Author: Denis Avetisyan
A new approach to set function learning, called Quasi-Arithmetic Neural Networks, boosts expressiveness and transferability by moving beyond simple summation of set elements.
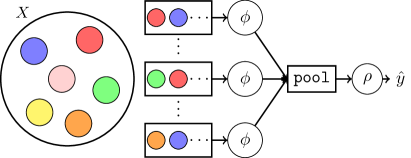
This work introduces QUANNs, a novel architecture utilizing a learnable Kolmogorov mean for improved set aggregation and function approximation.
Representing and processing sets-fundamental data structures across diverse domains-remains a challenge for neural networks due to the inherent need for permutation invariance. This paper, ‘Improving Set Function Approximation with Quasi-Arithmetic Neural Networks’, addresses this limitation by introducing Quasi-Arithmetic Neural Networks (QUANNs), a novel framework leveraging a learnable, neuralized Kolmogorov mean to enhance set function approximation. QUANNs not only demonstrate universal approximation capabilities for a broad class of set decompositions, but also learn more structured latent representations due to their invertible design. Could this approach unlock improved generalization and transfer learning in scenarios where set-structured data is prevalent, and fixed pooling operations currently limit performance?
The Inevitable Headache of Unordered Data
Numerous practical applications demand functions that analyze collections of elements – sets – and produce consistent results irrespective of the arrangement of those elements. This presents a fundamental difficulty for conventional neural networks, which are inherently designed to process sequential data where order does matter. Consider tasks like predicting the properties of a molecule based on its constituent atoms, or classifying a collection of objects in an image; the meaning isn’t altered by rearranging the atoms or objects. Successfully modeling these set-based problems necessitates methods that can effectively abstract away from the specific ordering, requiring specialized architectures and training strategies to ensure reliable and meaningful outputs from unordered data. This contrasts sharply with traditional approaches optimized for sequences, like text or time series, where positional information is critical for accurate prediction.
Permutation invariance, the ability of a function to yield the same output despite alterations in the order of its input elements, represents a significant hurdle in designing neural networks for set-based data. While seemingly intuitive – a collection of ingredients should produce the same dish regardless of mixing order – achieving this consistently requires substantial computational resources. Traditional approaches often involve exhaustively considering all possible permutations, an operation that scales factorially with the input set size, quickly becoming intractable. More sophisticated methods, such as utilizing symmetric functions or carefully crafted architectures, attempt to bypass this combinatorial explosion, but frequently introduce added complexity and parameters. The core challenge lies in effectively capturing the underlying relationships within the set without being misled by superficial orderings, demanding algorithms that prioritize the content of the set over its arrangement.
Initial approaches to processing sets with neural networks often relied on straightforward aggregation methods like summation or averaging of element-wise features. However, these techniques prove inadequate for capturing the nuanced relationships inherent within sets. Simply adding or averaging disregards the combinatorial richness of set elements-the specific interactions and dependencies that define a set’s structure. This leads to a loss of information, preventing the network from discerning meaningful patterns; for instance, the set {1, 2, 3} would yield the same result as {3, 1, 2}, despite potentially representing distinct concepts. Consequently, these rudimentary methods struggle with tasks requiring a deeper understanding of set composition, highlighting the need for more sophisticated architectures capable of handling permutation-invariant representations.
The Usual Suspects: Pooling and Attention
Early approaches to achieving permutation invariance in neural networks processing sets, such as DeepSets and PointNet, utilized pooling operations – typically max or average pooling – to aggregate information from the set elements into a fixed-size vector representation. While effective at ensuring the output remains consistent regardless of the input set’s element order, these pooling methods inherently discard potentially valuable information about the individual elements and their relationships. The reduction in dimensionality caused by pooling can limit the network’s ability to discriminate between nuanced differences in the input set, as detailed information is lost during the aggregation process. This information loss represents a trade-off between achieving permutation invariance and maintaining expressive power.
SetTransformer utilizes attention mechanisms to directly model pairwise relationships between elements within an input set, unlike methods relying on permutation-invariant pooling. Specifically, it employs a multi-head self-attention layer where each element attends to all other elements, creating a contextualized representation for each set member. This allows the model to capture dependencies and interactions without being constrained by a fixed ordering, resulting in a more expressive representation capable of discerning subtle differences between sets even with varying element permutations. The attention weights, computed based on the element embeddings, quantify the relevance of each element to others, effectively creating a dynamic graph representation of the set.
