Author: Denis Avetisyan
A new approach combines the efficiency of smaller AI models with the power of large language models to overcome data limitations and improve threat detection.
This review details CompFreeze, a parameter-efficient technique augmenting pre-trained language models with large language models for enhanced cybersecurity applications, data labeling, and confidence scoring.
Maintaining robust and adaptive artificial intelligence in cybersecurity is challenged by data drift and limited labeled datasets, necessitating frequent model updates. This paper, ‘Augmenting Parameter-Efficient Pre-trained Language Models with Large Language Models’, introduces CompFreeze, a novel approach combining parameter-efficient fine-tuning with the capabilities of large language models (LLMs) to address these limitations. By leveraging LLMs for both data labeling and as fallback mechanisms for low-confidence predictions, we demonstrate improved model reliability and robustness across various cybersecurity tasks. Could this hybrid approach unlock more resilient and scalable AI solutions for an ever-evolving threat landscape?
Decoding the Threat Landscape: A System Under Stress
The digital frontier is increasingly defined by a relentless surge in cybersecurity threats, demanding a paradigm shift in how organizations defend against malicious activity. No longer are simple signature-based detections sufficient; adversaries employ sophisticated techniques – polymorphic malware, zero-day exploits, and coordinated phishing campaigns – that quickly overwhelm conventional defenses. This escalating threat landscape necessitates the rapid and intelligent processing of vast quantities of threat intelligence data – logs, network traffic, vulnerability reports, and dark web chatter – to identify emerging patterns, prioritize risks, and proactively neutralize attacks. The sheer volume and velocity of these threats require automated analysis capabilities that can surpass human capacity, driving the need for innovative approaches to threat detection and response.
The sheer scale and sophistication of contemporary cyber threats have quickly overwhelmed conventional security practices. Historically, threat detection relied heavily on signature-based systems and manual analysis, methods proving increasingly ineffective against the rapid proliferation of polymorphic malware and zero-day exploits. Modern attacks generate vast quantities of data – log files, network traffic, code snippets – exceeding human analysts’ capacity for timely and accurate assessment. Consequently, advanced Natural Language Processing (NLP) techniques are becoming indispensable; these methods enable automated analysis of unstructured text data, identification of anomalous patterns, and prediction of potential threats with a speed and precision unattainable through traditional means. By leveraging NLP, security systems can now sift through massive datasets, extract meaningful insights, and proactively defend against evolving cyberattacks, shifting the paradigm from reactive response to predictive prevention.
The promise of Pre-trained Language Models (PLMs) in bolstering cybersecurity defenses is significant, yet practical implementation faces considerable hurdles. These models, while adept at understanding and generating human language, demand substantial computational resources – including powerful processing units and large memory capacities – for both training and deployment. This presents a barrier for many organizations, particularly those with limited budgets or infrastructure. Furthermore, the energy consumption associated with running complex PLMs is a growing concern, impacting sustainability efforts. Consequently, research is actively focused on techniques like model compression, knowledge distillation, and efficient fine-tuning methods to reduce the computational footprint of PLMs without sacrificing their efficacy in threat detection and analysis. Addressing these resource limitations is crucial to democratizing access to advanced NLP-powered cybersecurity tools and enabling widespread adoption.
Parameter Efficiency: A Necessary Reduction
Parameter-Efficient Fine-tuning (PEFT) methods represent a departure from traditional full fine-tuning by substantially decreasing the number of parameters updated during adaptation. Full fine-tuning modifies all parameters within a pre-trained language model (PLM), which is computationally expensive and requires significant memory, especially for large models. PEFT techniques address these limitations by introducing strategies that allow for effective adaptation with only a small fraction of the total parameters being trained. This reduction in trainable parameters directly translates to lower computational costs, reduced storage requirements, and faster training times, making it feasible to adapt large PLMs on resource-constrained hardware and for a wider range of downstream tasks.
Compacters represent a parameter-efficient fine-tuning method that constructs compact adapter layers utilizing Kronecker products and Hypercomplex Multiplication. Kronecker products facilitate the creation of larger parameter matrices from smaller ones, effectively increasing model capacity without a proportional increase in trainable parameters. Hypercomplex Multiplication, an extension of complex numbers, allows for the representation of parameters in a higher-dimensional space, enabling more nuanced adaptation with fewer parameters. These techniques combine to produce adapter layers that can be integrated into pre-trained language models, allowing for task-specific adaptation while minimizing computational overhead and preserving the knowledge embedded within the original model.
