Author: Denis Avetisyan
A new system uses sensor fusion and continual learning to predict and diagnose wheel defects in railway systems, enhancing safety and reducing maintenance costs.
This review details an online monitoring approach leveraging Fiber Bragg Grating sensors and accelerometer data for continual wheel fault detection in wayside railway applications.
Maintaining railway infrastructure requires increasingly sophisticated fault detection, yet traditional predictive maintenance often struggles with evolving operational conditions and the need for manual feature engineering. This is addressed in ‘Axle Sensor Fusion for Online Continual Wheel Fault Detection in Wayside Railway Monitoring’, which introduces a novel framework leveraging data fusion of accelerometer and fiber Bragg grating sensor readings alongside a continual learning strategy. The approach effectively detects wheel imperfections-such as flats and polygonization-while adapting to changes in train type, speed, and track profiles, all without catastrophic forgetting. Could this semantic-aware, label-efficient system represent a significant step toward truly autonomous and reliable wayside railway monitoring?
The Evolving Landscape of Railway Fault Diagnosis
For decades, railway maintenance operated on a largely reactive basis, with faults identified through routine manual inspections or, critically, after a component failed. This approach, while historically standard, incurs significant costs due to unexpected service disruptions, emergency repairs, and the potential for cascading failures. The labor-intensive nature of manual checks also contributes to high operational expenses, and the time required to physically inspect vast rail networks introduces delays that ripple through the entire transportation system. Consequently, railway operators face a constant trade-off between the cost of preventative measures and the far greater financial and logistical burden of dealing with unscheduled downtime, prompting a growing need for more efficient and predictive diagnostic strategies.
Modern railway networks are evolving into intricately connected systems, integrating advanced signaling, communication, and train control technologies. This escalating complexity necessitates a shift from traditional, reactive maintenance schedules to proactive, data-driven strategies. Rather than addressing failures as they arise-often causing disruptive delays and substantial repair costs-operators are increasingly turning to continuous monitoring and predictive analytics. By harnessing the wealth of data generated by onboard sensors, trackside infrastructure, and operational systems, potential faults can be identified and mitigated before they impact service. This approach not only minimizes downtime and enhances safety but also optimizes resource allocation and extends the lifespan of critical railway assets, representing a fundamental change in how rail networks are managed and maintained.
