Author: Denis Avetisyan
A new framework combines the power of graph-based reasoning with large language models to dramatically improve the analysis and understanding of complex time series data.
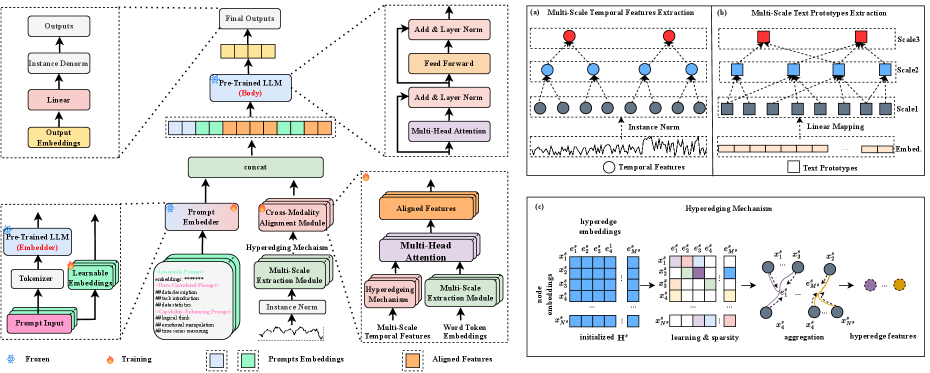
This paper introduces MSH-LLM, a novel approach leveraging multi-scale hypergraphs and cross-modality alignment to enhance large language model performance on time series analysis tasks, achieving state-of-the-art results.
Despite recent advances in applying large language models (LLMs) to time series analysis, effectively capturing the inherent multi-scale structures within both temporal data and natural language remains a significant challenge. This work, ‘Multi-scale hypergraph meets LLMs: Aligning large language models for time series analysis’, addresses this limitation by introducing MSH-LLM, a novel framework that leverages multi-scale hypergraphs and cross-modality alignment to better integrate LLMs for improved time series understanding. Experimental results demonstrate state-of-the-art performance across diverse applications, suggesting that a more nuanced representation of temporal scales can substantially enhance the power of LLMs in this domain. Could this approach pave the way for more robust and interpretable time series forecasting and anomaly detection systems?
The Inherent Limitations of Conventional Time Series Methods
Conventional time series analysis frequently encounters limitations when confronted with data exhibiting intricate, multi-scale patterns and extended temporal dependencies. These methods, often reliant on linearity and stationarity, struggle to effectively model phenomena where relationships unfold across vastly different time scales – from short-term fluctuations to gradual, long-term trends. Consequently, capturing dependencies stretching far into the past, crucial for accurate forecasting in systems with memory, proves challenging. This inability to discern and integrate information across these scales leads to simplified representations of complex dynamics, diminishing predictive power and potentially obscuring vital insights hidden within the data’s intricate structure. The result is often a failure to anticipate critical shifts or subtle changes in the system’s behavior, particularly when dealing with non-linear or chaotic processes.
Traditional time series forecasting often falters when confronted with real-world complexity due to its inherent dependence on strict statistical assumptions. Methods like ARIMA and exponential smoothing presume data stationarity and linearity, conditions rarely met in dynamic systems exhibiting trends, seasonality, or external influences. This reliance limits their ability to accurately model phenomena susceptible to sudden shifts or non-linear behaviors. Furthermore, these approaches frequently lack the capacity to incorporate crucial contextual information – economic indicators, geopolitical events, or even social media sentiment – that significantly impacts future values. Consequently, forecasts generated solely from historical data patterns can become increasingly unreliable in rapidly changing environments, leading to inaccurate predictions and potentially flawed decision-making. A robust forecasting strategy necessitates models capable of adapting to evolving conditions and leveraging a broader understanding of the underlying processes at play.
The escalating complexity of modern datasets demands analytical techniques that transcend the limitations of conventional time series modeling. Static methodologies, built on assumptions of linearity and stationarity, often fail to capture the subtle, interwoven relationships inherent in real-world phenomena. A critical shift is occurring towards methods prioritizing adaptability; these approaches dynamically adjust to evolving data patterns, rather than relying on pre-defined structures. This necessitates algorithms capable of identifying non-linear dependencies, incorporating external variables, and learning from continuous data streams, ultimately enhancing predictive accuracy and providing deeper insights into dynamic systems. The future of time series analysis hinges on embracing these flexible, nuanced tools to navigate the challenges of an ever-changing world.
