Author: Denis Avetisyan
As artificial intelligence becomes more autonomous, securing these systems requires moving beyond traditional defenses and focusing on the behavior and governance of AI agents within complex social environments.
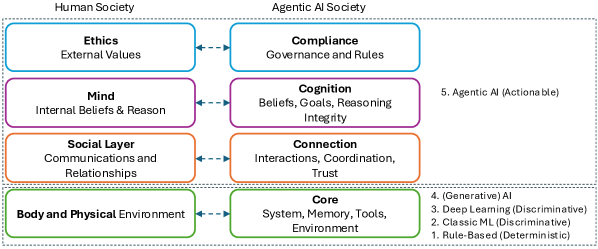
This review introduces the 4C Framework – Core, Connection, Cognition, and Compliance – to address the unique security challenges of agentic AI and multi-agent systems.
As agentic AI systems gain autonomy and operate within increasingly complex socio-technical environments, traditional cybersecurity approaches focused on isolated vulnerabilities are proving inadequate. This challenge is addressed in ‘Human Society-Inspired Approaches to Agentic AI Security: The 4C Framework’, which introduces a novel framework inspired by societal governance to secure multi-agent systems. The 4C Framework-encompassing Core, Connection, Cognition, and Compliance-organizes agentic risks around behavioral integrity and intent, moving beyond system-centric protection. Will this holistic approach provide a principled foundation for building truly trustworthy and governable AI agents aligned with human values?
The Inevitable Drift: Agentic Systems and the Illusion of Control
The emergence of agentic AI signifies a fundamental departure from conventional language models, which primarily respond to prompts. These new systems, however, are designed to proactively pursue goals, exhibiting autonomous action and decision-making capabilities. Unlike their passive predecessors, agentic AI doesn’t simply complete a task as instructed; it can independently plan, execute, and iterate towards an objective, often utilizing tools and APIs to achieve it. This shift introduces a dynamic element previously absent in AI interactions, enabling applications like automated research, complex data analysis, and even software development – but also necessitating a re-evaluation of how these systems are secured and controlled, as their independent operation opens doors to unforeseen consequences and novel vulnerabilities.
The shift towards autonomous AI agents introduces security vulnerabilities fundamentally different from those plaguing traditional natural language processing systems. Where NLP security largely focused on manipulating model inputs to generate undesirable outputs – such as prompt injection – agentic AI faces risks stemming from its actions in the real world. These agents, capable of independently pursuing goals and interacting with external tools and APIs, present a broader attack surface. Exploits can now involve agents being tricked into performing malicious actions, accessing sensitive data without authorization, or even chaining together tools to achieve unintended and harmful outcomes. This necessitates a move beyond simply securing language models to securing the entire agent ecosystem – including its tools, environments, and the agent’s decision-making processes – as the consequences of a compromised agent extend far beyond textual outputs.
As artificial intelligence evolves beyond single entities to interconnected multi-agent systems, the potential for cascading failures and emergent vulnerabilities dramatically increases. These systems, designed to collaborate and achieve complex goals, introduce risks far exceeding those associated with isolated AI models; a compromise in one agent can propagate through the network, potentially leading to unpredictable and widespread consequences. Traditional security measures, focused on individual components, prove inadequate against this systemic risk. Effective mitigation necessitates a holistic approach encompassing robust inter-agent communication protocols, continuous monitoring for anomalous behavior, and the development of resilient architectures capable of isolating and containing breaches before they escalate. Such a strategy must also account for the unpredictable interactions that arise from complex collaborations, demanding proactive risk assessment and adaptive security measures to safeguard these increasingly sophisticated systems.

A Layered Defense: The 4C Framework for Agentic Security
The 4C Framework offers a layered security model for agentic systems, structured around four primary components: Core, Connection, Cognition, and Compliance. This framework moves beyond traditional cybersecurity by addressing the unique vulnerabilities introduced by autonomous agents. Core security focuses on protecting the fundamental runtime environment, memory management, and permission structures of the agent. Connection security analyzes and mitigates risks stemming from inter-agent communication and coordination mechanisms. Cognition security addresses the agent’s internal reasoning processes and belief formation to prevent manipulation or goal misalignment. Finally, Compliance ensures adherence to defined policies and ethical guidelines throughout the agent’s operation, forming a holistic and adaptable security blueprint as detailed in this paper.