A truly effective predictive maintenance program for railways hinges on the reliable detection of both axle counts and wheel defects, yet current technologies frequently struggle to surpass 90% accuracy in these critical areas. This shortfall isn’t merely a statistical inconvenience; inaccurate axle counting can lead to false positives triggering unnecessary safety checks and delays, or, more seriously, fail to identify missing or incorrectly counted axles-potentially creating hazardous conditions. Similarly, incomplete wheel defect identification-missing cracks, flat spots, or material fatigue-allows damage to propagate, increasing the risk of derailments and costly repairs. Improving these detection rates requires advancements in sensor technology, data analytics, and machine learning algorithms capable of discerning subtle anomalies and minimizing both false alarms and missed defects, ultimately bolstering railway safety and operational efficiency.
Unveiling Railway Dynamics: Data Acquisition and Feature Extraction
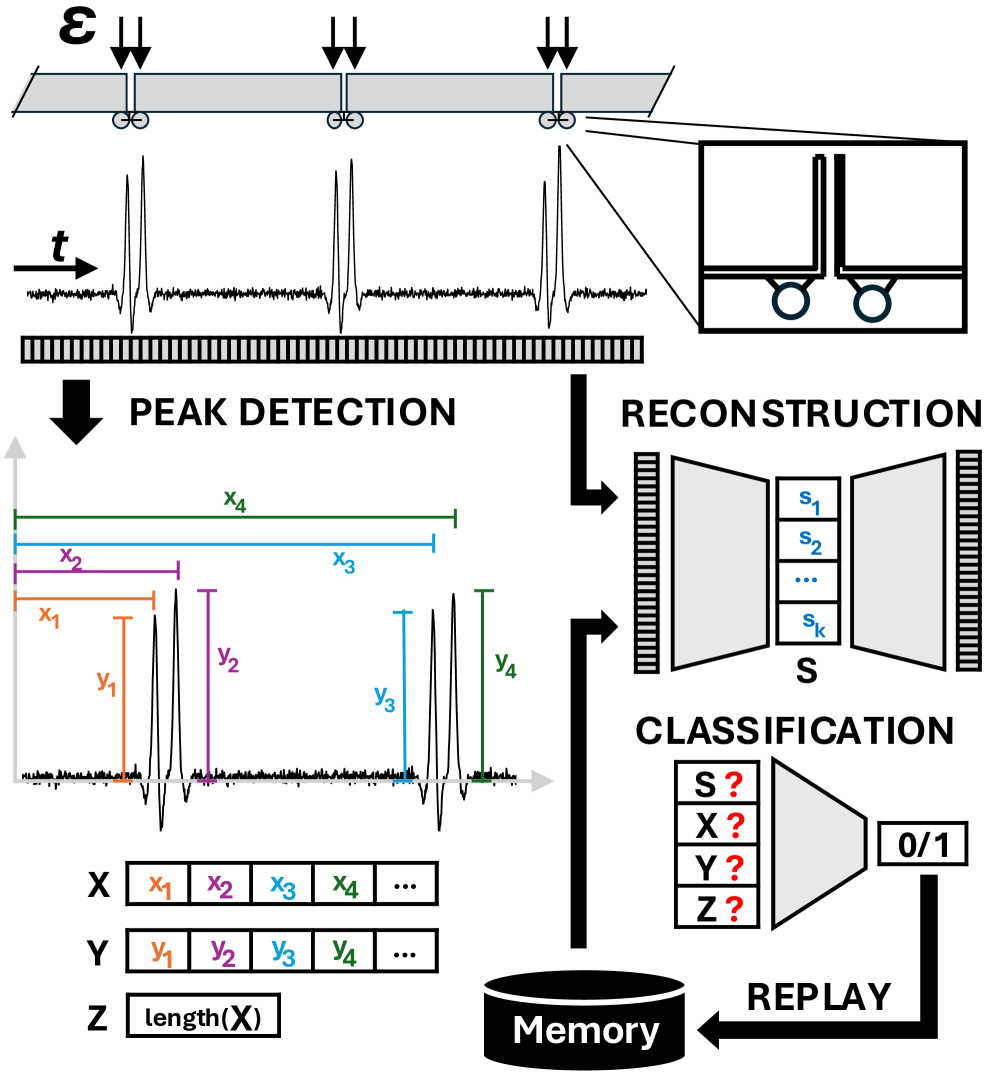
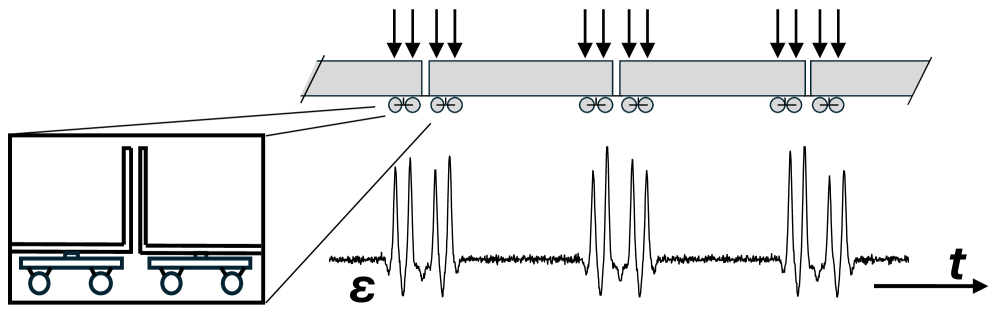
Accelerometers mounted on rail vehicles measure vibration data directly correlated to wheel-rail interaction forces. These sensors capture accelerations in multiple axes, providing a detailed profile of dynamic responses as wheels traverse the rails. Analysis of this data allows for the identification of irregularities such as flat spots on wheels, rail defects like squats and corrugation, and bearing faults. The frequency and amplitude of detected vibrations are key indicators; deviations from established baselines signal potential anomalies requiring further investigation. Data is typically sampled at rates exceeding 1 kHz to capture high-frequency events and is processed to quantify vibration energy in specific frequency bands, providing actionable insights into the condition of both rolling stock and track infrastructure.
Peak detection algorithms are critical for processing accelerometer data to determine the number of axles passing over a sensor. These algorithms identify local maxima within the time-series signal generated by the accelerometer, with each peak ideally corresponding to a wheel passing. Accurate axle counting relies on precise peak identification and filtering to eliminate noise and spurious signals caused by track irregularities or sensor vibration. Algorithm parameters, such as threshold values and minimum peak separation, are tuned based on the specific sensor characteristics and expected train speeds. Furthermore, robust algorithms incorporate techniques to differentiate between closely spaced peaks resulting from a single axle and separate events, ensuring accurate axle count data for railway monitoring and weight-in-motion applications.
