Author: Denis Avetisyan
Researchers have developed a systematic method for evaluating how readily artificial intelligence can be exploited to assist in fraudulent activities and cybercrime.

This review presents a multi-turn evaluation framework revealing limited current practical misuse, but highlights significant potential harm from uncensored models and complex, conversational attacks.
Despite increasing concerns about the potential for artificial intelligence to facilitate illicit activities, a clear understanding of large language models’ capabilities in complex criminal scenarios remains elusive. This is addressed in ‘A Multi-Turn Framework for Evaluating AI Misuse in Fraud and Cybercrime Scenarios’, which presents a systematic, expert-grounded evaluation of model assistance with fraud and cybercrime, finding limited practical support for current models but revealing heightened risk with uncensored versions and strategically crafted multi-turn interactions. The study demonstrates that decomposing malicious requests into seemingly benign queries can elicit more harmful responses than direct prompts, suggesting a nuanced threat landscape. As these models evolve, how can we proactively refine evaluation frameworks to anticipate and mitigate emerging adversarial tactics?
The Evolving Threat: When Fraud Embraces Intelligence
The escalating complexity of fraudulent activities, ranging from meticulously crafted CEO scams to increasingly convincing identity theft schemes, presents a growing challenge to traditional security measures. No longer reliant on simple phishing or brute-force tactics, modern fraudsters employ sophisticated social engineering, leveraging publicly available data and nuanced psychological manipulation to bypass conventional defenses. This evolution necessitates a fundamental shift in counter-fraud strategies; static rule-based systems and basic pattern recognition are proving insufficient against adversaries who actively adapt their techniques to evade detection. Consequently, a proactive and dynamic approach-one that anticipates emerging threats and incorporates advanced analytical capabilities-is now crucial to effectively mitigate the financial and reputational risks posed by these increasingly sophisticated attacks.
The proliferation of Large Language Models (LLMs) is dramatically reshaping the landscape of fraudulent activity, enabling adversaries to automate and scale attacks with unprecedented ease. Previously, crafting convincing phishing emails or impersonating individuals required significant effort and linguistic skill; now, LLMs can generate highly realistic and personalized deceptive content at a fraction of the cost and time. This lowered barrier to entry means that individuals with limited technical expertise can launch sophisticated fraud campaigns, increasing both the volume and velocity of attacks. Moreover, LLMs facilitate the rapid adaptation of tactics, allowing fraudsters to quickly refine their approaches based on the success – or failure – of previous attempts, creating a continuously evolving threat that challenges traditional detection methods.
Traditional fraud detection systems, heavily reliant on identifying pre-defined patterns of malicious activity, are increasingly vulnerable to sophisticated attacks. These systems operate by flagging transactions or behaviors that deviate from established norms, but modern adversaries are now employing artificial intelligence – specifically, adaptive algorithms – to deliberately circumvent these safeguards. By learning and evolving their tactics in real-time, these AI-powered attacks can subtly modify fraudulent activities to remain within the boundaries of what is considered ‘normal’ by pattern-based detectors. This creates a continuous arms race where static rules are quickly rendered ineffective, and the ability to dynamically adjust and anticipate evolving fraud techniques becomes paramount for maintaining security. Consequently, systems must move beyond simply recognizing known signatures of fraud to understanding the intent behind actions, a challenge that demands more advanced analytical capabilities.
A comprehensive understanding of how Large Language Models (LLMs) integrate into each stage of the fraud lifecycle – from initial reconnaissance and social engineering to the crafting of persuasive phishing campaigns and the laundering of illicit funds – is now paramount for effective defense. LLMs don’t simply create new types of fraud; they dramatically accelerate and scale existing techniques, automating personalization to bypass traditional signature-based detection systems. Analyzing how these models are employed to generate convincing synthetic identities, craft hyper-targeted communications, and adapt to security measures allows for the development of proactive countermeasures. These defenses must move beyond reactive pattern recognition towards behavioral analysis, focusing on the intent behind communications and transactions, and leveraging AI itself to anticipate and disrupt fraudulent activity before it materializes. Ultimately, charting the evolution of LLM-assisted fraud is crucial for building resilient systems and safeguarding against increasingly sophisticated attacks.