Multi-Scale Hypergraphs: A Structurally Sound Representation
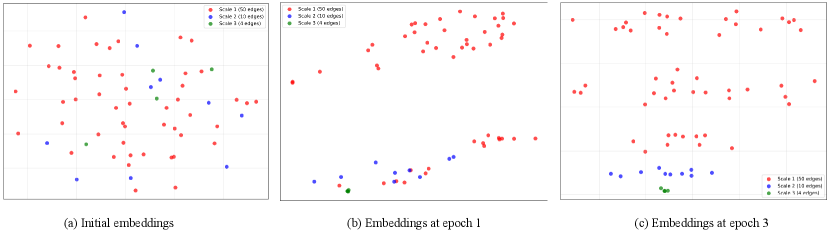
Multi-scale hypergraphs represent time series data by constructing hyperedges that connect multiple nodes, allowing the modeling of group interactions beyond pairwise relationships. Traditional graph-based time series analysis often focuses on connections between individual data points; however, hypergraphs facilitate the representation of collective behaviors and dependencies occurring within time windows or defined groups. These hyperedges can vary in size and scope, representing interactions at different temporal granularities – from short-term, fine-grained dependencies to long-term, coarse-grained patterns. This multi-scale approach allows the framework to capture both immediate relationships and broader contextual influences within the time series, providing a more comprehensive representation of the data’s dynamic structure and enabling analysis of complex, interconnected events.
Hyperedge feature extraction within multi-scale hypergraphs involves calculating descriptive statistics and learned embeddings for each hyperedge, representing group interactions over time. These features can include the size of the hyperedge (number of nodes involved), duration of the temporal interval it covers, and aggregated properties of the nodes it connects – such as mean, variance, or sum of node attributes. Furthermore, learned embeddings, often generated through graph neural networks, capture complex relationships within and between hyperedges, identifying salient temporal patterns. The resulting hyperedge features serve as input for downstream tasks like classification or prediction, providing a richer representation than node-based approaches by directly encoding group-wise dependencies and temporal dynamics.
Analyzing time series data with a focus on both local and global dependencies allows for a more comprehensive understanding of underlying patterns than methods considering only one scale. Local dependencies, representing immediate relationships between adjacent time points or variables, capture short-term fluctuations and transient effects. Conversely, global dependencies identify long-range correlations and structural relationships spanning the entire time series. By integrating these perspectives, the approach avoids limitations inherent in methods focusing solely on local trends (potentially missing broader contextual factors) or global patterns (overlooking important short-term variations). This holistic view facilitates the detection of complex, multi-scale dynamics and improves the accuracy of forecasting and anomaly detection tasks.
MSH-LLM: Aligning Structure and Semantic Understanding
MSH-LLM presents a new method for time series analysis that integrates Multi-Scale Hypergraphs (MSH) with Large Language Models (LLMs). This approach represents time series data as a hypergraph, capturing complex relationships between multiple variables at different temporal scales. The MSH is then aligned with an LLM, enabling the model to leverage both the structural information encoded in the graph and the reasoning capabilities of the language model. This alignment facilitates a more nuanced understanding of time series dynamics compared to traditional methods, allowing the LLM to interpret patterns, anomalies, and dependencies within the data based on the hypergraph’s representation. The technique aims to overcome limitations of applying LLMs directly to raw time series data, which often lacks contextual information and relational structure.
Cross-Modality Alignment (CMA) establishes a direct correspondence between the node and edge attributes within a Multi-Scale Hypergraph and the embedding space of a Large Language Model (LLM). This is achieved by projecting hypergraph features – representing temporal dependencies and relationships within the time series – into the LLM’s semantic space. Specifically, CMA utilizes a learned mapping function to translate hypergraph node and edge properties into token embeddings that the LLM can directly process. This allows the LLM to interpret the graph structure not as abstract data, but as linguistic information conveying contextual relationships and influencing its reasoning process when analyzing time series patterns and making predictions. The alignment process facilitates a bi-directional flow of information, enabling the LLM to both understand the graph and refine its internal representations based on the graph’s structure.
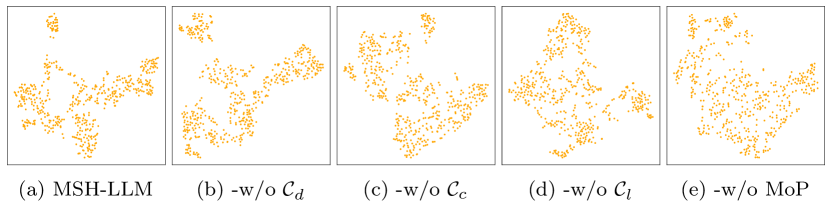
The Mixture of Prompts (MoP) technique improves Large Language Model (LLM) performance on time series analysis by generating multiple prompts that query the same data from different analytical angles. Specifically, MoP constructs prompts focusing on temporal patterns, anomaly detection, and forecasting, each representing a distinct perspective. These diverse prompts are then submitted to the LLM, and the responses are aggregated to produce a consolidated output. This approach mitigates the impact of any single prompt’s limitations and leverages the LLM’s ability to synthesize information from multiple sources, resulting in more robust and accurate reasoning about the time series data.