Parameter-efficient fine-tuning methods substantially reduce computational expense by limiting trainable parameters to a small fraction of the original pre-trained language model (PLM). These techniques achieve up to a 99.4% reduction in trainable parameters when contrasted with full fine-tuning, which updates all model weights. This reduction is accomplished through methods like adapter layers and selective parameter updates, allowing for significant savings in memory and processing power without substantial performance degradation. The decreased parameter count also facilitates faster training and deployment, especially in resource-constrained environments.
Layer freezing is a technique used in parameter-efficient fine-tuning to reduce computational demands and accelerate training. This method involves maintaining the weights of the pretrained language model (PLM) layers as fixed parameters, thereby preventing them from being updated during the adaptation process. Training is then focused exclusively on a smaller set of newly introduced or specifically selected parameters. This targeted approach reduces the number of trainable parameters, leading to reported training speedups of up to 40% when compared to full fine-tuning, where all PLM parameters are updated.
CompFreeze: Strategic Adaptation for the Digital Battlefield
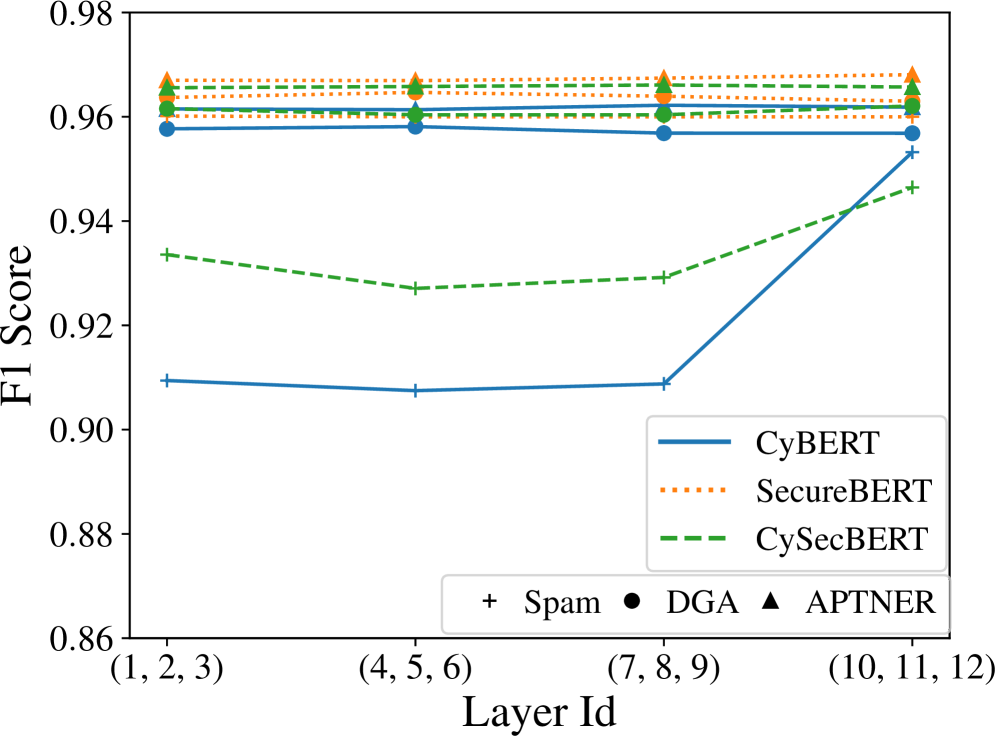
CompFreeze enhances Parameter-Efficient Fine-tuning (PEFT) by integrating Compacters – modules designed to reduce parameter counts – with strategic layer freezing. This combination allows for selective adaptation of Pre-trained Language Models (PLMs) by only training a small subset of parameters while keeping the majority frozen. The Compacter modules facilitate dimensionality reduction within the PLM, further minimizing trainable parameters. Layer freezing, implemented variably across different PLM layers, prevents catastrophic forgetting and optimizes resource allocation, resulting in improved performance and reduced computational costs compared to traditional full fine-tuning or standard PEFT techniques.
