Author: Denis Avetisyan
A new research effort introduces TIME, a comprehensive benchmark designed to rigorously evaluate the next generation of time series forecasting models.
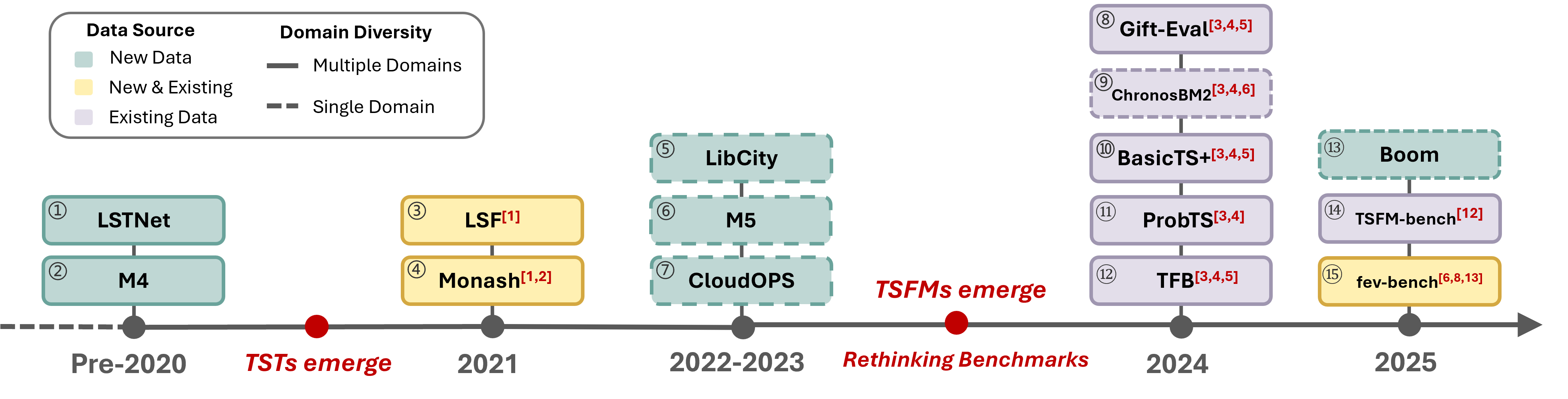
TIME addresses limitations in existing benchmarks with improved data quality, task-centric evaluation, and pattern-level analysis of model performance.
Despite the rapid advancement of time series foundation models (TSFMs), current benchmarks often suffer from data limitations and a disconnect from real-world forecasting needs. To address these shortcomings, we present ‘It’s TIME: Towards the Next Generation of Time Series Forecasting Benchmarks’, introducing a novel, task-centric benchmark comprising 50 fresh datasets and 98 forecasting tasks designed for rigorous zero-shot evaluation. This work establishes a human-in-the-loop construction pipeline and a pattern-level evaluation perspective-moving beyond static meta-labels to assess model capabilities across diverse temporal properties-and provides a multi-granular leaderboard for in-depth analysis. Will this new benchmark facilitate the development of truly generalizable and robust time series forecasting models?
The Illusion of Accuracy: Why Time Series Benchmarks Often Deceive
The pursuit of accurate time series forecasting is frequently undermined by a subtle yet pervasive issue: data leakage in commonly used benchmarks. This occurs when information from the future, or data that should only be available at prediction time, inadvertently creeps into the training data used to build forecasting models. Consequently, reported performance metrics often present an overly optimistic – and therefore misleading – picture of a model’s true capabilities. This inflation arises from models effectively “seeing” the answers before they are supposed to, leading to unrealistically high accuracy scores that do not generalize well to unseen data. Rigorous evaluation, therefore, demands careful attention to preventing this contamination and establishing benchmarks that genuinely reflect a model’s ability to predict the future, not simply recall the past.
The integrity of time series forecasting evaluations is often compromised by subtle data leakage, where information from the benchmark test set unintentionally finds its way into the training data. This can occur through various mechanisms, such as including future data points in feature engineering or failing to properly separate training and testing periods in datasets with inherent temporal dependencies. Consequently, models may appear to perform exceptionally well on benchmarks, not because of genuine predictive power, but because they have effectively ‘seen’ the future. This inflated performance creates a misleading impression of a model’s capabilities and hinders true progress in the field, as researchers may optimize for benchmarks rather than robust generalization to unseen data. Identifying and eliminating these sources of contamination is therefore crucial for obtaining reliable and meaningful assessments of time series forecasting techniques.