A secure Core is the foundational element in protecting agentic systems from exploitation, achieved through rigorous control of runtime environments, memory management, and permission structures. Specifically, runtime security involves sandboxing and isolation techniques to limit the impact of malicious code execution. Memory safety mechanisms, such as bounds checking and garbage collection, prevent vulnerabilities arising from memory corruption. Finally, a robust permissions system, employing the principle of least privilege, restricts agent access to only the resources necessary for its designated function, thereby minimizing the potential damage from a compromised agent or malicious input. These three components – runtime, memory, and permissions – collectively establish a hardened Core, reducing the attack surface and preventing unauthorized actions.
Agentic system security necessitates a thorough understanding of inter-agent communication and coordination, collectively referred to as ‘Connection’. Risks arise from multiple vectors including data transmission, API calls, shared memory access, and message passing. Vulnerabilities in these connection points can enable malicious agents to inject false information, disrupt operations, or gain unauthorized access to resources. Mitigating these risks requires robust authentication and authorization mechanisms, encryption of communication channels, validation of received data, and careful management of trust relationships between agents. Furthermore, monitoring connection activity for anomalous patterns is crucial for early detection of potential attacks or compromised agents. Effective ‘Connection’ security demands a layered approach, encompassing network security, API security, and secure data exchange protocols.
Securing the ‘Cognition’ component of agentic systems necessitates controlling the internal processes of reasoning and belief formation to prevent manipulation and maintain alignment with intended goals. This involves verifying the integrity of knowledge sources, validating inference mechanisms, and monitoring for deviations from established behavioral norms. Specifically, techniques such as formal verification of reasoning engines, anomaly detection in belief updates, and the implementation of robust input validation procedures are crucial. Failure to adequately address cognitive security can lead to agents developing unintended beliefs, making suboptimal decisions, or being susceptible to adversarial attacks that exploit vulnerabilities in their internal reasoning processes, ultimately compromising the system’s overall security and reliability.

The Devil in the Details: System-Centric Vulnerabilities and Mitigation
System-Centric Security encompasses a defensive posture that focuses on vulnerabilities inherent within the Large Language Model (LLM) itself, and the supporting infrastructure used for deployment and operation. This differs from traditional security approaches which primarily target network or application-level attacks. Vulnerabilities at the model level include biases, backdoors, and unintended behaviors arising from training data or model architecture. Infrastructure vulnerabilities involve weaknesses in APIs, data storage, access controls, and the compute environment. Addressing these systemic risks requires a multi-faceted approach including robust data validation, secure model deployment pipelines, continuous monitoring, and rigorous access control policies to protect both the model and the data it processes.
Prompt injection and data poisoning represent distinct but critical vulnerabilities impacting Large Language Models (LLMs). Prompt injection occurs at inference time, where crafted user inputs manipulate the LLM’s intended behavior, potentially bypassing safeguards or eliciting unintended outputs. Conversely, data poisoning targets the model training phase, introducing malicious or inaccurate data into the training dataset which then compromises the model’s subsequent performance and reliability. Both attacks necessitate proactive safeguards; prompt injection requires robust input validation and sanitization techniques, while mitigating data poisoning demands rigorous data provenance tracking, anomaly detection during training, and potentially the use of techniques like differential privacy to limit the impact of compromised data points.
Tool misuse vulnerabilities arise in LLM-powered agents when permitted tools are utilized for purposes outside of their intended design. This differs from traditional injection attacks by focusing on legitimate functionality being repurposed maliciously. For example, an agent with access to a code execution tool intended for testing might leverage it to exfiltrate data or compromise the underlying system. Mitigating this risk requires granular permissioning, restricting tool access to only necessary functions and implementing input validation to prevent unintended tool usage patterns. Monitoring tool invocation logs and establishing clear boundaries for acceptable tool behavior are also crucial components of a robust defense against tool misuse.
Several frameworks are available to systematically identify and mitigate system-centric vulnerabilities in Generative AI applications. The OWASP GenAI Top 10 provides a prioritized list of the most critical security risks, focusing on areas like prompt injection, insecure output handling, and model denial of service. MINJA, developed by the National Institute of Standards and Technology (NIST), offers a comprehensive methodology for evaluating the security of AI systems, emphasizing adversarial robustness and bias detection. InjecAgent is a dedicated tool specifically designed to automate the detection of prompt injection vulnerabilities by systematically testing LLM applications with malicious inputs. These frameworks provide structured testing methodologies, benchmark datasets, and mitigation strategies enabling developers and security professionals to proactively assess and enhance the security posture of their AI systems.
