Author: Denis Avetisyan
New research demonstrates that fine-tuned artificial intelligence models can accurately forecast corrective actions for warranty claims, paving the way for truly automated processing.
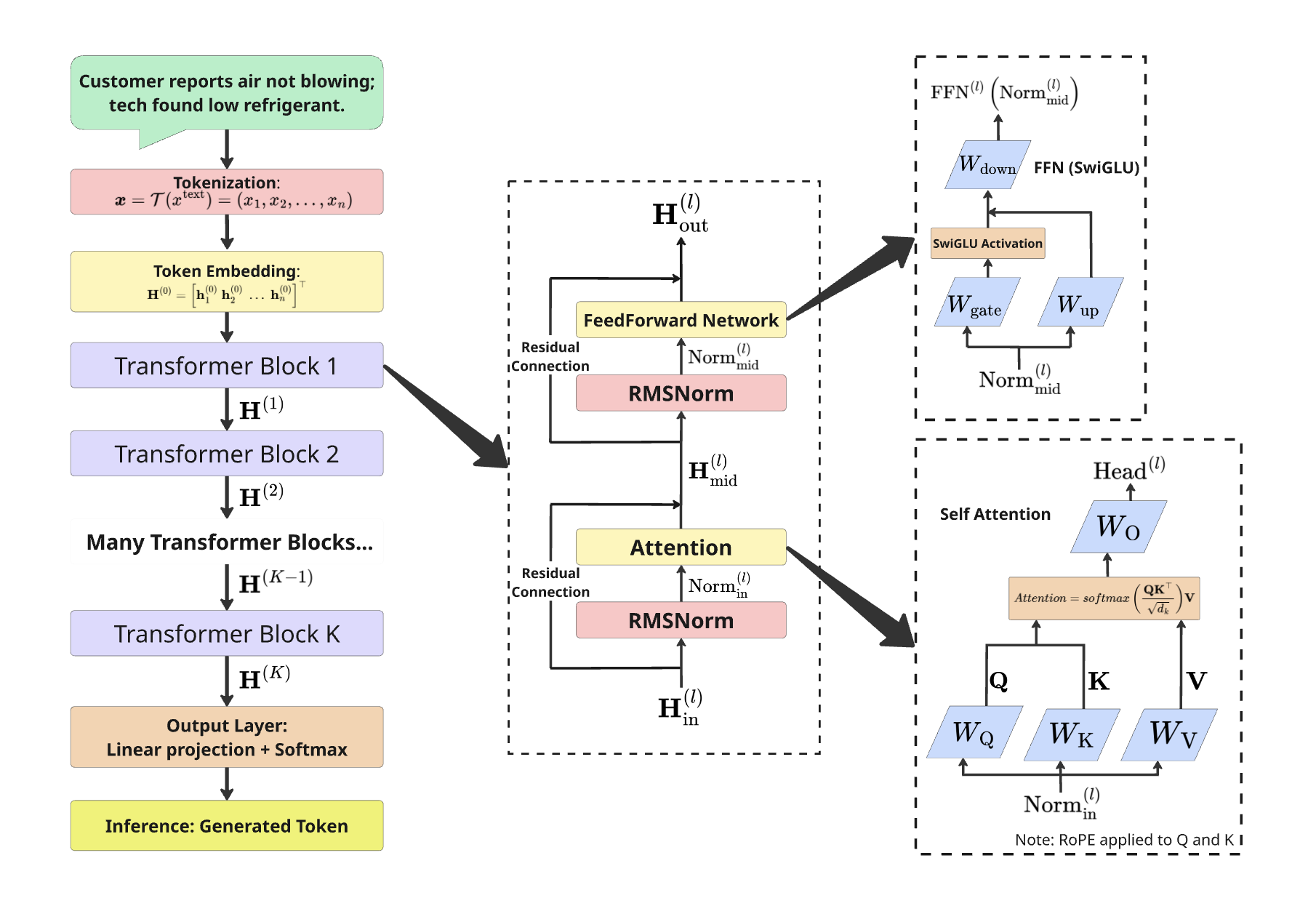
Domain adaptation of large language models significantly improves corrective action prediction in warranty claims, addressing governance concerns and surpassing general-purpose AI performance.
