Governing the AI Estate: A New Architecture for Robust Security
A novel multi-agent system provides a comprehensive framework for managing risk and ensuring the integrity of enterprise artificial intelligence deployments.
A novel multi-agent system provides a comprehensive framework for managing risk and ensuring the integrity of enterprise artificial intelligence deployments.
As large language models become increasingly powerful, researchers are turning to mechanistic interpretability to reveal how these systems actually think and ensure they align with human values.
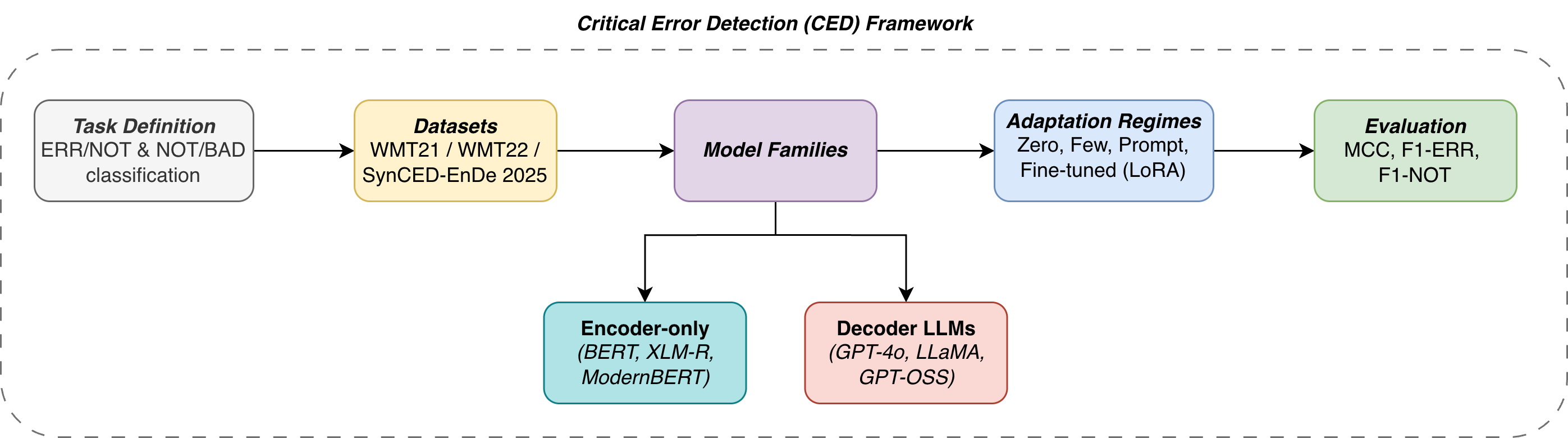
New research shows that advanced language models, when properly refined, can dramatically improve the detection of critical errors in translated text, paving the way for more reliable multilingual communication.
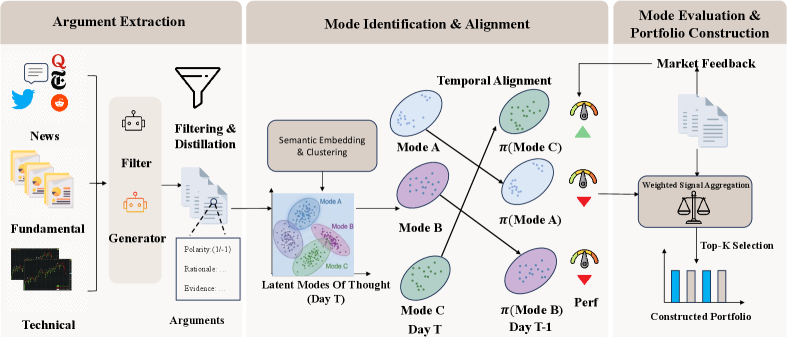
A new framework models financial markets not as random noise, but as complex systems driven by evolving investment strategies.
A new framework leverages artificial intelligence to automatically summarize structural damage assessments following catastrophic events, accelerating response efforts.
New research shows that artificial intelligence can forecast functional outcomes for stroke patients with accuracy comparable to established methods.