Latent representation learning techniques, such as autoencoders and principal component analysis (PCA), are employed to reduce the dimensionality of high-volume sensor data derived from railcar monitoring systems. These methods transform the original data-typically multi-channel accelerometer readings-into a lower-dimensional “latent space” while preserving salient features relevant to track and component health. This compression not only decreases computational demands for real-time anomaly detection-reducing processing time and resource utilization-but also improves the robustness of algorithms by mitigating the impact of noise and irrelevant variations present in the raw sensor signals. The resulting latent features can then be used as input to machine learning models designed to identify deviations from normal operating conditions, such as wheel flats or bearing defects.
Adaptive Resilience: Continual Learning for Railway Fault Prediction
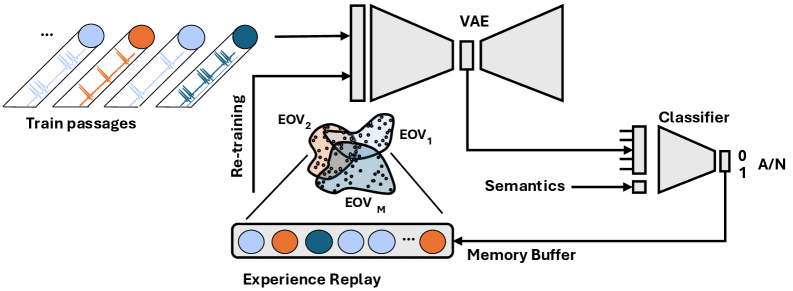
Continual learning (CL) is a machine learning paradigm designed to address the non-stationary nature of railway operational data. Traditional machine learning models, when trained incrementally on new data, often experience “catastrophic forgetting,” where the acquisition of new knowledge overwrites previously learned information. CL techniques mitigate this by enabling models to learn from a continuous stream of data – reflecting evolving track conditions, rolling stock characteristics, and emerging fault patterns – without a significant loss of performance on previously encountered scenarios. This is achieved through strategies that preserve relevant historical data and consolidate new information, allowing for adaptive fault prediction and improved system reliability in dynamic railway environments.
Experience replay is a crucial component of continual learning (CL) systems, mitigating catastrophic forgetting by storing past data and replaying it during training on new tasks. To improve the efficiency and effectiveness of this process, the system utilizes both reservoir sampling and loss-based sampling. Reservoir sampling maintains a fixed-size, uniformly random subset of historical data, ensuring diverse representation. Loss-based sampling, conversely, prioritizes replaying samples where the model previously performed poorly, focusing learning on difficult or previously misclassified instances. This combination allows the CL model to retain crucial historical information without being overwhelmed by data volume, contributing to robust performance in dynamic environments where conditions and fault types evolve over time.
The implemented Fiber Bragg Grating (FBG)-based axle counting system demonstrated a maximum accuracy of 93% when integrated with a loss-based memory sampling continual learning strategy and semantic data enrichment. This system utilizes FBG sensors to detect the passage of train axles, and the continual learning component addresses the challenge of adapting to changing railway conditions without losing previously learned data. The incorporation of semantic information, representing contextual details about the operating environment and potential fault indicators, further contributes to the system’s performance. This combined approach enables reliable axle counting even with evolving fault patterns and varying operational scenarios.
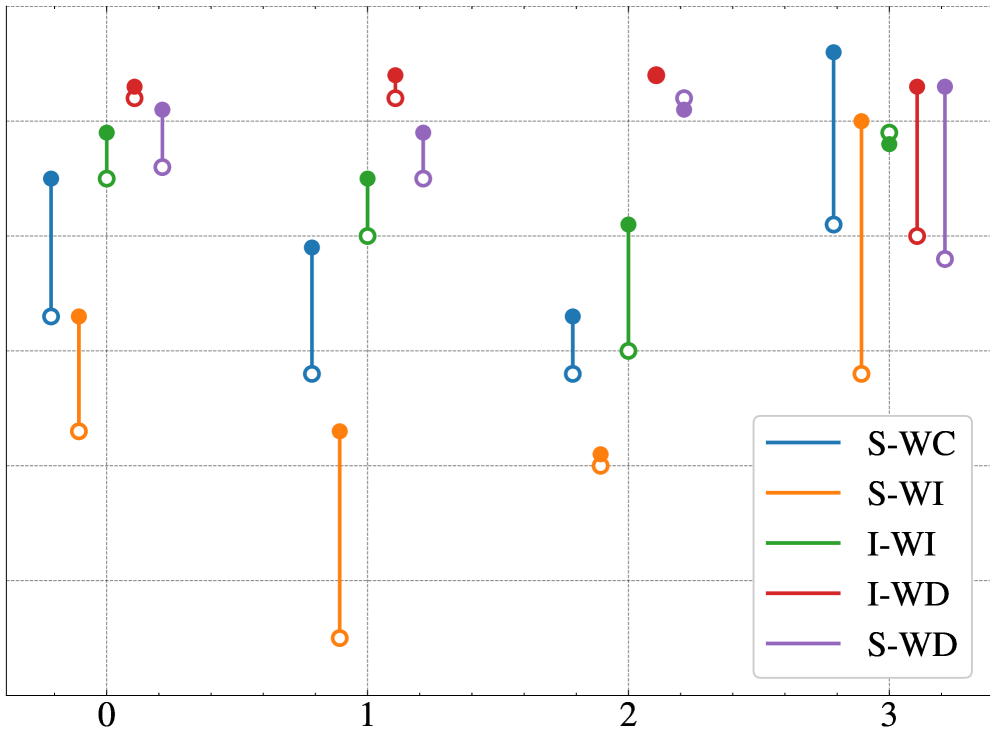
Evaluation of the proposed continual learning strategy using a Fiber Bragg Grating (FBG)-based axle counting system demonstrated forward transfer values ranging from 0.24 to 0.31. This metric quantifies the model’s ability to retain previously learned knowledge while adapting to new data distributions, specifically evolving railway conditions and fault types. These values indicate a substantial level of effective knowledge retention, minimizing catastrophic forgetting and enabling the model to generalize effectively to unseen scenarios. The achieved forward transfer values suggest the loss-based memory sampling technique successfully prioritizes and stores informative historical data, contributing to the system’s overall robustness and adaptability.