Beyond Prediction: A Demonstration of Robustness and Adaptability
The MSH-LLM framework exhibits a notable capacity for long-term forecasting, achieving robust results even when provided with minimal training data – a characteristic known as few-shot learning. This capability stems from the model’s architecture, which allows it to generalize patterns from a limited number of examples and extrapolate them accurately over extended time horizons. Unlike traditional time series models that demand extensive historical data, MSH-LLM can effectively predict future values with significantly less input, offering a practical advantage in scenarios where data is scarce or expensive to obtain. This efficient learning approach not only reduces the computational burden but also enhances the model’s adaptability to new and evolving time series, making it a valuable tool for forecasting in dynamic environments.
The MSH-LLM framework distinguishes itself through an exceptional capacity for zero-shot learning, meaning it successfully tackles time series tasks it was never specifically trained on. This capability stems from the model’s inherent understanding of temporal dynamics, allowing it to extrapolate learned patterns to entirely novel datasets and applications without requiring any task-specific fine-tuning. Rather than memorizing solutions, the framework demonstrates a genuine ability to reason about time series data, enabling effective performance on unseen challenges-a significant advancement over traditional methods that typically demand extensive retraining for each new task. This adaptability not only streamlines implementation but also opens doors to broader applicability across diverse and evolving time series domains.
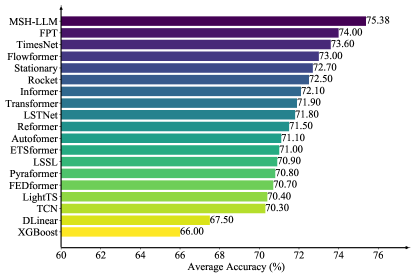
Across five diverse applications, the MSH-LLM framework demonstrably surpasses existing methodologies in forecasting accuracy. Rigorous evaluation reveals an average reduction in Mean Squared Error (MSE) of 56.89% when contrasted with the established DHR-ARIMA model, a substantial improvement indicating enhanced predictive capability. Further comparisons highlight a 70.31% reduction in MSE relative to the Repeat forecasting method, and a noteworthy 5.20% decrease when measured against PAtnn. These results collectively establish MSH-LLM as a state-of-the-art solution, consistently delivering more precise long-term forecasts and offering a significant advancement over conventional time series analysis techniques.
The MSH-LLM framework demonstrates a compelling ability to identify unusual patterns within time series data, achieving an F1-score of 88.08% in anomaly detection tasks. This metric, representing the harmonic mean of precision and recall, indicates a robust balance between correctly identifying anomalies and minimizing false positives. Such performance suggests the model effectively learns the underlying characteristics of normal behavior, allowing it to accurately flag deviations that may signal critical events or system failures. The high F1-score highlights MSH-LLM’s potential in applications ranging from predictive maintenance and fraud detection to monitoring complex systems where timely identification of anomalies is paramount.
Evaluations reveal that the proposed framework’s short-term forecasting capabilities, specifically utilizing the Symmetric Mean Absolute Percentage Error (SMAPE) metric, demonstrate a significant advancement over existing methodologies. The system consistently achieves superior accuracy, surpassing the performance of AutoTimes by 1.45% and outperforming S2IP-LLM by a more substantial margin of 3.01%. This improvement suggests a heightened ability to capture nuanced temporal dynamics and provide more precise predictions within shorter time horizons, potentially offering practical benefits for applications requiring immediate and reliable forecasting, such as resource allocation and real-time decision-making.
The framework demonstrates a significant advancement in time series classification, achieving an accuracy of 75.38%. This performance not only surpasses established baseline models, but also establishes a new state-of-the-art benchmark in the field. This improved classification capability is crucial for a variety of applications, from predicting equipment failures based on sensor data to identifying patterns in financial markets. The accuracy gain represents a substantial leap forward, allowing for more reliable and insightful analysis of complex temporal datasets, and paving the way for more effective decision-making in data-driven contexts.
Rigorous statistical analysis consistently validates the observed performance gains of the proposed framework across all experimental evaluations. A p-value consistently below 0.01 was achieved throughout the study, indicating a less than one percent chance that the reported improvements occurred due to random variation. This level of statistical significance provides strong evidence that the observed reductions in forecasting error – averaging 56.89%, 70.31%, and 5.20% across various applications – and gains in anomaly detection (F1-score of 88.08%) and time series classification (accuracy of 75.38%) are genuine and reliable effects, rather than simply chance occurrences. The consistently low p-value reinforces the robustness and dependability of the proposed methodology, suggesting it offers a statistically meaningful advancement over existing approaches.
