Author: Denis Avetisyan
A new assessment reveals uneven progress in machine translation capabilities, leaving vulnerable communities at risk during emergencies.
Evaluation of machine translation systems across 35 languages highlights persistent quality gaps for low-resource languages in critical crisis communication scenarios.
Effective crisis communication relies on clear multilingual information, yet current machine translation (MT) capabilities often fall short in serving vulnerable populations. This study, framed by the question ‘Is MT Ready for the Next Crisis or Pandemic?’, evaluates the performance of commercial and large language model translation systems across 35 languages, using the TICO-19 dataset of pandemic-related text. Our findings reveal improved coverage but persistent quality gaps, particularly for low-resource languages spoken in regions most susceptible to crises. Will these limitations hinder effective responses to future global health emergencies, and what targeted improvements are needed to bridge this critical communication divide?
The Illusion of Connection: Language Barriers in Crisis
The urgency of effective communication during crises is undeniable, yet a significant impediment arises from language barriers, disproportionately impacting communities speaking low-resource languages. While global crises demand swift and widespread information dissemination, many translation tools and resources prioritize widely-spoken languages, leaving vulnerable populations isolated and at increased risk. This disparity isn’t merely a matter of linguistic diversity; it directly affects access to life-saving instructions regarding public health, disaster preparedness, and essential aid. Consequently, a failure to address these linguistic gaps can exacerbate inequalities, hindering effective crisis response and potentially leading to preventable loss of life and increased suffering within marginalized communities.
Effective crisis response hinges on the swift and accurate dissemination of information, a necessity acutely felt by vulnerable populations who may not share a common language with relief organizations or official sources. During events like pandemics, natural disasters, or political upheaval, timely access to critical instructions-regarding evacuation, healthcare, or safety protocols-can be the difference between life and death. Consequently, translation is not merely a logistical detail, but a fundamental component of equitable emergency management. These efforts demand more than simple word-for-word conversions; nuanced understanding of cultural contexts and local dialects is crucial to ensure messaging is both comprehensible and actionable, fostering trust and maximizing the impact of aid initiatives.
Existing machine translation tools frequently struggle to deliver usable results for languages with limited digital resources, creating critical communication breakdowns during crises. A recent investigation highlighted substantial deficiencies in the accuracy and clarity of translated information intended for vulnerable populations, particularly when dealing with complex public health directives or emergency warnings. This performance gap isn’t simply a matter of technical refinement; current evaluation metrics often fail to adequately capture the nuances of meaning and cultural context essential for effective communication, leading to an overestimation of system capabilities. Consequently, there is an urgent need for both innovative translation methodologies tailored to low-resource languages and more robust evaluation frameworks that prioritize real-world usability and comprehension – moving beyond simple word-matching to assess whether translated content truly resonates with and empowers intended recipients during times of need.
Automated Band-Aids: The Promise and Peril of Neural Machine Translation
Neural Machine Translation (NMT) systems facilitate rapid response in crisis scenarios by automating the translation of critical information. Unlike traditional rule-based or statistical methods, NMT utilizes deep learning to model entire sequences of words, allowing for more fluent and contextually accurate translations. This capability is crucial when time is of the essence, such as during natural disasters, public health emergencies, or humanitarian crises, where immediate communication with affected populations is paramount. By reducing the reliance on human translators, NMT enables the swift dissemination of vital updates, warnings, and instructions, potentially mitigating risks and saving lives. The technology’s speed and scalability are particularly advantageous when dealing with large volumes of multilingual data requiring near real-time processing.
The increasing adoption of commercial machine translation services, including Google Translation and Microsoft Translation, is driven by their accessibility and scalability for rapid response scenarios. Furthermore, advanced Large Language Models (LLMs) like GPT-4o and Gemini are being integrated into translation workflows due to their contextual understanding and ability to handle complex linguistic structures. These platforms offer API access and cloud-based infrastructure, facilitating deployment in real-time communication systems and crisis management tools. Organizations are leveraging these services to process large volumes of multilingual data, automate communication with affected populations, and accelerate information dissemination during emergencies, though quality remains variable depending on language pair and subject matter.
Achieving high-quality Neural Machine Translation (NMT) necessitates large volumes of training data specific to the target language pair; performance degrades significantly with data scarcity. Our analysis of the TICO-19 dataset, encompassing 35 languages, revealed substantial variation in translation quality, directly correlating with the amount of available parallel text. Languages with limited representation in the training corpus consistently exhibited lower BLEU scores and increased instances of mistranslation. Furthermore, linguistic diversity presents a challenge, as NMT models often struggle with morphologically rich languages or those employing significantly different syntactic structures from the languages heavily represented in the training data. This highlights the need for curated datasets and potentially, language-specific model adaptations to ensure reliable translation across a broad range of languages.
