Truth in ESG: Evaluating AI’s Grip on Sustainability Reports

As companies increasingly rely on artificial intelligence to analyze lengthy Environmental, Social, and Governance reports, ensuring the factual accuracy of those analyses is paramount.
As companies increasingly rely on artificial intelligence to analyze lengthy Environmental, Social, and Governance reports, ensuring the factual accuracy of those analyses is paramount.
![This work details a computational pipeline-from extracting the Lyα forest and computing the one-dimensional power spectrum [latex]P_{\rm 1D}(k)[/latex], through a neural network input/output configuration, to a schematic normalizing flow-demonstrating how complex cosmological data can be processed and transformed via interconnected computational stages, potentially obscuring fundamental truths within layers of abstraction.](https://arxiv.org/html/2603.13011v1/x6.png)
New research leverages the power of neural networks and simulated data to extract cosmological insights from the subtle patterns within the Lyman-alpha forest.
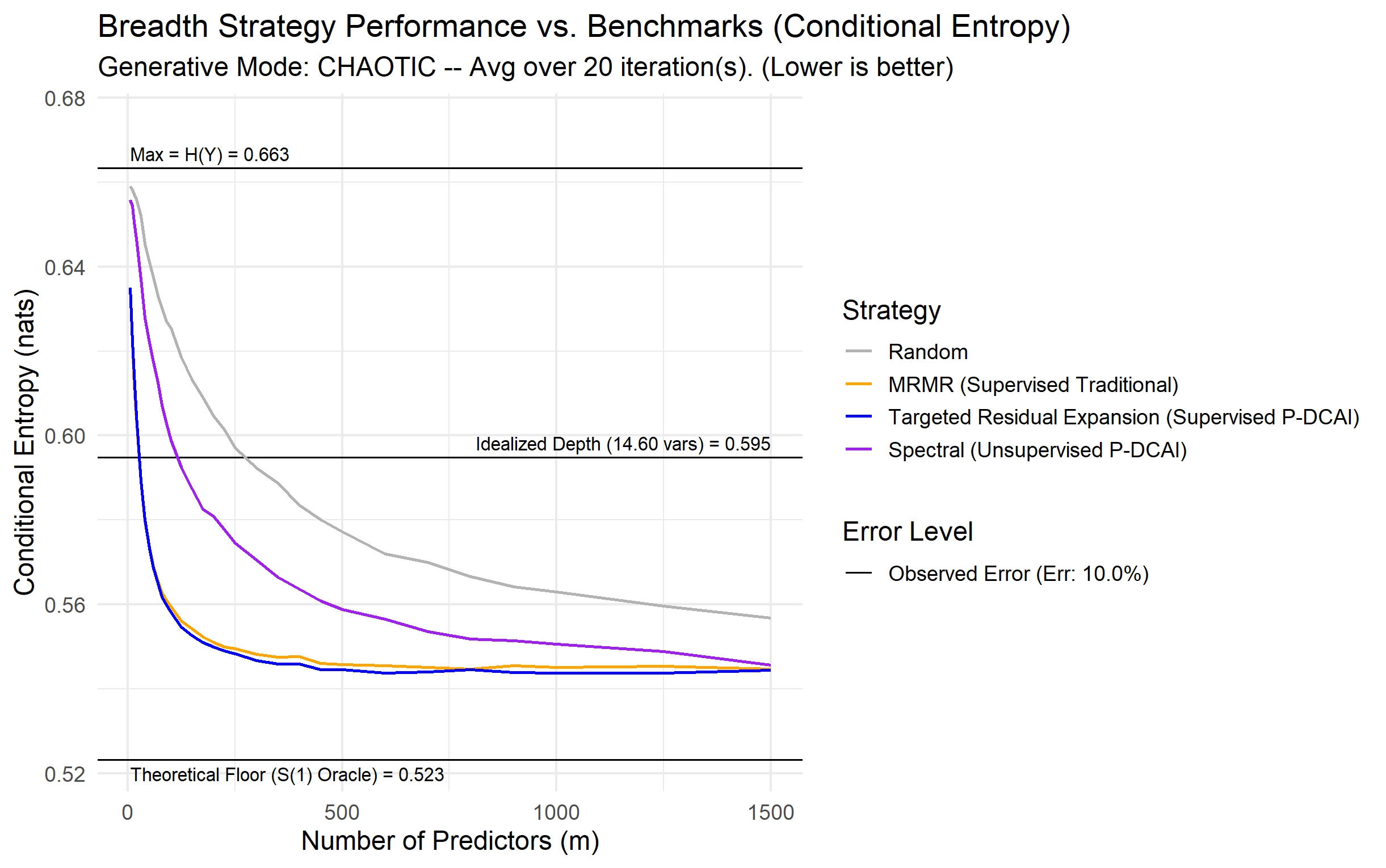
A new framework reveals how embracing high-dimensional data, when combined with a focus on quality, can unlock surprisingly accurate and robust machine learning models.

A new review examines the rapid evolution of AI dialogue systems designed to provide mental health support, charting a course from specialized models to the age of large language models.

A new framework analyzes how AI agents navigate the web, moving beyond simple task success to understand the quality of their decision-making.
![The framework leverages a two-stage process-first, a cross-species continual pre-training of the VideoMAE model using a tube masking strategy and [latex]MSE[/latex] loss to learn robust video representations, and second, the transfer of these learned weights to a forecasting model that predicts seizure onset within a defined future window based on encoded states derived from monitoring clips.](https://arxiv.org/html/2603.12887v1/x1.png)
A new study demonstrates that artificial intelligence, initially trained on animal video data, can accurately predict epileptic seizures in humans using only standard video recordings.

A new system, FraudFox, dynamically adjusts to evolving fraud patterns and business needs, providing a more robust defense against online transaction fraud.

As AI-powered agents gain greater autonomy, understanding and mitigating their unique security risks is paramount.

New research reveals that a company’s position within the lending network is increasingly influencing credit access, potentially eclipsing traditional financial metrics.
A new framework uses artificial intelligence to automatically connect real-world cyber incidents to known attack patterns and security defenses, improving threat response and risk mitigation.