Advancing the field of time series analysis hinges critically on the establishment of benchmarks free from contamination and representative of real-world challenges. Existing evaluation protocols frequently overestimate model performance due to subtle data leakage – instances where future information inadvertently influences training. This creates a false impression of progress and hinders the development of genuinely robust and reliable forecasting methods. A shift towards meticulously curated, untainted datasets is therefore essential, allowing researchers to accurately assess model capabilities and drive meaningful innovation beyond artificially inflated scores. Such rigorous evaluation will not only foster trust in predictive models but also accelerate the translation of research into practical applications across diverse domains.
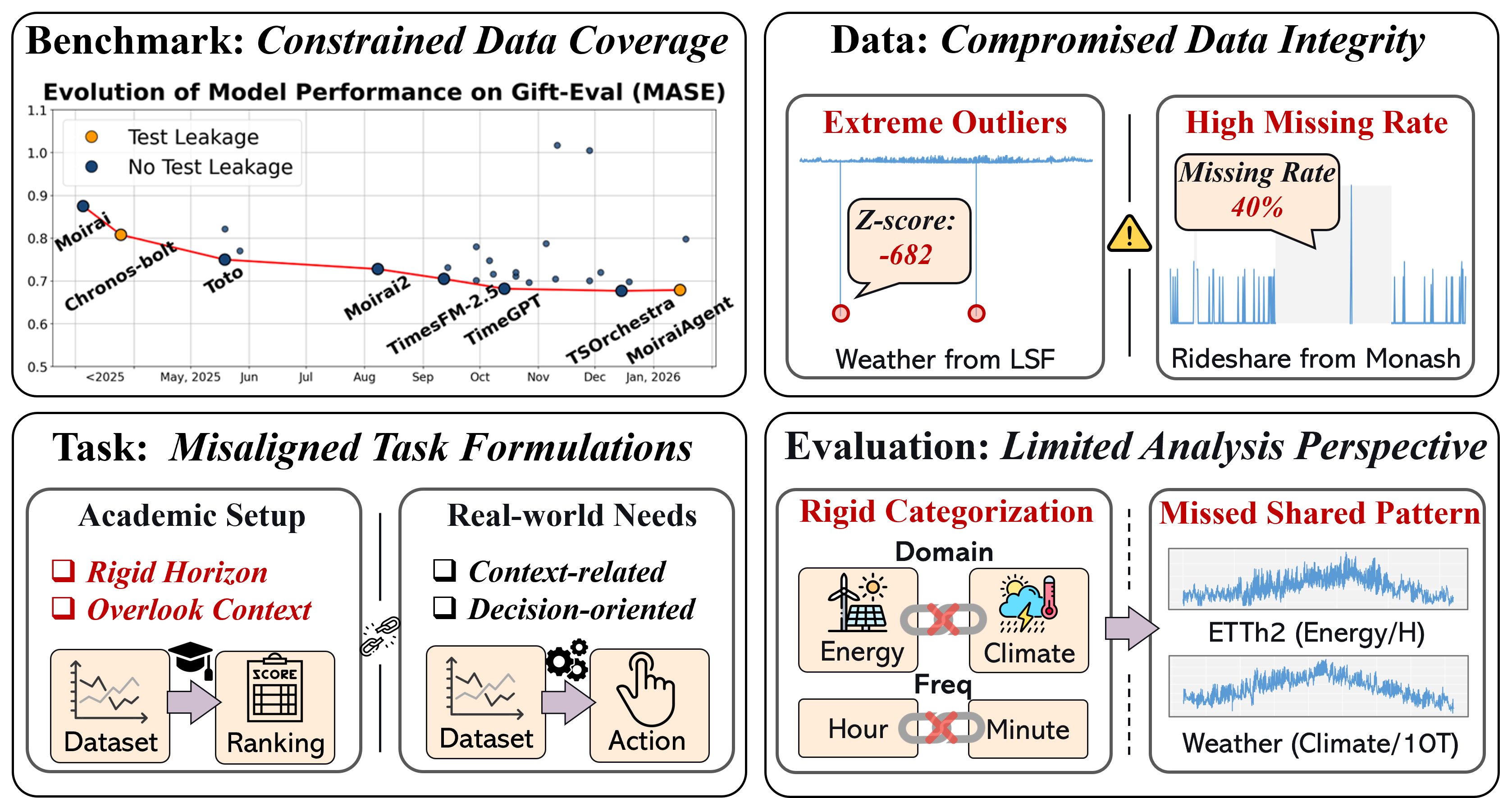
Beyond Dataset Size: A Task-Centric Approach to Time Series Evaluation
The TIME benchmark represents a shift from traditional, dataset-centric evaluation to a task-centric framework, addressing limitations found in existing benchmarks which often prioritize dataset size over real-world applicability. Current benchmarks frequently exhibit biases, limited task diversity, and a lack of focus on practical use-cases. TIME directly assesses model performance on clearly defined, representative tasks, prioritizing a holistic evaluation of capabilities beyond simple accuracy metrics. This task-centric approach facilitates more meaningful comparisons between models and provides a clearer indication of their suitability for deployment in real-world applications, moving beyond artificial performance gains on contrived datasets.
