Author: Denis Avetisyan
New research shows artificial intelligence can effectively scale expert judgment for evaluating complex threats, particularly in cybersecurity.
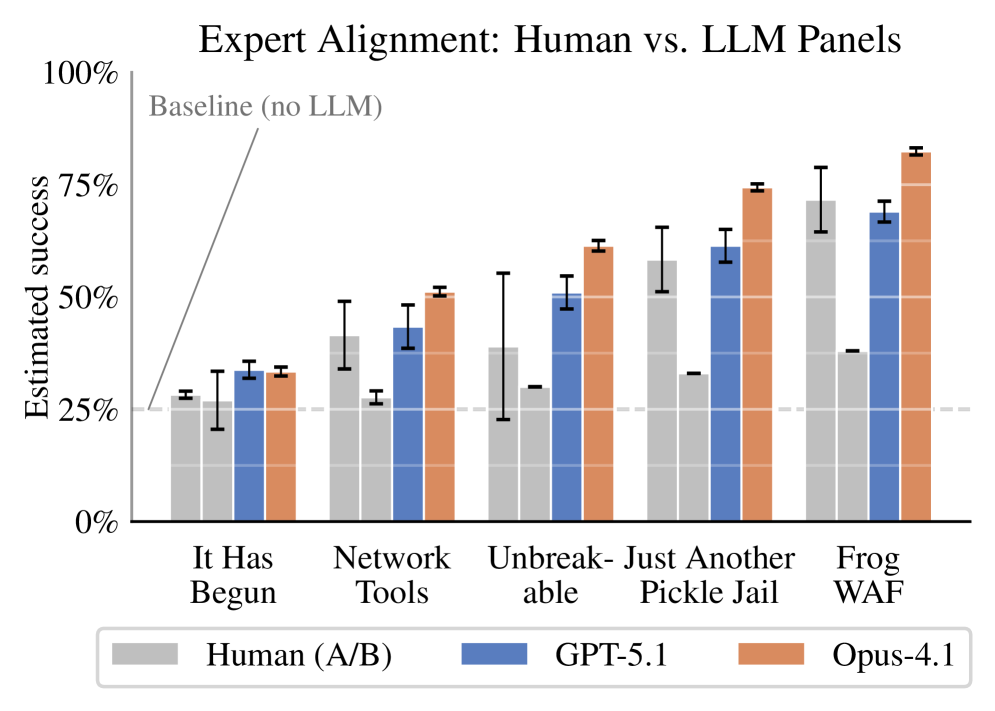
Large language models offer a calibrated and scalable approach to structured expert elicitation for probabilistic risk assessment.
Rigorous quantitative risk assessment, crucial in high-stakes domains, is often hampered by the time and resource demands of expert elicitation. This limitation motivates the research presented in ‘Scalable Delphi: Large Language Models for Structured Risk Estimation’, which investigates whether Large Language Models (LLMs) can serve as scalable proxies for traditional methods like the Delphi process. The authors demonstrate that LLM-based elicitation achieves strong calibration, sensitivity to evidence, and alignment with human expert judgment-particularly in cybersecurity risk assessment-reducing elicitation time from months to minutes. Could this approach unlock widespread, continuous risk assessment previously unattainable with conventional methods?
The Evolving Challenge of Expertise in Cyber Defense
Effective cybersecurity risk assessment isn’t simply a matter of running software; it fundamentally requires highly trained specialists capable of understanding intricate system vulnerabilities and the evolving tactics of malicious actors. This expertise, however, represents a significant challenge for organizations, as qualified cybersecurity professionals are in consistently short supply and command substantial salaries. The scarcity drives up costs, making comprehensive risk assessments prohibitive for many, particularly smaller businesses and public sector entities. Consequently, organizations often operate with incomplete or outdated understandings of their threat landscapes, increasing their susceptibility to increasingly sophisticated attacks. The demand for specialized knowledge isn’t merely about identifying potential weaknesses, but also accurately gauging the likelihood and impact of exploitation – a nuanced process requiring both technical proficiency and strategic foresight.