Future Directions: Towards Truly Intelligent Time Series Systems
The versatility of the MSH-LLM framework extends significantly beyond its initial demonstrations, promising advancements across a spectrum of time series applications. In finance, the model could refine algorithmic trading strategies and enhance risk assessment by identifying subtle patterns in market data. Healthcare stands to benefit from improved patient monitoring and early disease detection through analysis of physiological time series, such as electrocardiograms or blood glucose levels. Furthermore, environmental monitoring systems could leverage MSH-LLM to forecast weather patterns, predict natural disasters, and track pollution levels with greater accuracy, enabling proactive interventions and resource allocation. These diverse applications highlight the potential of MSH-LLM to transform raw time series data into actionable insights, driving innovation and improving decision-making in critical sectors.
The convergence of Multi-Scale Hierarchical Long Learning Models (MSH-LLM) with continuously updating, real-time data streams promises a new era of adaptive time series analysis. Rather than relying on static datasets, these systems are designed to ingest and process information as it becomes available, allowing the model to dynamically refine its understanding and predictive capabilities. This continuous learning approach is crucial for applications where underlying patterns evolve – for example, financial markets or climate modeling – as the MSH-LLM can adjust to non-stationarity without requiring retraining from scratch. By integrating feedback loops and leveraging the model’s hierarchical structure, the system not only forecasts future values but also identifies shifts in data distributions and proactively adjusts its internal parameters, ultimately leading to more robust and accurate intelligent time series systems capable of handling the complexities of the real world.
The capacity of Multi-Scale Hierarchical Long-term Memory (MSH-LLM) extends beyond simple forecasting, offering a powerful tool for identifying unusual patterns and anticipating failures within intricate systems. By learning the nuanced temporal dependencies inherent in time series data, MSH-LLM can effectively distinguish between normal operational behavior and anomalous deviations, flagging potential issues before they escalate. This proactive capability is particularly valuable in predictive maintenance, where early detection of subtle anomalies-such as a slight temperature increase in a critical component or a minor deviation in vibration patterns-can prevent costly downtime and extend the lifespan of equipment. The model’s hierarchical structure allows it to capture both short-term fluctuations and long-term trends, enhancing its ability to discern meaningful anomalies from random noise and providing operators with actionable insights for optimized system performance and reliability.
The pursuit of robust time series analysis, as detailed in this framework, demands a rigor akin to mathematical proof. The presented MSH-LLM method, with its emphasis on multi-scale hypergraphs and cross-modality alignment, seeks not merely functional performance, but a structurally sound integration of large language models. This aligns perfectly with the sentiment expressed by Tim Bern-Lee: “The Web is more a social creation than a technical one.” The framework’s success isn’t solely predicated on algorithmic innovation, but on the cohesive alignment of disparate data modalities – a social construction of information, mirrored in the interconnectedness of the web itself. The pursuit of ‘state-of-the-art results’ is only meaningful if built upon a verifiable and logically consistent foundation.
Future Directions
The presented framework, while demonstrating empirical success, merely scratches the surface of a fundamental challenge: the translation of continuous, inherently analog data into the discrete realm of language models. The current reliance on prompt engineering, a decidedly heuristic process, feels…unsatisfactory. One anticipates a future where time series characteristics are encoded not as textual descriptions, but as mathematically rigorous constraints within the LLM’s latent space – a true formalization of temporal reasoning. The hypergraph representation, though effective, invites consideration of alternative graph structures possessing even greater expressive power and computational efficiency.
A crucial, often overlooked limitation resides in the assumption of stationarity, or near-stationarity, within the analyzed time series. Real-world signals are rarely so accommodating. Future work must address the problem of non-stationary time series with greater robustness, perhaps through adaptive hypergraph construction or the incorporation of differential equations directly into the LLM’s training regime. The elegance of a solution lies not in its ability to approximate, but in its provable correctness, even amidst chaos.
Ultimately, the pursuit of ‘intelligence’ in time series analysis demands a move beyond pattern recognition. The goal should be a system capable of genuine causal inference-understanding why a signal behaves as it does, not simply how it behaves. This necessitates a synthesis of LLMs with formal methods of causal modeling, a marriage of statistical power and mathematical rigor. Any less, and the endeavor remains a sophisticated form of curve fitting.
Original article: https://arxiv.org/pdf/2602.04369.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Invincible Season 4 Episode 6 Release Date, Time, Where to Watch
- Mewgenics vinyl limited editions now available to pre-order
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
- Viral Letterboxd keychain lets cinephiles show off their favorite movies on the go
2026-02-06 05:09