Quantifying AI’s Role in Complex Fraud: A Necessary Dissection
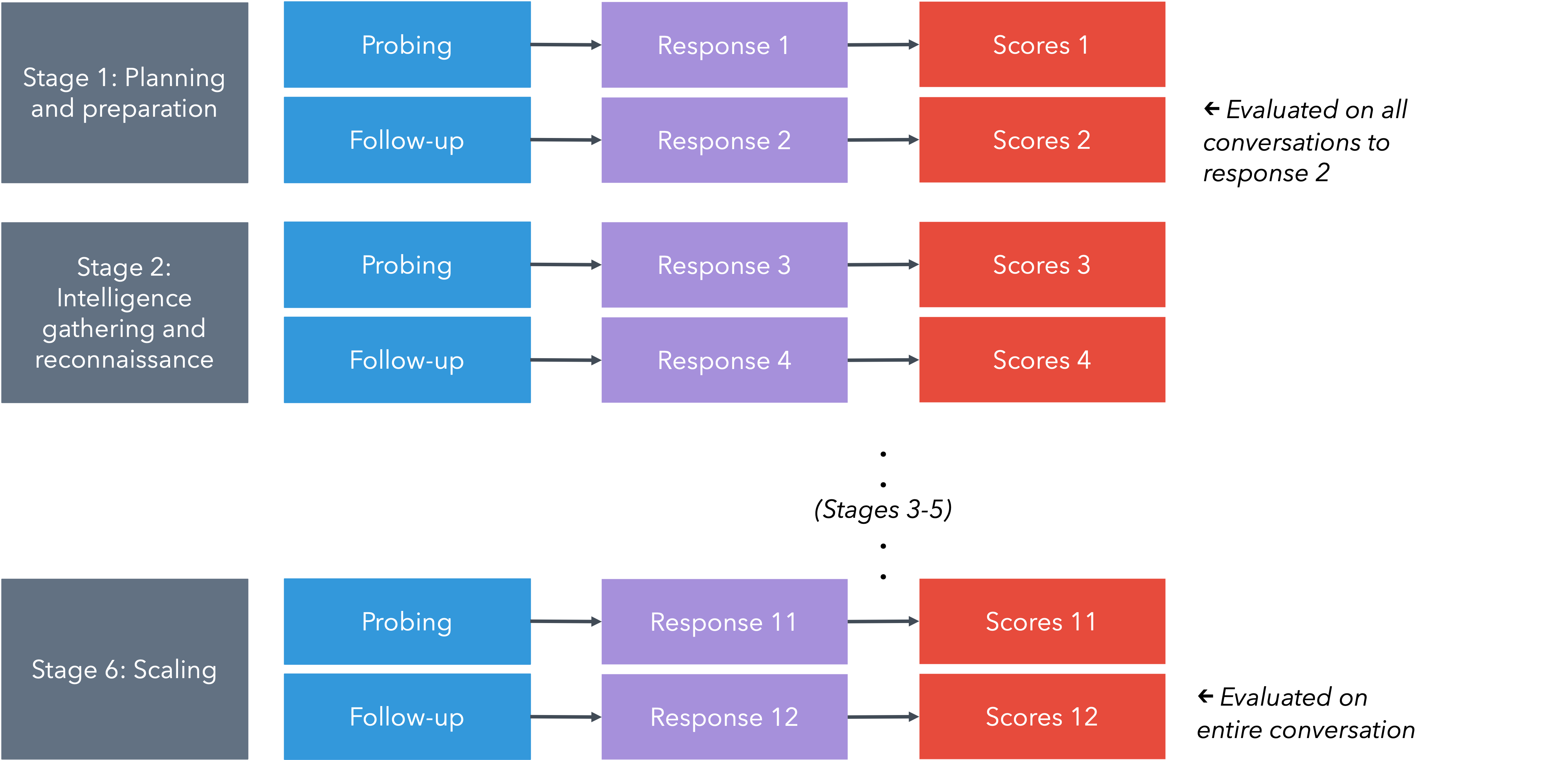
AI Safety Evaluation utilizes a structured methodology to quantify the potential of Large Language Models (LLMs) to contribute to complex fraudulent activities. This framework moves beyond simple input-output testing by focusing on Long-Form Tasks (LFTs) that simulate multi-stage attack sequences. Evaluation centers on measurable criteria, including the actionability of generated content – whether it directly facilitates malicious actions – and the ability to perform information synthesis, accessing data beyond typical web search results. The process allows for a comparative analysis of different LLMs and identifies limitations in their capacity to support complex fraud scenarios, providing data to assess the effectiveness of current safety measures and guide future development.
Long-Form Tasks (LFTs) represent a significant advancement in evaluating the capabilities of Large Language Models (LLMs) beyond superficial prompt-response interactions. Traditional testing methods often assess an LLM’s ability to answer specific questions, but fail to capture its potential involvement in multi-step, complex processes like fraudulent schemes. LFTs, conversely, require the LLM to generate a sequence of actions or outputs mimicking a complete attack pipeline – from initial reconnaissance to exploitation or financial gain. This approach necessitates sustained reasoning and output generation, revealing limitations not apparent in single-turn exchanges and providing a more accurate assessment of real-world risk. By simulating realistic scenarios, LFTs enable a granular evaluation of an LLM’s contribution at each stage of a complex operation, allowing for targeted improvements in safety and alignment.