The incorporation of semantic information into data streams used for railway fault diagnosis demonstrably improves both accuracy and reliability. This enrichment process involves supplementing raw sensor data with contextual details regarding operational conditions, track geometry, and historical maintenance records. Testing indicates that this semantic enrichment results in a 5-12 percentage point increase in anomaly detection performance compared to systems relying solely on raw sensor inputs, signifying a substantial improvement in the ability to identify and classify developing faults within the railway infrastructure.
Towards Proactive Resilience: The Future of Railway Maintenance
Predictive maintenance represents a paradigm shift in railway infrastructure management, leveraging the power of machine learning and advanced sensing technologies to move beyond reactive repairs. By continuously monitoring critical components – such as wheels, bearings, and tracks – systems can identify subtle anomalies indicative of developing faults long before they escalate into major failures. This proactive approach minimizes unscheduled downtime, a significant cost driver in rail operations, and drastically reduces maintenance expenses by allowing for targeted interventions only when and where needed. Crucially, predictive maintenance substantially enhances railway safety; early detection of potential issues prevents catastrophic events, protects passengers and freight, and ensures the continued reliability of this vital transportation network. The ability to anticipate and address problems before they occur is transforming railway maintenance from a cost center into a strategic asset.
The integrity of railway wheels is paramount to operational safety and efficiency, and early detection of defects like polygonization – the development of flat spots due to uneven wear – and wheel flats themselves is crucial in preventing catastrophic failures. These seemingly minor imperfections generate impactful vibrations that, if left unaddressed, can escalate into significant track damage, derailments, or even collisions. Proactive monitoring systems utilizing advanced sensing technologies and algorithms allow for the identification of these defects in their nascent stages, enabling timely intervention and preventing the progression towards critical failure points. By prioritizing early detection, railway operators not only minimize the risk of accidents but also substantially reduce maintenance costs associated with reactive repairs and component replacements, ultimately ensuring a more reliable and cost-effective transportation network.
Recent investigations into proactive railway maintenance demonstrate a significant advancement in anomaly detection capabilities. Utilizing the Scipy peak detection algorithm, researchers achieved a 93% accuracy rate in identifying deviations from normal operational parameters. This level of precision was attained through careful configuration and optimization of the algorithm, allowing for the reliable pinpointing of potential faults before they escalate. Such a high degree of accuracy promises a substantial reduction in unexpected failures, improved safety metrics, and a considerable decrease in maintenance expenditures by enabling targeted interventions only when and where they are needed. The demonstrated efficacy of this approach positions data-driven anomaly detection as a cornerstone of future railway infrastructure management.