The Numbers Tell a Story: Validating Translation with Metrics and Data
Evaluating machine translation (MT) quality presents inherent challenges due to the complexities of natural language. While the Bilingual Evaluation Understudy (BLEU) score has historically been a primary metric, it operates by comparing n-gram overlap between machine-translated text and human reference translations. This approach focuses on lexical matching and struggles to accurately reflect semantic accuracy; a translation with high n-gram overlap may still convey a different meaning or contain factual errors. BLEU is also sensitive to the length of the translation and can be easily gamed by generating overly verbose or repetitive text. Consequently, reliance solely on BLEU can provide a misleading assessment of MT system performance, necessitating the use of more advanced metrics that consider semantic similarity and contextual understanding.
Traditional machine translation evaluation metrics, like BLEU, primarily focus on n-gram overlap and struggle to assess semantic equivalence. Metrics such as BERTScore and COMET address this limitation by leveraging pre-trained contextual embedding models. BERTScore computes a similarity score based on the cosine similarity of contextual embeddings of tokens in the candidate and reference translations, capturing semantic relatedness beyond exact word matches. COMET, a learned metric, utilizes a multilingual source-target translation model to predict human judgments of translation quality, incorporating cross-lingual consistency and fluency as key factors. These approaches provide a more nuanced assessment by considering meaning and contextual relationships, offering improvements over lexical overlap-based methods.
The TICO-19 dataset was developed to stimulate machine translation research focused on pandemic-related information for languages with limited resources. Evaluation of this dataset using the BLEU score as a metric indicates a significant disparity in translation quality depending on the translation direction. Approximately 50% of the priority languages included in the dataset achieve a usable BLEU score of 30 or higher when translating from English (XE direction). However, no languages within the dataset meet this usability threshold when translating into English (EX direction), suggesting a substantial performance gap in reverse translation for these under-resourced languages.
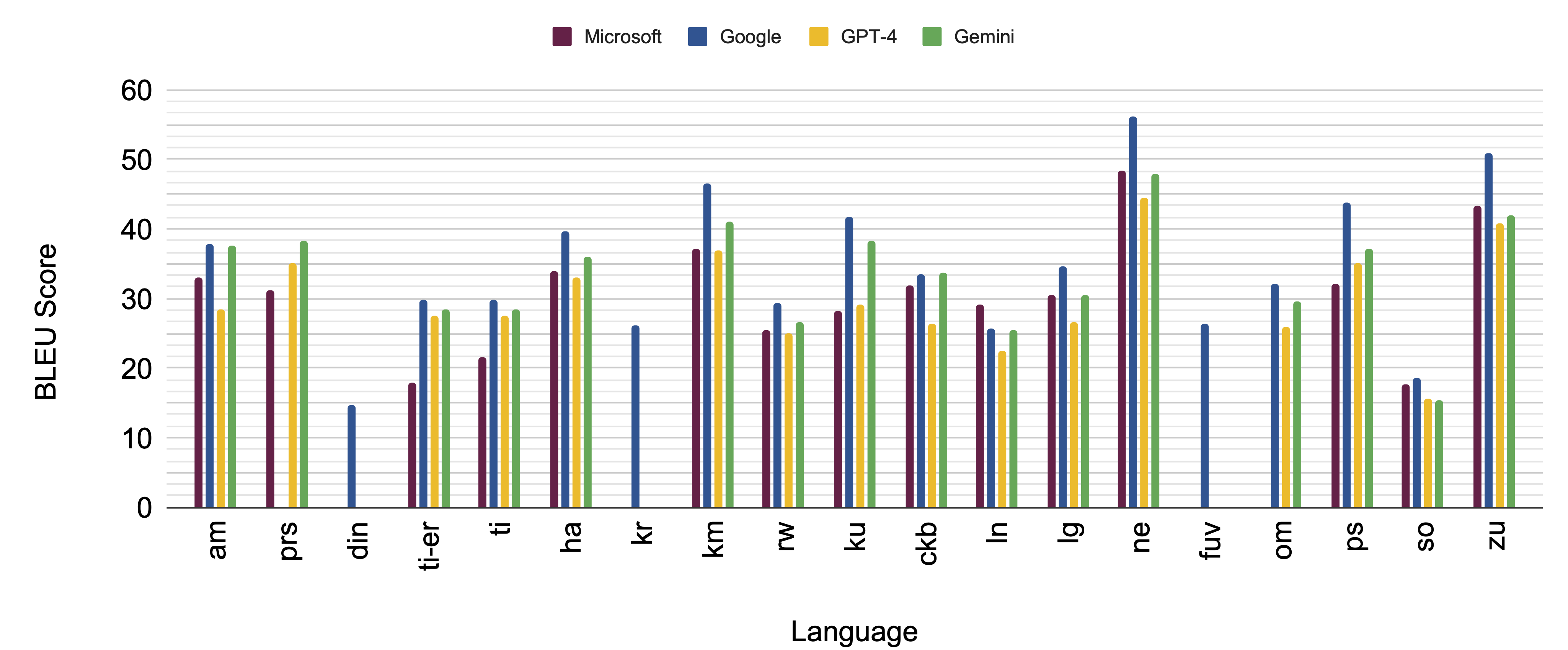
The Illusion of Coverage: Bias, Data Contamination, and the Limits of Equitable Reach
Machine translation (MT) evaluation faces a subtle but significant challenge: training data contamination. This occurs when portions of the datasets used to train translation systems inadvertently appear within the datasets used to evaluate those same systems. The result is an artificially inflated performance score, creating a misleading impression of accuracy and reliability. Essentially, the system is being ‘tested’ on data it has already ‘seen’ during training, masking its true capabilities in real-world scenarios. This contamination isn’t necessarily malicious; it can stem from overlapping web crawls or the reuse of common datasets. However, its presence undermines the validity of benchmarks and hinders meaningful progress in MT, potentially leading to overreliance on systems that perform well in controlled tests but falter when confronted with genuinely new linguistic input.
