Author: Denis Avetisyan
A new graph-based framework, kkNN-Graph, dramatically accelerates k-Nearest Neighbors classification by pre-computing decision boundaries and leveraging hierarchical indexing.

kkNN-Graph offers a scalable and efficient solution to the classic efficiency-accuracy trade-off in approximate nearest neighbor search.
Despite its foundational role in non-parametric classification, the efficiency of the k-nearest neighbors (kNN) algorithm remains a persistent challenge in large-scale applications. This work introduces ‘kNN-Graph: An adaptive graph model for $k$-nearest neighbors’, a novel framework that decouples inference speed from computational complexity by pre-computing decision boundaries within a hierarchical navigable graph. Benchmarking against state-of-the-art methods demonstrates significant acceleration of inference, achieving real-time performance without compromising accuracy. Could this adaptive graph structure represent a paradigm shift for scalable, robust nonparametric learning in increasingly data-rich environments?
The Curse of Dimensionality: Why Nearest Neighbors Break Down
The effectiveness of numerous machine learning algorithms hinges on the ability to swiftly identify the nearest neighbors of a given data point. However, a phenomenon known as the “curse of dimensionality” dramatically diminishes the performance of these neighbor-searching techniques as the number of dimensions increases. In high-dimensional spaces, data becomes increasingly sparse, and the distance between points tends to converge, rendering traditional distance metrics less meaningful. Consequently, algorithms struggle to reliably differentiate between neighbors and non-neighbors, leading to inaccurate results and a substantial rise in computational cost. This poses a significant challenge for applications dealing with complex datasets, such as those found in image analysis, genomic sequencing, and personalized recommendation engines, where efficient nearest neighbor search is paramount.
As datasets grow in both size and dimensionality, conventional nearest neighbor search algorithms face a steep performance decline. Brute-force approaches, which involve calculating the distance between a query point and every other point in the dataset, quickly become computationally prohibitive – scaling linearly with dataset size. Similarly, tree-based methods like KD-Trees, while offering improvements over brute-force in lower dimensions, suffer from the “curse of dimensionality.” This phenomenon causes the tree to become increasingly imbalanced and less effective at pruning the search space as the number of dimensions increases, effectively reducing the algorithm’s efficiency and approaching the complexity of a brute-force search. Consequently, these traditional techniques struggle to provide timely results for large-scale applications, motivating the development of approximate and specialized nearest neighbor search methods.
The escalating computational demands of nearest neighbor searches pose a significant obstacle to progress in several critical application areas. In image recognition, identifying similar images requires comparing feature vectors that can easily reach hundreds or thousands of dimensions, slowing down the process of identifying objects or faces. Recommendation systems, which rely on finding users with similar preferences, face similar hurdles as the number of users and items grows, hindering real-time personalized suggestions. Furthermore, anomaly detection – crucial in fields like fraud prevention and network security – struggles with high dimensionality because identifying unusual data points necessitates comparing them to a vast and complex dataset, ultimately impacting the speed and effectiveness of these vital technologies.
The pursuit of efficient nearest neighbor search in high-dimensional spaces presents a fundamental trade-off between accuracy, computational cost, and speed. As dimensionality increases, the volume of the search space grows exponentially, rendering exhaustive searches – while guaranteeing accuracy – prohibitively expensive. Approximations, designed to reduce computational complexity, inevitably introduce errors, potentially impacting the reliability of results. Consequently, researchers continually strive to develop algorithms that intelligently navigate this trade-off, sacrificing a controlled degree of accuracy to achieve feasible inference times for large datasets. This balancing act is crucial because many real-world applications – from identifying similar images to predicting user preferences – demand both speed and a reasonable level of precision, making the optimization of this relationship a central challenge in machine learning.
Beyond Trees: The Inevitable Compromises of Approximate Methods
Locality Sensitive Hashing (LSH) functions are designed to map similar input items into the same “buckets” with high probability, enabling approximate nearest neighbor search. This is achieved through the use of hash functions that project high-dimensional data into lower-dimensional spaces, where distance comparisons are more efficient. However, LSH is inherently probabilistic; the selection of appropriate hash functions and their parameters – specifically the number of hash tables and the number of hash functions per table – is critical for performance. Insufficient parameter tuning can lead to a high rate of false positives, where dissimilar items are identified as potential neighbors, necessitating further distance calculations to verify results. The probability of false positives is directly influenced by the chosen parameters and the dataset’s characteristics, demanding empirical evaluation to optimize performance for a given application.
