Author: Denis Avetisyan
A new framework automatically constructs and expands a comprehensive cybersecurity knowledge graph by intelligently integrating diverse threat intelligence sources.
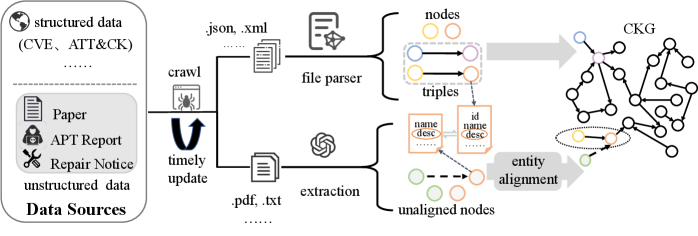
TRACE leverages large language models and a robust ontology to create a more complete and timely cybersecurity knowledge graph than previously possible.
The increasing velocity of cyber threats often outpaces the ability of security knowledge graphs to incorporate critical, rapidly evolving intelligence. To address this challenge, we introduce TRACE: Timely Retrieval and Alignment for Cybersecurity Knowledge Graph Construction and Expansion, a novel framework that leverages large language models and a comprehensive ontology to integrate both structured and unstructured cybersecurity data. Experimental results demonstrate that TRACE achieves a 1.8x increase in node coverage and outperforms existing LLM-based entity extraction methods by 7.8%, yielding a more comprehensive and current knowledge representation. Will this enhanced knowledge graph capability empower security teams to proactively anticipate and mitigate emerging threats with greater efficacy?
The Illusion of Insight: Fragmented Intelligence in a Connected World
The modern cybersecurity landscape is characterized by a troubling paradox: an abundance of data coupled with a scarcity of actionable intelligence. Information regarding potential threats originates from a multitude of sources – meticulously organized structured databases detailing known malware signatures, voluminous unstructured reports from incident responders, and the constantly shifting currents of the dark web. However, these sources frequently operate as isolated islands of information, creating significant siloes. This fragmentation prevents a holistic understanding of emerging threats; a crucial indicator spotted in a dark web forum might remain unconnected to a suspicious network event logged in a security information and event management (SIEM) system, or a detailed vulnerability assessment may not correlate with observed exploitation attempts. Consequently, security teams struggle to piece together a complete picture, hindering their ability to proactively identify, prioritize, and respond to evolving cyber risks.
Current cybersecurity systems often grapple with a critical limitation: the inability to synthesize information from varied and disconnected sources. While threat data accumulates from structured logs, intelligence reports, and the often-opaque dark web, conventional security information and event management (SIEM) systems and analytical tools frequently lack the capacity to correlate these diverse formats effectively. This creates significant delays in threat identification and response, as analysts are forced to manually sift through fragmented data, increasing the window of opportunity for malicious actors. The result is a diminished ability to detect sophisticated, multi-stage attacks that leverage information spread across multiple sources, ultimately leaving organizations vulnerable to breaches and data loss.
Effective cybersecurity demands a shift beyond simply collecting threat data; the true challenge lies in synthesizing it. Current intelligence relies on fragmented sources – structured databases, free-form reports, and the nebulous dark web – each offering a partial view of the threat landscape. To overcome this, researchers are exploring novel knowledge representation techniques, moving away from simple data aggregation towards systems capable of unifying disparate data types and reasoning about their relationships. These approaches aim to build a holistic understanding of threats, enabling automated analysis, proactive defense, and a faster, more accurate response to evolving cyberattacks. The goal is not merely to store information, but to create a dynamic, interconnected knowledge graph that mirrors the complexity of the digital threat environment.
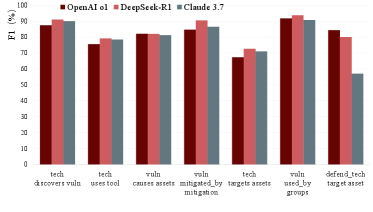
TRACE: Reconstructing the Signal from the Noise
The TRACE framework facilitates automated Cybersecurity Knowledge Graph (CKG) construction through the integration of diverse data sources. This process combines structured data, such as threat intelligence feeds and vulnerability databases, with unstructured data including security blogs, research papers, and incident reports. By consolidating these disparate sources, TRACE aims to create a comprehensive and interconnected representation of cybersecurity knowledge. The framework’s architecture is designed to ingest, process, and normalize data from various formats, enabling the identification of entities – like malware families, threat actors, and vulnerabilities – and the relationships between them, ultimately forming a robust and dynamically updated CKG.