Despite advancements in machine translation, equitable access to these technologies remains a significant hurdle, particularly for communities in Africa and Asia. An analysis of translation system coverage revealed a critical gap, with several languages – including Congolese Swahili, Dinka, Fulfulde, Kanuri, and Nuer – receiving no usable translations from any tested system. This disparity underscores the need for targeted solutions that address the unique linguistic challenges present in these regions, moving beyond broadly-trained models to incorporate data and expertise specific to under-represented languages and dialects. Simply scaling existing systems will not suffice; focused development and localized data collection are essential to ensure that the benefits of machine translation are universally distributed and contribute meaningfully to crisis communication and information access for all.
The development of truly useful machine translation for crisis response hinges on a dual commitment: rigorous evaluation and broadened linguistic scope. Current benchmarks often fail to account for data contamination, leading to inflated performance metrics that don’t reflect real-world accuracy. However, simply improving evaluation isn’t enough; a parallel expansion of linguistic coverage is crucial. Research indicates significant gaps in translation support for many languages spoken in regions acutely vulnerable to crisis, particularly across Africa and Asia. By prioritizing robust evaluation methodologies-those that actively identify and mitigate data contamination-and simultaneously investing in the development of translation capabilities for a wider array of languages, it becomes possible to build systems that deliver reliable and equitable communication tools when they are needed most.
The pursuit of seamless, universal translation feels…familiar. This paper’s findings – improved coverage alongside persistent quality gaps in low-resource languages – merely confirm a predictable truth. It’s always the edge cases that unravel things, isn’t it? The core concept of assessing crisis communication tools across 35 languages highlights a recurring pattern: increased complexity doesn’t necessarily equate to increased reliability. As Vinton Cerf once observed, “Any sufficiently advanced technology is indistinguishable from magic.” But magic, as anyone who’s been on call knows, always has a trick to it – and that trick usually manifests when production traffic spikes. Everything new is just the old thing with worse docs, and in this case, the ‘magic’ of LLMs simply exposes the same old data scarcity issues in a shinier wrapper.
What’s Next?
The exercise, predictably, reveals that coverage is not quality. More languages are represented in the machine translation landscape, but to claim readiness for a crisis – a scenario that thrives on nuance and ambiguity – feels…optimistic. The TICO-19 dataset is a useful stress test, certainly, but production will inevitably find the edge cases the tidy test sets missed. It always does.
The focus, unsurprisingly, lands on low-resource languages. Throwing larger language models at the problem is the current vogue, and while they offer incremental improvements, it’s merely a redistribution of existing errors. A perfect translation in Swahili is still a statistical improbability. The real question isn’t whether the technology can translate, but whether it can translate correctly when lives depend on it. And that demands something beyond simply scaling up parameters.
Perhaps the next phase isn’t chasing higher BLEU scores, but accepting that everything new is old again, just renamed and still broken. A return to basic linguistic principles – a focus on meaning, context, and the limitations of automated systems – might prove more fruitful than another, slightly larger, neural network. After all, the most sophisticated algorithm is useless if it tells someone to evacuate towards the danger.
Original article: https://arxiv.org/pdf/2601.10082.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Mewgenics vinyl limited editions now available to pre-order
- Invincible Season 4 Episode 6 Release Date, Time, Where to Watch
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
- Nintendo Officially Rewrites Princess Peach After 41 Years
2026-01-17 03:31