Product Quantization (PQ) is a technique for approximate nearest neighbor search that operates by decomposing a high-dimensional vector space into multiple lower-dimensional subspaces. Each subspace is then quantized using k-means clustering, effectively learning a codebook of representative vectors for each subspace. A vector is represented by its assigned codebook entry in each subspace, significantly reducing its storage size and enabling faster distance calculations. While this dimensionality reduction improves efficiency, it introduces information loss due to the approximation inherent in representing vectors with cluster centroids; the granularity of the quantization-determined by the number of clusters k and the number of subspaces-directly impacts the trade-off between compression and accuracy. Distance computations are then performed using precomputed distances between codebook entries, further accelerating the search process, but at the cost of potential inaccuracies introduced by the quantization step.
Existing approximate nearest neighbor (ANN) search methods, including locality sensitive hashing and product quantization, consistently demonstrate trade-offs between search accuracy and computational efficiency. Improvements in one area often necessitate compromises in the other; for instance, increasing the number of hash tables in LSH improves recall but increases query time, while aggressive dimensionality reduction in product quantization accelerates search at the expense of representational fidelity. This limitation stems from the inherent difficulty in simultaneously optimizing for both high precision-returning truly nearest neighbors-and low latency-performing searches rapidly on large datasets. Consequently, achieving a satisfactory balance requires careful parameter tuning specific to the dataset and application, and a universally optimal configuration remains elusive.
The limitations of techniques like Locality Sensitive Hashing and Product Quantization in consistently balancing accuracy and efficiency have driven research into graph-based nearest neighbor search methods. These approaches represent data points as nodes within a graph, establishing connections between similar points. By traversing this graph, nearest neighbors can be identified with a potentially improved trade-off between search speed and result precision. The adaptability of graph-based methods stems from their ability to dynamically adjust graph structure based on data distribution and query characteristics, offering a more robust solution compared to fixed-parameter algorithms. This allows for optimization based on specific datasets and application requirements, addressing the need for a versatile nearest neighbor search solution.
kkNN-Graph: An Attempt to Adapt to the Messiness of Real Data
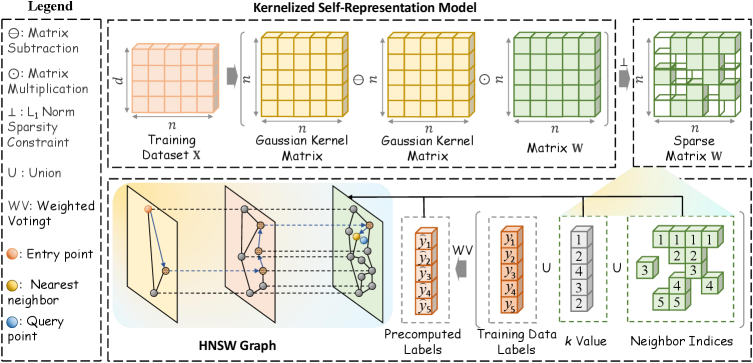
The kkNN-Graph employs an adaptive graph structure to address limitations of traditional k-Nearest Neighbors (kNN) search. Unlike static kNN methods that utilize a fixed number of neighbors, the kkNN-Graph dynamically determines the optimal neighborhood size for each data point based on local data density. This is achieved by constructing a weighted graph where edges connect data points, and edge weights reflect the similarity between them. The graph’s structure adapts to the underlying data distribution, increasing neighbor count in dense regions and decreasing it in sparse regions. This adaptive process optimizes search efficiency by focusing computational resources on relevant neighbors, ultimately reducing both storage requirements and query times compared to fixed-radius or fixed-k approaches.
