Author: Denis Avetisyan
A new framework evaluates the reliability of digital evidence discovered and analyzed using artificial intelligence.
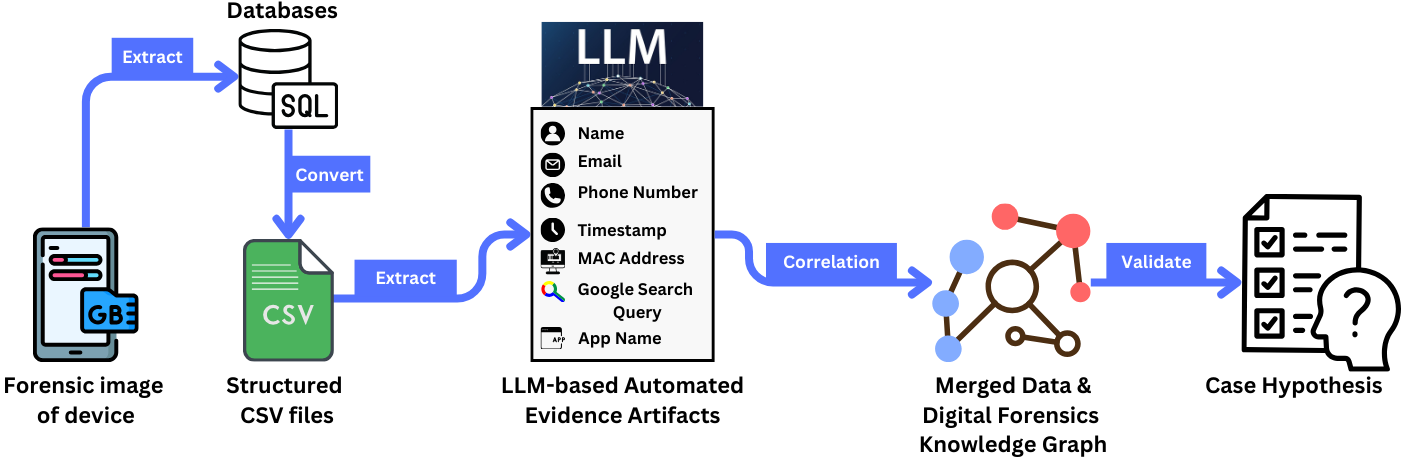
This review introduces a forensic evaluation methodology integrating large language models, knowledge graphs, and unique identifiers to enhance artifact validation and chain of custody.
Despite advancements in digital forensics, ensuring the reliability of evidence identified through artificial intelligence remains a critical challenge. This is addressed in ‘Evaluating the Reliability of Digital Forensic Evidence Discovered by Large Language Model: A Case Study’, which proposes a novel framework integrating large language models with a Digital Forensic Knowledge Graph and deterministic Unique Identifiers (UIDs) to automate artifact discovery and validation. Evaluations on a substantial dataset demonstrate over 95% accuracy in artifact extraction and robust support for chain-of-custody adherence, establishing a foundation for legally sound, AI-assisted investigations. Will this approach pave the way for widespread adoption of AI in forensic science, and what further refinements are needed to guarantee its long-term integrity?
Navigating the Scale of Digital Evidence
The exponential growth of data generation presents a significant hurdle for traditional digital forensic investigations. Where once examiners could meticulously analyze entire storage devices, the sheer volume of information – exacerbated by cloud storage, mobile devices, and the Internet of Things – now routinely overwhelms manual processes. This data deluge creates substantial analysis bottlenecks, extending investigation timelines and increasing costs. More critically, the risk of overlooking crucial evidence rises dramatically as examiners are forced to prioritize and sample data, potentially missing subtle indicators of malicious activity or vital contextual information. Consequently, modern forensic practice demands a shift towards scalable solutions capable of processing and analyzing vast datasets efficiently and accurately, lest critical evidence remain hidden within the digital noise.
The bedrock of any digital forensic investigation rests upon the unassailable integrity and trustworthiness of the evidence presented; however, traditional, largely manual processes introduce vulnerabilities that threaten this foundation. Human error, ranging from documentation mistakes to improper handling of storage media, can inadvertently alter or corrupt forensic artifacts, leading to inaccurate findings and potentially invalidating the entire case. Furthermore, inconsistencies arising from varied examiner interpretations and subjective decision-making can compromise the reliability of the analysis, creating reasonable doubt and hindering successful prosecution. Ensuring a robust chain of custody and meticulous documentation are crucial steps, but even with diligence, manual workflows inherently lack the repeatability and verifiability necessary to fully mitigate these risks in the face of increasingly complex digital landscapes.