Despite advances in artificial intelligence, deploying large language models in highly regulated fields like insurance remains challenging due to data sensitivity and governance requirements. This research, ‘Claim Automation using Large Language Model’, introduces a locally deployed, domain-adapted language model fine-tuned on millions of warranty claims to generate structured corrective-action recommendations from unstructured narratives. Results demonstrate that this approach substantially outperforms general-purpose LLMs, achieving near-identical matches to ground-truth actions in approximately 80% of evaluated cases. Could this represent a viable pathway toward reliable and governable automation within complex insurance operations, and what further refinements are needed for broader implementation?
The Erosion of Meaning: From Text to Feature
For decades, actuarial science, in its effort to quantify risk, predominantly employed a methodology of converting descriptive textual data – such as warranty claim details or customer feedback – into discrete, numerical features. While seemingly pragmatic, this ‘Text-to-Feature Paradigm’ inevitably resulted in a significant loss of semantic context. The richness of natural language – including subtleties of phrasing, implied meanings, and the relationships between concepts – was flattened into quantifiable variables. Consequently, critical information embedded within the narrative, potentially indicative of emerging risks or fraudulent activity, was often discarded or obscured. This reductionist approach, though computationally efficient, ultimately limited the precision of risk assessments and hindered the development of truly predictive models, as the underlying complexity of the data remained largely untapped.
The conventional actuarial approach, termed the ‘Text-to-Feature Paradigm’, fundamentally restricts the comprehensive understanding of warranty claim narratives by distilling rich textual details into a limited set of numerical features. This transformation inevitably discards crucial semantic information – the subtle cues, contextual nuances, and descriptive details that contribute significantly to a complete picture of the failure event. Consequently, the resulting models struggle to differentiate between superficially similar claims that actually stem from distinctly different underlying causes, hindering precise risk prediction and potentially leading to inaccurate or unfair claim assessments. The loss of narrative context prevents a holistic evaluation, forcing reliance on simplified representations that may overlook critical factors influencing future failures and ultimately limiting the effectiveness of preventative measures.
Traditional actuarial methods often struggle with the wealth of information contained within unstructured text, such as warranty claim descriptions. Because these systems rely on converting narratives into limited numerical features, critical details-like the specific circumstances of a failure or subtle indicators of emerging product defects-are frequently lost. This inability to directly analyze textual data not only diminishes the accuracy of risk predictions, potentially leading to underestimation of future claims, but also impedes efficient claims processing. Human adjusters must spend considerable time manually interpreting narratives to fill the gaps left by automated systems, increasing operational costs and delaying resolutions. Consequently, a shift towards methodologies capable of directly processing unstructured text promises more precise risk assessment and streamlined claims handling, unlocking significant value within the insurance sector.
Adapting the Oracle: Language Models and the Domain of Failure
Domain adaptation, the process of fine-tuning a pre-trained large language model (LLM) to a specific task or dataset, presents a viable method for extracting valuable insights from warranty claim data. Warranty claims often contain nuanced language, specific product terminology, and implicit failure modes not adequately represented in general-purpose LLM training corpora. By adapting an LLM to this specialized domain, the model can better understand the semantic relationships within claim narratives, identify key issues, and ultimately unlock richer, more actionable data. This approach moves beyond simple keyword extraction and allows for a more comprehensive analysis of the underlying reasons for product failures, improving predictive maintenance and product development efforts.
The DeepSeek-R1 8B parameter language model was selected as the base model for domain adaptation due to its performance characteristics and open-weight availability. This model, comprising 8 billion parameters, provides a substantial capacity for learning complex patterns within the warranty claim data. Utilizing a pre-trained model of this scale avoids training from scratch, significantly reducing the required computational resources and training time. The DeepSeek-R1 architecture was chosen to facilitate subsequent parameter-efficient fine-tuning, allowing adaptation to the specific nuances of warranty claim language and terminology without necessitating full model retraining.
LoRA (Low-Rank Adaptation) is a parameter-efficient transfer learning technique that significantly reduces the number of trainable parameters when adapting large language models. Instead of updating all model weights, LoRA introduces trainable low-rank decomposition matrices into each layer of the Transformer architecture. This approach freezes the pre-trained model weights and only optimizes these smaller, added matrices, reducing the computational cost and memory requirements for adaptation. For the DeepSeek-R1 8B model, LoRA enabled domain adaptation using substantially fewer resources than full fine-tuning, making it practical to achieve performance gains on warranty claim data with limited hardware availability. The reduction in trainable parameters also mitigates the risk of overfitting when dealing with specialized datasets.