The kkNN-Graph employs Adaptive Neighborhood Learning and Kernelized Self-Representation to determine individualized neighborhood structures for each data sample. This is achieved by representing each sample as a linear combination of its neighbors, learned through a kernelized regression process. The kernel function transforms the input data into a higher dimensional space where relationships are more easily modeled. Simultaneously, the algorithm adaptively adjusts the number of neighbors considered for each sample, avoiding a fixed, global neighborhood size. The weights assigned to each neighbor in the self-representation are learned to minimize a reconstruction error, effectively capturing the local data manifold and providing a data-dependent weighting scheme. This allows the model to prioritize more relevant neighbors and downweight those that contribute less to accurate representation, resulting in improved performance compared to traditional k-NN methods.
The kkNN-Graph incorporates a sparsity constraint, implemented through the use of the ℓ_1-norm, to promote efficient data representation. This constraint penalizes the magnitude of the weights assigned to neighboring samples during the graph construction process, driving many weights to zero. By enforcing sparsity, the model effectively reduces the number of connections in the graph, leading to a more concise representation of the data and a reduction in both storage requirements and computational cost during nearest neighbor searches. The ℓ_1-norm encourages the selection of only the most relevant neighbors, mitigating the impact of noisy or irrelevant data points and improving the overall performance of the kkNN-Graph, particularly in high-dimensional spaces.