Despite demonstrated improvements in modeling set data, permutation-invariant architectures like SetTransformer and those utilizing complex pooling operations present scalability challenges. The computational cost of attention mechanisms, particularly with increasing set sizes, grows quadratically O(n^2), where n represents the number of elements in the input set. This quadratic complexity limits their applicability to large datasets and real-time applications. Furthermore, the parameter count associated with these complex models can be substantial, demanding significant memory resources during both training and inference, and potentially leading to overfitting with limited training data.
A Better Way: Neuralized Kolmogorov Means
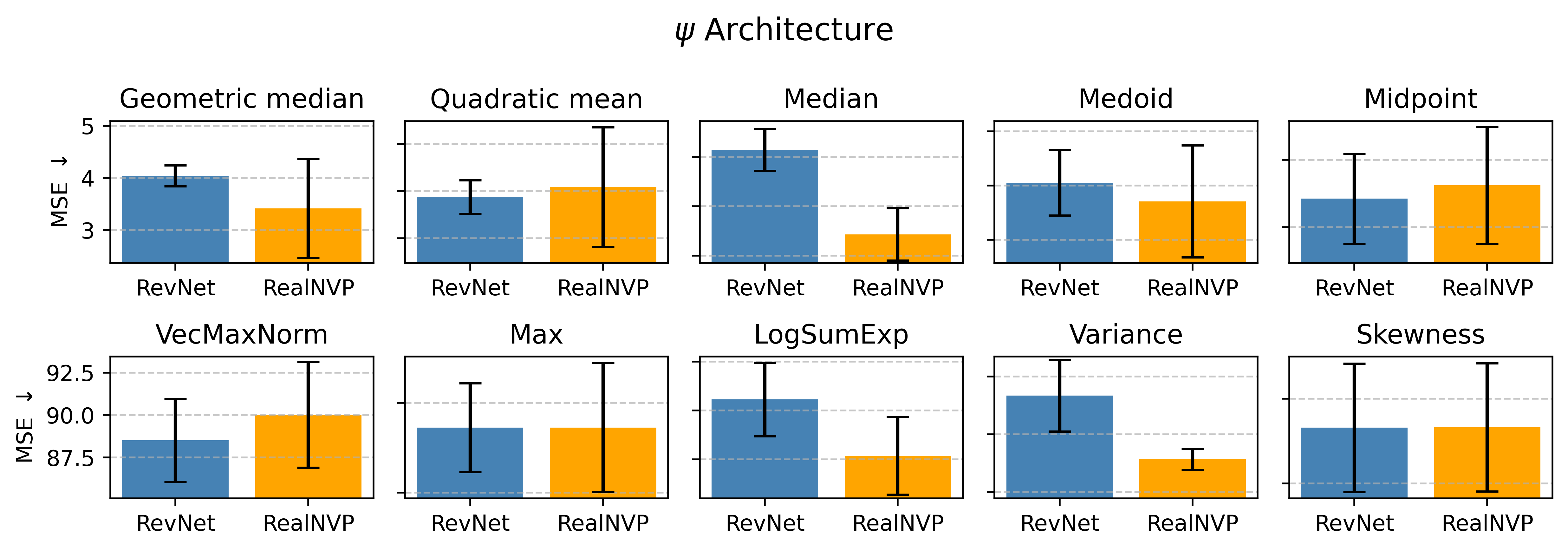
The Kolmogorov Mean extends traditional averaging methods by calculating the expected value of a random variable’s rank amongst a reference distribution, effectively weighting each sample by its relative order. While mathematically elegant – defined as E[X] = \in t_{0}^{1} F^{-1}(t) dt, where F is the cumulative distribution function – direct computation requires evaluating the integral over all possible ranks, posing significant computational challenges, especially in high-dimensional spaces or with large datasets. This intractability stems from the need to determine the inverse cumulative distribution function F^{-1}(t) and perform the integration numerically, a process that scales poorly with dimensionality and sample size. Consequently, practical applications necessitate approximations or alternative formulations to realize the benefits of the Kolmogorov Mean.