Addressing the escalating challenges in digital forensics necessitates a fundamental shift towards automated processes and robust validation techniques. Manual analysis, while historically central, simply cannot keep pace with the exponential growth in data volume and complexity, creating significant bottlenecks and increasing the likelihood of crucial evidence being overlooked. Automation streamlines repetitive tasks – such as data acquisition, indexing, and initial filtering – allowing investigators to focus on higher-level analysis and interpretation. However, automation alone is insufficient; rigorous validation procedures are vital to ensure the integrity and trustworthiness of forensic artifacts throughout the workflow. These validations encompass verifying data authenticity, confirming the accuracy of automated processes, and establishing a clear audit trail to demonstrate the defensibility of findings. By integrating both automation and validation, digital forensic investigations can achieve greater efficiency, reduce the risk of human error, and ultimately deliver more reliable and legally sound results.
Refining Forensic Artifacts with Language Models
The LLM-Based Forensic Framework employs Large Language Models (LLMs) to analyze extracted digital evidence, specifically targeting inconsistencies and inaccuracies commonly found in forensic artifacts. This process involves the LLM evaluating artifact data against established forensic principles and known data patterns to identify and flag potential errors or anomalies. Refinement occurs through LLM-driven data normalization, correction of formatting errors, and reconciliation of conflicting information within and between artifacts. The ultimate goal is to improve the reliability and evidential weight of digital evidence by providing a validated and consistent dataset for subsequent analysis, thereby enhancing the overall quality and defensibility of forensic investigations.
Standardized data extraction methods are critical for effective LLM processing within the forensic framework. Inconsistent formatting across artifacts introduces noise and reduces the LLM’s ability to accurately identify patterns and relationships. The framework mandates the use of pre-defined parsing rules and data schemas for each artifact type, encompassing file systems, registry entries, and network logs. These rules ensure uniformity in data fields, date/time stamps, and character encoding. Specifically, textual data is converted to UTF-8, numerical data is normalized to a consistent precision, and date/time values are standardized to ISO 8601 format. This pre-processing step minimizes ambiguity and optimizes the input data for the LLM’s natural language and analytical capabilities, improving both the speed and reliability of forensic analysis.
The LLM-based refinement process necessitates the assignment of Unique Identifiers (UIDs) to each forensic artifact to maintain data integrity and enable accurate tracking throughout analysis. These UIDs are generated using the SHA-256 hashing algorithm, a cryptographic function that produces a fixed-size alphanumeric string representing the artifact’s content. This hashing method ensures that even minor alterations to the artifact will result in a different UID, immediately flagging potential data corruption or tampering. The implementation of SHA-256 hashing provides a robust mechanism for verifying the authenticity of artifacts and establishing a clear chain of custody, critical for legal admissibility and reliable forensic conclusions.
The LLM-based forensic framework integrates with the Digital Forensic Knowledge Graph (DFKG) to establish and leverage contextual relationships between discovered artifacts. The DFKG functions as a structured repository of forensic knowledge, enabling the framework to move beyond isolated artifact analysis. By modeling connections – such as file associations, registry key dependencies, or network communication patterns – the DFKG provides the LLM with crucial background information. This contextual awareness enhances the LLM’s ability to validate artifact data, identify inconsistencies, and ultimately improve the accuracy and reliability of forensic investigations by providing a broader understanding of the digital evidence.