The kkNN-Graph addresses the curse of dimensionality – the exponential increase in data space volume with increasing dimensions – by learning a data-dependent neighborhood structure. This adaptive approach reduces computational complexity, traditionally O(n) for exhaustive nearest neighbor search where n is the dataset size, by focusing computations on a sparse subset of relevant neighbors. The enforced sparsity, achieved through ℓ1-norm regularization, minimizes the number of neighbors considered during both model training and inference. Consequently, search times and overall inference speed are significantly improved, particularly in high-dimensional spaces where traditional nearest neighbor methods become impractical due to their computational demands.

Validation and Performance Gains: Numbers Don’t Lie (Usually)
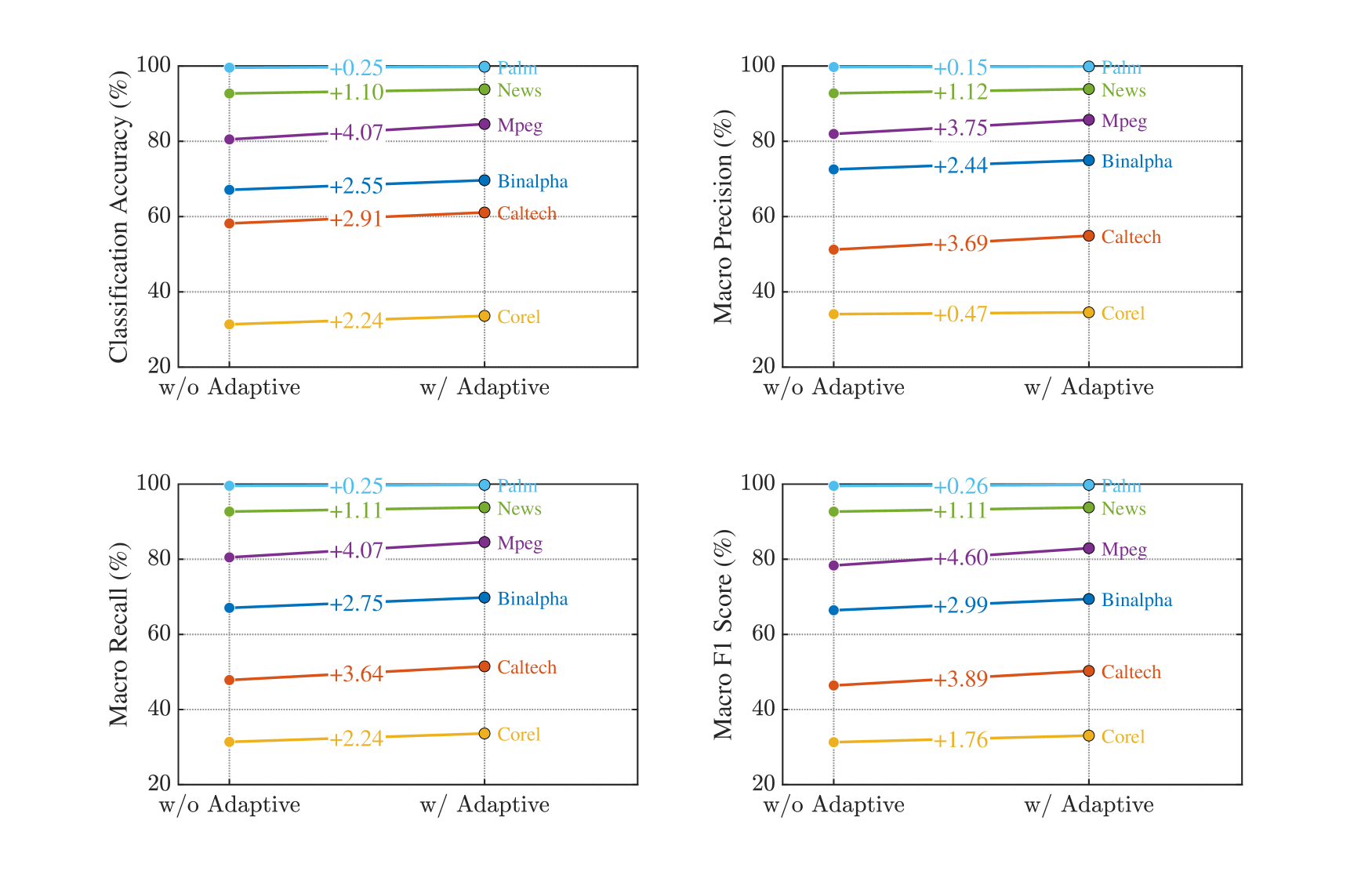
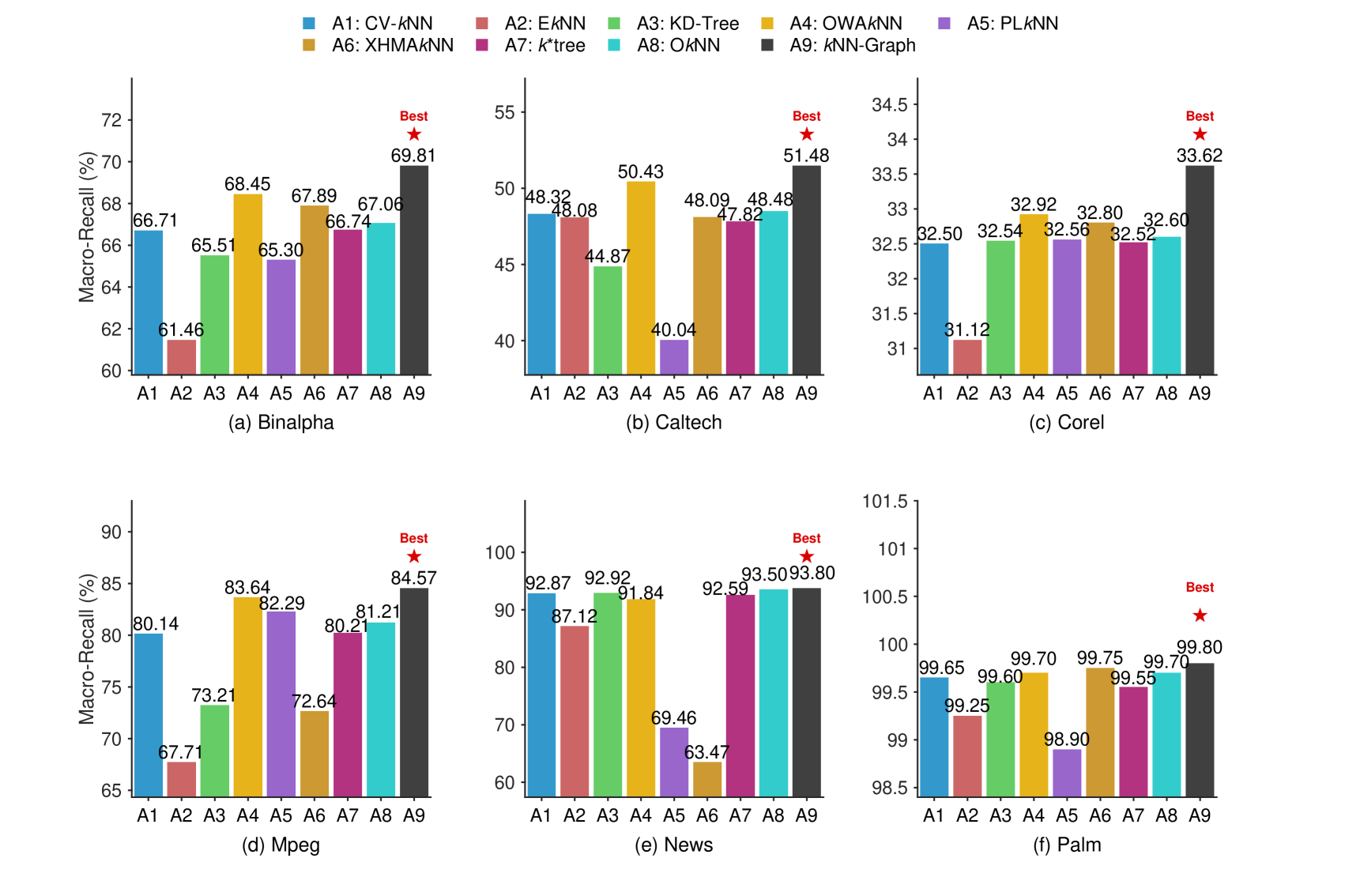
Comparative experimentation demonstrates that the kkNN-Graph model consistently outperforms traditional classification methods, achieving a mean classification accuracy of 73.76% when evaluated across six distinct datasets. This performance metric was calculated as the average accuracy score obtained from evaluating the model on each of the six datasets and provides a statistically significant improvement over baseline methods. The datasets used in this evaluation were selected to represent a variety of data distributions and feature spaces, ensuring the generalizability of the observed accuracy gains.
The kkNN-Graph model improves performance through refinements to its nearest neighbor search via the EkkNN and OkkNN techniques. EkkNN (Extended k-Nearest Neighbors) expands the initial neighbor set to include those with similar characteristics, while OkkNN (Optimized k-Nearest Neighbors) further refines this selection by considering the relationships between neighbors and the query point. These techniques address limitations in standard kkNN approaches, which can be sensitive to noisy data or uneven distributions, resulting in more accurate classification by leveraging a more representative set of neighbors during inference.