Conditional KL Minimization was implemented to address the challenge of distributional shift between the pre-trained language model and the target warranty claim data. This technique minimizes the Kullback-Leibler divergence between the model’s output distribution, conditioned on the input claim text, and a desired target distribution representing expected claim characteristics. Specifically, it encourages the model to generate outputs-such as predicted failure categories or repair recommendations-that align with the observed frequencies and patterns within the training dataset. By reducing the KL divergence, the process constrains the model’s predictions, improving the reliability and accuracy of its outputs for downstream tasks and mitigating the risk of generating improbable or irrelevant responses.
From Narrative to Structure: Predicting the Necessary Interventions
Corrective Action Prediction involves the automated generation of structured recommendations derived from unstructured text within warranty claim narratives. This process utilizes natural language processing techniques to identify key issues described in claim text and translate them into a standardized, machine-readable format. The system analyzes claim details – including reported failures, symptoms, and component information – to propose specific corrective actions, such as component replacement, software updates, or procedural adjustments. This automated output is designed to move beyond simple keyword extraction and provide actionable, specific recommendations suitable for direct integration into service workflows and automated decision-making processes.
The system generates a structured output consisting of standardized fields – including failure mode, root cause, and recommended repair procedure – formatted as JSON for compatibility with existing enterprise systems. This standardized format facilitates automated ingestion into Computerized Maintenance Management Systems (CMMS), warranty processing platforms, and parts ordering systems. The use of a consistent, machine-readable structure eliminates the need for manual data entry and interpretation, enabling direct automation of corrective actions and reducing processing time. Specifically, the output includes a confidence score for each predicted field, allowing downstream systems to prioritize and validate recommendations based on pre-defined thresholds.