The TRACE framework utilizes Large Language Models (LLMs) to perform entity extraction and relation classification on diverse data sources, enabling the automated population of a Cybersecurity Knowledge Graph (CKG) from previously untapped text data. Performance metrics demonstrate an F1-score of 86.08% for this process, representing a 7.8% improvement over the highest-performing LLM-based baseline. This enhancement signifies a substantial increase in the accuracy and completeness of knowledge extracted from unstructured text, directly contributing to a more robust and informative CKG.
Retrieval-Augmented Generation (RAG) improves the reliability of knowledge extraction performed by Large Language Models (LLMs) by grounding LLM responses in verified, external knowledge sources. Rather than relying solely on the parametric knowledge stored within the LLM’s weights, RAG first retrieves relevant documents or data fragments from a knowledge base based on the input query. These retrieved materials are then incorporated into the prompt provided to the LLM, effectively providing it with contextual information at inference time. This process significantly reduces the occurrence of “hallucinations” – the generation of factually incorrect or unsupported statements – and enhances knowledge fidelity by ensuring that LLM outputs are traceable to, and consistent with, the provided evidence.
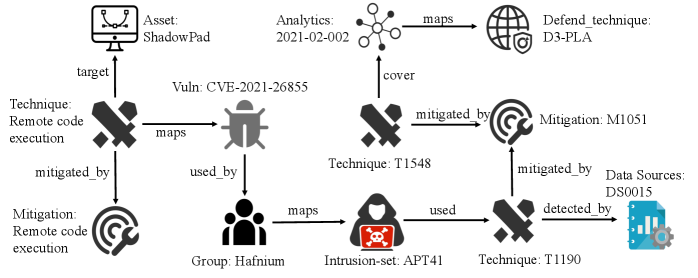
Mapping the Battlefield: Validating and Applying the Knowledge Graph
The constructed Cybersecurity Knowledge Graph (CKG) establishes relationships between critical cybersecurity elements, specifically Common Vulnerabilities and Exposures (CVEs) identified by their unique identifiers, techniques and tactics outlined in the MITRE ATT&CK Framework, and structured threat information expressed in the STIX (Structured Threat Information Expression) format. This integration allows for the representation of attack campaigns, vulnerability details, and adversary behaviors as interconnected data points. By linking CVEs to ATT&CK techniques and representing them within STIX-formatted observations, the CKG facilitates a holistic understanding of the threat landscape and supports automated analysis of attack patterns, enabling more effective threat detection and response strategies.
The Consolidated Knowledge Graph (CKG) enables detailed analysis of advanced persistent threat (APT) activity by linking threat actors, tools, and vulnerabilities. Specifically, investigations into the Hafnium Group’s exploitation of the ProxyLogon vulnerability (CVE-2021-26855, CVE-2021-26857, CVE-2021-26858, CVE-2021-27065) are facilitated by the CKG’s ability to map the group’s tactics, techniques, and procedures (TTPs) to the affected systems and the exploited vulnerabilities. Similarly, analysis of the OrpaCrab backdoor-a remote access trojan-is enhanced through the CKG’s representation of the malware’s functionality, associated indicators of compromise, and its relationship to known threat actors and campaigns.
The Constructed Knowledge Graph (CKG) comprises 4,741,428 nodes and 24,980,064 edges, signifying a substantial expansion in scale compared to previously published knowledge graphs in the cybersecurity domain. Specifically, the CKG demonstrates a 1.82x increase in the number of nodes and a 1.79x increase in the number of edges when contrasted with the largest previously known CKG. This growth indicates a considerably more extensive representation of cybersecurity concepts and their relationships, enabling more complex and detailed analysis.