Data curation within the TIME benchmark prioritizes the creation of datasets that accurately reflect real-world task distributions. This is achieved through a multi-faceted approach, prominently featuring downsampling techniques. Downsampling reduces dataset size by selectively removing instances, but within TIME, it’s implemented strategically to maintain representativeness; the process isn’t random, and focuses on balancing class distributions and preserving edge cases. This ensures the benchmark doesn’t disproportionately favor models trained on over-represented data, and instead, evaluates performance across the full spectrum of possible inputs, leading to a more robust and reliable assessment of model generalization capabilities.
The TIME benchmark incorporates zero-shot evaluation as a core tenet, assessing a model’s capacity to perform tasks it has not been explicitly trained for. This is achieved by presenting models with task descriptions and input data without any prior fine-tuning on that specific task. Performance is then measured on unseen data, strictly evaluating generalization capabilities and avoiding performance inflation from task-specific adaptation. This methodology differs from traditional benchmarks that often rely on few-shot or fine-tuned performance, providing a more robust assessment of a model’s inherent understanding and transfer learning potential. The zero-shot approach facilitates evaluating models on a broader range of tasks and identifying those with true cross-domain adaptability.
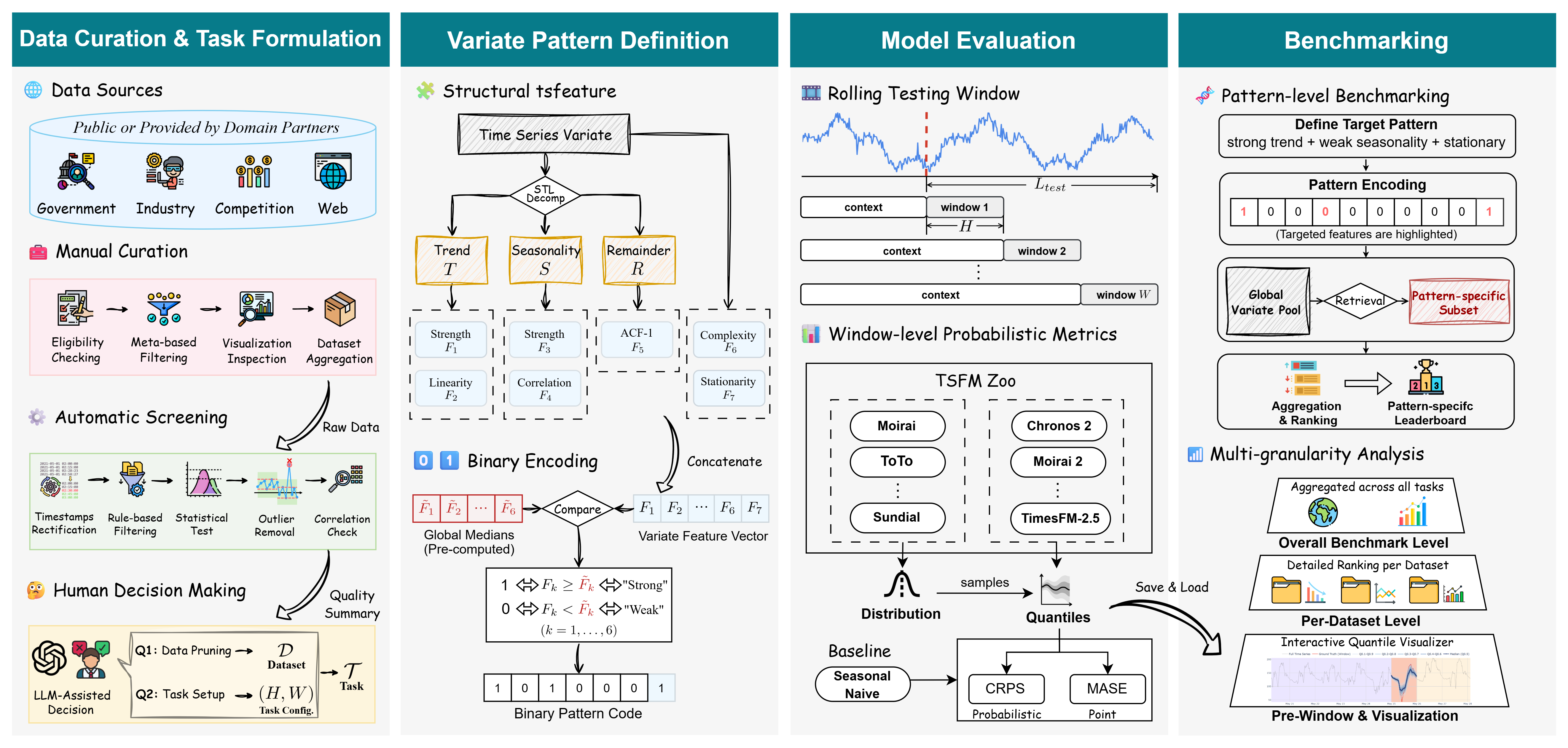
Dissecting the Signal: Pattern-Level Analysis for Granular Time Series Evaluation
The TIME benchmark utilizes Pattern-Level Analysis as a method for evaluating time series forecasting models beyond overall accuracy. Traditional aggregate metrics often mask performance variations across diverse time series characteristics; Pattern-Level Analysis addresses this by assessing model behavior on specific, identifiable patterns within the data. This approach moves beyond single, holistic scores to provide a more granular understanding of model strengths and weaknesses, enabling targeted improvements and a more reliable assessment of generalization capability. The analysis focuses on decomposing time series into constituent components to isolate and evaluate performance on features like trend and seasonality.