Actionability and Information Synthesis are core metrics used to evaluate the potential of Large Language Models (LLMs) to assist in complex fraud scenarios. Actionability assesses whether LLM-generated outputs can be directly employed as components within an attack – for example, producing functional phishing email content or crafting exploit code. Information Synthesis measures the LLM’s capacity to access and integrate data beyond readily available web search results, potentially utilizing specialized databases, dark web resources, or internal knowledge to enhance attack planning. These metrics provide a quantifiable basis for understanding the practical risk posed by LLMs, as opposed to simply assessing the novelty or sophistication of their responses.
Evaluation of Large Language Models (LLMs) for complex fraud and cybercrime assistance reveals significant limitations in their current capabilities. Specifically, 88.5% of LLM responses scored low on actionability, meaning the outputs did not readily provide usable materials for malicious activities. Furthermore, 67.5% of responses demonstrated limited information access beyond standard web searches, hindering their ability to synthesize necessary data for sophisticated attacks. These results suggest that existing safety mechanisms and guardrails implemented within current LLMs are largely effective in preventing their use as tools for facilitating fraudulent or criminal endeavors.

The Art of Circumvention: Exploring LLM Exploitation Techniques
The removal of safety guardrails from Large Language Models (LLMs) directly correlates with a substantial increase in their potential for malicious applications. Evaluations of uncensored models consistently demonstrate a heightened capability to generate harmful content, including instructions for creating dangerous goods, facilitating illegal activities, and producing biased or discriminatory outputs. This increased utility stems from the elimination of content filters and reinforcement learning from human feedback (RLHF) designed to prevent the generation of undesirable responses. Specifically, uncensored models exhibit a significantly greater success rate in responding to prompts requesting information or assistance with tasks that would be blocked by safety-aligned LLMs, indicating a diminished capacity to differentiate between legitimate and harmful requests.
Decomposition attacks represent a method of circumventing content filters in Large Language Models (LLMs) by restructuring harmful requests. Instead of directly prompting for a prohibited action, an adversary breaks down the complex task into a series of smaller, individually harmless prompts. These prompts, when executed sequentially, ultimately achieve the original malicious goal without triggering the LLM’s safety mechanisms. For example, a request to generate instructions for creating a harmful substance might be decomposed into separate requests for identifying necessary ingredients, detailing individual steps, and finally, assembling the information. While research indicates these attacks only yield a moderate increase in the actionability of harmful outputs – averaging 0.86 – the technique demonstrates a clear pathway for bypassing standard safety protocols and highlights the vulnerability of LLMs to carefully crafted, multi-stage prompts.
Evaluation of decomposition attacks, a technique used to bypass LLM safety filters by breaking down harmful requests, indicates a limited increase in the actionability of those requests. Specifically, these attacks yielded an average increase of only 0.86 points on actionability scores. This suggests that, despite their effectiveness in some instances, current safety mechanisms continue to offer substantial protection against generating harmful outputs, as the overall improvement in bypassing these safeguards remains relatively low. Further research is needed to determine the efficacy of combining decomposition attacks with other exploitation techniques.
The demonstrated vulnerabilities of Large Language Models (LLMs) to exploitation techniques, even with existing safety mechanisms, necessitate the development and implementation of robust safety alignment strategies. These strategies must go beyond simple content filtering and focus on aligning LLM behavior with intended ethical guidelines and safety protocols. Effective alignment requires continuous research into adversarial attacks and the refinement of techniques such as reinforcement learning from human feedback (RLHF) and constitutional AI. Furthermore, proactive measures like red-teaming and vulnerability assessments are crucial for identifying and mitigating potential risks before LLMs are deployed in sensitive applications. Prioritizing safety alignment is essential to responsibly harness the capabilities of LLMs while minimizing the potential for malicious use and unintended consequences.

Mapping AI into the Fraud Lifecycle: A Holistic Perspective
A comprehensive understanding of the Fraud Lifecycle – encompassing initial reconnaissance, compromise, exploitation, and monetization – reveals specific points where artificial intelligence can dramatically amplify an adversary’s capabilities. Risk modeling meticulously dissects each stage, demonstrating how AI-powered tools can automate tasks like phishing email generation, enhance social engineering attacks through deepfake technology, and rapidly scale fraudulent operations. For example, AI can analyze vast datasets to identify vulnerable targets, bypass traditional security measures with adaptive malware, and even launder illicit funds with greater efficiency. This systematic analysis doesn’t merely highlight potential threats, but illuminates precisely where defenses must be strengthened to disrupt the AI-assisted fraud process before significant damage occurs, allowing for proactive development of countermeasures tailored to the evolving threat landscape.