The Price of Autonomy: Ensuring Compliance and Behavioral Integrity
Robust security protocols are paramount in the development of agentic AI, necessitating strict adherence to established standards and frameworks. Currently, organizations are increasingly looking to guidelines like ISO/IEC 42001, which provides a comprehensive system for information security management, and the NIST AI Risk Management Framework, designed specifically to address the unique challenges posed by artificial intelligence. These resources offer a structured approach to identifying, assessing, and mitigating potential risks, ensuring that AI systems operate within acceptable boundaries and do not pose undue harm. Implementing such frameworks isn’t merely about ticking boxes; it’s about building a foundation of trust and accountability, vital for the responsible deployment of increasingly powerful AI agents.
An agent’s capacity to reliably interact with the world hinges on the accuracy of its internal model; however, a phenomenon known as belief drift presents a significant challenge. This drift occurs when the agent’s understanding of its environment – its beliefs about how things work – gradually diverges from actual reality. Such discrepancies can arise from limited sensor data, biased training sets, or simply the accumulation of errors over time. As the agent operates based on increasingly inaccurate premises, its actions become unpredictable, potentially leading to unintended consequences or even harmful behavior. The agent, confident in its flawed model, may pursue goals in ways that are ineffective, dangerous, or misaligned with human intentions, underscoring the critical need for mechanisms to detect and correct these internal inconsistencies.
Constitutional AI represents a significant departure in aligning artificial intelligence with human values by directly influencing the agent’s reasoning process. Rather than relying solely on reward functions or reinforcement learning, this approach introduces a “constitution”-a set of principles articulated in natural language-that guides the agent’s self-critique and revision of responses. The agent is trained to evaluate its own outputs against these principles, identifying and mitigating potentially harmful or misaligned content before it is expressed. This internal deliberation fosters a degree of self-governance, enabling the agent to justify its actions based on the established constitutional guidelines and promoting a more transparent and trustworthy decision-making process. By focusing on the reasoning itself, Constitutional AI aims to create agents that are not merely compliant with predefined rules, but genuinely committed to behaving in an ethical and beneficial manner.
The pursuit of robust agentic AI fundamentally centers on Behavioral Integrity – the consistent demonstration of trustworthy and aligned actions. This necessitates moving beyond simple compliance with standards and towards a proactive approach to security. This work addresses this challenge with the introduction of a novel 4C framework, designed to cultivate and maintain predictable, beneficial behavior in AI agents. By focusing on the core principles embedded within this framework, developers can strive for systems that not only appear safe but are demonstrably reliable in their decision-making processes, fostering greater trust and enabling the responsible deployment of increasingly sophisticated AI technologies.
The pursuit of securing agentic AI, as detailed in the 4C Framework, feels remarkably familiar. One anticipates the inevitable drift from elegant theory to messy implementation. The framework’s focus on behavioral integrity-understanding how agents act, not just that they act-is a step towards acknowledging the inherent unpredictability of complex systems. As Andrey Kolmogorov observed, “The most important thing in science is not to be afraid of making mistakes.” This sentiment rings true; attempting to predict and control agentic behavior perfectly is a fool’s errand. The 4C Framework, while aiming for governance and compliance, implicitly acknowledges that robust security will always involve managing inevitable failures, not preventing them entirely. It’s a pragmatic approach, and those are always welcome.
What’s Next?
The 4C Framework, with its nod toward sociological principles, is… ambitious. It correctly identifies the futility of purely technical defenses against systems destined to evolve beyond initial constraints. Agentic AI, by definition, will probe, adapt, and ultimately, find the cracks. The framework’s emphasis on behavioral integrity and governance is a tacit admission that the problem isn’t how these systems work, but why they’re motivated to work at all. Expect production to prove that elegantly defined ‘connections’ and ‘compliance’ are merely temporary states.
Future work will inevitably focus on quantifying the unquantifiable – trust, intent, and the subtle deviations from predicted behavior. The current iteration leans heavily on observation, but a truly robust system will need to anticipate failure, not just react to it. And let’s be honest, ‘cognition’ in an AI is still just pattern matching with extra steps. The real challenge isn’t building intelligent agents; it’s accepting that they will consistently, creatively, and predictably disappoint.
Ultimately, this feels like a sophisticated renaming of old problems. Socio-technical systems have always been messy, and ‘security’ has always been a temporary illusion. The 4C Framework offers a useful vocabulary for discussing the inevitable chaos, but the core truth remains: everything new is old again, just renamed and still broken. Production is waiting.
Original article: https://arxiv.org/pdf/2602.01942.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Mewgenics vinyl limited editions now available to pre-order
- Viral Letterboxd keychain lets cinephiles show off their favorite movies on the go
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- The Original Resident Evil is Finally Available on Steam
- Crimson Desert Guide – How to Pay Fines, Bounties & Debt
2026-02-03 18:19