The transition to data-driven railway maintenance represents a fundamental shift in how critical infrastructure is managed, moving beyond reactive repairs to proactive, condition-based strategies. By continuously monitoring assets and analyzing the resulting data – encompassing everything from wheel condition to track stress – operators can now anticipate potential failures before they occur. This capability allows for the optimization of maintenance schedules, concentrating resources on components exhibiting early signs of degradation and extending the overall lifespan of costly infrastructure. Consequently, resources are no longer wasted on unnecessary inspections or premature replacements, and downtime is minimized, leading to significant cost savings and a demonstrably safer, more reliable rail network. The implementation of these insights not only improves operational efficiency but also facilitates a more sustainable approach to infrastructure management, maximizing return on investment and ensuring long-term viability.
Ongoing investigations are centering on the synergistic combination of data from diverse sensor networks to refine predictive maintenance capabilities within railway systems. This multi-sensor data fusion aims to create a more holistic understanding of component health, moving beyond reliance on single data streams. Simultaneously, researchers are actively exploring and developing novel machine learning algorithms – extending beyond current approaches – to enhance the robustness and adaptability of fault prediction models. These advanced algorithms are designed to not only identify existing failure modes with greater accuracy but also to proactively anticipate unforeseen issues and dynamically adjust to evolving operational conditions, ultimately minimizing disruptions and maximizing the longevity of critical railway infrastructure.
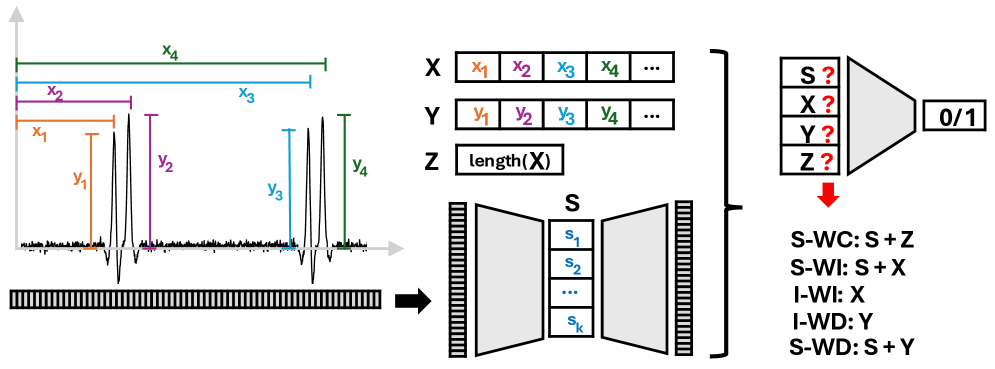
The presented system prioritizes a holistic understanding of railway health, mirroring the principle that structure dictates behavior. This approach, combining data from Fiber Bragg Grating sensors and accelerometers, isn’t merely about detecting anomalies, but about understanding the interconnectedness of components within the axle system. As Barbara Liskov once stated, “Programs must be correct and usable, but also maintainable.” This echoes the need for a predictive maintenance system that’s not just accurate in the present, but adaptable to the continual changes and operational variability inherent in railway environments. A clear, well-structured system, capable of learning and evolving, is paramount to long-term reliability and scalability – a principle beautifully embodied in this research.
Beyond the Rails
The presented system, while demonstrating a capacity for robust axle fault detection, ultimately highlights the enduring challenge of translating sensor data into actionable understanding. Documentation captures structure – the sensor array, the fusion algorithm, the continual learning loop – but behavior emerges through interaction with a system far more complex than any model. The mitigation of electromagnetic interference, though effective, serves as a reminder that the external environment is rarely static, and true resilience demands adaptation, not just shielding.
Future work must confront the inherent limitations of relying solely on axle data. A singular focus, however precise, risks overlooking systemic failures manifesting elsewhere in the train or along the track. Expanding the sensor network-integrating data from trackside vibration monitors, wheel impact load detectors, or even environmental sensors-promises a more holistic view. However, the true advancement will lie not simply in data volume, but in developing algorithms capable of discerning meaningful correlations within that complexity.
Ultimately, the goal transcends mere fault detection. The predictive capacity hinted at here suggests a future where maintenance is not reactive, but anticipatory – a shift requiring not just sophisticated algorithms, but a fundamental reimagining of railway infrastructure as a dynamic, self-aware organism. This is not merely an engineering challenge, but a question of systemic design, where elegance stems from simplicity and the whole truly exceeds the sum of its parts.
Original article: https://arxiv.org/pdf/2602.16101.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Gold Rate Forecast
- Brent Oil Forecast
- EUR ZAR PREDICTION
- Amazon Primes new GenAI cartoon looks like K-Pop Demon Hunters with aliens
- Inkford Hermitage Chest Locations In HSR (Honkai: Star Rail)
- KPop Demon Hunters Meets Avatar: The Last Airbender In Netflix’s 3-Part Fantasy Series
2026-02-19 21:13