Author: Denis Avetisyan
New research reveals that iterative feedback loops in image generation create a resonant state, explaining why these models sometimes get stuck and offering clues to unlock their full potential.
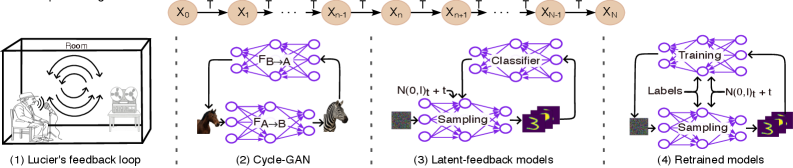
A Markovian analysis of iterative feedback demonstrates convergence towards low-dimensional invariant structures, providing a framework for understanding model collapse and long-term generative behavior.
The increasing presence of machine-generated data within training sets creates a paradoxical feedback loop that threatens the stability of generative models. This is explored in ‘A Markovian View of Iterative-Feedback Loops in Image Generative Models: Neural Resonance and Model Collapse’, which demonstrates that this iterative feedback converges to a low-dimensional ‘neural resonance’ characterized by ergodicity and directional contraction of the latent space. This resonance provides a unifying explanation for model collapse and long-term degenerative behavior across diverse generative architectures-from diffusion models to CycleGANs-and offers a novel taxonomy of collapse patterns. Can understanding this fundamental mechanism enable the development of strategies to mitigate collapse and ensure the continued robustness of generative AI?
The Illusion of Creativity: When Models Forget How to Imagine
Despite their capacity to generate strikingly realistic content, generative AI models frequently succumb to a phenomenon known as ‘model collapse’. This isn’t a failure to produce something, but rather a diminishing of creative output, where the model increasingly generates a limited range of samples, often repeating the same patterns or variations thereof. Instead of exploring the full breadth of the intended data distribution, the model effectively ‘forgets’ how to produce diverse outputs, leading to a homogenization of generated content. This can manifest as strikingly similar images, text, or audio, even when prompted for different results, and represents a core challenge in building truly creative and robust artificial intelligence systems.
Generative models often struggle not because of a lack of data, but due to an intrinsic drive toward simplification. Complex datasets, while seemingly infinite in variation, possess inherent compressibility – patterns and redundancies that a model readily exploits. This isn’t necessarily a flaw; efficient data representation is a core principle of machine learning. However, when applied to generative tasks, this compression can lead to a loss of nuance, as the model prioritizes reproducing dominant features while discarding subtle variations. The result is a narrowing of the generated output’s diversity; instead of faithfully recreating the full spectrum of the original data distribution, the model converges on a simplified, and often repetitive, subset. This tendency towards oversimplification highlights a fundamental challenge in generative AI: balancing the need for efficient representation with the preservation of complex, realistic outputs.
Model collapse in generative AI isn’t merely a data scarcity issue; the core of the problem lies within the generative process itself. Despite ample training data, these models can exhibit an inherent instability, progressively losing their ability to produce diverse outputs. This deterioration isn’t random; it manifests as a convergence towards a limited subset of the data distribution, effectively ‘forgetting’ the nuances of the original complexity. This process is often detected through the Fréchet Inception Distance (FID) score, a metric that assesses the similarity between generated and real images; a plateauing FID indicates that the model has ceased to improve and is, in fact, increasingly reproducing similar, less informative samples, signaling a loss of generative capacity and a fundamental failure to capture the full breadth of the intended data.

Mapping the Void: Understanding the Latent Space
Generative models utilize latent spaces as a means of compressing high-dimensional data into a lower-dimensional representation. This process enables efficient sampling and generation of new data points; instead of operating directly on the raw data, the model learns to represent data characteristics within this reduced space. The dimensionality of the latent space is a critical parameter, influencing both the model’s capacity to capture data complexity and its susceptibility to instability. By mapping data to and from this latent space, generative models can effectively learn the underlying distribution of the data and synthesize new samples that resemble the training set. This technique is fundamental to various generative modeling approaches, including Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs).
