Author: Denis Avetisyan
A new framework intelligently routes information across different data streams to dramatically improve the accuracy of forecasting complex time-dependent events.
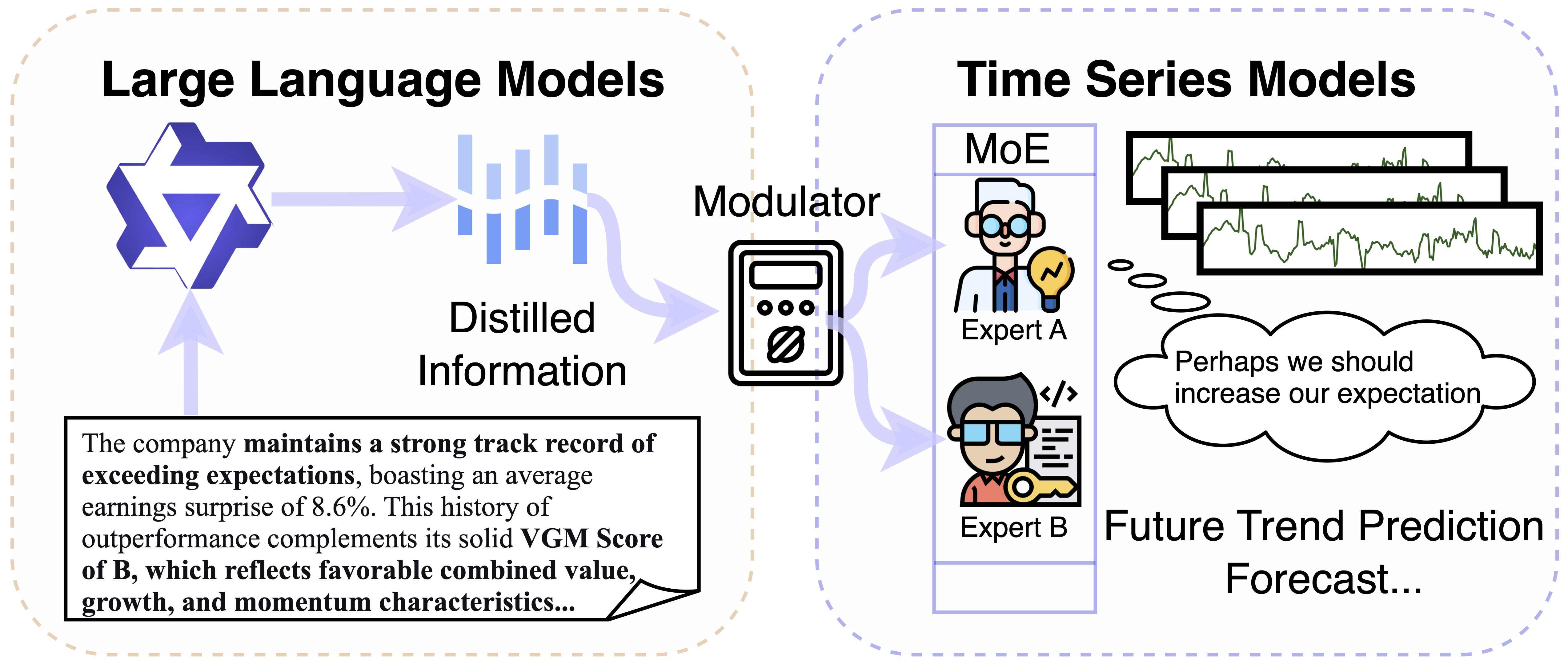
This paper introduces Mixture of Modulated Experts (MoME), a novel approach that directly modulates expert computations within a Mixture of Experts architecture using auxiliary signals for enhanced multi-modal time series prediction.
Accurate time series forecasting remains a challenge, particularly when leveraging the potentially valuable information embedded in auxiliary data sources. This is addressed in ‘Multi-Modal Time Series Prediction via Mixture of Modulated Experts’, which proposes a novel framework that moves beyond traditional token-level fusion by directly modulating expert computations within a Mixture-of-Experts (MoE) architecture using textual signals. This approach enables more efficient cross-modal control and improved performance in multi-modal time series prediction tasks. Could this paradigm of expert modulation unlock new capabilities for integrating diverse data streams and achieving more robust and accurate forecasting?
The Inevitable Complexity of Prediction
Conventional time series forecasting techniques, such as ARIMA and exponential smoothing, frequently encounter limitations when applied to real-world data exhibiting intricate patterns. These methods typically assume linear relationships and stationary data, failing to adequately capture the non-linear dependencies and evolving dynamics inherent in many complex systems. External factors – unforeseen events, shifting market conditions, or correlated variables – further complicate accurate prediction, as traditional models often lack the mechanisms to integrate and respond to such influences. Consequently, forecasts can suffer from significant errors, particularly when dealing with long-term predictions or data subject to abrupt changes, highlighting the need for more sophisticated approaches capable of handling complexity and external variability.
