Author: Denis Avetisyan
New research reveals that current anomaly detection models struggle with the complexities of real-world IoT deployments, necessitating a more rigorous and realistic benchmarking approach.
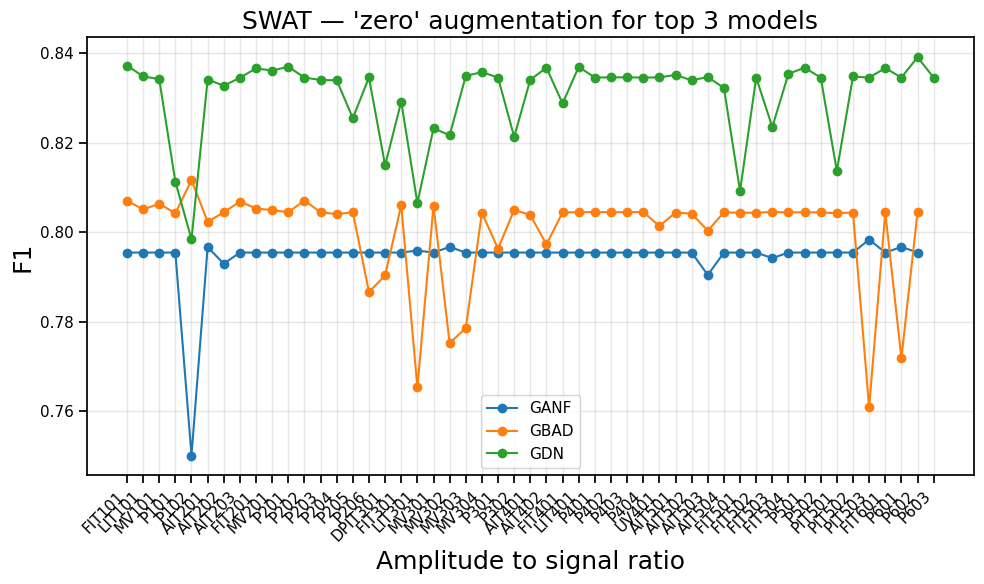
This paper introduces a deployment-first benchmarking protocol with event-level evaluation to assess anomaly detection performance under stress and data drift conditions.
While anomaly detection (AD) for critical infrastructure increasingly relies on point-level benchmarks, these often fail to reflect real-world deployment challenges. This paper, ‘Benchmarking IoT Time-Series AD with Event-Level Augmentations’, introduces a novel evaluation protocol emphasizing event-level performance under realistic stressors-including calibrated sensor dropouts, drift, and noise-to reveal how models truly behave when faced with data perturbations. Our extensive evaluation of 14 models across seven datasets demonstrates a surprising lack of universal winners, with performance heavily influenced by the specific anomaly characteristics and system dynamics. Ultimately, how can we move beyond idealized benchmarks and develop AD systems robust enough to reliably safeguard complex cyber-physical systems?
The Expanding Attack Surface of Critical Infrastructure
The operational backbone of modern life – encompassing everything from water purification and power grids to transportation networks – now heavily depends on the seamless integration of sensor data and automated control systems. This shift, while enhancing efficiency and responsiveness, simultaneously expands the potential attack surfaces available to malicious actors. Where once physical security was paramount, these digitally interconnected systems introduce vulnerabilities exploitable remotely. A compromised sensor, a manipulated data stream, or a flaw in the control logic can disrupt operations, cause physical damage, or even pose a threat to public safety. The increasing complexity of these systems, coupled with a growing reliance on interconnected networks, necessitates a proactive approach to cybersecurity, moving beyond traditional perimeter defenses to encompass the entire operational technology (OT) environment.
Critical infrastructure, encompassing systems like power grids and water treatment facilities, now functions on a foundation of continuous data streams and automated responses. However, this reliance introduces vulnerability to subtle anomalies – minute deviations from established operational norms. These aren’t necessarily catastrophic failures immediately; instead, they manifest as slight shifts in sensor readings, unexpected patterns in control system commands, or marginally altered process parameters. Crucially, these anomalies can signal either a developing equipment malfunction – a pump losing efficiency, a pipe experiencing early corrosion – or the insidious presence of malicious actors attempting to compromise the system. Detecting these deviations is exceptionally challenging, as distinguishing between benign fluctuations and genuine threats requires a deep understanding of the system’s complex, interconnected behavior and the ability to discern signal from noise.