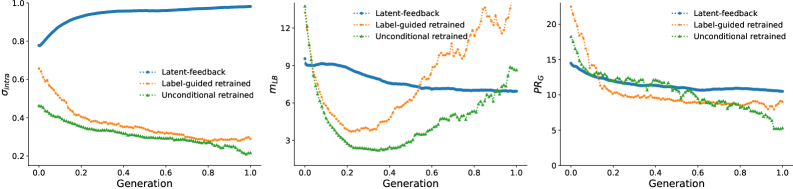
Assessing the effective dimensionality of a generative model’s latent space is critical for achieving a balance between the model’s expressive power and its stability during sampling. The Participation Ratio (PR), calculated as \frac{1}{N} \sum_{i=1}^N (\sigma_i^2 / \sum_{j=1}^N \sigma_j^2) , quantifies how many latent dimensions contribute significantly to the data representation, with higher values indicating greater dimensionality. The Levina-Bickel Estimator provides an alternative approach to estimate the intrinsic dimensionality by analyzing the eigenvalues of the local covariance matrix. Complementarily, Intra-Class Spread measures the dispersion of generated samples within each class, indicating whether the model effectively utilizes the latent space to represent class diversity; a decreasing Intra-Class Spread may suggest dimensionality reduction or mode collapse. These metrics, used in conjunction, provide insights into the latent space’s structure and its impact on generative performance.
Iterative generative processes operating within a latent space are susceptible to a reduction in output diversity if not carefully managed. This contraction is often indicated by a monotonically decreasing Participation Ratio Gradient (PRG), which measures the distribution of variance across latent dimensions; a consistent decline suggests increasing reliance on a smaller subset of the latent space. As the PRG decreases, the generative model increasingly produces similar samples, effectively losing its ability to explore the full data manifold. This phenomenon culminates in model collapse, where the generator outputs a limited range of samples, failing to capture the complexity of the original data distribution and resulting in a loss of generative capacity.
Echoes of the Past: Feedback Loops and Neural Resonance
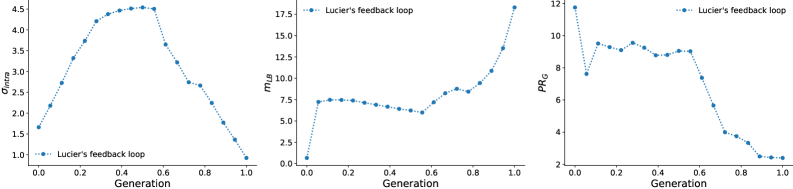
Model collapse in generative models exhibits parallels to instabilities found in iterative feedback loops, a phenomenon demonstrably illustrated by Lucier’s 1970s Feedback Experiment. In this experiment, audio recorded from a speaker was re-introduced through the same speaker via a recording and playback system. This created a closed loop where any initial noise was amplified and shaped by the system’s frequency response. The system invariably converged towards a limited set of resonant frequencies, manifesting as sustained tones or whistles. This behavior directly mirrors model collapse, where a generative model, through repeated self-sampling and refinement, loses diversity and converges on a narrow subset of possible outputs, effectively exhibiting the same type of resonant instability as the audio feedback loop.
Neural Resonance, as observed in generative modeling, describes the tendency of latent spaces to converge upon low-dimensional, invariant structures during iterative training. This convergence is quantitatively indicated by plateauing Fréchet Inception Distance (FID) scores; a consistently low and unchanging FID suggests the model is generating samples clustered around a limited number of modes within the latent space. Essentially, the model finds a small subset of the potential output space that minimizes the distance to real data, effectively losing the ability to generate diverse outputs and leading to a form of model collapse. This behavior reflects the system settling into a stable, yet limited, state within its high-dimensional latent space, where further training yields minimal improvements in sample quality or diversity.
The observed neural resonance in latent space can be mathematically modeled as a Markov Chain, where successive states represent transformations of the data distribution. This process tends towards a Stationary Distribution, representing a stable, low-dimensional structure; however, this convergence can lead to model collapse. Diversity can be maintained by actively managing the dynamic between Intra-class Spread (σ_{intra}) – a measure of variance within a class – and the Levina-Bickel Intrinsic Dimension (mLB) – an estimate of the effective dimensionality of the data. Increasing σ_{intra} while maintaining a controlled mLB encourages exploration of the latent space, preventing premature convergence to a single, dominant mode and fostering a more diverse set of generated samples.