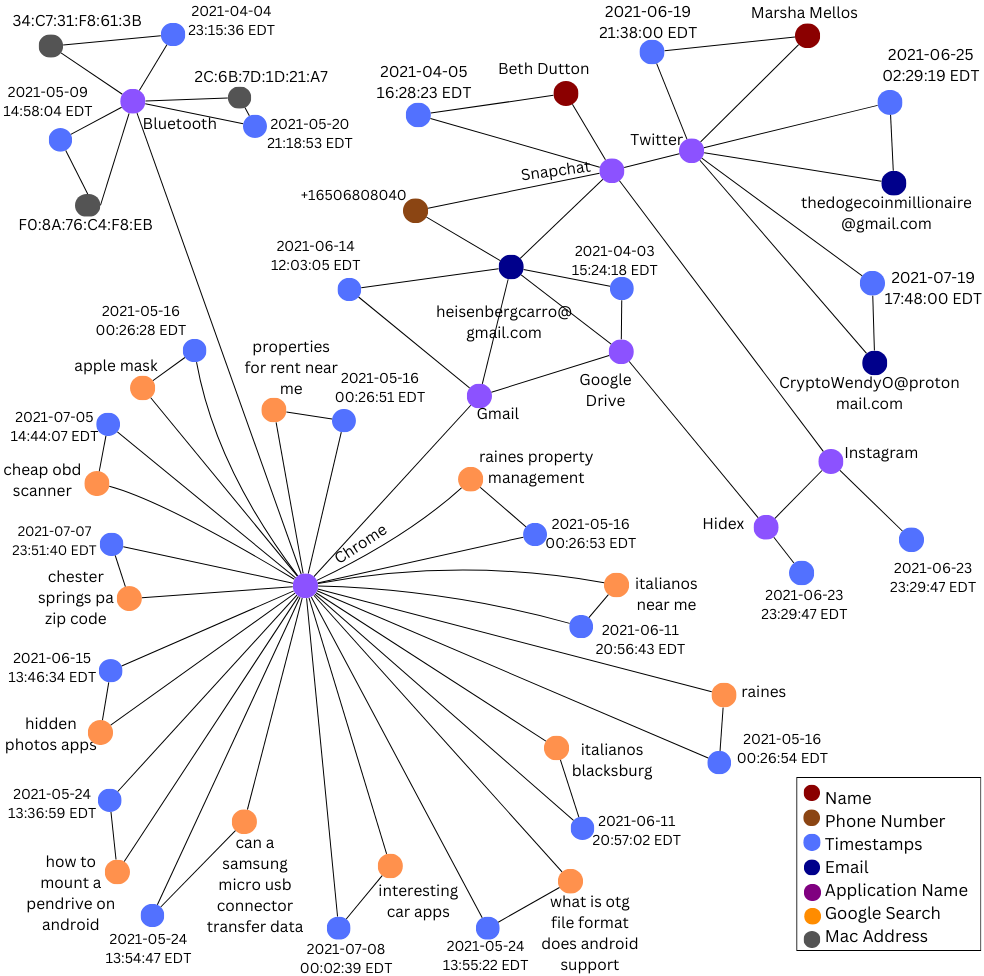
Quantifying Trust: Measuring Forensic Reliability
The forensic framework employs Evidence Extraction Accuracy (EEA) and Forensic Artifact Precision (FAP) as quantifiable metrics for assessing analytical quality. EEA, calculated by the ratio of correctly extracted evidence items to total potential items, achieved a score of 95.24% based on 40 correct extractions from a potential set of 42. FAP, measuring the proportion of correctly classified forensic artifacts, also yielded 95.24%. These metrics are determined through rigorous testing procedures designed to objectively validate the framework’s ability to accurately identify and retrieve relevant data while minimizing false positives in artifact classification.
Forensic Artifact Recall (FAR) and Knowledge Graph Connectivity Accuracy (KGCA) are key metrics used to evaluate the Digital Forensic Knowledge Graph (DFKG). FAR measures the completeness of evidence identification, with the framework achieving 100%, indicating all relevant artifacts were successfully identified during analysis. KGCA assesses the accuracy of relationships established between artifacts within the DFKG; the framework demonstrates a KGCA of 94.44%, calculated from the correct mapping of 68 out of 72 relationships. These metrics are complementary, with FAR focused on identifying all evidence and KGCA validating the integrity of connections between those artifacts, providing a comprehensive assessment of DFKG quality.
Chain of Custody Adherence (CCA) within the forensic framework ensures the complete and documented tracking of all evidence items from their initial seizure to final presentation, mitigating concerns regarding tampering or compromise. The demonstrated 100% CCA indicates that every artifact within the analyzed dataset has an unbroken, auditable history detailing its handling, storage, and any transformations applied during the analysis lifecycle. This rigorous adherence to chain-of-custody protocols is fundamental to the admissibility of forensic findings in legal proceedings and reinforces the integrity of the investigation. Contextual Consistency Score (CCS) complements CCA by validating the relevance of identified artifacts to the overall investigation, further solidifying data integrity.
The implemented metrics function as quantifiable benchmarks for establishing the reliability of forensic analysis results. An overall Forensic Artifact F1-Score (FAF1) of 97.56% demonstrates robust performance by combining both precision and recall; this composite metric offers a single value representing the balance between correctly identified artifacts (precision) and the completeness of identified artifacts relative to all existing relevant artifacts (recall). This FAF1 score, alongside individual metrics like Evidence Extraction Accuracy and Forensic Artifact Precision, facilitates objective validation of forensic findings and supports a data-driven approach to assessing trustworthiness.