Conventional anomaly detection techniques, designed for simpler systems, frequently falter when applied to the intricate networks governing critical infrastructure. These methods often struggle to differentiate between benign variations in operational data and genuine threats, resulting in a deluge of false positives that overwhelm human operators and obscure critical alerts. The sheer volume and velocity of data generated by modern infrastructure – encompassing thousands of sensors and control points – further exacerbate this issue, pushing traditional algorithms beyond their computational limits. Consequently, subtle but significant anomalies indicative of cyberattacks or impending equipment failure can be easily overlooked, creating a dangerous blind spot in system monitoring and potentially leading to cascading failures with far-reaching consequences. Improving detection requires moving beyond simplistic thresholds and embracing techniques capable of modeling the complex, dynamic behavior inherent in these vital systems.
Rigorous Evaluation: Stress-Testing Anomaly Detection Systems
Effective evaluation of anomaly detection systems is hampered by the inherent imbalance in real-world datasets, where anomalous instances represent a small fraction of total observations. This scarcity poses a significant challenge for traditional machine learning evaluation metrics, such as accuracy and precision, which can be misleadingly high due to the prevalence of normal data. Consequently, models may appear performant during initial testing but fail to generalize to genuinely anomalous events when deployed in operational environments. The low frequency of anomalies necessitates the use of specialized evaluation techniques and metrics, like precision-recall curves and area under the receiver operating characteristic curve (AUC-ROC), to accurately assess a model’s ability to identify rare but critical deviations from expected behavior. Furthermore, the creation of representative datasets containing sufficient anomalous examples is often difficult and costly, requiring either the simulation of anomalies or the collection of data over extended periods to capture naturally occurring events.
The Offline-Calibrated Stress Suite evaluates anomaly detection system performance by applying a series of realistic data perturbations. These stressors include Sensor Dropout, simulating sensor failures; Linear Drift and Log Drift, representing gradual changes in sensor readings over time; Additive Noise, introducing random error; and Window/Phase Shift, mimicking timing misalignments in data streams. Each stressor is applied independently to a validation dataset, allowing for systematic assessment of model robustness against specific, common data quality issues. This approach moves beyond idealized testing conditions and aims to better reflect the challenges encountered in real-world deployments.
The Offline-Calibrated Stress Suite establishes a standardized evaluation of anomaly detection robustness by scaling stressor intensity to the distribution of the validation dataset. This normalization process ensures that perturbations are applied relative to expected data characteristics, facilitating reproducible comparisons across different models and configurations. Critically, the suite demonstrates that model performance rankings are not static; models that perform highly under ideal conditions can be surpassed by others when subjected to realistic stressors, highlighting the necessity of evaluating anomaly detection systems beyond simple, clean datasets and validating their performance under conditions representative of real-world deployment.
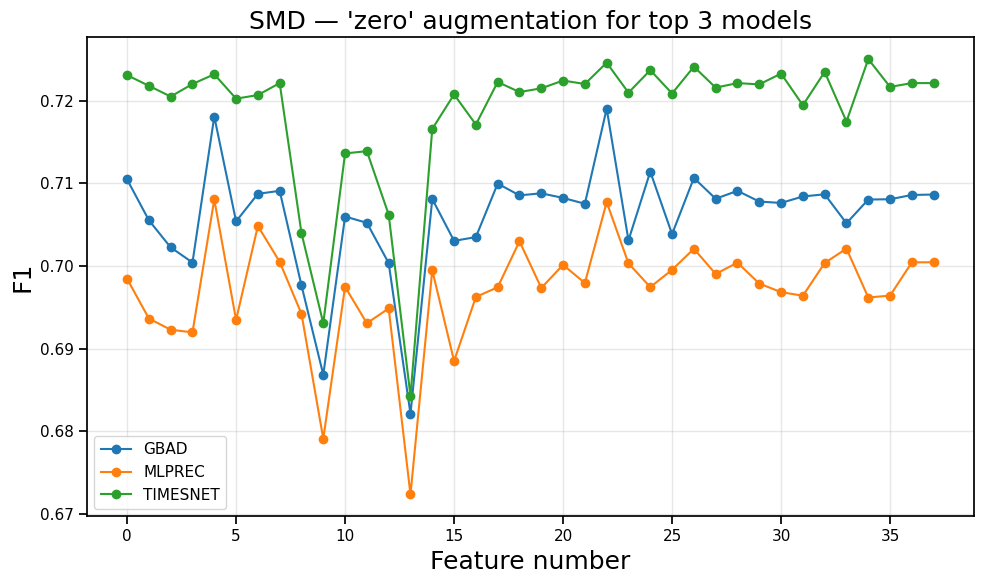
Harnessing Interdependence: Graph-Based Models for Anomaly Detection
Traditional anomaly detection methods often treat sensor data as independent streams, neglecting the correlative relationships present within complex systems. However, many industrial processes and infrastructure networks exhibit strong interdependencies between sensors; a change in one sensor’s reading frequently indicates or precedes a change in others. By representing these systems as graphs – where nodes represent sensors and edges represent relationships – models can explicitly incorporate this contextual information. This allows for a more holistic assessment of system state, enabling the identification of anomalies that might be missed when analyzing individual sensor readings in isolation. The structure of the graph, capturing these inherent relationships, facilitates feature learning that is more representative of the overall system behavior, improving the accuracy and robustness of anomaly detection.