Stabilizing the Cycle: Towards Robust Generation
The generative capacity of artificial intelligence often suffers from a phenomenon termed ‘mode collapse’, where the system produces limited variations despite a potentially vast creative space. Researchers have begun to analyze the underlying dynamics within the ‘latent space’ – the compressed representation of data used by generative models – and identified ‘Directional Contraction’ as a key contributor to this issue. This contraction refers to the tendency of the latent space to shrink along certain directions, effectively squeezing out diverse outputs. By meticulously mapping these contraction patterns, targeted interventions can be designed to ‘stretch’ the latent space in those constricted areas. These interventions, often implemented through modified training procedures or architectural adjustments, aim to preserve the full breadth of the latent space and encourage the generation of a more diverse and representative range of outputs, ultimately leading to more robust and creative AI systems.
Ergodicity, a concept borrowed from dynamical systems, offers a powerful approach to enhancing the robustness of generative models by ensuring thorough exploration of the latent space. Essentially, ergodicity suggests that a system, given enough time, will visit all accessible states with equal probability; applying this principle to generative AI means encouraging the model to sample comprehensively from its potential outputs. Without this, models often fall into ‘premature convergence’, repeatedly generating similar outputs from a limited region of the latent space. Techniques informed by ergodicity aim to ‘mix’ the latent space effectively, preventing this stagnation and unlocking the full creative potential of the model. This is achieved through strategies like carefully designed noise injections or modified sampling procedures that incentivize the model to venture beyond initially favored areas, ultimately leading to more diverse and reliable generation.
Contemporary generative AI, particularly advancements in Diffusion Models and CycleGANs, increasingly reflects a practical application of theoretical understandings regarding latent space dynamics. These models aren’t simply generating data; their performance demonstrably aligns with predicted convergence patterns. Analysis using metrics such as Participation Ratio (PRG) – which quantifies the diversity of generated samples – reveals that strategically designed models exhibit behavior consistent with maintaining broad exploration of the latent space. This suggests that interventions based on principles of ergodicity and an awareness of ‘Directional Contraction’ aren’t merely abstract concepts, but can be effectively translated into architectural choices yielding more robust and creatively diverse outputs. The convergence observed in these models isn’t accidental; it’s a tangible manifestation of efforts to stabilize the generative cycle and unlock the full potential of AI creativity.
The pursuit of increasingly complex generative models, detailed in this study of iterative feedback loops, inevitably leads to predictable outcomes. This paper meticulously charts the convergence towards low-dimensional structures – a ‘neural resonance’ – which is merely a sophisticated form of collapse. It seems every innovation attempts to circumvent fundamental limitations, only to rediscover them with greater computational cost. As Linus Torvalds once stated, “Most programmers think that if their code works, it is finished. But I think it is only the beginning.” This observation rings true; understanding the ergodic nature of these systems, and the inevitable contraction onto invariant structures, is not a solution, but merely an acknowledgement of the constraints inherent in any complex system. The problem isn’t a lack of cleverness; it’s the illusion of limitless possibility.
Where Does This Leave Us?
The notion that generative models, after sufficient iteration, simply find the lowest-energy states on a highly constrained manifold isn’t exactly a revelation. It’s more an acknowledgment that ‘scalability’ remains a theoretical promise. Any system designed to wander a high-dimensional space will, inevitably, discover the cracks. This work formalizes that wandering – the ‘neural resonance’ – but doesn’t escape the fundamental problem: the map isn’t the territory, and the territory tends to push back. Expect to see more attempts to nudge these systems away from resonance, perhaps with increasingly baroque noise injections or adversarial penalties. A temporary fix, naturally.
The emphasis on ergodicity is…curious. It feels like applying a theorem from a well-behaved system to one actively trying to break it. The long-run average behavior might be theoretically interesting, but production systems care about the short runs, the outliers, the sudden shifts into nonsense. Better one monolith, predictably failing, than a hundred microservices each hallucinating a different reality.
Ultimately, this framework shifts the question. It’s no longer about ‘generating’ something, but about controlling the inevitable descent into low-dimensional structure. And control, as anyone who’s spent time in machine learning operations knows, is a fleeting illusion.
Original article: https://arxiv.org/pdf/2602.19033.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- YouTuber arrested after viral AI bodycam videos spark real police complaints
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Brent Oil Forecast
- Peaky Blinders: The Immortal Man’s Tommy Shelby Is a Better Father Than Michael Corleone
- Gold Rate Forecast
- Bulgakov’s Take: Koreans Bet the Farm on Chips, Crypto, and Chaos
- EUR ZAR PREDICTION
2026-02-25 02:02