Time series decomposition, specifically utilizing Seasonal and Trend decomposition using Loess (STL), is employed to isolate and quantify the strength of underlying time series components. STL separates observed data into trend, seasonality, and remainder components. The magnitude of the seasonal component, relative to the overall time series, provides a measure of `Seasonality Strength`. Similarly, `Trend Strength` is determined by analyzing the amplitude and consistency of the extracted trend component. These strengths are then used as features for granular performance evaluation, allowing for analysis beyond simple aggregate metrics.
Statistical analysis of structural time series features demonstrates significant discriminatory power between patterns. Observed Fisher Scores ranged from 1.19 to 4.46, consistently exceeding the established threshold of 0.25, which indicates a robust ability to differentiate between time series characteristics. Complementing this, Cohen’s d values, measuring effect size, ranged from 1.54 to 2.98, signifying large effects and confirming that observed differences are not attributable to random chance. These metrics collectively support the validity and reliability of pattern-level analysis within the TIME benchmark.
Performance analysis segmented by time series characteristics – specifically, trend and seasonality strength as determined by STL decomposition – enables a granular understanding of model behavior beyond overall aggregate metrics. This pattern-level analysis reveals specific strengths and weaknesses, identifying scenarios where a model excels or underperforms. The low to moderate correlations (< 0.7) observed between the extracted time series features – trend strength and seasonality strength – confirm that these features are largely independent and capture complementary aspects of the data, enhancing the robustness and interpretability of the evaluation process. This independence avoids redundancy in the assessment and allows for a more nuanced identification of model biases related to specific time series patterns.