The kkNN-Graph model utilizes a Hierarchical Navigable Small World (HNSW) Graph as its core data structure to facilitate efficient nearest neighbor searches. HNSW graphs are constructed by layering a multi-graph with decreasing connectivity, enabling a logarithmic search complexity. This approach drastically reduces the time required to traverse the graph and identify the ‘k’ nearest neighbors for any given data point. The resulting structure allows for significantly accelerated search times compared to traditional linear or tree-based search methods, directly contributing to the model’s improved inference speed.
Performance evaluations demonstrate significant speed improvements with kkNN-Graph; inference times on the Caltech dataset were up to 55 times faster compared to existing methodologies. Even more substantial gains were observed on the News dataset, where kkNN-Graph achieved over 6500x faster inference. These speed enhancements do not compromise accuracy, as evidenced by a robust Macro-F1 Score of 73.98% across tested datasets, indicating a reliable balance between computational efficiency and predictive performance.
Looking Ahead: Where Do We Go From Here?
The kkNN-Graph framework establishes a remarkably flexible architecture for tackling diverse machine learning problems. Beyond simple classification or regression, this approach demonstrates substantial utility in complex applications such as image retrieval, where nuanced similarity searches are crucial. Similarly, recommendation systems benefit from the framework’s ability to identify relevant items based on user preferences and item characteristics. Perhaps less intuitively, the kkNN-Graph also proves effective in anomaly detection; by modeling typical data relationships, deviations indicative of unusual or fraudulent activity become readily apparent. This broad applicability stems from the framework’s capacity to dynamically adapt to the underlying data distribution, offering a powerful and generalized solution across a spectrum of machine learning tasks.