Performance of the corrective action prediction model was assessed using a dual-metric approach. General metrics quantified overall prediction accuracy, while semantic metrics evaluated the meaningfulness and relevance of the predicted corrective actions to the warranty claim narratives. Evaluation results demonstrated that the model’s performance, as measured by both metric types, was statistically indistinguishable from performance achieved by empirical references – indicating a comparable level of accuracy and reliability in generating structured outputs from textual data.
Beyond Correctness: The Search for Semantic Resonance
Evaluating the quality of automatically generated corrective actions requires more than simply counting exact matches with expected solutions. Traditional accuracy metrics often fail to capture the nuanced meaning and intent behind a repair instruction, potentially overlooking semantically correct, yet differently worded, responses. A system might suggest a functionally equivalent part or procedure phrased distinctly from the reference, which a strict accuracy score would deem incorrect. Therefore, assessing semantic correctness – the degree to which the generated action conveys the same meaning as the ideal solution – is paramount. This approach acknowledges that multiple valid solutions can exist and focuses on whether the proposed correction effectively addresses the underlying problem, providing a more robust and meaningful evaluation than simple correctness alone.
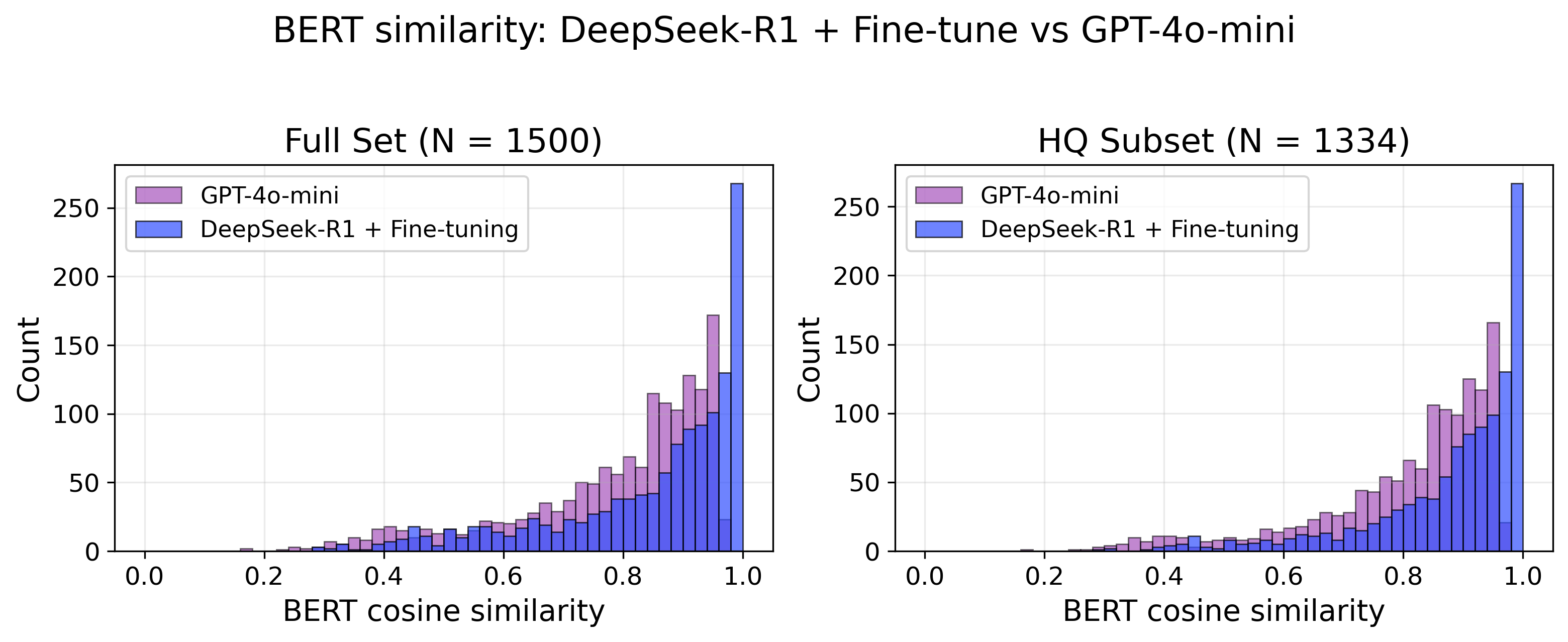
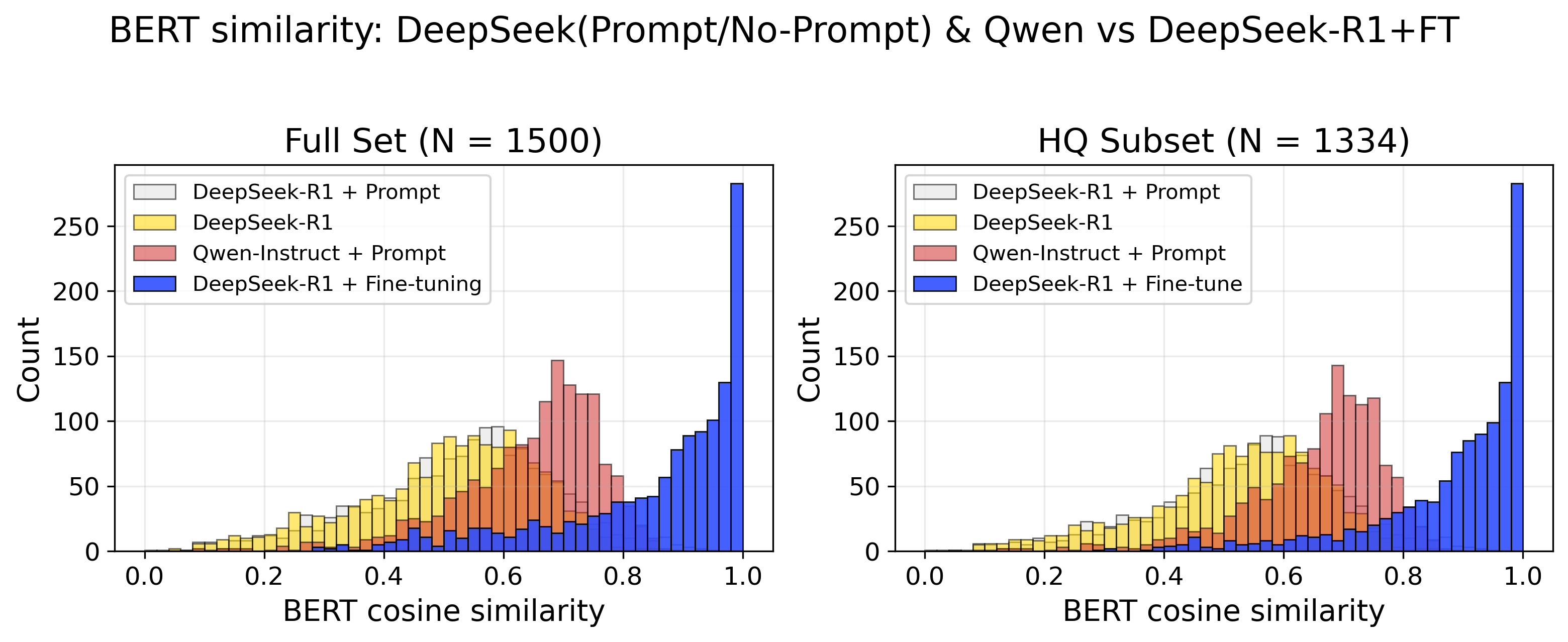
To move beyond simple correctness in evaluating generated corrective actions, a semantic similarity assessment was implemented utilizing BERT Cosine Similarity. This approach doesn’t merely check for exact matches between predicted and reference outputs, but rather assesses the degree to which their meanings align, capturing subtle nuances often missed by traditional accuracy metrics. The model demonstrated a high degree of semantic alignment, achieving a BERT Cosine Similarity score exceeding 0.95 on the high-quality (HQ) subset of the data. This indicates a strong ability to generate responses that are not only syntactically correct, but also meaningfully consistent with the expected solutions, representing a significant step towards more robust and reliable automated repair recommendations.