Beyond the Score: Assessing Robustness in Time Series Forecasting Models
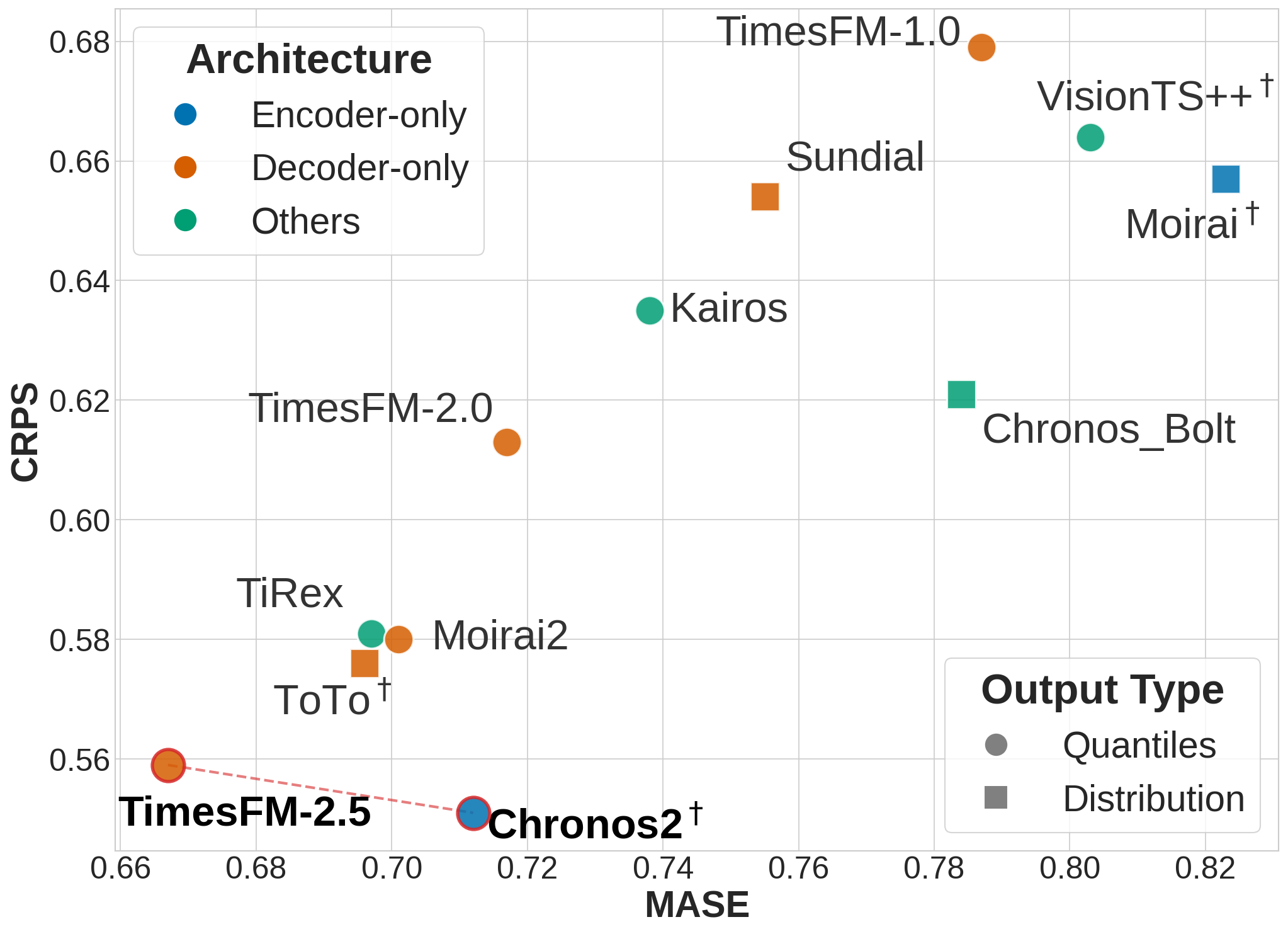
Evaluating the performance of Time Series Forecasting Models (TSFMs) requires quantifiable measures of accuracy, and the TIME benchmark employs both the Mean Absolute Scaled Error (MASE) metric and the Continuous Ranked Probability Score (CRPS) metric to achieve this. The MASE metric assesses forecast errors relative to the error of a naive forecast, providing a readily interpretable scale-independent measure. Complementing this, the CRPS metric evaluates the entire predictive distribution, offering a more nuanced assessment of forecast calibration and uncertainty. These metrics, when applied consistently across diverse time series datasets, allow for robust comparisons between different TSFM architectures and provide crucial insights into their forecasting capabilities, ultimately determining their suitability for deployment in real-world predictive tasks.