The Neuralized Kolmogorov Mean overcomes the computational intractability of directly calculating the Kolmogorov integral by employing a learned generative function. Specifically, architectures such as RevNet – a reversible neural network – are utilized to model the probability distribution underlying the data. This allows for the approximation of the \in t f(x)p(x)dx integral, where f(x) is the function to be averaged and p(x) is the learned data distribution. By learning to generate samples from p(x), the integral can be estimated using Monte Carlo methods, providing a scalable approach to Kolmogorov averaging.
Lipschitz continuity, a critical property ensured by the Neuralized Kolmogorov Mean, constrains the rate of change of a function; specifically, it dictates that the absolute value of the function’s change is bounded by a constant multiple of the change in its input. Mathematically, this is expressed as |f(x) - f(y)| \le L||x - y||, where L is the Lipschitz constant. This bound is crucial for stable learning because it prevents arbitrarily large gradients during optimization, mitigating issues like exploding gradients and ensuring convergence. Furthermore, Lipschitz continuity contributes to robustness by limiting the sensitivity of the model to small perturbations in the input data, thereby improving generalization performance and reducing the risk of adversarial attacks.

QUANN: A More Sensible Approach to Set Functions
At the heart of QUANN lies the Neuralized Kolmogorov Mean, a novel building block designed to efficiently represent and learn complex set functions. This mechanism moves beyond traditional neural networks by directly operating on sets of data, rather than treating each element as independent. The Neuralized Kolmogorov Mean effectively aggregates information from the input set, capturing nuanced relationships and dependencies that would otherwise be lost. By learning how to combine these set-level features, QUANN achieves a significant computational advantage when dealing with variable-sized inputs, allowing it to scale effectively and generalize well to unseen data. This core component empowers the network to model intricate set functions with a reduced number of parameters, ultimately leading to improved performance and efficiency compared to approaches that treat sets as unordered collections of individual data points.