Beyond Data Aggregation: Ontologies and the Future of Cybersecurity Intelligence
The Cyber Knowledge Graph (CKG) derives its power from a carefully constructed ontology, serving as the foundational structure for representing and connecting cybersecurity information. This ontology doesn’t emerge from a vacuum; it actively builds upon established standards like MITRE’s Modular Ontologies, providing a flexible and extensible framework, and the Unified Cybersecurity Ontology (UCO), which offers a common language for describing threats and defenses. By leveraging these existing resources and expanding upon them, the CKG achieves both interoperability with other cybersecurity tools and the capacity to model increasingly complex relationships between entities like vulnerabilities, threat actors, and attack patterns. This approach ensures the CKG isn’t merely a collection of data, but a semantically rich knowledge base capable of supporting advanced analytics and reasoning.
The core strength of this knowledge graph construction lies in its flexible frameworks, exemplified by BRON and CSKG4APT. These aren’t rigid, monolithic systems, but adaptable tools designed to rapidly generate specialized knowledge graphs tailored to particular threat landscapes. BRON, for instance, focuses on rapidly building graphs from open-source threat intelligence, while CSKG4APT concentrates on advanced persistent threat actors. This modularity allows security analysts to move beyond generalized threat models and focus on the specific tactics, techniques, and procedures employed by relevant adversaries. By leveraging a common ontological foundation, these frameworks ensure interoperability and facilitate the sharing of threat intelligence across different security tools and platforms, ultimately enhancing an organization’s ability to proactively defend against evolving cyber threats.
The precision with which distinct entities are correctly linked within the knowledge graph is not uniform across all categories; entity alignment performance, measured by the F1-score, demonstrates notable variation. While the system exhibits strong performance overall, the identification and correlation of vulnerability-related entities consistently achieves scores exceeding 80%. This suggests a particularly robust ability to map and integrate information pertaining to software flaws, exploits, and associated indicators. Conversely, other entity types may present greater challenges for accurate alignment, potentially due to ambiguity in naming conventions, differing data representations, or a scarcity of cross-referenced information, highlighting areas for continued refinement and focused data enrichment efforts.
The pursuit of a comprehensive Cybersecurity Knowledge Graph, as detailed in TRACE, inherently demands a willingness to dismantle established assumptions. One must actively probe the boundaries of existing ontologies and data structures to identify gaps and inconsistencies. This echoes Barbara Liskov’s sentiment: “Programs must be correct, but they also have to be understandable.” TRACE doesn’t simply accept pre-defined categories; it actively aligns entities extracted from diverse sources, essentially ‘reverse-engineering’ threat intelligence to build a more robust and accurate representation of the cyber landscape. The framework’s success stems from its ability to challenge the status quo, constantly testing and refining its understanding of the complex relationships within the cybersecurity domain.
Pushing the Boundaries
The construction of TRACE demonstrates, perhaps predictably, that a larger knowledge graph isn’t simply a ‘better’ one. The sheer volume of integrated data demands new methods of verification, a relentless pursuit of falsifiability within the connections themselves. Currently, the framework relies on the ontology as a foundational truth; a convenient starting point, certainly, but one ripe for recursive interrogation. What inherent biases are baked into the ontology, and how do these propagate through the graph? The true test isn’t expansion, but rigorous stress-testing of the existing structure.
Further work must address the inherent ambiguity within threat intelligence. Natural language, even when processed by large language models, remains frustratingly imprecise. Identifying ‘ground truth’ in cybersecurity is less about finding absolute certainty and more about establishing probabilistic confidence intervals. TRACE’s success highlights the potential of LLMs, but also underscores the need for models capable of expressing – and quantifying – their own uncertainty. A knowledge graph that knows what it doesn’t know is far more valuable than one that confidently asserts falsehoods.
Ultimately, this work isn’t about building a complete map of the threat landscape – an impossible task. It’s about creating a system that can rapidly decompose new threats into their constituent parts, revealing underlying patterns and vulnerabilities. The goal isn’t knowledge accumulation, but the development of a predictive engine, capable of anticipating the next iteration of attack. A system, in essence, that reverse-engineers the intentions of its adversaries.
Original article: https://arxiv.org/pdf/2602.11211.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- All Itzaland Animal Locations in Infinity Nikki
- Gold Rate Forecast
- How to Get to the Undercoast in Esoteric Ebb
- A Dark Scream Theory Rewrites the Only Movie to Break the 2-Killer Rule
- Australia’s New Crypto Law: Can They Really Catch the Bad Guys? 😂
- Fire Force Season 3 Part 2 Episode 24 Release Date, Time, Where to Watch
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
2026-02-16 00:42