Graph-based anomaly detection models, including Graph Autoencoders, Graph Attention Networks, and Hybrid Graph-Attention Models, represent system components as nodes within a graph and the functional relationships between them as edges. This structure allows the models to move beyond analyzing individual sensor readings in isolation and instead consider the contextual information derived from inter-sensor dependencies. The graph structure is then utilized to generate node embeddings – vector representations of each sensor – that capture not only the sensor’s intrinsic characteristics but also its relationships to other sensors in the system. These embeddings serve as enhanced feature representations, enabling more accurate identification of anomalies that manifest as deviations from established relational patterns within the graph.
Graph-based anomaly detection models, including Graph Autoencoders, Graph Attention Networks, and hybrid approaches, consistently outperform traditional methods when evaluated on benchmark datasets such as SWaT and WADI. However, performance is not uniform under stress conditions. Specifically, testing on the SWaT dataset revealed that the Graph Autoencoder experienced a 16% reduction in F1 score when subjected to additive noise, indicating a vulnerability to certain types of data corruption and a need for robust implementations to maintain reliability in real-world applications.
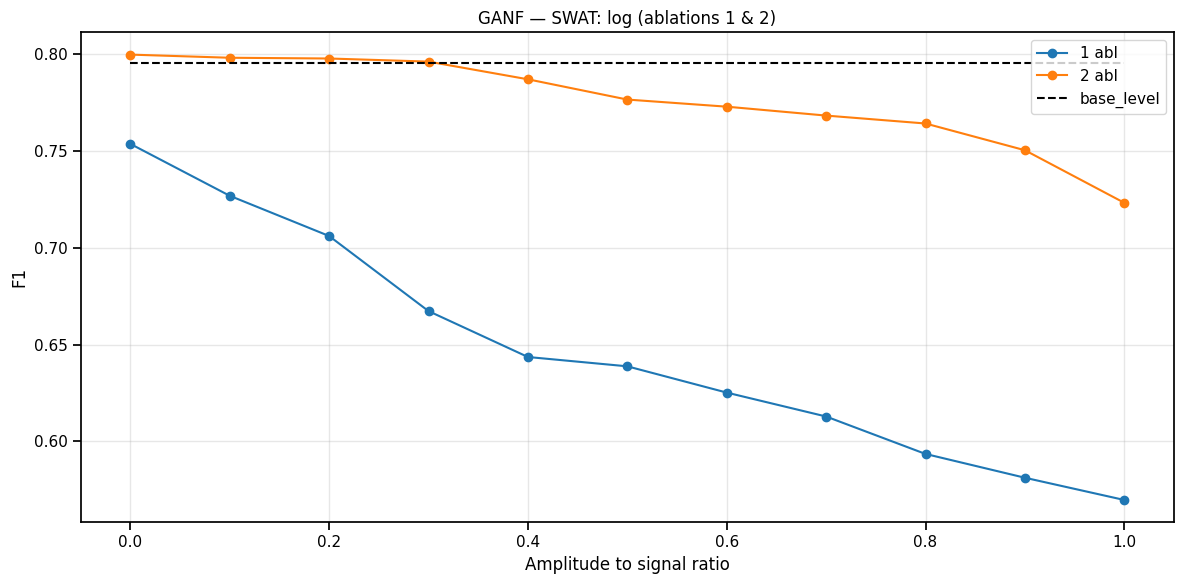
Beyond Prediction: Deploying Robust Anomaly Detection Systems
Truly impactful anomaly detection extends beyond simply flagging unusual events; it necessitates a system capable of reacting swiftly and maintaining performance amidst real-world volatility. A static model, however accurate in a controlled setting, proves ineffective when confronted with the inherent dynamism of industrial processes or complex systems. Consequently, research prioritizes solutions that exhibit resilience to changing conditions – variations in data streams, unexpected noise, or evolving system behavior. This demands a focus on rapid response times, allowing for timely intervention, and robust preprocessing techniques to mitigate the impact of imperfect data. The ultimate goal is a system that not only identifies anomalies but also supports proactive maintenance, prevents failures, and ensures continuous, reliable operation within unpredictable environments.