The architecture of QUANN is distinguished by its strategic employment of decomposition methods – specifically, sum, mean, and max – to effectively model the intricate relationships inherent within input sets. Rather than treating a set as a monolithic entity, QUANN breaks it down into constituent parts, allowing the network to learn how these components interact to produce a final output. The sum decomposition excels at capturing additive relationships, while the mean decomposition focuses on averaging effects, and the max decomposition identifies dominant features. By dynamically utilizing these diverse strategies, QUANN achieves a nuanced understanding of set data, enabling it to represent and learn a wider range of set functions compared to models reliant on a single aggregation technique. This flexibility is crucial for applications where the relationships within input sets are complex and vary considerably, allowing the network to adapt and generalize effectively across different datasets and tasks.
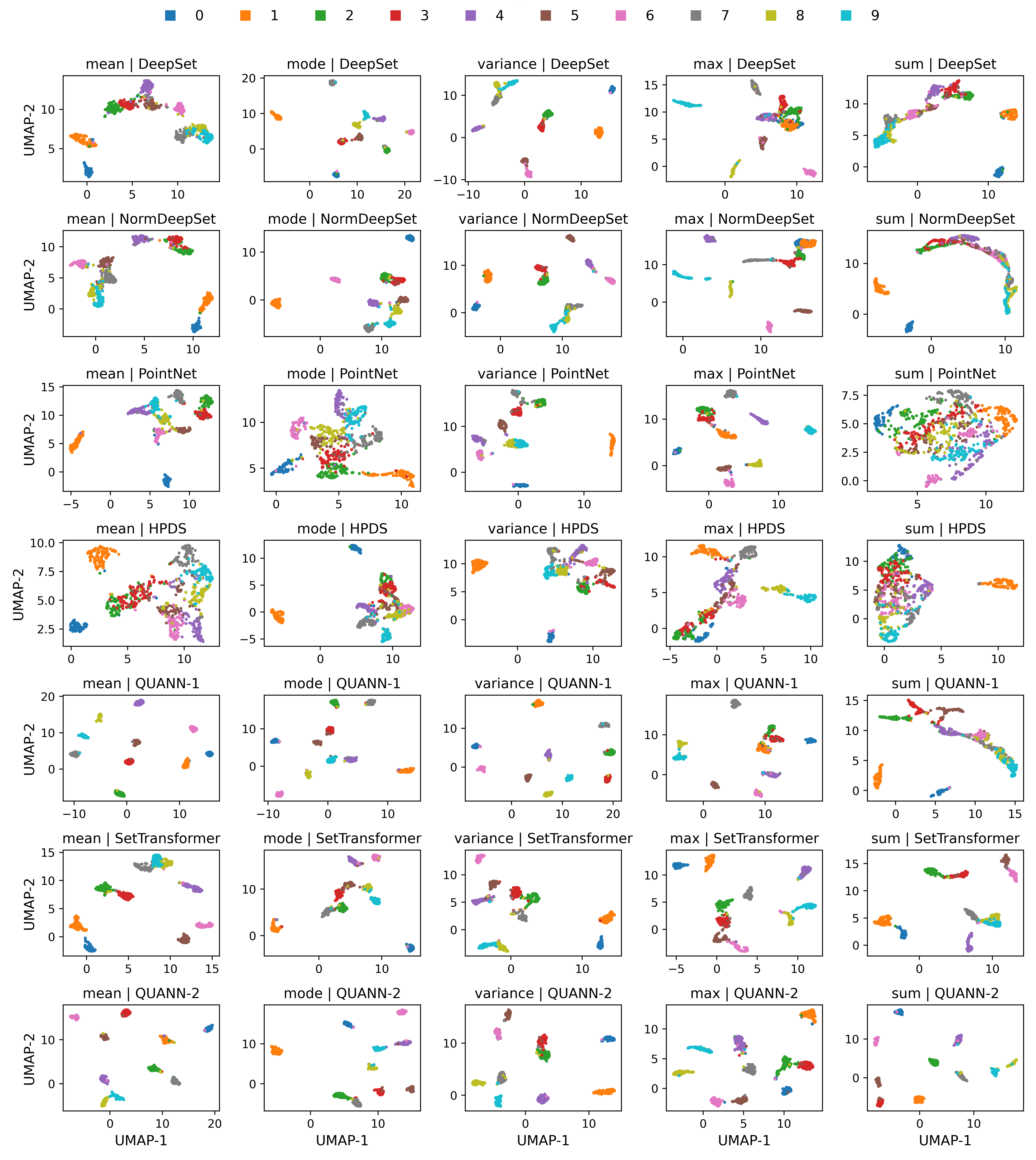
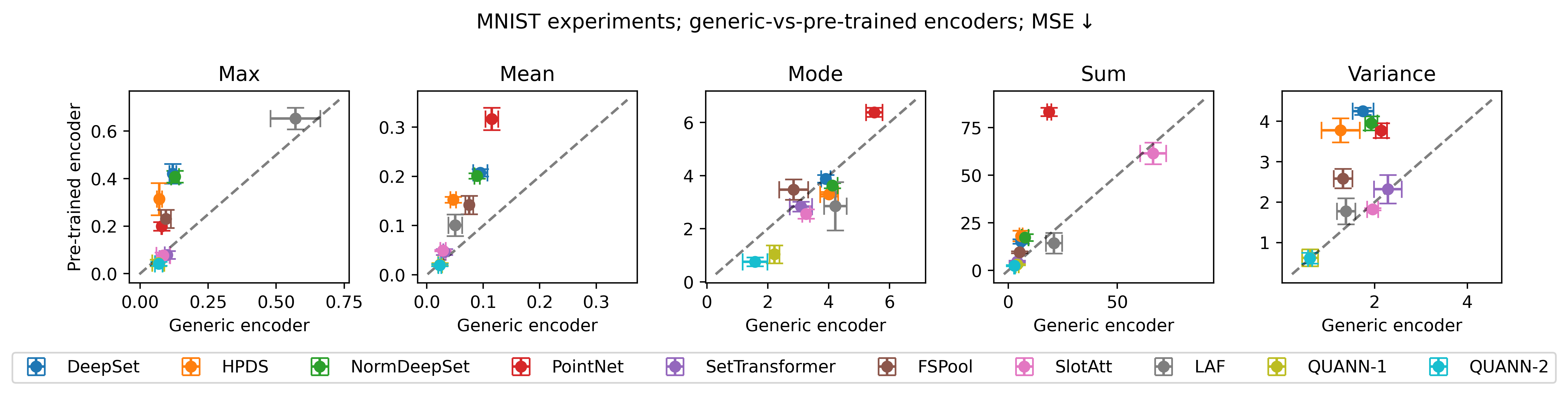
Evaluations reveal that QUANN consistently surpasses the performance of established baseline models in set function learning tasks. Rigorous pairwise comparisons were conducted to assess this superiority, and the results demonstrate a significant win rate for QUANN across numerous tests. These gains weren’t merely anecdotal; statistical validation using binomial tests-yielding p-values less than 0.01 in many instances-confirms that the observed outperformance is statistically significant and not due to random chance. This robust performance establishes QUANN as a reliable and effective solution for applications requiring accurate and scalable set function approximation, exceeding the capabilities of previously available methods.