Evaluations of Time Series Forecasting Models (TSFMs) consistently highlight the challenges posed by data sparsity and the ability to generalize to unseen patterns. Analysis reveals that models struggle when faced with limited data points or unusual sequences, impacting forecast accuracy. However, certain architectures, notably Chronos2 and TimesFM 2.5, exhibit notable resilience. These models consistently achieve high scores across both the MASE metric – measuring forecast error relative to a naive forecast – and the CRPS metric – evaluating probabilistic forecast skill. This strong performance across diverse patterns suggests a superior capacity to learn robust representations from available data, even under conditions of sparsity, and ultimately deliver more reliable time series predictions.
The dependable deployment of Time Series Forecasting Models (TSFMs) hinges on subjecting them to exhaustive evaluation frameworks, and benchmarks like TIME provide precisely that necessity. Such rigorous testing isn’t merely about achieving high scores on metrics like MASE and CRPS; it’s about uncovering potential failure points and gauging a model’s resilience when confronted with previously unseen data. Without this level of scrutiny, subtle biases or vulnerabilities can remain hidden, leading to inaccurate predictions and potentially costly errors in real-world applications ranging from supply chain management to energy forecasting. Consequently, comprehensive benchmarking serves as a critical step in building confidence and establishing the trustworthiness of TSFMs before they are integrated into critical decision-making processes.
The pursuit of ever-more-sophisticated time series forecasting benchmarks feels…familiar. It’s a predictable cycle. This paper, introducing TIME and its focus on data quality and pattern-level analysis, attempts to sidestep the pitfalls of prior work. One anticipates the inevitable: production data, with all its glorious messiness, will expose limitations even in this meticulously crafted evaluation. As Bertrand Russell observed, “The problem with the world is that everyone is an expert in everything.” Similarly, every benchmark begins believing it has conquered the complexities, until reality-in the form of edge cases and unforeseen data quirks-demonstrates otherwise. It’s a lovely attempt to build a robust system, but one suspects TIME, like its predecessors, will eventually accrue its own form of technical debt.
What’s Next?
The pursuit of ever-more-comprehensive time series benchmarks invariably circles back to a familiar truth: data, ultimately, is just a cleverly disguised source of errors. TIME, with its focus on quality and task alignment, is a step forward, certainly. But the moment it’s deployed at scale, someone will inevitably feed it a dataset where the ‘signal’ is a meticulously crafted adversarial attack, and then they’ll call it AI and raise funding. It’s a predictable lifecycle.
The emphasis on pattern-level evaluation is interesting, a tacit admission that forecasting isn’t about nailing a single number, but about capturing the shape of things to come. However, this also opens a new can of worms. Defining ‘meaningful’ patterns is subjective, and what constitutes a successful capture of a pattern will quickly become a battleground of statistical interpretation. Remember when anomaly detection was going to solve everything? It ended with a cascade of false positives and a lot of frustrated stakeholders.
One suspects the real innovation won’t be in the benchmarks themselves, but in the tools used to debug the inevitable failures. This whole field used to be a simple bash script and a spreadsheet. Now it’s a distributed system with layers of abstraction, and the documentation lied again. The core problem remains: time series data is messy, chaotic, and stubbornly resistant to elegant solutions.
Original article: https://arxiv.org/pdf/2602.12147.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- Gold Rate Forecast
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- 8 Actors Who Could Play Blackbeard In One Piece Live-Action Season 3
- All Itzaland Animal Locations in Infinity Nikki
- A Dark Scream Theory Rewrites the Only Movie to Break the 2-Killer Rule
- How to Get to the Undercoast in Esoteric Ebb
- Something Evil Will Happen codes (December 2025)
- NEXO PREDICTION. NEXO cryptocurrency
2026-02-15 16:13