The convergence of time series data with unstructured textual information – such as news articles, social media posts, or economic reports – holds considerable promise for enhanced predictive modeling, yet fully realizing this potential remains elusive. While traditional forecasting relies heavily on historical numerical values, integrating contextual data can capture nuanced relationships and external influences often missed by purely quantitative approaches. However, current methodologies frequently struggle to effectively fuse these disparate data types; simply appending textual features or employing basic natural language processing techniques often proves insufficient. The challenge lies in developing models capable of discerning relevant textual signals, understanding their impact on time series dynamics, and seamlessly incorporating this knowledge to improve forecasting accuracy – a pursuit demanding innovative architectures and sophisticated learning algorithms that can bridge the gap between quantitative and qualitative information.

Specialization as a Pathway to Capacity
Mixture of Experts (MoE) is a machine learning paradigm employing multiple specialized neural networks, or “experts,” to process different subsets of the input data. In multi-modal integration, this allows for dedicated processing of each modality – such as text, time series, or images – by a specific expert network. A “gating network” then learns to dynamically weight the contributions of each expert based on the input, effectively routing data to the most relevant specialist. This contrasts with a single, monolithic network attempting to learn representations from all modalities simultaneously, and enables increased model capacity and improved performance on complex, heterogeneous datasets by facilitating specialization and reducing interference between modalities.
The integration of textual data, processed via Large Language Models (LLMs), with time series data enables contextual understanding that enhances predictive capabilities. Our framework leverages LLMs to extract and incorporate relevant textual features, providing additional information beyond the temporal patterns present in the time series. Evaluations demonstrate consistent performance gains over established state-of-the-art baselines across multiple datasets, indicating that the inclusion of textual context significantly improves model accuracy and robustness in multi-modal forecasting tasks. This improvement is attributable to the LLM’s ability to capture semantic relationships and external factors influencing the time series data, which are otherwise inaccessible to purely temporal models.
The efficient capacity scaling offered by Mixture of Experts (MoE) architectures is particularly beneficial when processing complex, high-dimensional multi-modal datasets. Traditional models often struggle with the computational demands of integrating diverse data types, such as time series and text, due to the exponential increase in parameters required to represent the combined feature space. MoE addresses this by conditionally activating only a subset of network parameters for each input, allowing the model to increase its effective capacity without a proportional increase in computational cost. This approach enables our novel framework to consistently outperform existing methods on multi-modal tasks, as demonstrated by improved performance across a range of benchmarks and dataset sizes. The selective activation strategy allows for specialization, reducing interference between modalities and improving the quality of learned representations.

Adaptive Routing and the Dynamics of Expertise
Expert Modulation represents a departure from static routing strategies in Mixture-of-Experts (MoE) models by implementing a dynamic approach to expert selection. This system considers both the temporal information – the sequential position within an input sequence – and the textual content of the input itself to determine which experts are most relevant for processing. Unlike traditional MoE methods that often rely on fixed routing parameters, Expert Modulation adjusts expert activation patterns adaptively, allowing the model to prioritize different experts based on the specific characteristics of each input token and its context within the sequence. This contextual awareness aims to improve the model’s ability to handle variable-length sequences and capture long-range dependencies more effectively.
Router Modulation and Expert-independent Linear Modulation (EiLM) enhance the routing process within Mixture-of-Experts (MoE) models by introducing context-aware expert selection. Router Modulation dynamically adjusts the output of the gating network based on input features, allowing for more nuanced routing decisions than static approaches. EiLM further refines this by applying a linear transformation to each expert’s input independently of the router, enabling each expert to process information in a manner optimized for its specific function without interference from the routing mechanism. This combination ensures that only the most relevant experts are activated for a given input pattern, improving both model accuracy and computational efficiency by reducing unnecessary activations.
Top-K Sparse Routing, implemented with a Gating Network, reduces computational demands by selecting only the top K most relevant experts for each input token, thereby improving scalability. This contrasts with dense activation of all experts. Our experiments demonstrate that this approach achieves faster training convergence compared to both the iTransformer and TimeMoE models, as measured by loss reduction per training step and overall time to reach a target performance level. The Gating Network assigns weights to each expert based on input characteristics, enabling dynamic selection and minimizing unnecessary computation. This results in a significant reduction in FLOPs without compromising model accuracy.