A crucial step beyond laboratory accuracy lies in the practical deployment of anomaly detection systems, and the Event-Level Evaluation Protocol directly addresses this need. This protocol moves beyond simple benchmark scores by prioritizing speed – measured as latency – and adaptability to evolving, real-world conditions. Importantly, the protocol champions Zero Test-Time Calibration, meaning the system performs effectively on unseen data without requiring any adjustments or fine-tuning during the testing phase. This is vital for maintaining reliable performance in dynamic environments where immediate, autonomous responses are essential; a system constantly needing recalibration is impractical for many applications. By emphasizing these deployment-centric metrics, the protocol offers a more realistic and valuable assessment of an anomaly detection system’s true potential.
Advanced anomaly detection benefits significantly from pinpointing the root cause of issues, and techniques like Sensor-Level Probing offer a pathway to achieve this. This approach doesn’t simply flag anomalies; it actively investigates which sensors are most influential in triggering those alerts, effectively narrowing the search for the source. By utilizing an ‘Anomaly Window’ – a focused time frame around the detected event – the system can concentrate its analysis, improving both speed and accuracy. Studies have demonstrated the impact of such focused preprocessing; in one industrial application, simply deactivating the most problematic sensors-identified through this probing-resulted in a remarkable 54% increase in the F1 score, underscoring that robust data handling is often as critical as the anomaly detection algorithm itself.
The pursuit of robust anomaly detection, as detailed in the benchmarking protocol, necessitates a rigorous foundation mirroring mathematical principles. The article rightly emphasizes deployment-first benchmarking and event-level evaluation, seeking to expose vulnerabilities under realistic stress. This aligns perfectly with John McCarthy’s assertion: “The question of what constitutes ‘artificial intelligence’ is really a question of what we want computers to do.” The article doesn’t seek simply working anomaly detection, but rather a provable, reliable system – one that isn’t merely successful in testing, but demonstrably resilient to data drift and sensor faults in complex cyber-physical systems. A solution’s correctness, not just its apparent success, is paramount.
What’s Next?
The pursuit of universally ‘robust’ anomaly detection algorithms, as demonstrated by this work, appears increasingly… optimistic. The absence of a single model excelling across diverse, realistically stressed cyber-physical systems is not a failing of the algorithms themselves, but a consequence of imposing ill-defined metrics on fundamentally complex phenomena. Simplicity, in this context, does not equate to brevity of code, but to logical completeness – a provable correspondence between the model’s assumptions and the observed system’s behavior. Current evaluations often prioritize statistical performance on curated datasets, obscuring the critical question of whether the detected anomalies actually mean anything within the operational context.
Future work must move beyond synthetic fault injection and embrace a more rigorous, mathematically grounded approach to stress testing. Defining ‘data drift’ is insufficient; one requires a formalization of acceptable drift – a boundary beyond which system behavior is demonstrably compromised, and the anomaly detection system must react accordingly. This necessitates a shift towards event-level evaluation – not merely flagging anomalies, but quantifying the cost of false positives and false negatives in terms of system functionality and safety.
Ultimately, the field requires a formal theory of ‘operational anomaly’ – a definition rooted in the system’s intended purpose and the consequences of deviation. Only then can anomaly detection algorithms be judged not on their statistical prowess, but on their ability to preserve system integrity in the face of inevitable, unpredictable perturbations. The goal isn’t merely to detect something unusual, but to reliably distinguish between benign variation and genuinely hazardous states.
Original article: https://arxiv.org/pdf/2602.15457.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- All Itzaland Animal Locations in Infinity Nikki
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- How to Get to the Undercoast in Esoteric Ebb
- Crimson Desert: Disconnected Truth Puzzle Guide
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- BloxStrike codes (March 2026)
- 6 Ways Invincible Season 4’s Hell Episode Rewrites The Comics
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- Zendaya’s 4 Big 2026 Movies Could Beat Brie Larson’s Box 2019 Office Record
2026-02-19 01:10