forecast water quality parameters with greater precision. Such enhancements are not merely academic exercises; increased accuracy translates directly into more effective and targeted management strategies, allowing for proactive interventions that mitigate potential ecological damage and preserve these vital freshwater resources for future generations.
The pursuit of accurate lake water quality forecasting, as detailed in this research, exemplifies a predictable pattern. The framework aims to identify the minimal viable dataset for reliable predictions – a pragmatic concession to inevitable data sparsity. This echoes a sentiment expressed by Carl Friedrich Gauss: “Few things are more deceptive than a simple appearance.” The research doesn’t promise a perfect model, only a functional one given real-world limitations. It acknowledges that even sophisticated machine learning techniques are ultimately constrained by the quality and availability of input data. The attempt to distill essential measurements mirrors a broader trend: elegant theories consistently succumb to the messy reality of production data, highlighting the need for practical, rather than purely theoretical, solutions.
What Breaks Next?
This work establishes a baseline for parsimony in lake water quality forecasting – a laudable goal. However, the minimal data requirement, while efficient, implicitly assumes stationarity. Real-world limnological systems rarely cooperate. The identified ‘essential’ measurements will, inevitably, become insufficient as unforeseen stressors – algal blooms triggered by novel pollutants, shifts in thermal stratification due to climate change – introduce non-linear dynamics. Every abstraction dies in production, and the neatly defined feature space will require constant, reactive expansion.
Future iterations will undoubtedly focus on incorporating more sophisticated imputation methods for the remaining data sparsity. Yet, filling gaps is merely a delay tactic. The true challenge lies in predicting which data will be missing, and building models robust enough to function even with substantial, patterned absences. The current framework, while elegant, doesn’t address the fundamental unpredictability of data acquisition itself – sensor failures, budgetary constraints, logistical disruptions.
Ultimately, this research contributes to a growing body of work demonstrating the feasibility of data-driven lake management. But feasibility is not the same as resilience. The models will perform beautifully… until they don’t. The next logical step isn’t necessarily more data or more complex algorithms; it’s a frank acknowledgement of inherent uncertainty and the development of forecasting systems designed to gracefully degrade, rather than catastrophically fail.
Original article: https://arxiv.org/pdf/2601.15503.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- Gold Rate Forecast
- All Itzaland Animal Locations in Infinity Nikki
- 8 Actors Who Could Play Blackbeard In One Piece Live-Action Season 3
- A Dark Scream Theory Rewrites the Only Movie to Break the 2-Killer Rule
- How to Get to the Undercoast in Esoteric Ebb
- 10 Greatest Games of the Last 10 Years, Ranked
- $2B AI cow collars use “cowgorithm” to herd cattle with no fences
2026-01-25 10:14