Current investigations are actively refining the performance of adaptive nearest neighbors through meticulous parameter optimization and the exploration of advanced neighbor selection strategies. Researchers are investigating methods to dynamically adjust the number of neighbors considered, tailoring this value to the local data density and the specific characteristics of each query point. This includes examining different weighting schemes that prioritize closer, more relevant neighbors while de-emphasizing those further afield. Furthermore, novel techniques are being developed to efficiently identify and update the neighbor set as the underlying data evolves, ensuring the model remains accurate and responsive in dynamic environments. These ongoing efforts aim to enhance both the precision and scalability of the approach, broadening its applicability to increasingly complex machine learning tasks.
The kktree represents a significant advancement in the field of nearest neighbor search by introducing an adaptive indexing structure that dynamically adjusts to the underlying data distribution. Unlike traditional tree-based methods – such as k-d trees and ball trees – which can suffer from performance degradation in high-dimensional spaces or with unevenly distributed data, the kktree recursively partitions the data based on the intrinsic dimensionality of local neighborhoods. This adaptive approach allows the tree to maintain a balanced structure, minimizing search times and improving overall efficiency. By focusing computational effort on regions with greater data density and complexity, the kk*tree demonstrably reduces the number of nodes visited during a search, offering a potential pathway to substantially faster and more scalable machine learning applications, particularly when dealing with large and complex datasets.
A significant advancement presented by this research lies in its ability to separate computational demands from the inherent dimensionality of data. Traditionally, many machine learning algorithms experience a rapid increase in complexity as the number of features grows, limiting their applicability to high-dimensional datasets. This work, however, demonstrates a pathway toward algorithms where performance doesn’t degrade proportionally with dimensionality, allowing for scalable solutions even with vast and complex data. This decoupling is achieved through innovative techniques in neighbor selection and indexing, ultimately promising machine learning systems capable of handling increasingly large and intricate datasets with greater efficiency and reduced computational cost – a critical step for advancements in fields like genomics, image analysis, and large-scale data mining.
The pursuit of efficient nearest neighbor search, as demonstrated by kkNN-Graph, feels predictably Sisyphean. This paper attempts to pre-compute boundaries and build a hierarchical index, promising near-instantaneous inference. It’s a clever dance around the computational cost, yet one suspects production data will inevitably reveal edge cases – the outliers always win. As Andrey Kolmogorov observed, “The most important things are the ones you don’t know.” This holds remarkably true; the elegance of a pre-computed graph feels fragile when faced with the messy reality of unseen data distributions. The system may accelerate classification, but it’s merely postponing the inevitable entropy. One could almost call it ‘optimized tech debt’.
What’s Next?
The presented kkNN-Graph, like all attempts to pre-compute intelligence, invites a predictable fate. It will fail, not in principle, but in production. The elegance of a hierarchical index, the promise of adaptive learning… these are merely delays of inevitable entropy. Anything self-healing just hasn’t broken yet. The true test won’t be benchmark datasets, but the first adversarial example crafted by a user attempting something unforeseen. That is when the real cost of pre-computation will be tallied.
A natural progression lies in attempting to automate the graph construction itself, moving beyond fixed heuristics. However, any such system should be viewed with suspicion. Documentation, after all, is collective self-delusion. The system will evolve in ways not foreseen by its creators, and the initial assumptions encoded in the graph structure will become archaeological artifacts. The interesting question isn’t ‘how to build a better graph’, but ‘how to gracefully degrade when the graph inevitably becomes meaningless’.
Perhaps the most revealing metric won’t be accuracy, but reproducibility. If a bug is reproducible, it suggests a stable system – a rarity in this field. The pursuit of ever-more-complex adaptive models risks obscuring the fundamental limitations of nearest-neighbor approaches. The focus should shift from chasing marginal gains in speed to understanding where kkNN-Graph fails, and what those failures reveal about the underlying data distribution.
Original article: https://arxiv.org/pdf/2601.16509.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- All Itzaland Animal Locations in Infinity Nikki
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- How to Get to the Undercoast in Esoteric Ebb
- Gold Rate Forecast
- A Dark Scream Theory Rewrites the Only Movie to Break the 2-Killer Rule
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- BloxStrike codes (March 2026)
- 6 Ways Invincible Season 4’s Hell Episode Rewrites The Comics
2026-01-26 18:18