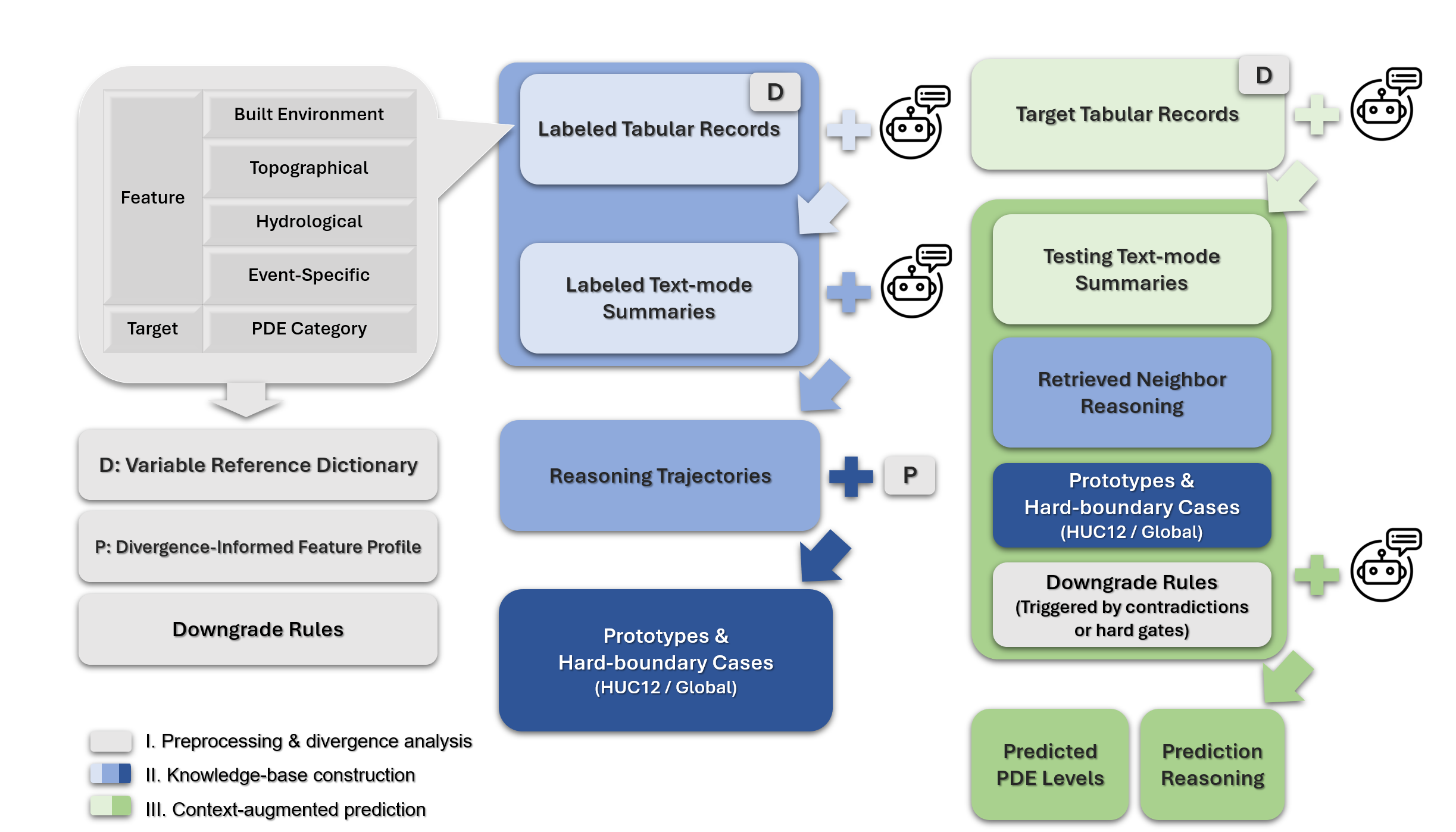
A new framework leverages the power of large language models and real-time data to rapidly assess property damage after flooding events.
A new approach leverages deep learning to anticipate and mitigate frequency instability in power grids, enhancing reliability during critical events.
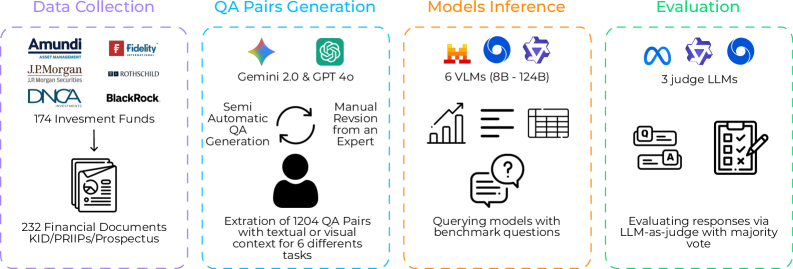
New research reveals the challenges vision-language models face when interpreting complex financial documents, particularly those containing charts and tables.
![The adversarial robustness of Lite-CNN models, evaluated through metrics like [latex]\mathrm{MCC}(\epsilon\_{\mathrm{adv}})[/latex] under both FGSM and PGD attacks, demonstrates that late fusion strategies degrade more gracefully than early fusion when subjected to perturbations targeting individual or combined views of the data.](https://arxiv.org/html/2602.11020v1/x5.png)
New research reveals that while combining multiple data sources can improve financial predictions, these systems are surprisingly vulnerable to even minor data manipulation.