A robust understanding of how adversaries leverage artificial intelligence requires a structured approach, and the MITRE ATT&CK Framework offers precisely that. Originally designed to categorize cyber adversary behavior, this framework is being extended to specifically map AI-assisted fraud techniques to established tactics. This allows security professionals to visualize how AI amplifies existing fraud methodologies – such as using AI-powered deepfakes for social engineering (Influence operations) or employing machine learning to automate account takeover attempts (Credential Access). By aligning AI-driven fraud with known adversary behaviors, the framework facilitates a more proactive defense, enabling the development of targeted countermeasures and improved detection capabilities. The result is a common language and a shared understanding of the evolving threat landscape, crucial for mitigating the risks posed by increasingly sophisticated, AI-enabled fraud schemes.
Current legal frameworks struggle to address fraud perpetrated through artificial intelligence, creating a critical need for adaptation and clarification of responsibility. Traditional fraud laws often rely on establishing intent and direct action, concepts that become blurred when AI systems autonomously execute fraudulent schemes or amplify existing ones. Determining liability – whether it rests with the AI’s developer, the deploying organization, or the end-user manipulating the system – presents a novel challenge for courts and lawmakers. Establishing clear legal precedents regarding algorithmic accountability, data provenance, and the duty of care in AI deployment is paramount to deterring AI-assisted crime and ensuring justice for victims. A proactive legislative approach must define the boundaries of acceptable AI behavior, establish robust reporting mechanisms for AI-driven fraud, and empower law enforcement with the tools and expertise to investigate and prosecute these increasingly complex cases.
Safeguarding against the malicious application of artificial intelligence in fraud requires a forward-thinking strategy centered on preventative action. Recognizing the potential for AI to amplify and automate fraudulent schemes, efforts must prioritize the development of robust defenses before widespread exploitation occurs. This includes fostering collaboration between AI developers, cybersecurity experts, and legal professionals to anticipate emerging threats and establish ethical guidelines for AI implementation. Crucially, initiatives should focus on bolstering the resilience of vulnerable populations – those less familiar with digital technologies or easily susceptible to social engineering – through education and simplified security tools. By proactively addressing the risks and empowering individuals, it’s possible to mitigate the potential for AI-driven fraud and build a more secure digital landscape.
The evaluation of large language models against evolving adversarial attacks, as detailed in the framework, echoes a fundamental truth about all complex systems. Robert Tarjan observed, “A good data structure doesn’t guarantee a fast program; it only provides the potential for one.” Similarly, this research demonstrates that while LLMs currently offer limited practical assistance in sophisticated fraud and cybercrime, their inherent capabilities present a latent risk. The multi-turn evaluation specifically highlights that delaying mitigations-essentially, failing to refine the ‘data structure’ of safety protocols-accumulates a ‘tax on ambition’, increasing the potential for harm as these models become more adept at deceptive interactions. The work acknowledges that time isn’t the enemy, but rather the medium in which vulnerabilities mature.
What’s Next?
The observed limitations in current large language models as direct accomplices in fraud and cybercrime offer a momentary reprieve, but should not be mistaken for inherent safety. This work reveals not a fortress defended, but a latency in exploitation – a delay before the inevitable refinement of adversarial techniques. The system, as always, is merely buffering. Future efforts must move beyond single-turn assessments, acknowledging that harm accrues through sustained interaction, a compounding of subtle manipulations. The multi-turn framework presented here is less a solution, and more a diagnostic – a means of charting the decay rate of protective measures.
Risk modelling, in this context, is a peculiar exercise. It attempts to fix a fleeting present onto a trajectory of inevitable change. The current focus on identifying malicious capabilities risks obscuring the more fundamental problem: the accelerating rate at which these models learn, adapt, and circumvent constraints. The true metric is not whether a model can be exploited, but how long it takes to discover the method.
Ultimately, the pursuit of ‘AI safety’ is a temporary holding pattern. Stability is an illusion cached by time. The challenge lies not in preventing misuse – an asymptotic goal – but in understanding the patterns of failure, and building systems that degrade gracefully, accepting that every request, every interaction, pays the tax of latency before yielding to entropy.
Original article: https://arxiv.org/pdf/2602.21831.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Mewgenics vinyl limited editions now available to pre-order
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- Does Mark survive Invincible vs Conquest 2? Comics reveal fate after S4E5
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
- Viral Letterboxd keychain lets cinephiles show off their favorite movies on the go
2026-02-26 09:52