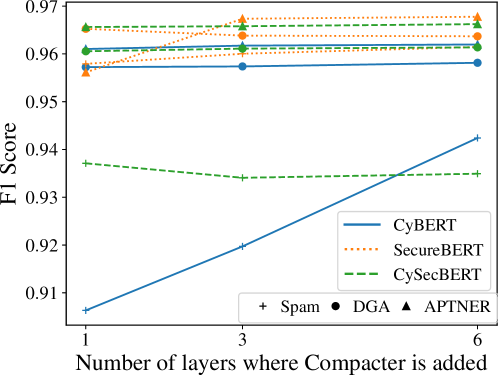
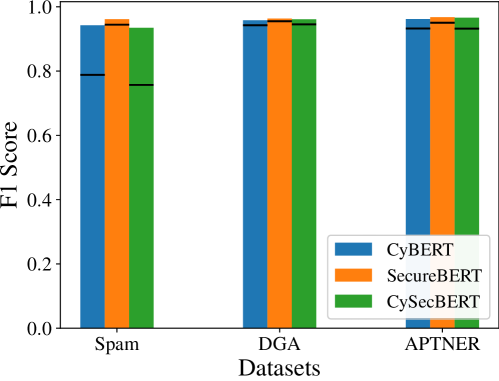
Application of the CompFreeze method to Pre-trained Language Models (PLMs) specifically designed for cybersecurity – including CyBERT, SecureBERT, and CySecBERT – has demonstrated notable performance across several key tasks. Evaluations have shown CompFreeze effectively adapts these models for Domain Generation Algorithm (DGA) Classification, identifying malicious domain names generated by malware, and Spam Detection, accurately filtering unwanted or harmful email. The methodology’s adaptability extends to more complex tasks like APTNER (Advanced Persistent Threat Named Entity Recognition) for Cyber Threat Intelligence (CTI) extraction, showcasing its versatility in analyzing security-relevant text data.
CompFreeze facilitates swift adaptation of Pre-trained Language Models (PLMs) to evolving threat environments while minimizing computational demands. Evaluations using CyBERT, SecureBERT, and CySecBERT demonstrate performance levels approaching those achieved through full fine-tuning. Specifically, the method attains F1-scores up to 96% on tasks including Spam Detection (CyBERT), Domain Generation Algorithm Classification (SecureBERT), and APTNER – a component of Cyber Threat Intelligence (CTI) extraction. This performance is realized through a combination of parameter-efficient fine-tuning and strategic layer freezing, reducing the number of trainable parameters and associated computational costs without substantial performance degradation.
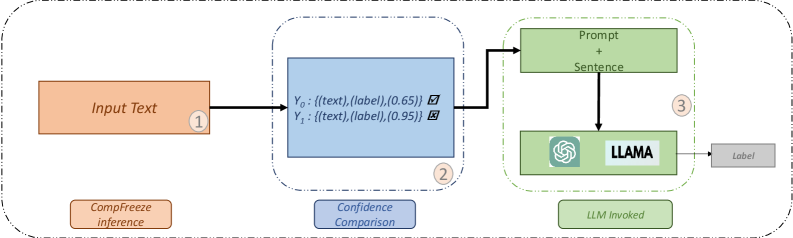
The reliability of CompFreeze predictions is directly correlated to the confidence score assigned to each output; lower confidence scores indicate increased uncertainty in the prediction. While CompFreeze achieves high F1-scores on various cybersecurity tasks, a significant number of predictions with low confidence can negatively impact the overall system performance and trustworthiness. Implementing a threshold for accepting predictions, or flagging low-confidence results for manual review, is therefore crucial for maintaining the integrity of any CompFreeze-powered cybersecurity application. Failure to address low-confidence predictions can lead to increased false positives or false negatives, potentially compromising security measures.
Beyond Efficiency: Augmenting Intelligence with Scale
CompFreeze’s reliability is significantly bolstered through a nuanced approach to prediction confidence. Rather than blindly accepting all outputs, the system incorporates a mechanism for identifying and rerouting low-confidence predictions to Large Language Models (LLMs) for independent verification. This process doesn’t simply reject uncertain results; it leverages the reasoning capabilities of LLMs to assess the validity of potentially ambiguous detections. By acting as a secondary validation layer, LLMs effectively reduce false positives and increase the accuracy of CompFreeze’s overall threat assessment. This intelligent handling of uncertainty is pivotal, ensuring that security professionals receive more trustworthy alerts and can focus resources on genuine threats, rather than investigating spurious anomalies.