Expanding the Horizon: Impact and Future Directions
The newly developed LLM-Based Forensic Framework demonstrates significant potential across a wide range of investigative applications, notably in the increasingly complex field of mobile phone forensics. Traditional methods of analyzing mobile devices are often time-consuming and require substantial manual effort, particularly when dealing with encrypted data or fragmented storage. This framework automates many of these initial processes, leveraging large language models to rapidly identify and extract relevant information from diverse data sources within the device. Consequently, investigators can achieve faster triage, more accurate data reconstruction, and a deeper understanding of the digital evidence, ultimately improving the efficiency and effectiveness of forensic investigations involving mobile technology.
The LLM-based forensic framework streamlines information exchange by generating reports compliant with the Structured Threat Information Expression (STIX) standard. This capability is crucial because STIX provides a common language and format for describing cyber threats, allowing investigators to seamlessly share findings with other security professionals and threat intelligence platforms. By adopting STIX, the framework moves beyond isolated incident analysis, fostering collaborative investigations and enabling a more comprehensive understanding of evolving cybercrime tactics. This standardized reporting not only accelerates the dissemination of critical forensic data but also enhances the accuracy and reliability of threat intelligence, ultimately strengthening collective cybersecurity defenses.
The LLM-based forensic framework significantly alters the traditional investigative process by automating repetitive and time-consuming tasks, such as data extraction and initial pattern identification. This automation frees forensic investigators from the burden of manual analysis, allowing them to concentrate on interpreting complex findings, formulating hypotheses, and making critical decisions based on the evidence presented. Consequently, investigations can proceed with increased efficiency and accuracy, as experts are empowered to leverage their expertise in contextualizing data and pursuing nuanced lines of inquiry rather than being overwhelmed by the sheer volume of information. The shift enables a more proactive and strategic approach to digital forensics, ultimately improving the quality and speed of actionable intelligence derived from investigations.
Continued development of the LLM-based forensic framework prioritizes proactive compatibility with the ever-evolving landscape of digital data. Researchers aim to move beyond current formats, integrating support for novel data types generated by emerging technologies and ensuring the framework remains effective as storage methods and communication protocols change. Simultaneously, efforts are dedicated to establishing more robust and nuanced metrics for quantifying the reliability of forensic findings. This involves moving past simple accuracy scores to incorporate measures of confidence, uncertainty, and potential biases inherent in the LLM’s analysis, ultimately providing investigators with a clearer understanding of the evidentiary weight of the results and bolstering the defensibility of findings in legal proceedings.
The pursuit of reliable digital evidence, as detailed in this evaluation framework, echoes a fundamental truth about complex systems. If the system survives on duct tape-patchwork solutions attempting to bridge gaps in validation-it’s probably overengineered. The article’s emphasis on deterministic UIDs and knowledge graphs isn’t merely about technical precision; it’s about establishing a clear, unbroken chain of custody – a structural integrity crucial for legal admissibility. As Blaise Pascal observed, “All of humanity’s problems stem from man’s inability to sit quietly in a room alone.” This seemingly unrelated observation speaks to the need for focused, methodical analysis – a deliberate slowing down to understand the foundational elements before building outwards, precisely what this framework seeks to achieve in the often chaotic landscape of digital forensics.
The Road Ahead
The integration of large language models into digital forensics, as demonstrated, offers a seductive promise: automation. Yet, every new dependency is the hidden cost of freedom. This framework, while addressing critical concerns regarding artifact validation and chain of custody through deterministic UIDs and knowledge graphs, merely shifts the locus of potential failure. The reliability now rests not solely on human interpretation, but on the integrity of the knowledge graph itself – its completeness, accuracy, and resistance to adversarial manipulation. A perfectly validated artifact, extracted by a flawed understanding of its context, remains… merely data.
Future work must confront the inherent fragility of these contextual layers. The emphasis cannot remain solely on finding evidence, but on articulating the reasoning that connects an artifact to a proposition. A truly robust system will necessitate formal methods for representing uncertainty and propagating it through the analytical process. The challenge isn’t merely to build a more efficient sieve, but to model the very nature of evidence itself.
Ultimately, the field will be defined by its ability to resist the temptation of purely algorithmic solutions. Structure dictates behavior, and a system built on opaque correlations, however statistically sound, will always be vulnerable to unforeseen consequences. The pursuit of automation must be tempered by a fundamental understanding that forensic science is, at its core, a hermeneutic endeavor – an ongoing conversation between data, context, and interpretation.
Original article: https://arxiv.org/pdf/2602.20202.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Gold Rate Forecast
- Brent Oil Forecast
- EUR ZAR PREDICTION
- Amazon Primes new GenAI cartoon looks like K-Pop Demon Hunters with aliens
- Inkford Hermitage Chest Locations In HSR (Honkai: Star Rail)
- KPop Demon Hunters Meets Avatar: The Last Airbender In Netflix’s 3-Part Fantasy Series
2026-02-25 17:05