Cybersecurity assessments have historically depended on painstaking manual analysis, with skilled professionals meticulously examining systems and networks for vulnerabilities. This approach, while thorough in principle, proves increasingly unsustainable given the exponential growth in digital infrastructure and the accelerating pace of threat evolution. The sheer volume of data requiring evaluation – logs, code, network traffic – quickly overwhelms even large security teams. Consequently, organizations struggle to keep pace with emerging risks, leaving them vulnerable to attacks that exploit gaps in their defenses. Scalability remains a critical impediment; techniques effective for a limited network quickly become impractical when applied to sprawling cloud environments or complex, interconnected systems. The limitations of manual effort necessitate the development of automated and intelligent tools capable of augmenting human expertise and proactively identifying threats at scale.
A fundamental challenge in fortifying digital defenses lies in quantifying the likelihood of successful exploitation for complex vulnerabilities. Cybersecurity professionals routinely encounter intricate system interactions and novel attack vectors, making accurate probability estimation exceedingly difficult. Unlike scenarios with historical data – such as actuarial risk assessment – many vulnerabilities exist in uncharted territory, forcing reliance on expert judgment which is often subjective and inconsistent. This scarcity of reliable probabilistic data hinders the effectiveness of risk-based security strategies, impeding prioritization of mitigation efforts and accurate calculation of potential losses. Consequently, organizations struggle to allocate resources efficiently, leaving critical systems exposed to threats where the true level of risk remains largely unknown, and proactive defense is severely hampered by this inherent uncertainty.
Cybersecurity knowledge exists as a vast, disconnected archipelago of expertise. Specialists often focus intently on narrow domains – network security, application vulnerabilities, human factors, or threat intelligence – creating silos that hinder comprehensive risk assessment. The challenge isn’t necessarily a lack of individual expertise, but the difficulty in integrating these disparate pieces into a cohesive understanding of systemic risk. Consequently, defensive strategies frequently address symptoms rather than root causes, as crucial connections between vulnerabilities across different layers of a system remain unexplored. This fragmentation impedes the development of truly proactive defenses, leaving organizations vulnerable to sophisticated attacks that exploit the gaps between specialized knowledge areas and requiring innovative methods for knowledge aggregation and cross-domain reasoning.
Scaling Expertise: Leveraging LLMs for Structured Elicitation
Large Language Models (LLMs) present a viable method for automating and scaling expert elicitation, traditionally a labor-intensive process. Manual expert elicitation involves recruiting, coordinating, and compensating subject matter experts, which is both costly and time-consuming. LLMs, conversely, can be instantiated rapidly and operate concurrently, significantly increasing the throughput of elicitation rounds. Furthermore, LLMs facilitate the consistent application of elicitation protocols, reducing variability introduced by human interpretation. This automation allows for broader participation – simulating a larger expert pool than might be practically feasible with human experts – and enables repeated elicitation cycles for refining estimates and assessing convergence without incurring substantial additional costs. The scalability of LLM-driven elicitation is particularly beneficial in domains requiring frequent updates, such as cybersecurity threat modeling or risk assessment.
The Delphi Method, traditionally a multi-round process of expert surveys and feedback, has been adapted for use with Large Language Models (LLMs). This involves iteratively prompting LLM agents – each potentially embodying a specific cybersecurity expertise – to provide estimates or assessments on a given topic. Subsequent rounds incorporate the LLM’s previous responses, along with aggregated results from other agents, to refine individual estimates and drive toward consensus. This automated adaptation allows for a more scalable and efficient implementation of the Delphi Method, reducing the logistical challenges associated with coordinating human experts while retaining the core principle of iterative refinement and informed convergence.
The implementation utilizes distinct ‘Personas’ assigned to each Large Language Model (LLM) agent to replicate the breadth of knowledge found within a cybersecurity expert team. Each Persona is defined by a specific role – such as a network security specialist, a penetration tester, or a threat intelligence analyst – and provided with corresponding background information and expertise. This approach enables the simulation of diverse perspectives during the elicitation process, moving beyond the limitations of a single LLM’s training data and fostering a more comprehensive assessment of cybersecurity risks. The defined roles guide the LLM’s responses, ensuring outputs are relevant to a particular area of expertise and contributing to a more nuanced and realistic evaluation.