Integrating semantic accuracy with conventional accuracy metrics offers a pathway to more effective risk assessment and predictive maintenance strategies. This holistic evaluation approach reveals a model capable of predicting repair outcomes with a performance statistically equivalent to observed empirical repair probability – a rate of 1.36 \times 10^{-3}. This suggests the model isn’t simply memorizing solutions, but genuinely understanding the underlying issues driving failures, and therefore has the potential to identify potential problems before they escalate, streamlining maintenance schedules and minimizing downtime. The ability to reliably forecast repair success allows for a shift from reactive fixes to proactive interventions, optimizing resource allocation and bolstering system resilience.
The model’s efficacy was firmly established through rigorous training and validation utilizing a substantial dataset of warranty claim data, ensuring both robustness and the capacity to generalize to unseen scenarios. Detailed analysis of this data revealed critical areas for refinement: a 28.4% rate of incorrect repair parts being identified, alongside a 23.4% divergence in surface form – discrepancies in how issues were described. These findings aren’t merely performance metrics; they offer valuable, actionable insights, pinpointing specific weaknesses in the system and guiding future development efforts toward more precise diagnostic capabilities and improved parts selection accuracy, ultimately minimizing costly errors and enhancing overall maintenance efficiency.
The pursuit of automated claim processing, as demonstrated by this research, isn’t about imposing order – it’s acknowledging the inherent complexity of warranty claims. This work suggests that a domain-adapted Large Language Model isn’t a solution that prevents failures, but one that learns to navigate them more effectively. As Edsger W. Dijkstra observed, “Program testing can be a very effective way to find errors, but it is impossibly to prove the absence of any errors.” The model’s ability to predict corrective actions, surpassing general-purpose approaches, isn’t about achieving perfect prediction-a guarantee is merely a contract with probability-but about building a system that gracefully handles inevitable imperfections. Stability, in this context, is merely an illusion that caches well, reliant on the model’s capacity to adapt and learn from the chaos inherent in real-world claims data.
What Lies Ahead?
The pursuit of automated claim processing via large language models reveals, predictably, not a destination, but a widening garden. This work demonstrates a capacity for prediction, certainly – a clever mimicking of corrective action. But every successful automation is merely a temporary reprieve from the inevitable drift of real-world data. The model, however well-adapted, will begin, as all things do, to reflect the biases and inconsistencies of the system it serves, not to resolve them.
The focus on ‘governance’ feels less like control and more like a hopeful charting of the currents. One builds not a fortress against error, but a series of breakwaters, accepting that the tide will always find a way. The true challenge lies not in achieving a static level of accuracy, but in cultivating a system capable of gracefully degrading, of signaling its own limitations before catastrophe strikes.
Future work will inevitably explore more elaborate architectures, more nuanced domain adaptation. Yet the fundamental truth remains: these models are not solutions, but amplifiers. They amplify existing strengths, and, with equal enthusiasm, existing flaws. The next generation of research will not be about building better models, but about building systems that can listen to the whispers of their own decay.
Original article: https://arxiv.org/pdf/2602.16836.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- How to Get to the Undercoast in Esoteric Ebb
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- All Itzaland Animal Locations in Infinity Nikki
- HBO’s Harry Potter Is Already Breaking My Heart
- Zendaya’s 4 Big 2026 Movies Could Beat Brie Larson’s Box 2019 Office Record
- Neon Genesis Evangelion’s 26-episode run Made the 1990s the Best Anime Decade
2026-02-21 08:53