The efficiency of Quasi-Arithmetic Neural Networks, or QUANN, is mathematically grounded in its ability to approximate set functions with guaranteed error bounds. For functions exhibiting Max-Decomposability, QUANN achieves an approximation error of no more than L_a <i> log(n) + \epsilon, where L_a represents the Lipschitz constant and ‘n’ denotes the size of the input set. Notably, for Sum-Decomposable functions, the error is bounded by L_a </i> (n <i> B_1 - w </i> B_0) + \epsilon, with B_1 and B_0 representing parameters related to the function’s complexity, and ‘w’ a weighting factor. These bounds demonstrate QUANN’s scalability; the logarithmic and linear relationships to ‘n’ indicate that the approximation error grows relatively slowly as the dataset expands, making it suitable for handling large and complex sets without sacrificing accuracy.
A key strength of the Quasi-Arithmetic Neural Network (QUANN) lies in its inherent permutation invariance, a property that significantly enhances its robustness and broadens its applicability across diverse fields. This means the network’s output remains consistent regardless of the order of elements within an input set; rearranging the input data does not alter the prediction. Such invariance is crucial for tasks where the order of elements is irrelevant – for example, analyzing collections of objects, predicting outcomes based on group characteristics, or processing data where the input features represent unordered sets. By eliminating sensitivity to input order, QUANN avoids spurious correlations and delivers more reliable and generalizable results, making it a valuable tool in scenarios demanding consistent performance across varying data presentations and minimizing the risk of overfitting to specific ordering patterns.
The pursuit of expressive power in set function learning, as demonstrated by these Quasi-Arithmetic Neural Networks, feels predictably ambitious. It’s another layer of complexity built atop existing architectures, and one suspects production data will swiftly reveal unforeseen edge cases. As John von Neumann observed, “There’s no point in being too careful; it’s better to have a good idea and run with it-or put another way, ‘if you want to know how things work, don’t ask me, I build things.’ The promise of a learnable Kolmogorov mean offers improved transferability, yet history suggests that elegant theoretical gains often come with practical costs. This paper’s novelty will be quickly absorbed, refined, and ultimately, transformed into the next set of technical debts that someone, somewhere, will be tasked with resolving.
What’s Next?
The pursuit of robust set function learning, as exemplified by Quasi-Arithmetic Neural Networks, inevitably encounters the limitations of any approximation. The elegance of a learnable Kolmogorov mean, while promising increased expressiveness, merely shifts the battleground for error. Production datasets, unconcerned with theoretical guarantees of permutation invariance, will undoubtedly reveal unforeseen sensitivities. The question isn’t if these networks will fail, but where, and with what delightful combination of edge cases.
Future work will likely focus on mitigating these practical failures – adding regularization, exploring different aggregation functions, perhaps even attempting to instill a sense of humility into the network itself. However, a more fundamental challenge remains: the inherent ambiguity of representing complex set relationships with finite parameters. Every abstraction dies in production, and it will be interesting to observe the specific manner of QUANN’s demise.
Ultimately, the field might be forced to confront the possibility that certain set functions are simply too intricate, too chaotic, to be reliably approximated. The search for ever-more-sophisticated architectures may yield diminishing returns. Perhaps the true innovation will lie not in building better networks, but in accepting the inherent limitations of the endeavor – and finding ways to gracefully degrade when, as always, things inevitably crash.
Original article: https://arxiv.org/pdf/2602.04941.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Mewgenics vinyl limited editions now available to pre-order
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Invincible Season 4 Episode 6 Release Date, Time, Where to Watch
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- TikToker’s viral search for soulmate “Mike” takes brutal turn after his wife responds
- ‘Timur’ Trailer Sees Martial Arts Action Collide With a Real-Life War Rescue
2026-02-08 00:53