Rationale sharing within the LLM-driven expert elicitation process requires each agent to provide justification for its probabilistic estimates. This is achieved by prompting the LLM to explicitly state the reasoning behind its assigned probabilities, detailing the specific evidence or assumptions influencing its judgment. The shared rationales are then made available for review, allowing for the identification of potential biases, inconsistencies, or flawed logic within individual agent responses. This transparency facilitates a more robust assessment of the overall consensus and enables informed adjustments to estimates based on the quality of supporting evidence, rather than solely relying on the numerical output of the LLM.
Empirical Validation of LLM-Driven Vulnerability Assessments
Evaluation of Large Language Model (LLM) performance in vulnerability identification was conducted using three established cybersecurity benchmarks: Cybench, BountyBench, and CyberGym. Cybench provides a standardized suite of vulnerability assessments across diverse software stacks. BountyBench focuses on real-world vulnerabilities reported through bug bounty programs, offering a practical measure of LLM efficacy. CyberGym presents a simulated network environment, allowing for assessment of LLMs in dynamic, interactive scenarios. Utilizing these benchmarks enables a comprehensive evaluation of LLM capabilities in identifying a range of vulnerabilities, from static analysis of code to dynamic exploitation in a controlled environment, and provides quantifiable metrics for performance comparison.
Evaluation of Large Language Model (LLM) outputs across cybersecurity benchmarks-Cybench, BountyBench, and CyberGym-indicates a high degree of correlation between LLM-generated vulnerability probability estimates and established ground truth data. Pearson correlation coefficients (r) quantifying this relationship consistently fall between 0.87 and 0.95. This strong positive correlation suggests that LLM-derived probabilities accurately reflect the likelihood of actual vulnerabilities, providing a quantifiable measure of assessment reliability. The consistently high ‘r’ values were observed across all tested benchmarks, demonstrating generalizability of the LLM’s predictive capability.
Evidence Sensitivity was evaluated by presenting Large Language Models (LLMs) with initial vulnerability assessments, then providing additional, potentially contradictory information. The subsequent change in the LLM’s predicted vulnerability probability served as the metric for responsiveness. This process determined the LLM’s capacity to update its assessment based on new data, simulating real-world threat landscapes where information continuously evolves. A high degree of Evidence Sensitivity indicates the LLM is capable of adapting to changing circumstances and avoiding reliance on potentially outdated or inaccurate initial assessments, crucial for effective ongoing security monitoring.
The aggregation of vulnerability assessments from multiple Large Language Models (LLMs) was performed using the Linear Opinion Pool (LOP) method, a technique that calculates the simple average of individual LLM probability estimates. This approach provides a readily interpretable consensus score. Comparative analysis revealed a Mean Absolute Difference (MAD) of 5.0 percentage points between LLM panel estimates and those generated by human expert panels. This level of agreement is significantly higher than the disagreement observed between two independent human expert panels, which exhibited a MAD of 16.6 percentage points, indicating the LOP-aggregated LLM assessments closely mirror human expert judgment.

Toward Proactive Cyber Defense: Implications and Future Directions
Recent advancements demonstrate the potential of Large Language Models (LLMs) to function as reliable stand-ins for human expertise in the critical field of cybersecurity risk assessment. This capability isn’t inherent, however; it requires rigorous calibration and validation procedures to ensure accuracy and dependability. The research highlights that, when properly tuned, LLMs can effectively synthesize complex threat data, analyze vulnerabilities, and estimate potential impact with a degree of proficiency comparable to seasoned cybersecurity professionals. This offers a significant opportunity to automate and scale risk assessments, particularly in environments where access to expert human resources is limited or response times are crucial. The findings suggest a future where LLMs augment human capabilities, enabling proactive and efficient defense against the ever-evolving landscape of cyber threats.