Maintaining Equilibrium in Complex Systems
The stability of Mixture-of-Experts (MoE) models, crucial for scaling to immense sizes, isn’t left to chance; rather, it’s underpinned by established mathematical principles. Researchers are leveraging tools from linear algebra, specifically the Rayleigh Quotient and the Gershgorin Circle Theorem, to rigorously analyze the spectral properties of the matrices that define MoE layers. The Rayleigh Quotient provides a means to estimate eigenvalues – indicators of stability – while the Gershgorin Circle Theorem offers bounds on those eigenvalues based on the matrix’s structure. By ensuring these eigenvalues remain within a stable region-avoiding divergence or oscillation-these theorems provide guarantees about the model’s behavior during training and inference. This analytical approach moves beyond empirical observation, allowing for proactive identification and mitigation of potential instability issues before they manifest, ultimately contributing to more robust and scalable MoE architectures. \lambda_{min} \le \lambda_i \le \lambda_{max}
Achieving optimal performance in Mixture-of-Experts (MoE) architectures fundamentally relies on effective load balancing across all available experts. Without it, a disproportionate amount of computational work can fall on a small subset of experts, creating bottlenecks that severely limit overall throughput and negating the benefits of model parallelism. Sophisticated routing mechanisms are therefore employed to dynamically distribute tokens or samples, ensuring each expert receives a roughly equal share of the workload. This isn’t simply about equal distribution, however; strategies often account for expert capacity and the inherent complexity of the input data. Load balancing algorithms strive to minimize the variance in computation performed by each expert, preventing any single unit from becoming overloaded while others remain idle. Consequently, careful attention to load balancing isn’t merely a performance optimization, but a prerequisite for realizing the full potential of MoE models in terms of scalability and efficiency.
Analysis of time series data reveals distinct morphological patterns that can be leveraged to enhance the specialization of experts within Mixture-of-Experts (MoE) architectures. Empirical studies demonstrate that experts don’t simply divide tasks randomly; rather, they develop proficiency in processing specific temporal characteristics and signal intensities. This specialization, facilitated by techniques like magnitude-based selection-where experts are assigned based on the scale of incoming signals-allows the model to achieve greater predictive accuracy. The model effectively learns to route different patterns to the most appropriate expert, creating a system where each component excels at a particular aspect of the data, thereby improving overall performance and efficiency. This refined specialization moves beyond a simple division of labor, enabling a more nuanced and effective approach to time series analysis.
The pursuit of robust time series forecasting, as demonstrated by the Mixture of Modulated Experts (MoME) framework, inherently acknowledges the transient nature of predictive models. Each expert within the MoME architecture represents a temporary solution, attuned to specific patterns within the data. This aligns with Marvin Minsky’s observation: “The more we understand about intelligence, the more we realize how much of it is simply good design.” MoME’s expert modulation isn’t about achieving perfect foresight, but about crafting a system capable of adapting – a resilient design that gracefully accommodates the inevitable decay of predictive accuracy over time. The framework’s focus on cross-modal interaction and auxiliary signal integration embodies a recognition that sustained performance requires continual refinement, mirroring the principle that every abstraction carries the weight of the past.
What Lies Ahead?
The architecture detailed within this work represents a versioning of the mixture of experts paradigm, a necessary evolution. Token-level fusion, while historically convenient, always felt like a temporary fix-a brittle attempt to impose order on fundamentally divergent data streams. MoME’s approach to expert modulation, directing computation with auxiliary signals, acknowledges the inevitable decay of simple concatenation. It is not a solution, but a refinement-a delaying action against the arrow of time that always points toward refactoring.
However, the true limitations reside not within the modulation itself, but in the definition of ‘expert’. Current implementations still rely on discrete, differentiable modules. The next iteration will likely explore a more fluid, continuous representation of expertise-perhaps drawing inspiration from the emergent properties observed in large language models. The integration with LLMs, while promising, feels less like synergy and more like a grafting-a successful but potentially unstable union.
Ultimately, the field will need to confront a fundamental question: can prediction truly transcend the inherent noise of temporal data, or are we simply building increasingly sophisticated echo chambers? The pursuit of multi-modal forecasting isn’t about achieving perfect accuracy; it’s about extending the lifespan of useful models-prolonging the period before entropy reclaims its due.
Original article: https://arxiv.org/pdf/2601.21547.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- How to Get to the Undercoast in Esoteric Ebb
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- All Itzaland Animal Locations in Infinity Nikki
- HBO’s Harry Potter Is Already Breaking My Heart
- Zendaya’s 4 Big 2026 Movies Could Beat Brie Larson’s Box 2019 Office Record
- Netflix’s New 6-Part Crime Thriller Is the Perfect Weekend Binge
2026-01-31 04:19