Cybersecurity models often suffer from a lack of sufficiently large, accurately labeled datasets – a critical bottleneck for effective threat detection. Recent advancements leverage Large Language Models (LLMs) to address this challenge by automating the data labeling process, offering a scalable solution previously hampered by manual effort and cost. This approach involves presenting unlabeled cybersecurity data – such as network traffic logs or malware samples – to an LLM, which then assigns appropriate labels based on its understanding of malicious or benign behavior. The resulting labeled datasets, generated at a significantly faster rate than traditional methods, can be used to retrain and refine existing models, improving their accuracy and ability to identify emerging threats. This LLM-assisted labeling not only accelerates model development but also reduces reliance on scarce and expensive expert annotations, ultimately fostering a more robust and adaptable cybersecurity posture.
The efficacy of leveraging Large Language Models (LLMs) within cybersecurity systems, particularly for tasks like verifying uncertain predictions, hinges significantly on the art of prompt engineering. Constructing precise and nuanced prompts is not merely about phrasing a question; it’s about carefully sculpting the input to elicit the desired response from the LLM. A well-crafted prompt provides sufficient context, clearly defines the task, and guides the LLM toward generating accurate and relevant feedback. Conversely, ambiguous or poorly defined prompts can lead to irrelevant outputs or reinforce existing biases within the model. Consequently, dedicated effort towards prompt optimization – including iterative refinement and the exploration of different prompting strategies – is essential to unlock the full potential of LLMs as a reliable component of advanced threat detection and mitigation systems.
The integration of confidence-based routing, large language models, and refined data labeling establishes a robust cybersecurity framework capable of anticipating and neutralizing threats with greater precision. By channeling predictions with low confidence scores to LLMs for verification, the system minimizes false positives and ensures more accurate assessments of potential risks. This proactive approach, bolstered by LLM-assisted data labeling that continuously improves model accuracy, shifts cybersecurity from a reactive posture to one of preemptive threat mitigation. The resulting models not only identify known malicious activities but also demonstrate an enhanced capacity to recognize and respond to emerging, sophisticated attacks, ultimately strengthening overall system resilience and minimizing potential damage.
The pursuit of robust cybersecurity, as detailed in this work, inherently demands a willingness to challenge existing limitations. The paper’s exploration of CompFreeze, a method for augmenting parameter-efficient fine-tuning with Large Language Models, exemplifies this principle. It’s a deliberate attempt to circumvent the constraints of data scarcity and unreliable predictions – a controlled dismantling of conventional approaches to achieve enhanced performance. This aligns perfectly with Claude Shannon’s assertion: “If you will work with symbols, and if you will write down the rules, you can then manipulate the symbols according to the rules and deduce all sorts of things.” The authors, like Shannon, define the ‘rules’ of parameter efficiency and LLM integration, then ‘manipulate the symbols’ – model parameters and data – to ‘deduce’ improved cybersecurity outcomes, pushing the boundaries of what’s achievable in a field perpetually shadowed by evolving threats.
What’s Next?
The elegance of CompFreeze lies in its circumvention of exhaustive retraining. But one wonders if this efficiency isn’t merely shifting the burden-from parameter updates to the LLM itself. Is the LLM truly an oracle, or are its biases, subtly amplified in low-data regimes, simply becoming more difficult to detect? The focus on confidence scoring is a pragmatic step, yet it begs the question: what constitutes ‘low confidence’ in a system built on statistical prediction? Is it a signal of genuine uncertainty, or merely a measure of divergence from the training distribution – a perfectly confident, yet utterly wrong, assertion?
Future work must address the inherent limitations of augmenting smaller models with larger, potentially opaque, ones. Can we develop techniques to ‘interrogate’ the LLM’s reasoning, to understand why a prediction is made, not just that it is made? Perhaps the true advance won’t be in minimizing parameter updates, but in maximizing interpretability – reverse-engineering the black box to expose the underlying logic. The current emphasis on data labeling feels almost… quaint. If the goal is robust cybersecurity, should effort not be directed toward building systems that are resistant to bad data, rather than simply hungry for more of it?
Ultimately, CompFreeze, and approaches like it, represent a temporary truce in the arms race. The adversary will adapt. The system will degrade. The challenge isn’t just to build more accurate models, but to build models that fail gracefully, revealing their weaknesses before they are exploited. The interesting bugs, as always, will be the most informative.
Original article: https://arxiv.org/pdf/2602.02501.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Mewgenics vinyl limited editions now available to pre-order
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
- Viral Letterboxd keychain lets cinephiles show off their favorite movies on the go
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
2026-02-04 14:18