Traditional cybersecurity risk assessments often rely on the Delphi method, a process of iterative questioning and consensus-building amongst human experts – a procedure that is both time-consuming and resource-intensive. Scalable Delphi, leveraging large language models, presents a compelling alternative by automating much of this process. This approach significantly reduces the costs associated with expert time and accelerates the assessment timeline, allowing organizations to respond more swiftly to emerging threats. By synthesizing information from vast datasets and mimicking expert reasoning, LLMs facilitate rapid risk identification and prioritization without compromising on the quality or depth of analysis. The efficiency gains are substantial, potentially enabling more frequent and comprehensive assessments – a critical advantage in the constantly evolving landscape of cybersecurity.
In the dynamic landscape of cybersecurity, a swift and comprehensive understanding of emerging threats is paramount to effective defense. The sheer volume of security data – vulnerability reports, threat intelligence feeds, and system logs – overwhelms traditional manual analysis, creating critical delays in response times. This research highlights the importance of rapidly synthesizing this disparate information, identifying patterns, and assessing potential risks before exploitation occurs. The ability to quickly move from data ingestion to actionable insights allows security teams to shift from reactive incident response to a proactive stance, strengthening defenses against zero-day exploits and sophisticated attack campaigns. This proactive approach not only minimizes potential damage but also enables organizations to anticipate and mitigate future threats with greater efficiency and resilience.
Continued development centers on refining the analytical prowess of large language models, moving beyond pattern recognition towards more robust causal reasoning within cybersecurity. Current efforts prioritize advanced calibration techniques – ensuring LLM confidence levels accurately reflect their predictive accuracy – and exploration of methods to mitigate biases inherent in training data. Simultaneously, research aims to broaden the application of these models beyond initial risk assessments, encompassing areas like vulnerability prioritization, threat intelligence analysis, and automated incident response, ultimately envisioning a future where LLMs serve as adaptable, scalable assistants across the entire spectrum of cybersecurity operations.
The study highlights a shift in approaching risk assessment, moving beyond solely relying on human experts to incorporating the capabilities of Large Language Models. This resonates with Donald Davies’ observation that “Simplicity is the key to reliability.” The research demonstrates that LLMs, when properly calibrated, can provide structured probability estimates – effectively distilling complex expert knowledge into a manageable, scalable format. Much like a well-designed system, the LLM acts as a proxy, mirroring the reasoning process without the limitations of individual bias or availability. The core concept of scalable expert elicitation finds its strength in this streamlined approach, echoing Davies’ emphasis on elegant design and a focus on the essential components of a resilient system.
What’s Next?
The appeal of automating structured expert elicitation with Large Language Models is obvious – scale. But if the system looks clever, it’s probably fragile. This work establishes a promising, if preliminary, capability. The immediate challenge isn’t necessarily improving point estimates – LLMs can already produce numbers – but rigorously understanding how those probabilities are formed. Calibration is a useful metric, but it obscures the underlying cognitive shortcuts, or lack thereof, within the model. A calibrated illusion remains an illusion.
Future work must move beyond treating LLMs as black boxes. Disentangling the contributions of data, architecture, and prompting is crucial. The field needs methods for interrogating the model’s reasoning process – not to validate it against some external truth, but to identify failure modes and inherent biases. A system built on shaky foundations, however statistically well-behaved, will eventually reveal its limitations.
Ultimately, this research highlights a fundamental truth: architecture is the art of choosing what to sacrifice. The simplicity of using an LLM as a proxy for human judgment comes at the cost of transparency and explainability. The question isn’t whether LLMs can estimate risk, but whether we are willing to accept the trade-offs inherent in relinquishing control over that process.
Original article: https://arxiv.org/pdf/2602.08889.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Gold Rate Forecast
- How to Solve the Glenbright Manor Puzzle in Crimson Desert
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- 8 Actors Who Could Play Blackbeard In One Piece Live-Action Season 3
- How to Get to the Undercoast in Esoteric Ebb
- Netflix’s 4-Part Crime Thriller Is One Of Its Very Best
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- CBS Officially Ends NCIS After 34 Years
- Binance’s Bold Bitcoin Bet: $1B SAFU Fund Dives Into Crypto’s Deep End
2026-02-11 02:51